Azure Data Lake Storage Gen2의 액세스 제어 및 데이터 레이크 구성
이 문서는 Azure Data Lake Storage Gen2의 액세스 제어 메커니즘을 평가하고 이해하는 데 도움이 됩니다. 이러한 메커니즘에는 Azure RBAC(역할 기반 액세스 제어) 및 ACL(액세스 제어 목록)이 포함됩니다. 이 문서에서 학습할 내용은 다음과 같습니다.
- Azure RBAC와 ACL 간의 액세스를 평가하는 방법
- 이러한 메커니즘 중 하나 또는 둘 다를 사용하여 액세스 제어를 구성하는 방법
- 데이터 레이크 구현 패턴에 액세스 제어 메커니즘을 적용하는 방법
스토리지 컨테이너, 보안 그룹, Azure RBAC 및 ACL에 대한 기본 지식이 필요합니다. 토론을 구성하기 위해 원시 영역, 보강 영역, 큐레이팅된 영역으로 이루어진 일반 데이터 레이크 구조를 참조합니다.
이 문서는 데이터 액세스 관리와 함께 사용할 수 있습니다.
기본 제공 Azure RBAC 역할 사용
Azure Storage에는 서비스 관리와 데이터 등 두 가지 액세스 레이어가 있습니다. 서비스 관리 계층을 통해 구독 및 스토리지 계정에 액세스할 수 있습니다. 데이터 계층을 통해 컨테이너, Blob 및 기타 데이터 리소스에 액세스합니다. 예를 들어 Azure에서 스토리지 계정 목록을 원하는 경우 관리 엔드포인트에 요청을 보냅니다. 스토리지 계정의 파일 시스템, 폴더 또는 파일 목록을 원하는 경우 서비스 엔드포인트에 요청을 보냅니다.
역할에는 관리 또는 데이터 레이어 액세스에 대한 권한이 포함될 수 있습니다. 읽기 권한자 역할은 관리 레이어 리소스에 대한 읽기 전용 액세스 권한을 부여하지만 데이터에 대한 읽기 권한은 부여하지 않습니다.
소유자, 기여자, 읽기 권한자 및 스토리지 계정 기여자와 같은 역할은 보안 주체가 스토리지 계정을 관리할 수 있도록 허용합니다. 그러나 해당 계정의 데이터에 대한 액세스는 제공하지 않습니다. 데이터 액세스에 대해 명시적으로 정의된 역할만 보안 주체가 데이터에 액세스할 수 있도록 허용합니다. 읽기 권한자를 제외한 이러한 역할은 스토리지 키에 액세스하여 데이터에 액세스합니다.
기본 제공 관리 역할
다음은 기본 제공 관리 역할입니다.
- 소유자: 리소스에 대한 액세스를 포함하여 모든 것을 관리합니다. 이 역할은 키 액세스를 제공합니다.
- 참가자: 리소스에 대한 액세스를 제외한 모든 것을 관리합니다. 이 역할은 키 액세스를 제공합니다.
- 스토리지 계정 기여자: 스토리지 계정의 전체 관리. 이 역할은 키 액세스를 제공합니다.
- 읽기 권한자: 리소스를 읽고 나열합니다. 이 역할은 키 액세스를 제공하지 않습니다.
기본 제공 데이터 역할
다음은 기본 제공 데이터 역할입니다.
- 스토리지 Blob 데이터 소유자: 소유권 설정 및 POSIX 액세스 제어 관리를 포함하여 Azure Storage Blob 컨테이너 및 데이터에 대한 모든 액세스.
- Storage Blob 데이터 기여자: Azure Storage 컨테이너 및 Blob을 읽고, 쓰고, 삭제합니다.
- Storage Blob 데이터 판독기: Azure Storage 컨테이너 및 Blob을 읽고 나열합니다.
Storage Blob 데이터 소유자는 모든 변경 작업에 대한 모든 액세스 권한을 부여하는 슈퍼 사용자 역할입니다. 이러한 작업에는 디렉터리 또는 파일의 소유자를 설정하는 것과 이들이 소유자가 아닌 디렉터리와 파일에 대한 ACL을 설정하는 것이 포함됩니다. 슈퍼 사용자 액세스는 리소스 소유자를 변경할 수 있는 유일한 권한 있는 방식입니다.
참고 항목
Azure RBAC 할당을 전파하고 적용하는 데 최대 5분이 걸릴 수 있습니다.
액세스 평가 방법
보안 주체 기반 권한 부여 중에 시스템은 다음 순서로 권한을 평가합니다. 자세한 내용은 다음 다이어그램을 참조하세요.
- Azure RBAC가 먼저 평가되며 ACL 할당보다 우선합니다.
- RBAC에 따라 작업에 권한이 완전히 부여된 경우 ACL은 전혀 평가되지 않습니다.
- 작업에 권한이 완전히 부여되지 않은 경우 ACL이 평가됩니다.
자세한 내용은 사용 권한을 평가하는 방법을 참조하세요.
참고 항목
이 권한 모델은 Azure Data Lake Storage에만 적용됩니다. 계층 구조 네임스페이스를 사용하도록 설정하지 않은 경우 범용 또는 Blob Storage에는 적용되지 않습니다.
이 설명에서 공유 키 및 SAS 인증 방법은 제외됩니다. 또한 보안 주체에 슈퍼 사용자 액세스를 제공하는 Storage Blob 데이터 소유자 기본 제공 역할이 할당되는 시나리오도 제외됩니다.
ID에 의해 액세스가 감사되도록 false로 설정합니다 allowSharedKeyAccess .

지정된 작업에 필요한 ACL 기반 권한에 대한 자세한 내용은 Azure Data Lake Storage Gen2의 액세스 제어 목록을 참조하세요.
참고 항목
- 액세스 제어 목록은 게스트 사용자를 포함하여 동일한 테넌트의 보안 주체에만 적용됩니다.
- 클러스터에 연결할 수 있는 권한이 있는 모든 사용자는 Azure Databricks 탑재 지점을 만들 수 있습니다. 서비스 주체 자격 증명 또는 Microsoft Entra 통과 옵션을 사용하여 탑재 지점을 구성합니다. 생성 시 사용 권한은 평가되지 않습니다. 사용 권한은 작업에서 탑재 지점을 사용할 때 평가됩니다. 클러스터에 연결할 수 있는 모든 사용자는 탑재 지점을 사용하려고 시도할 수 있습니다.
- 사용자가 Azure Databricks 또는 Azure Synapse Analytics에서 테이블 정의를 만들 때 기본 데이터에 대한 읽기 권한이 있어야 합니다.
Azure Data Lake Storage에 대한 액세스 구성
Azure RBAC, ACL 또는 둘의 조합을 사용하여 Azure Data Lake Storage에서 액세스 제어를 설정합니다.
Azure RBAC만 사용하여 액세스 구성
컨테이너 수준 액세스 제어로 충분하면 Azure RBAC 할당은 데이터 보안에 대한 간단한 관리 방법을 제공합니다. 많은 수의 제한된 데이터 자산 또는 세분화된 액세스 제어가 필요한 위치에 액세스 제어 목록을 사용하는 것이 좋습니다.
ACL만 사용하여 액세스 구성
다음은 클라우드 규모 분석에 대한 구성 권장 사항을 나열하는 액세스 제어 목록입니다.
개별 사용자 또는 서비스 주체가 아닌 보안 그룹에 액세스 제어 항목을 할당합니다. 자세한 내용은 보안 그룹 대 개별 사용자 사용을 참조하세요.
그룹에서 사용자를 추가하거나 제거하는 경우 Data Lake Storage를 업데이트할 필요가 없습니다. 또한 그룹을 사용하면 파일 또는 폴더 ACL당 32개의 액세스 제어 항목을 초과할 가능성이 줄어듭니다. 네 가지 기본 항목 후에는 권한 할당에 대한 다시 기본 항목이 28개만 있습니다.
그룹을 사용하는 경우에도 디렉터리 트리의 최상위 수준에서 많은 액세스 제어 항목을 가질 수 있습니다. 이 상황은 다른 그룹에 대한 세분화된 권한이 필요한 경우에 발생합니다.

Azure RBAC 및 액세스 제어 목록을 모두 사용하여 액세스 구성
Storage Blob 데이터 참가자 및 Storage Blob 데이터 읽기 권한자는 스토리지 계정이 아니라 데이터에 대한 액세스를 제공합니다. 스토리지 계정 수준 또는 컨테이너 수준에서 액세스 권한을 부여할 수 있습니다. Storage Blob 데이터 기여자가 할당된 경우 ACL을 사용하여 액세스를 관리할 수 없습니다. Storage Blob 데이터 판독기를 할당하는 경우 ACL을 사용하여 상승된 쓰기 권한을 부여할 수 있습니다. 자세한 내용은 액세스 평가 방법을 참조하세요.
이 방법은 대부분의 사용자에게 읽기 액세스가 필요하지만 일부 사용자만 쓰기 액세스가 필요한 시나리오를 선호합니다. 데이터 레이크 영역은 서로 다른 스토리지 계정일 수 있으며 데이터 자산은 서로 다른 컨테이너일 수 있습니다. 데이터 레이크 영역은 폴더가 나타내는 컨테이너 및 데이터 자산으로 나타낼 수 있습니다.
중첩된 액세스 제어 목록 그룹 접근 방법
중첩된 ACL 그룹에는 두 가지 접근 방법이 있습니다.
옵션 1: 부모 실행 그룹
파일 및 폴더를 만들기 전에 부모 그룹으로 시작합니다. 컨테이너 수준에서 기본 ACL 및 액세스 ACL 모두에 해당 그룹 실행 권한을 할당합니다. 그런 다음 부모 그룹에 대한 데이터 액세스가 필요한 그룹을 추가합니다.
Warning
재귀 삭제가 있는 이 패턴에 대해 대신 옵션 2: 액세스 제어 목록 다른 항목을 사용하는 것이 좋습니다.
이 기술을 중첩 그룹이라고 합니다. 멤버 그룹은 모든 멤버 그룹에 전역 실행 권한을 제공하는 부모 그룹의 사용 권한을 상속합니다. 이러한 권한은 상속되므로 멤버 그룹에는 실행 권한이 필요하지 않습니다. 중첩이 많을수록 유연성과 민첩성이 향상될 수 있습니다. 팀 또는 자동화된 작업을 나타내는 보안 그룹을 데이터 액세스 읽기 권한자 및 쓰기 권한자 그룹에 추가합니다.
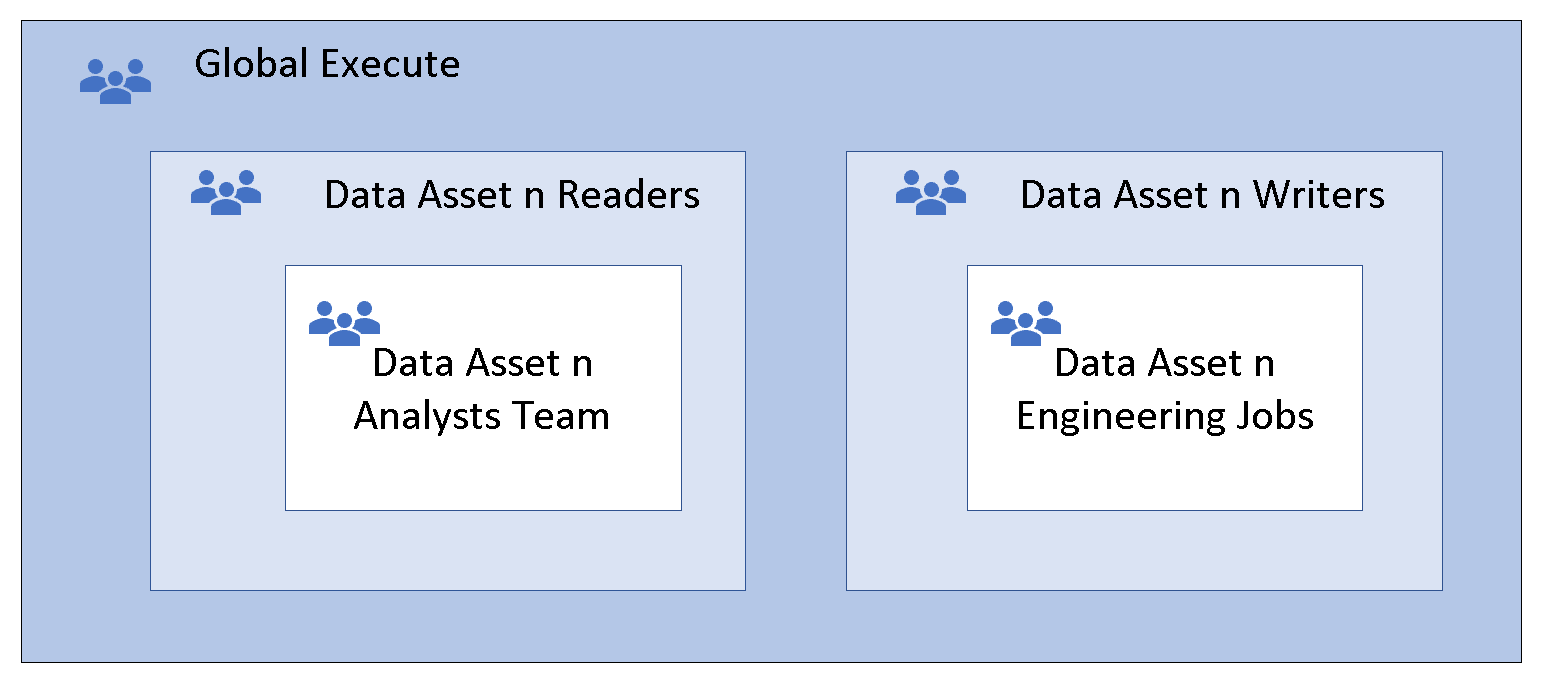
옵션 2: 액세스 제어 목록 기타 항목
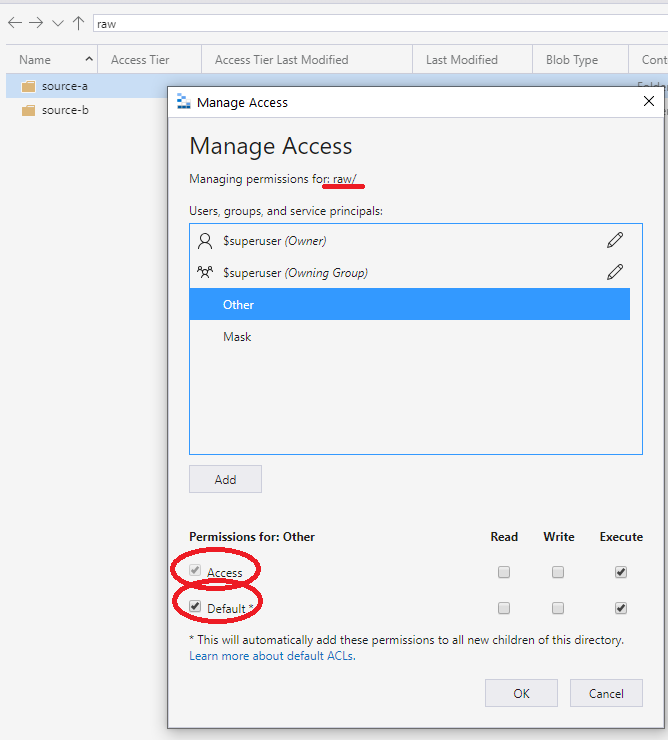
권장되는 방법은 컨테이너 또는 루트에서 ACL 기타 항목 집합을 사용하는 것입니다. 다음 화면에 표시된 대로 기본값을 지정하고 ACL에 액세스합니다. 이 방법을 사용하면 루트에서 최저 수준까지 경로의 모든 부분에 실행 권한이 있습니다.
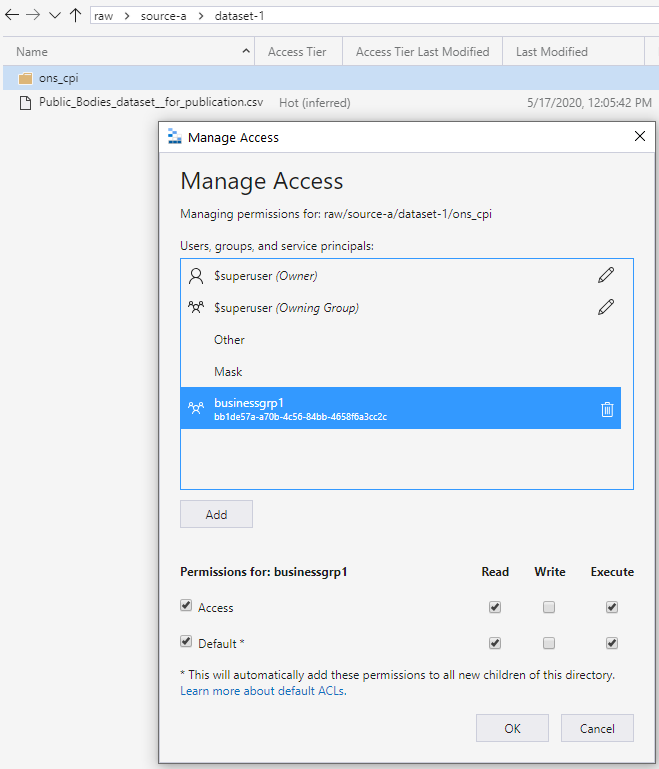
이 실행 권한은 추가된 모든 자식 폴더로 아래쪽으로 전파됩니다. 사용 권한은 의도한 액세스 그룹에 읽고 실행할 수 있는 권한이 필요한 깊이로 전파됩니다. 수준은 다음 화면에 표시된 것처럼 체인의 가장 낮은 부분에 있습니다. 이 방법은 데이터를 읽을 수 있는 액세스 권한을 그룹에 부여합니다. 이 방법은 쓰기 액세스와 유사하게 작동합니다.
권장되는 데이터 레이크 영역 보안
각 데이터 레이크 영역에 권장되는 보안 패턴은 다음과 같습니다.
- 원시는 SPN(보안 주체 이름)을 사용해야만 데이터에 액세스할 수 있습니다.
- 보강은 SPN(보안 주체 이름)을 사용해야만 데이터에 액세스할 수 있습니다.
- 큐레이팅은 SPN(보안 주체 이름) 및 UPN(사용자 계정 이름) 모두에 대한 액세스를 허용해야 합니다.
Microsoft Entra 보안 그룹을 사용하는 예제 시나리오
그룹을 설정하는 방법에는 여러 가지가 있습니다. 예를 들어 서버에서 생성한 로그 데이터를 보유하는 디렉터 /LogData 리가 있다고 상상해 보십시오. Azure Data Factory는 해당 폴더에 데이터를 수집합니다. 서비스 엔지니어링 팀의 특정 사용자는 로그를 업로드하고 이 폴더의 다른 사용자를 관리합니다. Azure Databricks 분석 및 데이터 과학 작업 영역 클러스터는 해당 폴더의 로그를 분석할 수 있습니다.
이러한 활동을 사용하도록 설정하려면 LogsWriter 그룹 및 LogsReader 그룹을 만듭니다. 다음 권한을 할당합니다.
rwx권한이 있는/LogData디렉터리의 ACL에LogsWriter그룹을 추가합니다.r-x권한이 있는/LogData디렉터리의 ACL에LogsReader그룹을 추가합니다.- Data Factory에 대한 서비스 주체 개체 또는 MSI(관리 서비스 ID)를
LogsWriters그룹에 추가합니다. - 서비스 엔지니어링 팀의 사용자를 그룹에 추가합니다
LogsWriter. - Azure Databricks는 Azure Data Lake 저장소에 대한 Microsoft Entra 통과에 대해 구성됩니다.
서비스 엔지니어링 팀의 사용자가 다른 팀으로 이전하는 경우 그룹에서 해당 사용자를 제거하면 LogsWriter 됩니다.
해당 사용자를 그룹에 추가하지 않고 대신 해당 사용자에 대한 전용 ACL 항목을 추가한 경우 디렉터리에서 /LogData 해당 ACL 항목을 제거해야 합니다. 또한 디렉터리의 전체 디렉터리 계층 /LogData 구조에 있는 모든 하위 디렉터리 및 파일에서 항목을 제거해야 합니다.
Azure Synapse Analytics 데이터 액세스 제어
Azure Synapse 작업 영역을 배포하려면 Azure Data Lake Storage Gen2 계정이 필요합니다. Azure Synapse Analytics는 여러 통합 시나리오에 기본 스토리지 계정을 사용하고 컨테이너에 데이터를 저장합니다. 컨테이너에는 /synapse/{workspaceName} 폴더 아래에 있는 애플리케이션 로그 및 Apache Spark 테이블이 포함됩니다. 또한 작업 영역에서는 설치하는 라이브러리를 관리하기 위해 컨테이너를 사용합니다.
Azure Portal을 통해 작업 영역을 배포하는 동안 기존 스토리지 계정을 제공하거나 새 스토리지 계정을 만듭니다. 제공된 스토리지 계정은 작업 영역의 기본 스토리지 계정입니다. 배포 프로세스는 Storage Blob 데이터 참가자 역할을 사용하여 지정된 Data Lake Storage Gen2 계정에 대한 액세스 권한을 작업 영역 ID에 부여합니다.
Azure Portal 외부에 작업 영역을 배포하는 경우 스토리지 Blob 데이터 기여자 역할에 Azure Synapse Analytics 작업 영역 ID를 수동으로 추가합니다. 최소 권한 원칙을 따르도록 컨테이너 수준에서 Storage Blob 데이터 기여자 역할을 할당하는 것이 좋습니다.
작업을 통해 파이프라인, 워크플로 및 Notebook을 실행하는 경우 작업 영역 ID 권한 컨텍스트를 사용합니다. 작업 영역 기본 스토리지를 읽거나 쓰는 작업이 있는 경우 작업 영역 ID는 Storage 블로그 데이터 참가자를 통해 부여된 읽기/쓰기 권한을 사용합니다.
사용자가 스크립트를 실행하거나 개발을 위해 작업 영역에 로그인할 때 사용자의 컨텍스트 권한은 기본 스토리지에 대한 읽기/쓰기 액세스를 허용합니다.
액세스 제어 목록을 사용하여 세분화된 Azure Synapse Analytics 데이터 액세스 제어
데이터 레이크 액세스 제어를 설정할 때 일부 조직에서는 세분화된 수준의 액세스 권한이 필요합니다. 조직의 일부 그룹에서 볼 수 없는 중요한 데이터가 있을 수 있습니다. Azure RBAC는 스토리지 계정 및 컨테이너 수준에서만 읽기 또는 쓰기를 허용합니다. ACL을 사용하면 폴더 및 파일 수준에서 세분화된 액세스 제어를 설정하여 특정 그룹의 데이터 하위 집합에서 읽기/쓰기를 허용할 수 있습니다.
Spark 테이블 사용 시 고려 사항
Spark 풀에서 Apache Spark 테이블을 사용하면 웨어하우스 폴더가 만들어집니다. 폴더는 작업 영역 기본 스토리지의 컨테이너 루트에 있습니다.
synapse/workspaces/{workspaceName}/warehouse
Azure Synapse Spark 풀에서 Apache Spark 테이블을 만들려는 경우 Spark 테이블을 만드는 명령을 실행하는 그룹에 대해 웨어하우스 폴더에 대한 쓰기 권한을 부여합니다. 명령이 파이프라인에서 트리거된 작업을 통해 실행되는 경우 작업 영역 MSI에 쓰기 권한을 부여합니다.
이 예에서는 Spark 테이블을 만듭니다.
df.write.saveAsTable("table01")
자세한 내용은 synapse 작업 영역에 대한 액세스 제어를 설정하는 방법을 참조하세요.
Azure Data Lake 액세스 요약
데이터 레이크 액세스를 관리하는 한 가지 접근 방식이 모든 사람에게 적합하지는 않습니다. 데이터 레이크의 주요 이점은 데이터에 대한 마찰 없는 액세스를 제공하는 것입니다. 실제로 조직마다 데이터에 대해 서로 다른 수준의 거버넌스 및 제어를 원합니다. 일부 조직에는 엄격한 내부 제어 하에 액세스 및 프로비전 그룹을 관리하는 중앙 집중식 팀이 있습니다. 다른 조직은 더 민첩하고 분산된 제어를 갖습니다. 거버넌스 수준을 충족하는 방법을 선택합니다. 데이터에 액세스하는 데 과도한 지연이나 마찰이 발생하는 방법은 선택하지 않아야 합니다.