자습서: Azure SQL Database의 데이터베이스와 SQL Server 간에 SQL 데이터 동기화 설정
적용 대상:![]() Azure SQL Database
Azure SQL Database
이 자습서에서는 Azure SQL Database와 SQL Server 인스턴스를 모두 포함하는 동기화 그룹을 생성하여 SQL 데이터 동기화를 설정하는 방법을 설명합니다. 새 동기화 그룹을 사용자 지정으로 구성하고 설정한 일정에 따라 동기화합니다.
자습서에서는 이전에 SQL Database 및 SQL Server에 대한 경험이 조금이라도 있다고 가정합니다.
SQL 데이터 동기화의 개요는 SQL 데이터 동기화를 사용하여 클라우드 및 온-프레미스 데이터베이스에서 데이터 동기화를 참조하세요.
SQL 데이터 동기화를 구성하는 방법을 보여 주는 PowerShell 예제는 SQL Database의 데이터베이스를 동기화하는 방법 또는 Azure SQL Database와 SQL Server의 데이터베이스를 동기화하는 방법을 참조하세요.
Important
허브 데이터베이스는 동기화 그룹에 여러 데이터베이스 엔드포인트가 있는 동기화 토폴로지의 중앙 엔드포인트입니다. 동기화 그룹에 엔드포인트가 있는 다른 모든 구성원 데이터베이스는 허브 데이터베이스와 동기화합니다.
현재 SQL 데이터 동기화는 Azure SQL Database에서만 지원됩니다. 허브 데이터베이스는 Azure SQL Database여야 합니다.
Azure SQL Database Hyperscale은 허브 데이터베이스가 아닌 구성원 데이터베이스로만 지원됩니다.
동기화 그룹 만들기
Azure Portal로 이동합니다. SQL Database를 검색하여 선택하고 기존 Azure SQL Database를 찾습니다.
데이터 동기화를 위해 허브 데이터베이스로 사용할 데이터베이스를 선택합니다.
선택한 데이터베이스에 대한 SQL Database 리소스 메뉴의 데이터 관리에서 다른 데이터베이스에 동기화를 선택합니다.
다른 데이터베이스에 동기화 페이지에서 새 동기화 그룹을 선택합니다. 데이터 동기화 그룹 만들기 페이지가 열립니다.
데이터 동기화 그룹 만들기 페이지에서 다음 설정을 구성합니다.
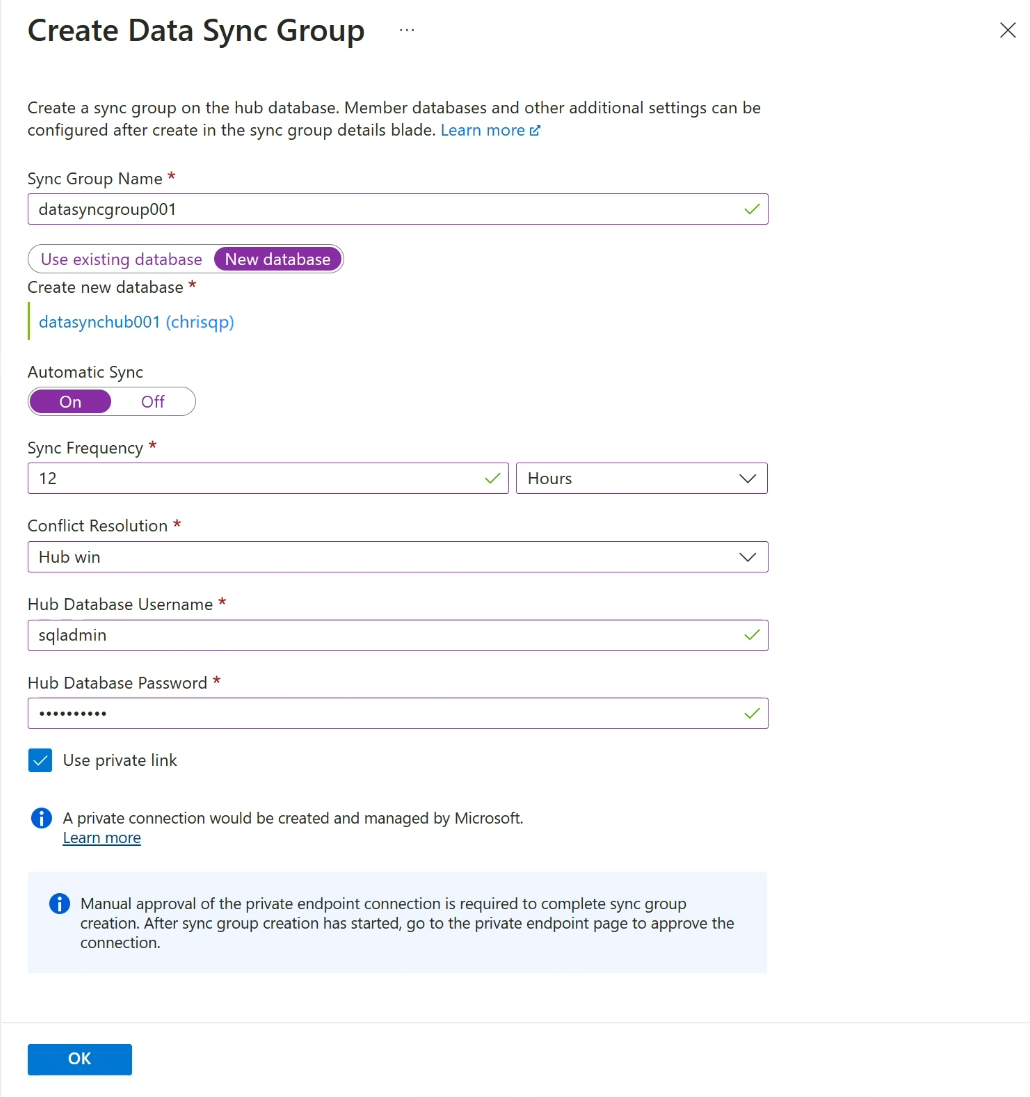
설정 설명 동기화 그룹 이름 새 동기화 그룹의 이름을 입력합니다. 이 이름은 데이터베이스 이름과 다릅니다. 동기화 메타데이터 데이터베이스 동기화 메타데이터 데이터베이스 섹션에서 새 데이터베이스를 생성할지(권장), 아니면 기존 데이터베이스를 사용할지를 선택합니다.
동기화 메타데이터 데이터베이스로 사용할 비어 있는 새 데이터베이스를 생성하는 것이 좋습니다. 데이터 동기화는 이 데이터베이스에서 테이블을 생성하고 빈번한 워크로드를 실행합니다. 이 데이터베이스는 선택한 지역 및 구독에서 모든 동기화 그룹의 동기화 메타데이터 데이터베이스로 공유됩니다. 해당 지역의 모든 동기화 그룹 및 동기화 에이전트를 제거해야만 데이터베이스 또는 해당 이름을 변경할 수 있습니다.
새 데이터베이스를 생성하려는 경우 새 데이터베이스를 선택합니다. 데이터베이스 설정 구성을 선택합니다. SQL Database 페이지에서 새 Azure SQL 데이터베이스를 구성하고 이름을 지정한 후 확인을 선택합니다.
기존 데이터베이스 사용을 선택하는 경우 동기화 메타데이터 데이터베이스 드롭다운 목록에서 데이터베이스를 선택합니다.자동 동기화 설정 또는 해제를 선택합니다.
켜기를 선택하는 경우 숫자를 입력하고 동기화 빈도 섹션에서 초, 분, 시간 또는 일을 선택합니다.
첫 번째 동기화는 구성이 저장된 시간부터 선택한 간격 기간이 경과한 후에 시작됩니다.충돌 해결 허브 우선 또는 구성원 우선을 선택합니다.
허브 우선은 충돌이 발생할 경우 허브 데이터베이스의 데이터가 구성원 데이터베이스에서 충돌하는 데이터를 덮어쓰는 것을 의미합니다.
구성원 우선은 충돌이 발생할 경우 구성원 데이터베이스의 데이터가 허브 데이터베이스에서 충돌하는 데이터를 덮어쓰는 것을 의미합니다.허브 데이터베이스 사용자 이름 및 허브 데이터베이스 비밀번호 허브 데이터베이스에 대한 서버 관리자 SQL 인증 로그인에 사용자 이름 및 비밀번호를 제공합니다. 시작한 것과 동일한 Azure SQL 논리 서버의 서버 관리자 사용자 이름 및 비밀번호입니다. Microsoft Entra(이전의 Azure Active Directory) 인증은 현재 지원되지 않습니다. 프라이빗 링크 사용 서비스 관리형 프라이빗 엔드포인트를 선택하여 동기화 서비스와 허브 데이터베이스 간에 보안 연결을 설정합니다. 확인을 선택하고 동기화 그룹이 생성되어 배포될 때까지 기다립니다.
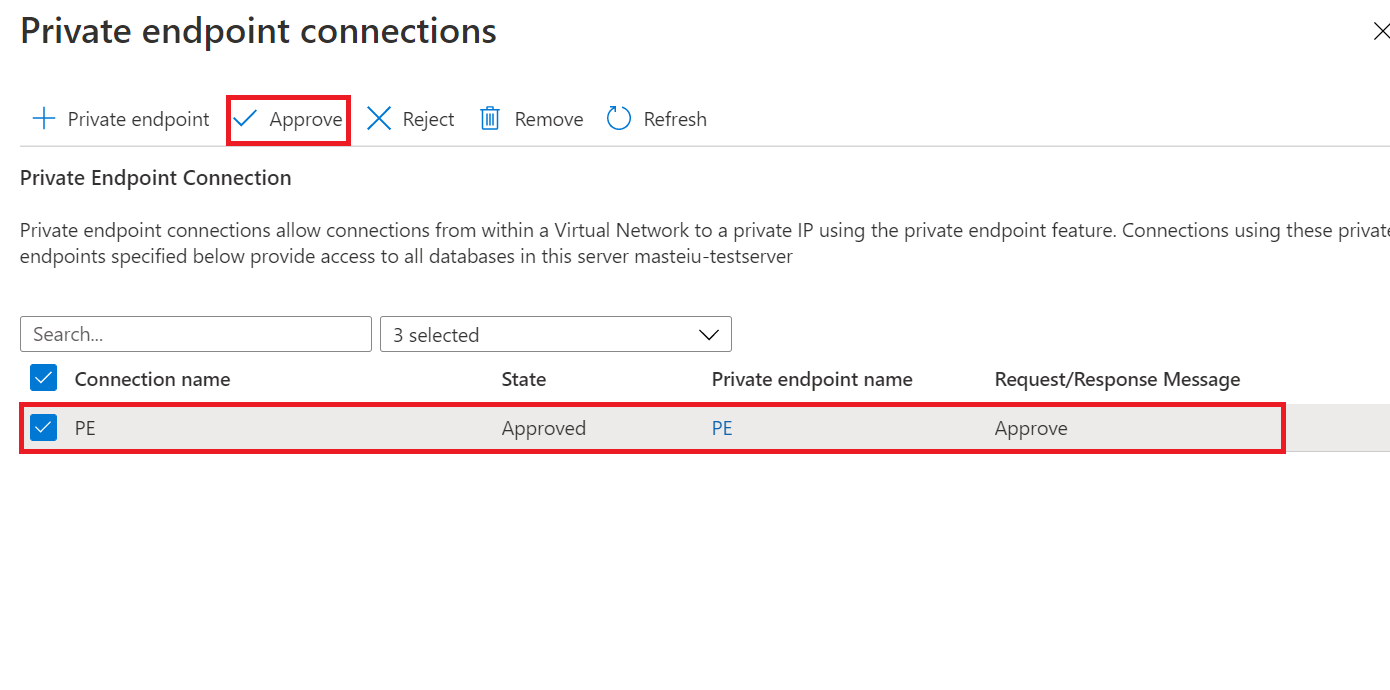
새 동기화 그룹 페이지에서 프라이빗 링크 사용을 선택한 경우 프라이빗 엔드포인트 연결을 승인해야 합니다. 정보 메시지의 링크를 통해 연결을 승인할 수 있는 프라이빗 엔드포인트 연결 환경으로 이동합니다.
참고 항목
동기화 그룹의 프라이빗 링크 및 동기화 구성원을 별도로 생성 및 승인하고 사용하지 않도록 설정해야 합니다.
동기화 구성원 추가
새 동기화 그룹을 생성하고 배포한 후 동기화 그룹을 열고 데이터베이스 페이지에 액세스하여 동기화 구성원을 선택합니다.
참고 항목
사용자 이름과 암호를 업데이트하거나 허브 데이터베이스에 삽입하려면 동기화 구성원 선택 페이지에서 허브 데이터베이스 섹션으로 이동합니다.
Azure SQL Database의 데이터베이스를 동기화 그룹에 구성원으로 추가
동기화 구성원 선택 섹션에서 필요에 따라 Azure 데이터베이스 추가를 선택하여 Azure SQL Database의 데이터베이스를 동기화 그룹에 추가합니다. Azure Database 구성 페이지가 열립니다.
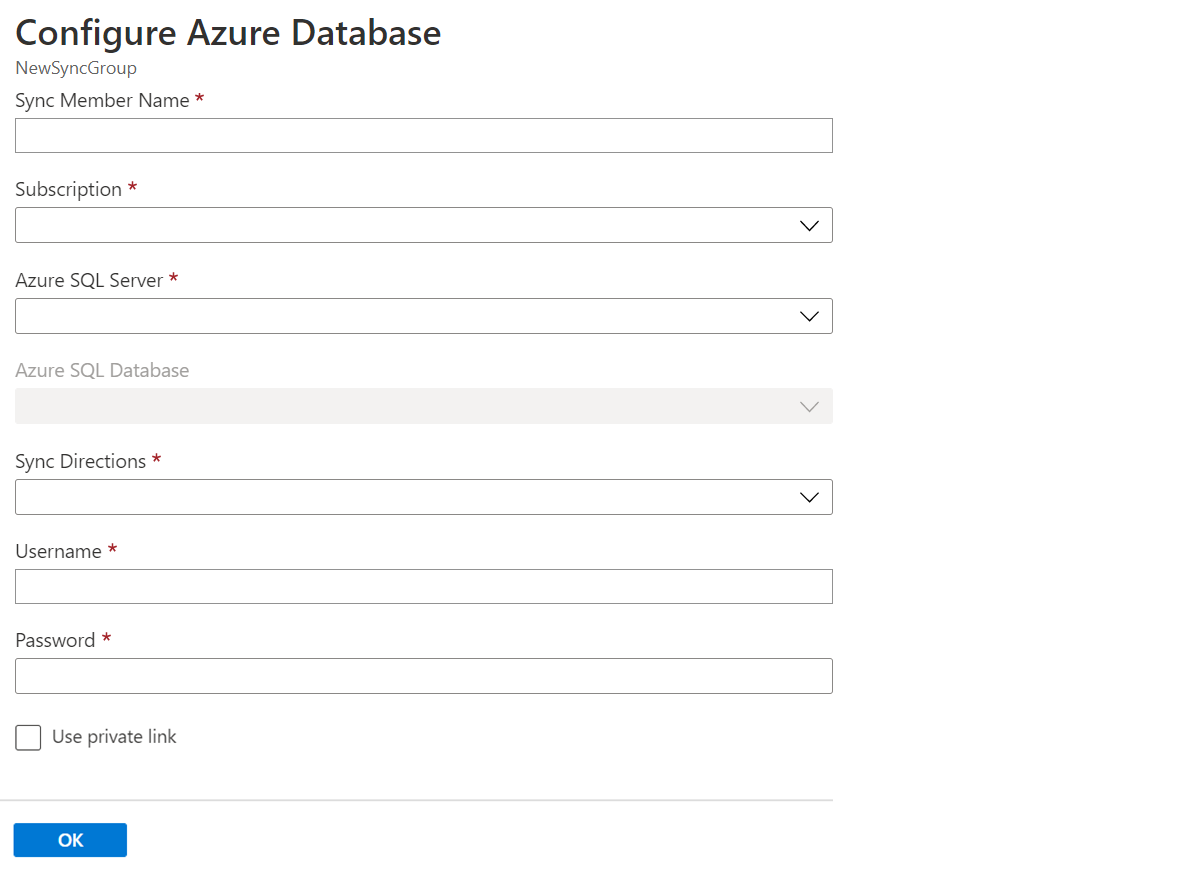
Azure SQL Database 구성 페이지에서 다음 설정을 변경합니다.
설정 설명 동기화 구성원 이름 새 동기화 구성원의 이름을 제공합니다. 이 이름은 데이터베이스 이름과 다릅니다. 구독 요금 청구를 위해 연결된 Azure 구독을 선택합니다. Azure SQL Server 기존 서버를 선택합니다. Azure SQL Database SQL Database 필드에서 기존 데이터베이스를 선택합니다. 동기화 방향 동기화 방향은 허브에서 구성원, 구성원에서 허브 또는 둘 다일 수 있습니다. 허브에서, 허브로 또는 양방향 동기화에서 선택합니다. 자세한 내용은 작동 방식을 참조하세요. 사용자 이름 및 암호 구성원 데이터베이스가 있는 서버의 기존 자격 증명을 입력합니다. 이 섹션에서 새 자격 증명을 입력하지 않습니다. 프라이빗 링크 사용 서비스 관리형 프라이빗 엔드포인트를 선택하여 동기화 서비스와 구성원 데이터베이스 간에 보안 연결을 설정합니다. 확인을 선택하고 새 동기화 구성원이 생성되어 배포될 때까지 기다립니다.
SQL Server 인스턴스의 데이터베이스를 동기화 그룹에 구성원으로 추가
구성원 데이터베이스 섹션에서 필요에 따라 온-프레미스 데이터베이스 추가를 선택하여 SQL Server 인스턴스의 데이터베이스를 동기화 그룹에 추가합니다.
다음 작업을 수행할 수 있는 온-프레미스 구성 페이지가 열립니다.
동기화 에이전트 게이트웨이 선택을 선택합니다. 동기화 에이전트 선택 페이지가 열립니다.
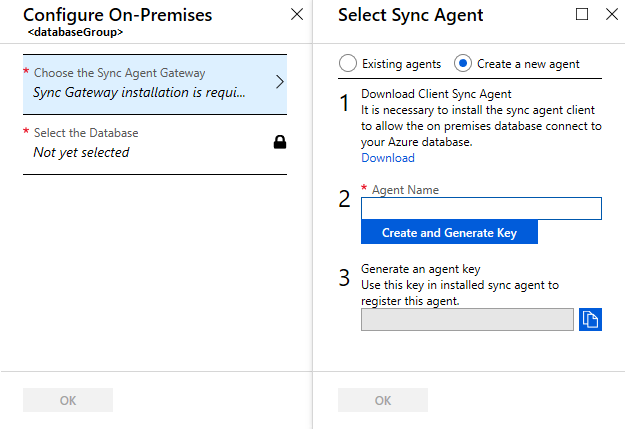
동기화 에이전트 선택 페이지에서 기존 에이전트를 사용할지, 에이전트를 생성할지를 선택합니다.
기존 에이전트를 선택하는 경우 목록에서 기존 에이전트를 선택합니다.
새 에이전트 만들기를 선택하는 경우 다음을 수행합니다.
제공된 링크에서 데이터 동기화 에이전트를 다운로드하고 SQL Server 인스턴스가 있는 서버와 다른 서버에 설치합니다. Azure SQL 데이터 동기화 에이전트에서 직접 에이전트를 다운로드할 수도 있습니다. 동기화 클라이언트 에이전트에 대한 모범 사례는 Azure SQL 데이터 동기화 모범 사례를 참조하세요.
Important
클라이언트 에이전트가 서버와 통신할 수 있도록 방화벽에서 아웃바운드 TCP 포트 1433을 열어야 합니다.
에이전트 이름을 입력합니다.
키 만들기 및 생성을 선택하고 에이전트 키를 클립보드에 복사합니다.
확인을 선택하여 동기화 에이전트 선택 페이지를 닫습니다.
동기화 클라이언트 에이전트가 설치된 서버에서 클라이언트 동기화 에이전트 앱을 찾아 실행합니다.
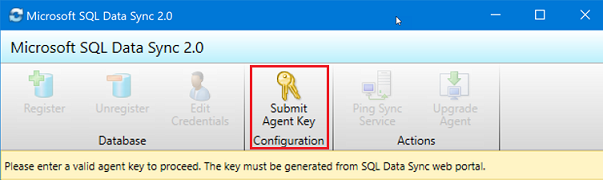
동기화 에이전트 앱에서 에이전트 키 제출을 선택합니다. 동기화 메타데이터 데이터베이스 구성 대화 상자가 열립니다.
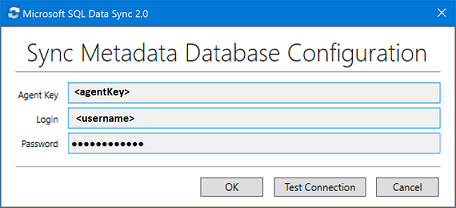
동기화 메타데이터 데이터베이스 구성 대화 상자에 Azure Portal에서 복사된 에이전트 키를 붙여 넣습니다. 또한 동기화 메타데이터 데이터베이스 데이터베이스가 있는 서버에 대한 기존 자격 증명을 제공합니다. 확인을 선택하고 구성 완료를 기다립니다.
참고 항목
방화벽 오류가 발생하면 SQL Server 컴퓨터에서 들어오는 트래픽을 허용하도록 Azure에서 방화벽 규칙을 만듭니다. 포털 또는 SQL Server Management Studio(SSMS)에서 규칙을 수동으로 생성할 수 있습니다. SSMS에서 이름을
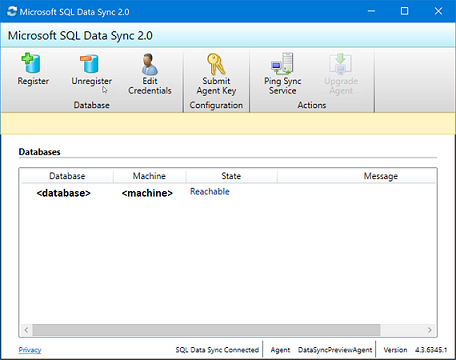
<hub_database_name>.database.windows.net으로 이름을 입력하여 Azure의 허브 데이터베이스에 연결합니다.등록을 선택하여 에이전트에 SQL Server 데이터베이스를 등록합니다. SQL Server에 연결 대화 상자가 열립니다.
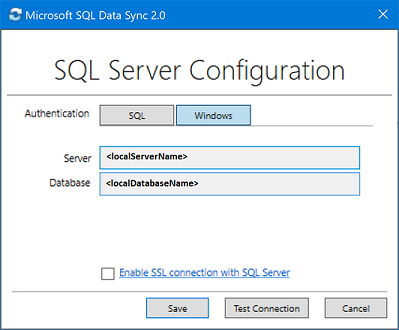
SQL Server 구성 대화 상자에서 SQL Server 인증 또는 Windows 인증을 사용하여 연결하도록 선택합니다. SQL Server 인증을 선택하는 경우 기존 자격 증명을 입력합니다. 동기화할 SQL Server 이름 및 데이터베이스의 이름을 제공하고 연결 테스트를 선택하여 설정을 테스트합니다. 그런 다음, 저장을 선택하면 등록된 데이터베이스가 목록에 표시됩니다.
클라이언트 동기화 에이전트 앱을 닫습니다.
Azure Portal의 온-프레미스 구성 페이지에서 데이터베이스 선택을 선택합니다.
데이터베이스 선택 페이지의 동기화 구성원 이름 필드에서 새 동기화 구성원의 이름을 제공합니다. 이 이름은 데이터베이스 이름과 다릅니다. 목록에서 데이터베이스를 선택합니다. 동기화 방향 필드에서 양방향 동기화, 허브로 또는 허브에서를 선택합니다.
확인을 선택하여 데이터베이스 선택 페이지를 닫습니다. 그런 다음, 확인을 선택하여 온-프레미스 구성 페이지를 닫고 새 동기화 구성원을 생성하고 배포할 때까지 기다립니다. 마지막으로 확인을 선택하여 동기화 구성원 선택 페이지를 닫습니다.
참고 항목
SQL 데이터 동기화 및 로컬 에이전트에 연결하려면 DataSync_Executor 역할에 사용자 이름을 추가합니다. 데이터 동기화는 SQL Server 인스턴스에서 이 역할을 생성합니다.
동기화 그룹 구성
새 동기화 그룹 구성원을 생성하고 배포한 후 데이터베이스 동기화 그룹 페이지의 테이블 섹션으로 이동합니다.
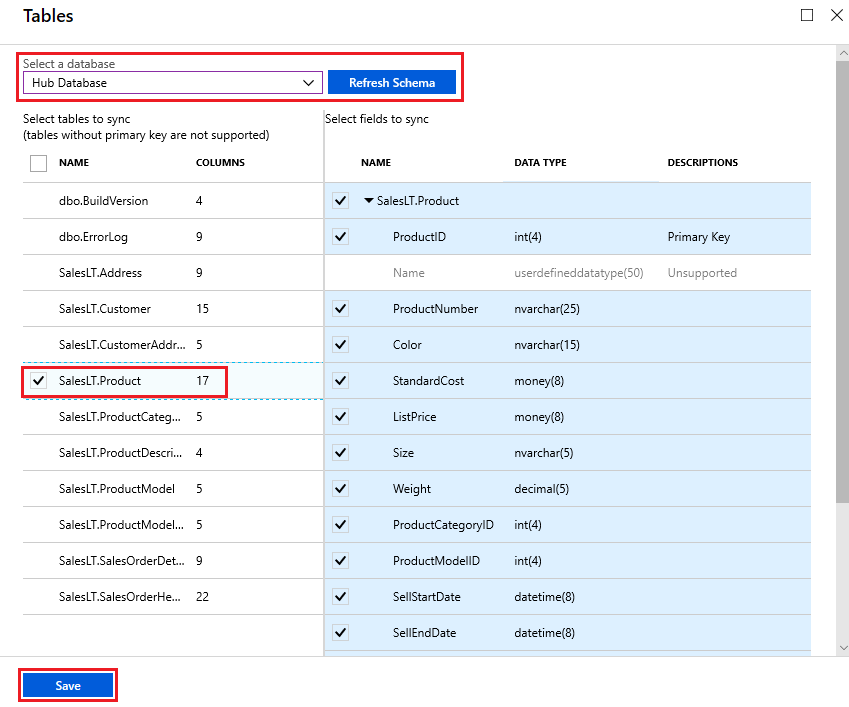
테이블 페이지의 동기화 그룹 구성원 목록에서 데이터베이스를 선택하고 스키마 새로 고침을 선택합니다. 스키마 새로 고침에서 몇 분 정도 지연이 예상되며, 프라이빗 링크를 사용할 경우 몇 분 정도 더 지연될 수 있습니다.
목록에서 동기화할 테이블을 선택합니다. 기본적으로 모든 열이 선택되어 있으므로 동기화하지 않을 열에 대한 확인란을 사용하지 않도록 설정합니다. 기본 키 열이 선택된 그대로 두는 것이 중요합니다.
저장을 선택합니다.
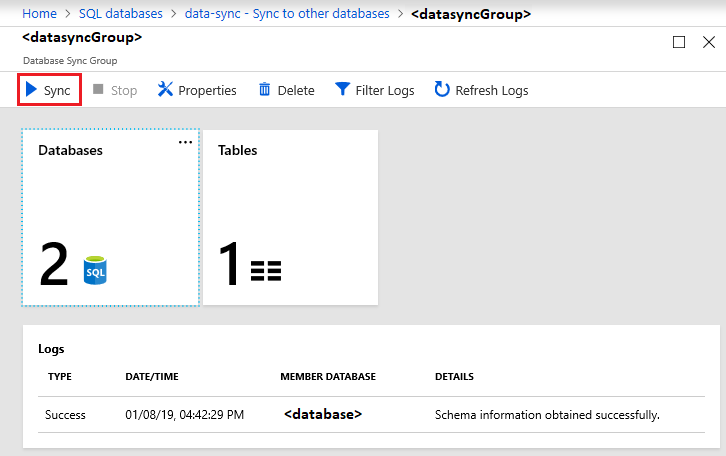
데이터베이스는 동기화를 예약하거나 수동으로 실행할 때까지 기본적으로 동기화되지 않습니다. 수동 동기화를 실행하려면 Azure Portal의 SQL Database에서 데이터베이스로 이동하고 다른 데이터베이스에 동기화를 선택한 후 동기화 그룹을 선택합니다. 데이터 동기화 페이지가 열립니다. 동기화를 선택합니다.
FAQ
이 섹션에서는 Azure SQL 데이터 동기화 서비스에 대한 질문과 대답을 제공합니다.
SQL 데이터 동기화가 테이블을 완벽하게 생성하나요?
대상 데이터베이스에서 동기화 스키마 테이블이 누락되어 있으면 SQL 데이터 동기화에서는 사용자가 선택한 열로 누락된 테이블을 만듭니다. 그러나 다음과 같은 이유로 전체 충실도의 스키마는 생성되지 않습니다.
- 대상 테이블에서는 사용자가 선택한 열만 생성됩니다. 선택하지 않은 열은 무시됩니다.
- 대상 테이블에서는 선택한 열 인덱스만 생성됩니다. 선택하지 않은 열의 인덱스는 무시됩니다.
- XML 형식 열의 인덱스는 생성되지 않습니다.
- CHECK 제약 조건은 생성되지 않습니다.
- 원본 테이블의 트리거는 생성되지 않습니다.
- 보기 및 저장 프로시저는 생성되지 않습니다.
이러한 제한 때문에 다음이 권장됩니다.
- 프로덕션 환경에서는 완전히 충실한 스키마를 직접 생성합니다.
- 서비스로 실험을 할 때는 자동 프로비저닝 기능을 사용합니다.
내가 생성하지 않은 테이블이 표시되는 이유는 무엇인가요?
데이터 동기화는 변경 내용 추적을 위해 데이터베이스에 추가 테이블을 만듭니다. 이러한 항목을 삭제하지 마세요. 데이터 동기화 작동이 중지됩니다.
동기화 후 내 데이터가 수렴되나요?
반드시 그런 것은 아닙니다. 허브 하나와 스포크 3개(A, B, C)가 포함된 동기화 그룹에서 허브->A/B/C로 동기화가 진행되는 경우 허브->A로의 동기화 후에 데이터베이스 A를 변경하면 다음 동기화 작업이 진행될 때까지 해당 변경 내용이 데이터베이스 B나 C에 기록되지 않습니다.
동기화 그룹으로 스키마 변경 내용을 가져오려면 어떻게 해야 하나요?
스키마를 변경하고 모든 변경 내용을 수동으로 전파합니다.
- 스키마 변경 내용을 허브 및 모든 동기화 구성원에 수동으로 복제합니다.
- 동기화 스키마를 업데이트합니다.
새 테이블 및 열을 추가하는 경우:
새 테이블과 열은 현재 동기화에 영향을 주지 않으며 데이터 동기화는 동기화 스키마에 테이블과 열이 추가될 때까지 이를 무시합니다. 새 데이터베이스 개체를 추가할 때는 다음 순서를 따르세요.
- 허브 및 모든 동기화 구성원에 새 테이블 또는 열을 추가합니다.
- 동기화 스키마에 새 테이블 또는 열을 추가합니다.
- 새 테이블 및 열에 값을 삽입하기 시작합니다.
열의 데이터 형식을 변경하는 방법:
기존 열의 데이터 형식을 변경하는 경우 새 값이 동기화 스키마에 정의된 원래 데이터 형식에 맞는 한 데이터 동기화는 계속 작동합니다. 예를 들어, 원본 데이터베이스의 데이터 형식을 int에서 bigint로 변경할 경우, int 데이터 형식에 비해 너무 큰 값을 삽입하기 전까지는 데이터 동기화가 계속 작동합니다. 변경을 완료하려면 스키마 변경 사항을 허브 및 모든 동기화 구성원에 수동으로 복제한 다음, 동기화 스키마를 업데이트합니다.
데이터 동기화 사용하여 데이터베이스를 내보내고 가져오려면 어떻게 해야 하나요?
데이터베이스를 .bacpac 파일로 내보내고 데이터베이스를 생성하기 위해 파일을 가져온 후에 새 데이터베이스에서 데이터 동기화를 사용하도록 다음 작업을 수행합니다.
- Data Sync complete cleanup.sql을 사용하여 새 데이터베이스에서 데이터 동기화 개체와 추가 테이블을 정리합니다. 스크립트는 데이터베이스에서 필요한 모든 데이터 동기화 개체를 삭제합니다.
- 새 데이터베이스를 사용하여 동기화 그룹을 다시 생성합니다. 이전 동기화 그룹이 더 이상 필요하지 않으면 삭제합니다.
클라이언트 에이전트에 대한 정보는 어디서 확인할 수 있나요?
클라이언트 에이전트에 대한 질문과 답변은 에이전트 FAQ를 참조하세요.
링크를 사용하려면 먼저 수동으로 링크를 승인해야 하나요?
예. 동기화 그룹 배포 중에 또는 PowerShell을 사용하여 Azure Portal의 프라이빗 엔드포인트 연결 페이지에서 서비스 관리형 프라이빗 엔드포인트를 수동으로 승인해야 합니다.
동기화 작업에서 Azure 데이터베이스를 프로비저닝할 때 방화벽 오류가 발생하는 이유는 무엇인가요?
이 문제는 Azure 리소스가 서버에 액세스할 수 없기 때문에 발생할 수 있습니다. 두 가지 해결 방법이 있습니다.
- Azure 데이터베이스의 방화벽에서 이 서버에 액세스할 수 있는 Azure 서비스 및 리소스 허용이 예로 설정되어 있는지 확인합니다. 자세한 내용은 Azure SQL Database 및 네트워크 액세스 제어를 참조하세요.
- Azure Private Link와 다른 데이터 동기화에 대한 프라이빗 링크를 구성합니다. 프라이빗 링크는 방화벽 뒤에 있는 데이터베이스와의 보안 연결을 사용하여 동기화 그룹을 생성하는 방법입니다. SQL 데이터 동기화 프라이빗 링크는 Microsoft 관리형 엔드포인트로, 내부적으로 기존 가상 네트워크 안에 서브넷을 생성하므로 다른 가상 네트워크 또는 서브넷을 생성할 필요가 없습니다.
다음 단계
축하합니다! Azure SQL Database와 SQL Server 데이터베이스를 모두 포함하는 동기화 그룹을 생성했습니다.
SQL 데이터 동기화에 대한 자세한 내용은 다음을 참조하세요.
- Azure SQL 데이터 동기화는 무엇인가요?
- Azure SQL 데이터 동기화용 데이터 동기화 에이전트
- 모범 사례 및 Azure SQL 데이터 동기화 관련 문제를 해결하는 방법
- Azure Monitor 로그를 사용하여 SQL 데이터 동기화 모니터링
- Transact-SQL 또는 PowerShell을 사용하여 동기화 스키마 업데이트
SQL Database에 대한 자세한 내용은 다음을 참조하세요.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기