Spark DB 커넥터를 사용하여 실시간 빅 데이터 분석 가속화
적용 대상: ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
참고 항목
2020년 9월 현재, 이 커넥터는 활발하게 관리되고 있지 않습니다. 그러나 Azure SQL 및 SQL Server용 Apache Spark 커넥터는 Python 및 R 바인딩에 대한 지원, 데이터 대량 삽입을 위한 사용이 간편한 인터페이스 및 기타 많은 개선 사항을 통해 이제 사용 가능합니다. 이 커넥터 대신 새 커넥터를 평가하고 사용하는 것이 좋습니다. 이전 커넥터에 대한 정보(이 페이지)는 보관 목적으로만 보존됩니다.
Spark 커넥터를 사용하면 Azure SQL Database, Azure SQL Managed Instance 및 SQL Server의 데이터베이스가 Spark 작업에 대한 입력 데이터 원본 또는 출력 데이터 싱크로 작동할 수 있습니다. 빅 데이터 분석에서 실시간 트랜잭션 데이터를 활용하고 임시 쿼리 또는 보고에 대한 결과를 유지할 수 있습니다. 기본 제공 JDBC 커넥터에 비해, 이 커넥터는 데이터베이스에 대량으로 데이터를 삽입하는 기능을 제공합니다. 10배~20배 빠른 성능으로 행 단위로 삽입할 때 뛰어난 성능을 제공합니다. Spark 커넥터는 Microsoft Entra ID(이전의 Azure Active Directory)를 사용하여 Azure SQL Database 및 Azure SQL Managed Instance에 연결할 때 인증을 지원하므로, Microsoft Entra 계정을 사용하여 Azure Databricks에서 데이터베이스를 연결할 수 있습니다. 기본 제공 JDBC 커넥터와 유사한 인터페이스를 제공합니다. 이 새 커넥터를 사용하기 위해 기존 Spark 작업을 쉽게 마이그레이션할 수 있습니다.
참고 항목
Microsoft Entra ID는 이전의 Azure Active Directory(Azure AD)입니다.
Spark 커넥터 다운로드 및 빌드
이전에 이 페이지에서 링크했던 이전 커넥터의 GitHub 리포지토리는 적극적으로 관리되지 않습니다. 대신 새 커넥터를 평가하고 사용하도록 적극 권장합니다.
공식 지원되는 버전
| 구성 요소 | 버전 |
|---|---|
| Apache Spark | 2.0.2 이상 |
| Scala | 2.10 이상 |
| SQL Server용 Microsoft JDBC Driver | 6.2 이상 |
| Microsoft SQL Server | SQL Server 2008 이상 |
| Azure SQL Database | 지원 여부 |
| Azure SQL Managed Instance | 지원 여부 |
Spark 커넥터는 SQL Server용 Microsoft JDBC 드라이버를 사용하여 Spark 작업자 노드 및 데이터베이스 사이에서 데이터를 이동합니다.
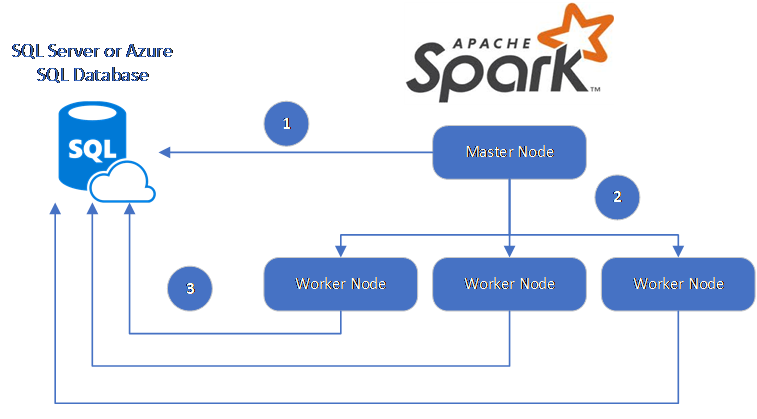
데이터 흐름은 다음과 같습니다.
- Spark 마스터 노드는 SQL Database 또는 SQL Server의 데이터베이스에 연결하고 특정 테이블에서 또는 특정 SQL 쿼리를 사용하여 데이터를 로드합니다.
- Spark 마스터 노드는 변환을 위해 데이터를 작업자 노드에 배포합니다.
- 작업자 노드는 SQL Database 및 SQL Server에 연결된 데이터베이스에 연결하고 데이터베이스에 데이터를 쓰는 씁니다. 사용자는 행 단위 삽입 또는 대량 삽입을 사용할지 선택할 수 있습니다.
다음 다이어그램은 데이터 흐름을 보여줍니다.
Spark 커넥터 빌드
현재 커넥터 프로젝트는 maven을 사용합니다. 종속성 없이 커넥터를 빌드하기 위해 다음을 실행할 수 있습니다.
- mvn 클린 패키지
- 릴리스 폴더에서 최신 버전의 JAR 다운로드
- SQL Database Spark JAR 포함
Spark 커넥터를 사용하여 연결 및 데이터 읽기
Spark 작업에서 SQL Database 및 SQL Server의 데이터베이스에 연결하여 데이터를 읽거나 쓸 수 있습니다. SQL Database 및 SQL Server의 데이터베이스에서 DML 또는 DDL 쿼리를 실행할 수도 있습니다.
Azure SQL 및 SQL Server에서 데이터 읽기
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********",
"connectTimeout" -> "5", //seconds
"queryTimeout" -> "5" //seconds
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
지정된 SQL 쿼리를 사용하여 Azure SQL 및 SQL Server에서 데이터 읽기
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"queryCustom" -> "SELECT TOP 100 * FROM dbo.Clients WHERE PostalCode = 98074" //Sql query
"user" -> "username",
"password" -> "*********",
))
//Read all data in table dbo.Clients
val collection = sqlContext.read.sqlDB(config)
collection.show()
Azure SQL 및 SQL Server에 데이터 쓰기
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
// Aquire a DataFrame collection (val collection)
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********"
))
import org.apache.spark.sql.SaveMode
collection.write.mode(SaveMode.Append).sqlDB(config)
Azure SQL 또는 SQL Server에서 DML 또는 DDL 쿼리 실행
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.query._
val query = """
|UPDATE Customers
|SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
|WHERE CustomerID = 1;
""".stripMargin
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"queryCustom" -> query
))
sqlContext.sqlDBQuery(config)
Microsoft Entra 인증을 사용하여 Spark에서 연결
Microsoft Entra 인증을 사용하여 SQL Database 및 SQL Managed Instance에 연결할 수 있습니다. Microsoft Entra 인증을 사용하여 데이터베이스 사용자의 ID를 중앙에서 관리하고 SQL 인증 대신 사용할 수 있습니다.
ActiveDirectoryPassword 인증 모드를 사용하여 연결
설치 요구 사항
ActiveDirectoryPassword 인증 모드를 사용하는 경우 microsoft-authentication-library-for-java 및 해당 종속성을 다운로드하고 Java 빌드 경로에 포함해야 합니다.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"authentication" -> "ActiveDirectoryPassword",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
액세스 토큰을 사용하여 연결
설치 요구 사항
액세스 토큰 기반 인증 모드를 사용하는 경우 microsoft-authentication-library-for-java 및 해당 종속성을 다운로드하고 Java 빌드 경로에 포함해야 합니다.
Azure SQL Database 또는 Azure SQL Managed Instance에서 데이터베이스에 대한 액세스 토큰을 가져오는 방법은 Microsoft Entra 인증 사용을 참조하세요.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"accessToken" -> "access_token",
"hostNameInCertificate" -> "*.database.windows.net",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
대량 삽입을 사용하여 데이터 쓰기
기존의 jdbc 커넥터는 행 단위 삽입을 사용하여 데이터베이스에 에 데이터를 씁니다. Spark 커넥터를 사용하여 대량 삽입으로 Azure SQL과 SQL Server에 데이터를 쓸 수 있습니다. 큰 데이터 집합을 로드하거나 columnstore 인덱스가 사용되는 테이블에 데이터를 로드할 때 쓰기 성능이 크게 개선됩니다.
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
/**
Add column Metadata.
If not specified, metadata is automatically added
from the destination table, which may suffer performance.
*/
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "Title", java.sql.Types.NVARCHAR, 128, 0)
bulkCopyMetadata.addColumnMetadata(2, "FirstName", java.sql.Types.NVARCHAR, 50, 0)
bulkCopyMetadata.addColumnMetadata(3, "LastName", java.sql.Types.NVARCHAR, 50, 0)
val bulkCopyConfig = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"dbTable" -> "dbo.Clients",
"bulkCopyBatchSize" -> "2500",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
df.bulkCopyToSqlDB(bulkCopyConfig, bulkCopyMetadata)
//df.bulkCopyToSqlDB(bulkCopyConfig) if no metadata is specified.
다음 단계
아직 수행하지 않은 경우 azure-sqldb-spark GitHub repository에서 Spark 커넥터를 다운로드하고 리포지토리에서 추가 리소스를 탐색합니다.
Apache Spark SQL, DataFrames 및 데이터 세트 가이드 및 Azure Databricks 설명서를 검토할 수도 있습니다.