Azure SQL Database의 데이터베이스에 대한 파일 공간 관리
적용 대상: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
이 문서에서는 Azure SQL Managed Instance의 데이터베이스에서 파일을 모니터링 및 관리하는 방법을 설명합니다. 데이터베이스 파일 크기를 모니터링하고, 트랜잭션 로그를 축소하며, 트랜잭션 로그 파일을 확대하고, 트랜잭션 로그 파일의 증가를 제어하는 방법을 검토합니다.
이 문서는 Azure SQL Managed Instance에 적용됩니다. 매우 유사하지만 SQL Server에서 트랜잭션 로그 파일의 크기를 관리하는 방법에 대한 자세한 내용은 트랜잭션 로그 파일의 크기 관리를 참조하세요.
데이터베이스의 스토리지 공간 유형 이해
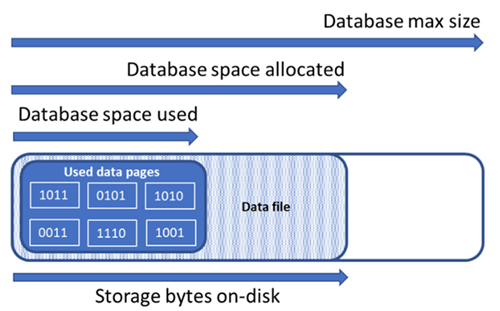
다음 스토리지 공간 수량을 이해하는 것은 데이터베이스의 파일 공간을 관리하는 데 중요합니다.
| 데이터베이스 수량 | 정의 | 주석 |
|---|---|---|
| 사용된 데이터 공간 | 데이터베이스 데이터를 저장하는 데 사용되는 공간 크기입니다. | 일반적으로 사용된 공간은 삽입(삭제) 시 증가(감소)합니다. 작업 및 조각화와 관련된 데이터의 크기 및 패턴에 따라 삽입 또는 삭제 시 사용된 공간이 변경되지 않는 경우가 있습니다. 예를 들어 모든 데이터 페이지에서 하나의 행을 삭제한다고 해서 사용된 공간이 반드시 감소하지는 않습니다. |
| 할당된 데이터 공간 | 데이터베이스 데이터 저장에 사용할 수 있는 형식화된 파일 공간의 크기입니다. | 할당된 공간의 크기는 자동으로 증가하지만 삭제 후에는 감소하지 않습니다. 이 동작은 공간을 다시 형식화할 필요가 없기 때문에 향후 삽입이 더 빨라질 수 있습니다. |
| 할당되었지만 사용되지 않은 데이터 공간 | 할당된 데이터 공간의 크기와 사용된 데이터 공간 간의 차이입니다. | 이 수량은 데이터베이스 데이터 파일을 축소하면 회수할 수 있는 사용 가능한 공간의 최대 크기를 나타냅니다. |
| 데이터 최대 크기 | 데이터베이스 데이터 저장에 사용할 수 있는 최대 공간의 크기입니다. | 할당된 데이터 공간 크기는 데이터 최대 크기를 초과할 수 없습니다. |
다음 다이어그램에서는 데이터베이스에 대한 여러 스토리지 공간 유형 간의 관계를 보여줍니다.
파일 공간 정보를 위해 단일 데이터베이스 쿼리
sys.database_files에 대한 다음 쿼리를 사용하여 할당 데이터베이스 파일 공간 크기 및 사용하지 않은 할당 공간 크기를 반환합니다. 쿼리 결과의 단위는 MB입니다.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
로그 공간 사용 모니터링
sys.dm_db_log_space_usage를 사용하여 로그 공간 사용을 모니터링합니다. 이 DMV는 현재 사용된 로그 공간 크기에 대한 정보를 반환하고 트랜잭션 로그 잘림을 수행해야 하는 시기를 나타냅니다.
현재 로그 파일 크기 및 최대 크기, 파일의 자동 증가 옵션에 대한 자세한 내용을 보기 위해 sys.database_files의 해당 로그 파일에 대한 size, max_size, growth 열을 사용할 수도 있습니다.
Azure Resource Manager 기반 메트릭 API에 표시되는 스토리지 공간 메트릭은 사용된 데이터 페이지의 크기만 측정합니다. 예를 들어, PowerShell get-metrics를 참조하세요.
로그 파일 크기 축소
실제 로그 파일의 실제 크기를 줄이려면 사용하지 않는 공간을 제거함으로써 로그 파일을 축소합니다. 축소는 트랜잭션 로그 파일에 사용되지 않는 공간이 포함된 경우에만 차이가 납니다. 열린 트랜잭션으로 인해 로그 파일이 가득 차면 트랜잭션 로그 자름을 차단하는 원인을 조사합니다.
주의
축소 작업을 정기적인 유지 관리 작업으로 간주해서는 안 됩니다. 반복되는 일상 업무에 따라 증가하는 데이터와 로그 파일은 축소 작업이 필요하지 않습니다. 축소 명령은 실행하는 동안 데이터베이스 성능에 영향을 주므로, 가능하면 사용량이 낮은 기간 동안 실행해야 합니다. 일반 애플리케이션 워크로드로 인해 파일이 동일한 할당된 크기로 다시 증가하는 경우 데이터 파일을 축소하지 않는 것이 좋습니다.
데이터베이스 파일 축소가 성능에 부정적인 영향을 미칠 수 있음을 알고 있어야 합니다. 축소 후 인덱스 유지 관리를 참조하세요. 드물게 축소 작업은 자동화된 데이터베이스 백업의 영향을 받을 수 있습니다. 필요한 경우 축소 작업을 다시 시도합니다.
트랜잭션 로그를 줄이기 전에 로그 잘림을 지연시킬 수 있는 요소를 염두에 두세요. 로그 축소 후 스토리지 공간이 다시 필요하면 트랜잭션 로그가 다시 커지고 로그 확장 작업 중에 성능 오버헤드가 발생합니다. 자세한 내용은 권장 사항을 참조하세요.
데이터베이스가 온라인 상태이고 하나 이상의 가상 로그 파일(VLF)에 여유 공간이 있는 경우에만 로그 파일을 축소할 수 있습니다. 경우에 따라 다음에 로그가 잘릴 때까지 로그를 축소하지 못할 수도 있습니다.
장기 실행 트랜잭션과 같이 오랜 시간 동안 VLF를 활성 상태로 유지하는 요인으로 인해 로그 축소가 제한되거나 로그가 전혀 축소되지 못할 수 있습니다. 자세한 내용은 로그 잘림을 지연시킬 수 있는 요소를 참조하세요.
로그 파일을 축소하면 논리 로그 부분이 포함되지 않은 하나 이상의 VLF(비활성 VLF)가 제거됩니다. 트랜잭션 로그 파일을 축소하면 비활성 VLF가 로그 파일의 끝에서 제거되어 로그가 대략적인 대상 크기로 줍니다.
축소 작업에 대한 자세한 내용은 다음을 검토하세요.
로그 파일 축소(데이터베이스 파일의 축소 없이)
로그 파일 축소 이벤트 모니터링
로그 공간 모니터링
sys.database_files(Transact-SQL)(로그 파일의
size,max_size및growth열 참조)
축소 후 인덱스 유지 관리
데이터 파일에 대한 축소 작업이 완료되면 인덱스가 조각화될 수 있습니다. 이로 인해 대규모 검사를 사용하는 쿼리와 같은 특정 워크로드에 대한 성능 최적화 효과가 줄어듭니다. 축소 작업 완료 후 성능 저하가 발생하면 인덱스 유지 관리를 통해 인덱스를 다시 빌드하는 것을 고려해 봅니다. 인덱스를 다시 빌드하려면 데이터베이스에 사용 가능한 공간이 필요하므로 할당된 공간이 증가하여 축소 효과가 무효화될 수 있습니다.
인덱스 유지 관리에 대한 자세한 내용은 쿼리 성능 향상 및 리소스 소비 감소를 위한 인덱스 유지 관리 최적화를 참조하세요.
인덱스 페이지 밀도 평가
데이터 파일을 잘라도 할당된 공간이 충분히 줄어들지 않으면 해당 파일에서 사용하지 않는 공간을 회수하여 데이터베이스 데이터 파일을 축소해야 할 수 있습니다. 그러나 선택적이지만 권장되는 단계로, 먼저 데이터베이스의 인덱스에 대한 평균 페이지 밀도를 결정해야 합니다. 동일한 양의 데이터의 경우 페이지 밀도가 높으면 더 적은 수의 페이지를 이동해야 하므로 축소가 더 빠르게 완료됩니다. 일부 인덱스에 대한 페이지 밀도가 낮은 경우 먼저 이러한 인덱스에 대한 유지 관리를 수행하여 페이지 밀도를 높인 후에 데이터 파일을 축소하는 것이 좋습니다. 이렇게 하면 축소가 할당된 스토리지 공간을 더 많이 줄일 수도 있습니다.
데이터베이스의 모든 인덱스에 대한 페이지 밀도를 확인하려면 다음 쿼리를 사용합니다. 페이지 밀도는 avg_page_space_used_in_percent 열에 보고됩니다.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
페이지 밀도가 60~70% 미만인 페이지의 수가 많은 인덱스가 있는 경우 데이터 파일을 축소하기 전에 이러한 인덱스를 다시 빌드하거나 다시 구성하는 것이 좋습니다.
참고 항목
더 큰 데이터베이스의 경우 페이지 밀도를 확인하기 위한 쿼리를 완료하는 데 오래(몇 시간) 걸릴 수 있습니다. 또한 큰 인덱스를 다시 빌드하거나 다시 구성하려면 상당한 시간과 리소스 사용량이 필요합니다. 한편으로 페이지 밀도를 높이는 데 추가 시간을 소비하고 다른 한편으로 축소 기간을 줄이고 더 높은 공간 절약을 달성하는 것 사이에는 절충점이 있습니다.
페이지 밀도가 낮은 인덱스가 여러 개 있는 경우 여러 데이터베이스 세션에서 인덱스를 병렬로 다시 빌드하여 프로세스 속도를 높일 수 있습니다. 그러나 이 작업을 수행하여 데이터베이스 리소스 제한에 도달하지 않는지 확인하고 애플리케이션 워크로드에 충분한 리소스 가용 공간을 확보합니다. Azure Portal 또는 sys.dm_db_resource_stats 보기를 사용하여 리소스 사용량(CPU, 데이터 I/O, 로그 I/O)을 모니터링하고, 이러한 각 차원의 리소스 사용률이 100%보다 훨씬 낮게 유지되는 경우에만 추가 병렬 다시 빌드를 시작합니다. CPU, 데이터 I/O 또는 로그 I/O 사용률이 100%인 경우 더 많은 CPU 코어를 확보하고 I/O 처리량을 늘리도록 데이터베이스를 스케일 업하여 추가 병렬 다시 빌드를 통해 프로세스를 더 빨리 완료할 수 있습니다.
샘플 인덱스 다시 빌드 명령
ALTER INDEX 문을 사용하여 인덱스를 다시 빌드하고 해당 페이지의 밀도를 높이는 샘플 명령은 다음과 같습니다.
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
이 명령은 온라인 및 다시 시작 가능한 인덱스 다시 빌드를 시작합니다. 이렇게 하면 다시 빌드가 진행되는 동안 동시 워크로드에서 테이블을 계속 사용할 수 있으며, 어떤 이유로든 중단된 경우 다시 빌드를 다시 시작할 수 있습니다. 그러나 이 유형의 다시 빌드는 테이블에 대한 액세스를 차단하는 오프라인 다시 빌드보다 느립니다. 다시 빌드하는 동안 다른 워크로드에서 테이블에 액세스할 필요가 없는 경우 ONLINE 및 RESUMABLE 옵션을 OFF로 설정하고 WAIT_AT_LOW_PRIORITY 절을 제거합니다.
인덱스 유지 관리에 대한 자세한 내용은 쿼리 성능 향상 및 리소스 소비 감소를 위한 인덱스 유지 관리 최적화를 참조하세요.
여러 데이터 파일 축소
앞에서 설명한 대로 데이터 이동을 통한 축소는 장기 프로세스입니다. 데이터베이스에 여러 데이터 파일이 있는 경우 여러 데이터 파일을 병렬로 축소하여 프로세스 속도를 높일 수 있습니다. 이 작업은 여러 데이터베이스 세션을 열고 각 세션에서 file_id 값이 다른 DBCC SHRINKFILE을 사용하여 수행합니다. 이전에 인덱스를 다시 빌드하는 경우와 마찬가지로 먼저 충분한 리소스 가용 공간(CPU, 데이터 I/O, 로그 I/O)이 있는지 확인한 후에 새 병렬 축소 명령을 시작해야 합니다.
다음 샘플 명령은 파일 내에서 페이지를 이동하여 file_id가 4인 데이터 파일을 축소해 할당된 크기를 52,000MB로 줄이려고 시도합니다.
DBCC SHRINKFILE (4, 52000);
파일에 할당된 공간을 가능한 최소로 줄이려면 대상 크기를 지정하지 않고 다음 명령문을 실행합니다.
DBCC SHRINKFILE (4);
워크로드가 축소와 함께 동시에 실행되는 경우 축소가 완료되고 파일이 잘리기 전에 축소를 통해 확보된 스토리지 공간의 사용을 시작할 수 있습니다. 이 경우 축소는 지정된 대상에 할당된 공간을 줄일 수 없습니다.
이는 각 파일을 더 작은 단계로 축소하여 완화할 수 있습니다. 즉, DBCC SHRINKFILE 명령에서 파일에 대해 현재 할당된 공간보다 약간 작은 대상을 설정합니다. 예를 들어 file_id가 4인 파일에 할당된 공간이 200,000MB이고 이를 100,000MB로 축소하려는 경우 먼저 대상을 170,000MB로 설정할 수 있습니다.
DBCC SHRINKFILE (4, 170000);
이 명령이 완료되면 파일이 잘리고 할당된 크기가 170,000MB로 줄어듭니다. 그러면 파일이 원하는 크기로 축소될 때까지 먼저 대상을 140,000MB로 설정하고, 다음으로 110,000MB 등으로 설정하면서 이 명령을 반복할 수 있습니다. 명령이 완료되었지만 파일이 잘리지 않은 경우 더 작은 단계(예: 30,000MB가 아닌 15,000MB)를 사용합니다.
동시에 실행되는 모든 축소 세션에 대한 축소 진행률을 모니터링하려면 다음 쿼리를 사용할 수 있습니다.
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
참고 항목
축소 진행률은 비선형일 수 있으며, 축소가 아직 진행 중인 경우에도 percent_complete 열의 값이 오랜 기간 동안 거의 변경되지 않은 상태로 유지될 수 있습니다.
모든 데이터 파일에 대한 축소가 완료되면 공간 사용량 쿼리를 사용하여 할당된 스토리지 크기가 감소되었는지 확인합니다. 사용된 공간과 할당된 공간 사이에 여전히 큰 차이가 있는 경우 인덱스를 다시 빌드할 수 있습니다. 이렇게 하면 할당된 공간이 일시적으로 더 늘어날 수 있지만, 인덱스를 다시 빌드한 후 데이터 파일을 다시 축소하면 할당된 공간이 더 많이 줄어듭니다.
로그 파일 확대
Azure SQL Managed Instance에서 기존 로그 파일을 확대하여(디스크 공간이 허용되는 경우) 로그 파일에 공간을 추가합니다. 데이터베이스에 로그 파일 추가는 지원되지 않습니다. 로그 공간이 부족하고 로그 파일을 보관하는 볼륨에 디스크 공간이 부족한 경우가 아니라면 하나의 트랜잭션 로그 파일로 충분합니다.
로그 파일을 확대하려면 ALTER DATABASE 문의 MODIFY FILE 절을 사용하여 SIZE 및 MAXSIZE 구문을 지정합니다. 자세한 내용은 ALTER DATABASE(Transact-SQL) 파일 및 파일 그룹 옵션을 참조하세요.
자세한 내용은 권장 사항을 참조하세요.
트랜잭션 로그 파일 증가 제어
트랜잭션 로그 파일의 증가를 관리하기 위해 ALTER DATABASE(Transact-SQL) 파일 및 파일 그룹 옵션 문을 사용합니다. 다음 사항에 유의하세요.
- 현재 파일의 크기(KB, MB, GB 및 TB 단위)를 변경하려면
SIZE옵션을 사용합니다. - 증분을 변경하려면
FILEGROWTH옵션을 사용합니다. 값 0은 자동 증가를 사용하지 않고 추가 공간을 허용하지 않음을 나타냅니다. - 로그 파일의 최대 크기(KB, MB, GB, TB 단위)를 제어하거나 증가를 UNLIMITED로 설정하려면
MAXSIZE옵션을 사용합니다.
권장 사항
다음은 트랜잭션 로그 파일 작업 시 일반적으로 권장되는 사항입니다.
FILEGROWTH옵션으로 설정된 대로 트랜잭션 로그의 자동 증가(자동 증가) 증분은 워크로드 트랜잭션의 요구를 앞설 수 있도록 커야 합니다. 로그 파일의 파일 증가분이 충분히 커야 자주 확장하는 번거로움을 피할 수 있습니다. 트랜잭션 로그의 크기를 적절히 조정하는 좋은 방법은 다음과 같은 시간 동안 사용된 로그의 양을 모니터링하는 것입니다.- 완료될 때까지 로그를 백업할 수 없기 때문에 전체 백업을 실행하는 데 필요한 시간.
- 가장 큰 인덱스 유지 보수 작업에 필요한 시간.
- 데이터베이스에서 가장 큰 일괄 처리를 실행하는 데 필요한 시간.
FILEGROWTH옵션을 사용하여 데이터 및 로그 파일에 대해 자동 증가를 설정한 경우, 백분율은 계속 증가하는 양이기 때문에percentage대신size에서 설정하는 것이 확장률을 더 잘 제어할 수 있습니다.- Azure SQL Managed Instance에서 인스턴트 파일 초기화를 통해 최대 64MB의 트랜잭션 로그 증가 이벤트를 지원할 수 있습니다. 새 데이터베이스의 기본 자동 증가 크기 증분은 64MB입니다. 64MB보다 큰 트랜잭션 로그 파일 자동 증가 이벤트는 즉시 파일 초기화의 이점을 얻을 수 없습니다.
- 모범 사례에서는 트랜잭션 로그에 대해
FILEGROWTH옵션 값을 1,024MB 이상으로 설정하지 않습니다.
작은 자동 증가 증분에서는 너무 많은 VLF가 생성되어 성능이 저하될 수 있습니다. 지정된 인스턴스에 있는 모든 데이터베이스의 현재 트랜잭션 로그 크기에 대한 최적의 VLF 분포 및 필수 크기가 달성되도록 필수 증가 증분을 결정하려면 SQL Tiger Team에서 제공하는 VFL 분석 및 수정용 스크립트를 참조하세요.
큰 자동 증가 증분으로 인해 두 가지 문제가 발생할 수 있습니다.
- 큰 자동 증가 증분으로 인해 새 공간이 할당되는 동안 데이터베이스가 일시 중지되어 쿼리 제한 시간이 초과될 수 있습니다.
- 큰 자동 증가 증분에서 너무 적고 큰 VLF를 생성하여 성능도 영향을 받을 수 있습니다. 지정된 인스턴스에 있는 모든 데이터베이스의 현재 트랜잭션 로그 크기에 대한 최적의 VLF 분포 및 필수 크기가 달성되도록 필수 증가 증분을 결정하려면 SQL Tiger Team에서 제공하는 VFL 분석 및 수정용 스크립트를 참조하세요.
자동 증가를 사용하는 경우에도 쿼리의 요구 사항을 충족시킬 정도로 빠르게 커질 수 없는 경우 트랜잭션 로그가 꽉 찼다는 메시지를 받을 수 있습니다. 증가 증분 변경에 대한 자세한 내용은 ALTER DATABASE(Transact-SQL) 파일 및 파일 그룹 옵션을 참조하세요.
로그 파일은 자동으로 축소되도록 설정할 수 있습니다. 그러나 이것은 권장되지 않으며auto_shrink 데이터베이스 속성은 기본적으로 FALSE로 설정됩니다. auto_shrink를 TRUE로 설정하면 파일 공간의 25% 이상이 사용되지 않을 때만 자동 축소에 의해 파일 크기가 줄어듭니다.
- 파일은 파일의 25%만 사용되지 않을 때의 크기 또는 파일의 원래 크기 중 더 큰 크기로 축소됩니다.
- auto_shrink 속성의 설정 변경에 대한 자세한 내용은 데이터베이스의 속성 보기 또는 변경 또는 ALTER DATABASE SET 옵션(Transact-SQL)을 참조하세요.