자습서: Azure Notebook에서 Personalizer 사용
Important
2023년 9월 20일부터 새 Personalizer 리소스를 만들 수 없습니다. Personalizer 서비스는 2026년 10월 1일에 사용 중지됩니다.
이 자습서에서는 Azure Notebook에서 Personalizer 루프를 실행하여 Personalizer 루프의 엔드투엔드 수명 주기를 보여 줍니다.
루프는 고객이 주문해야 하는 커피의 종류를 제안합니다. 사용자 및 해당 기본 설정은 사용자 데이터 세트에 저장됩니다. 커피에 대한 정보는 커피 데이터 세트에 저장됩니다.
사용자 및 커피
웹 사이트와의 사용자 상호 작용을 시뮬레이션하는 Notebook은 데이터 세트에서 임의 사용자, 시간 및 날씨 유형을 선택합니다. 사용자 정보는 다음과 같이 요약됩니다.
| 고객 - 컨텍스트 기능 | 하루 중 시간 | 날씨 유형 |
|---|---|---|
| Alice Bob Cathy Dave |
아침 낮 Evening |
맑음 비 눈 |
시간이 지남에 따라 Personalizer에서 학습하도록 시스템에서도 각 사용자의 커피 선택에 대한 세부 정보를 인식하고 있습니다.
| 커피 - 작업 기능 | 온도 형식 | 원산지 | 로스트 종류 | 유기농 |
|---|---|---|---|---|
| 카푸치노 | 핫 | 케냐 | 어둡게 | 유기농 |
| 콜드브루 | 관심 낮음 | 브라질 | 밝게 | 유기농 |
| 아이스 모카 | 관심 낮음 | 에티오피아 | 밝게 | 비유기농 |
| 라떼 | 핫 | 브라질 | 어둡게 | 비유기농 |
Personalizer 루프의 목적은 가능한 한 많은 시간 동안 사용자와 커피 사이에서 가장 일치하는 항목을 찾는 것입니다.
이 자습서의 코드는 Personalizer 샘플 GitHub 리포지토리에서 사용할 수 있습니다.
시뮬레이션 작동 방법
실행 시스템의 초기에는 Personalizer의 제안이 20%에서 30% 사이에서만 성공합니다. 이 성공은 Personalizer 보상 API로 다시 전송된 보상으로 표시되며 점수가 1입니다. 일부 순위 및 보상을 호출한 후에는 시스템이 향상됩니다.
초기 요청 후에는 오프라인 평가를 실행합니다. 이렇게 하면 Personalizer에서 데이터를 검토하여 더 나은 학습 정책을 제안할 수 있습니다. 새 학습 정책을 적용하고 이전 요청 수의 20%로 Notebook을 다시 실행합니다. 루프는 새 학습 정책으로 더 잘 수행됩니다.
순위 및 보상 호출
Personalizer 서비스에 대한 수천 개의 호출마다 Azure Notebook은 순위 요청을 REST API에 보냅니다.
- 순위/요청 이벤트의 고유 ID
- 컨텍스트 기능 - 사용자, 날씨 및 하루 중 시간을 임의로 선택하여 사용자를 웹 사이트 또는 모바일 디바이스에서 시뮬레이션합니다.
- 기능을 사용하는 작업 - Personalizer에서 모든 커피 데이터를 제안합니다.
시스템은 요청을 받은 다음, 동일한 하루 중 시간 및 날씨에 대해 해당 예측과 사용자의 알려진 선택 항목을 비교합니다. 알려진 선택 항목이 예측된 선택 항목과 동일하면 1의 보상을 Personalizer에 다시 보냅니다. 그렇지 않은 경우 다시 보낸 보상은 0입니다.
참고 항목
이는 시뮬레이션이므로 보상 알고리즘이 간단합니다. 실제 시나리오의 알고리즘에서는 고객 경험의 다양한 측면에 가중치를 부여할 수 있는 비즈니스 논리를 사용하여 보상 점수를 결정해야 합니다.
필수 조건
- Azure Notebook 계정
- Azure AI Personalizer 리소스
- Personalizer 리소스를 이미 사용한 경우 Azure Portal에서 해당 리소스에 대한 데이터를 지워야 합니다.
- 이 샘플의 모든 파일을 Azure Notebook 프로젝트에 업로드합니다.
파일 설명:
- Personalizer.ipynb는 이 자습서에서 사용할 Jupyter Notebook입니다.
- 사용자 데이터 세트는 JSON 개체에 저장됩니다.
- 커피 데이터 세트는 JSON 개체에 저장됩니다.
- 요청 JSON 예제는 순위 API에 대한 POST 요청에 필요한 형식입니다.
Personalizer 리소스 구성
Azure Portal에서 모델 업데이트 빈도를 15초로, 보상 대기 시간을 10초로 설정하여 Personalizer 리소스를 구성합니다. 이러한 값은 구성 페이지에서 찾을 수 있습니다.
| 설정 | 값 |
|---|---|
| 모델 업데이트 빈도 | 15초 |
| 보상 대기 시간 | 10분 |
이 자습서의 변경 내용을 보여 주기 위해 이러한 값의 기간이 매우 짧습니다. 프로덕션 시나리오에서 이러한 값을 사용하려면 먼저 Personalizer 루프를 사용하여 목표를 달성하는지를 확인해야 합니다.
Azure Notebook 설정
- 커널을
Python 3.6으로 변경합니다. Personalizer.ipynb파일을 엽니다.
Notebook 셀 실행
각 실행 셀을 실행하고 반환될 때까지 기다립니다. 셀 옆의 대괄호에 *가 아닌 숫자가 표시되면 완료되었음을 알 수 있습니다. 다음 섹션에서는 각 셀에서 프로그래밍 방식으로 수행하는 작업과 출력에 필요한 항목에 대해 설명합니다.
Python 모듈 포함
필요한 Python 모듈을 포함합니다. 셀에는 출력이 없습니다.
import json
import matplotlib.pyplot as plt
import random
import requests
import time
import uuid
Personalizer 리소스 키 및 이름 설정
Personalizer 리소스에 대한 Azure Portal의 빠른 시작 페이지에서 키와 엔드포인트를 찾습니다. <your-resource-name> 값을 Personalizer 리소스의 이름으로 변경합니다. <your-resource-key> 값을 Personalizer 키로 변경합니다.
# Replace 'personalization_base_url' and 'resource_key' with your valid endpoint values.
personalization_base_url = "https://<your-resource-name>.cognitiveservices.azure.com/"
resource_key = "<your-resource-key>"
현재 날짜 및 시간 인쇄
이 함수를 사용하여 반복 함수의 시작 및 종료 시간, 반복 횟수를 기록합니다.
이러한 셀에는 출력이 없습니다. 이 함수가 호출되면 현재 날짜 및 시간을 출력합니다.
# Print out current datetime
def currentDateTime():
currentDT = datetime.datetime.now()
print (str(currentDT))
마지막 모델 업데이트 시간 가져오기
get_last_updated 함수가 호출되면 모델이 업데이트된 마지막 수정 날짜 및 시간을 출력합니다.
이러한 셀에는 출력이 없습니다. 이 함수가 호출되면 마지막 모델 학습 날짜를 출력합니다.
이 함수는 GET REST API를 사용하여 모델 속성을 가져옵니다.
# ititialize variable for model's last modified date
modelLastModified = ""
def get_last_updated(currentModifiedDate):
print('-----checking model')
# get model properties
response = requests.get(personalization_model_properties_url, headers = headers, params = None)
print(response)
print(response.json())
# get lastModifiedTime
lastModifiedTime = json.dumps(response.json()["lastModifiedTime"])
if (currentModifiedDate != lastModifiedTime):
currentModifiedDate = lastModifiedTime
print(f'-----model updated: {lastModifiedTime}')
정책 및 서비스 구성 가져오기
이러한 두 개의 REST 호출을 통해 서비스 상태를 확인합니다.
이러한 셀에는 출력이 없습니다. 이 함수는 호출될 때 서비스 값을 출력합니다.
def get_service_settings():
print('-----checking service settings')
# get learning policy
response = requests.get(personalization_model_policy_url, headers = headers, params = None)
print(response)
print(response.json())
# get service settings
response = requests.get(personalization_service_configuration_url, headers = headers, params = None)
print(response)
print(response.json())
URL 생성 및 JSON 데이터 파일 읽기
이 셀에서 다음을 수행합니다.
- REST 호출에 사용되는 URL을 작성합니다.
- Personalizer 리소스 키를 사용하여 보안 헤더를 설정합니다.
- 순위 이벤트 ID의 임의 시드를 설정합니다.
- JSON 데이터 파일을 읽습니다.
get_last_updated메서드를 호출합니다. 예제 출력에서 학습 정책이 제거됩니다.get_service_settings메서드를 호출합니다.
셀에는 get_last_updated 및 get_service_settings 함수에 대한 호출의 출력이 있습니다.
# build URLs
personalization_rank_url = personalization_base_url + "personalizer/v1.0/rank"
personalization_reward_url = personalization_base_url + "personalizer/v1.0/events/" #add "{eventId}/reward"
personalization_model_properties_url = personalization_base_url + "personalizer/v1.0/model/properties"
personalization_model_policy_url = personalization_base_url + "personalizer/v1.0/configurations/policy"
personalization_service_configuration_url = personalization_base_url + "personalizer/v1.0/configurations/service"
headers = {'Ocp-Apim-Subscription-Key' : resource_key, 'Content-Type': 'application/json'}
# context
users = "users.json"
# action features
coffee = "coffee.json"
# empty JSON for Rank request
requestpath = "example-rankrequest.json"
# initialize random
random.seed(time.time())
userpref = None
rankactionsjsonobj = None
actionfeaturesobj = None
with open(users) as handle:
userpref = json.loads(handle.read())
with open(coffee) as handle:
actionfeaturesobj = json.loads(handle.read())
with open(requestpath) as handle:
rankactionsjsonobj = json.loads(handle.read())
get_last_updated(modelLastModified)
get_service_settings()
print(f'User count {len(userpref)}')
print(f'Coffee count {len(actionfeaturesobj)}')
출력의 rewardWaitTime이 10분으로, modelExportFrequency가 15초로 설정되어 있는지 확인합니다.
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:10:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:00:15', 'logRetentionDays': -1}
User count 4
Coffee count 4
첫 번째 REST 호출 문제 해결
이 이전 셀은 Personalizer를 호출하는 첫 번째 셀입니다. 출력의 REST 상태 코드가 <Response [200]>인지 확인합니다. 404와 같은 오류가 발생하지만 리소스 키와 이름이 올바른 경우 Notebook을 다시 로드합니다.
커피와 사용자의 수가 모두 4인지 확인합니다. 오류가 발생하면 3개의 JSON 파일을 모두 업로드했는지 확인합니다.
Azure Portal에서 메트릭 차트 설정
이 자습서의 뒷부분에서는 10,000개의 요청에 대한 장기 실행 프로세스가 브라우저에서 업데이트하는 텍스트 상자를 통해 표시됩니다. 장기 실행 프로세스가 종료되면 차트 또는 총 합계로 더 쉽게 볼 수 있습니다. 이 정보를 보려면 리소스와 함께 제공되는 메트릭을 사용합니다. 이제 서비스에 대한 요청을 완료했으므로 차트를 만든 다음, 장기 실행 프로세스가 진행되는 동안 차트를 정기적으로 새로 고칠 수 있습니다.
Azure Portal에서 Personalizer 리소스를 선택합니다.
리소스 탐색의 [모니터링] 아래에서 메트릭을 선택합니다.
차트에서 메트릭 추가를 선택합니다.
리소스 및 메트릭 네임스페이스가 이미 설정되어 있습니다. 성공한 호출 수 메트릭과 합계 집계만 선택하면 됩니다.
시간 필터를 지난 4시간으로 변경합니다.
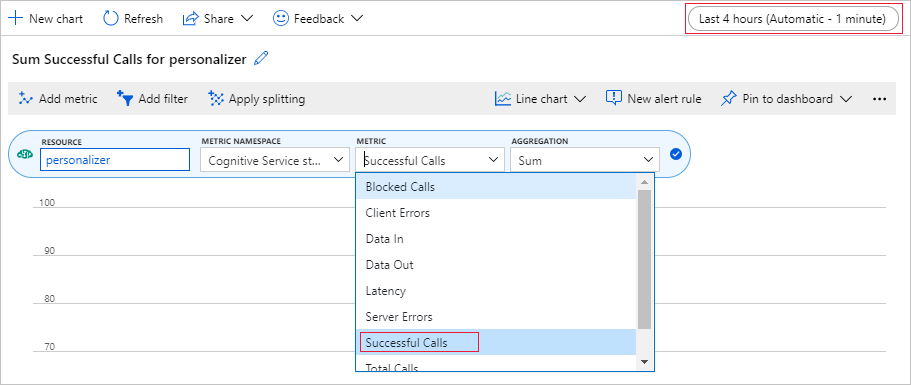
차트에 세 개의 성공한 호출이 표시됩니다.
고유 이벤트 ID 생성
이 함수는 각 순위 호출에 대한 고유 ID를 생성합니다. ID는 순위 및 보상 호출 정보를 식별하는 데 사용됩니다. 이 값은 웹 보기 ID 또는 트랜잭션 ID와 같은 비즈니스 프로세스에서 가져올 수 있습니다.
셀에는 출력이 없습니다. 이 함수가 호출되면 고유 ID를 출력합니다.
def add_event_id(rankjsonobj):
eventid = uuid.uuid4().hex
rankjsonobj["eventId"] = eventid
return eventid
임의 사용자, 날씨 및 하루 중 시간 가져오기
이 함수는 고유한 사용자, 날씨 및 시간을 선택한 다음, 해당 항목을 JSON 개체에 추가하여 순위 요청에 보냅니다.
셀에는 출력이 없습니다. 이 함수가 호출되면 임의 사용자의 이름, 임의의 날씨 및 임의의 하루 중 시간을 반환합니다.
4명의 사용자 목록과 해당 사용자 기본 설정은 다음과 같습니다. 간단히 하기 위해 일부 기본 설정만 표시됩니다.
{
"Alice": {
"Sunny": {
"Morning": "Cold brew",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Bob": {
"Sunny": {
"Morning": "Cappucino",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Cathy": {
"Sunny": {
"Morning": "Latte",
"Afternoon": "Cold brew",
"Evening": "Cappucino"
}...
},
"Dave": {
"Sunny": {
"Morning": "Iced mocha",
"Afternoon": "Iced mocha",
"Evening": "Iced mocha"
}...
}
}
def add_random_user_and_contextfeatures(namesoption, weatheropt, timeofdayopt, rankjsonobj):
name = namesoption[random.randint(0,3)]
weather = weatheropt[random.randint(0,2)]
timeofday = timeofdayopt[random.randint(0,2)]
rankjsonobj['contextFeatures'] = [{'timeofday': timeofday, 'weather': weather, 'name': name}]
return [name, weather, timeofday]
모든 커피 데이터 추가
이 함수는 커피 목록 전체를 JSON 개체에 추가하여 순위 요청에 보냅니다.
셀에는 출력이 없습니다. 이 함수가 호출되면 rankjsonobj를 변경합니다.
커피의 단일 기능 예제는 다음과 같습니다.
{
"id": "Cappucino",
"features": [
{
"type": "hot",
"origin": "kenya",
"organic": "yes",
"roast": "dark"
}
}
def add_action_features(rankjsonobj):
rankjsonobj["actions"] = actionfeaturesobj
알려진 사용자 기본 설정과 예측 비교
각 반복에 대해 순위 API 호출이 호출되면 이 함수가 호출됩니다.
이 함수는 날씨와 시간을 기준으로 커피에 대한 사용자의 기본 설정을 해당 필터에 대한 사용자의 Personalizer 제안과 비교합니다. 제안이 일치하면 1의 점수가 반환되고, 그렇지 않으면 점수가 0입니다. 셀에는 출력이 없습니다. 이 함수가 호출되면 점수를 출력합니다.
def get_reward_from_simulated_data(name, weather, timeofday, prediction):
if(userpref[name][weather][timeofday] == str(prediction)):
return 1
return 0
순위 및 보상에 대한 호출 반복
다음 셀은 임의의 사용자를 가져오고, 커피 목록을 가져오며, 둘 모두를 순위 API에 보내는 Notebook의 main 작업입니다. 예측과 사용자의 알려진 기본 설정을 비교한 다음, 보상을 Personalizer 서비스에 다시 보냅니다.
루프는 num_requests회 실행됩니다. Personalizer에서 모델을 만들려면 순위 및 보상에 대한 수천 개의 호출이 필요합니다.
순위 API에 보내는 JSON의 예제는 다음과 같습니다. 간단히 하기 위해 커피 목록이 완전하지 않습니다. coffee.json에서 커피의 전체 JSON을 볼 수 있습니다.
순위 API에 보내는 JSON:
{
'contextFeatures':[
{
'timeofday':'Evening',
'weather':'Snowy',
'name':'Alice'
}
],
'actions':[
{
'id':'Cappucino',
'features':[
{
'type':'hot',
'origin':'kenya',
'organic':'yes',
'roast':'dark'
}
]
}
...rest of coffee list
],
'excludedActions':[
],
'eventId':'b5c4ef3e8c434f358382b04be8963f62',
'deferActivation':False
}
순위 API의 JSON 응답:
{
'ranking': [
{'id': 'Latte', 'probability': 0.85 },
{'id': 'Iced mocha', 'probability': 0.05 },
{'id': 'Cappucino', 'probability': 0.05 },
{'id': 'Cold brew', 'probability': 0.05 }
],
'eventId': '5001bcfe3bb542a1a238e6d18d57f2d2',
'rewardActionId': 'Latte'
}
마지막으로, 각 루프는 임의로 선택한 사용자, 날씨, 하루 중 시간 및 결정된 보상을 보여 줍니다. 1의 보상은 Personalizer 리소스에서 지정된 사용자, 날씨 및 하루 중 시간에 적합한 커피 유형을 선택했음을 나타냅니다.
1 Alice Rainy Morning Latte 1
함수는 다음을 사용합니다.
def iterations(n, modelCheck, jsonFormat):
i = 1
# default reward value - assumes failed prediction
reward = 0
# Print out dateTime
currentDateTime()
# collect results to aggregate in graph
total = 0
rewards = []
count = []
# default list of user, weather, time of day
namesopt = ['Alice', 'Bob', 'Cathy', 'Dave']
weatheropt = ['Sunny', 'Rainy', 'Snowy']
timeofdayopt = ['Morning', 'Afternoon', 'Evening']
while(i <= n):
# create unique id to associate with an event
eventid = add_event_id(jsonFormat)
# generate a random sample
[name, weather, timeofday] = add_random_user_and_contextfeatures(namesopt, weatheropt, timeofdayopt, jsonFormat)
# add action features to rank
add_action_features(jsonFormat)
# show JSON to send to Rank
print('To: ', jsonFormat)
# choose an action - get prediction from Personalizer
response = requests.post(personalization_rank_url, headers = headers, params = None, json = jsonFormat)
# show Rank prediction
print ('From: ',response.json())
# compare personalization service recommendation with the simulated data to generate a reward value
prediction = json.dumps(response.json()["rewardActionId"]).replace('"','')
reward = get_reward_from_simulated_data(name, weather, timeofday, prediction)
# show result for iteration
print(f' {i} {currentDateTime()} {name} {weather} {timeofday} {prediction} {reward}')
# send the reward to the service
response = requests.post(personalization_reward_url + eventid + "/reward", headers = headers, params= None, json = { "value" : reward })
# for every N rank requests, compute total correct total
total = total + reward
# every N iteration, get last updated model date and time
if(i % modelCheck == 0):
print("**** 10% of loop found")
get_last_updated(modelLastModified)
# aggregate so chart is easier to read
if(i % 10 == 0):
rewards.append( total)
count.append(i)
total = 0
i = i + 1
# Print out dateTime
currentDateTime()
return [count, rewards]
10,000회 반복 실행
10,000회 반복을 위한 Personalizer 루프를 실행합니다. 이는 장기 실행 이벤트입니다. Notebook을 실행하는 브라우저를 닫지 마세요. 서비스에 대한 총 호출 수를 확인하려면 Azure Portal에서 메트릭 차트를 정기적으로 새로 고칩니다. 약 20,000개의 호출이 있으면 루프의 각 반복에 대한 순위 및 보상 호출과 반복이 수행됩니다.
# max iterations
num_requests = 200
# check last mod date N% of time - currently 10%
lastModCheck = int(num_requests * .10)
jsonTemplate = rankactionsjsonobj
# main iterations
[count, rewards] = iterations(num_requests, lastModCheck, jsonTemplate)
개선 사항을 표시하는 차트 결과
count 및 rewards에서 차트를 만듭니다.
def createChart(x, y):
plt.plot(x, y)
plt.xlabel("Batch of rank events")
plt.ylabel("Correct recommendations per batch")
plt.show()
10,000개 순위 요청에 대한 차트 실행
createChart 함수를 실행합니다.
createChart(count,rewards)
차트 읽기
이 차트에서는 현재 기본 학습 정책에 대한 모델의 성공을 보여 줍니다.
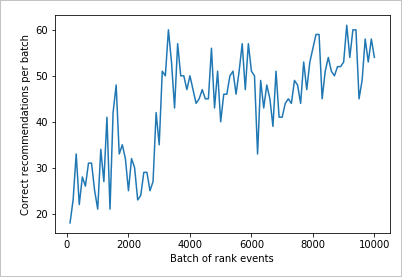
이상적인 목표는 테스트의 끝에서 루프가 평균적으로 100%에 가까운 검색 성공률을 달성하는 것입니다. 탐색의 기본 값은 20%입니다.
100-20=80
이 탐색 값은 Personalizer 리소스에 대한 Azure Portal의 구성 페이지에 있습니다.
순위 API에 대한 데이터를 기반으로 하여 더 나은 학습 정책을 찾으려면 포털에서 Personalizer 루프에 대한 오프라인 평가를 실행합니다.
오프라인 평가 실행
Azure Portal에서 Personalizer 리소스의 평가 페이지를 엽니다.
평가 만들기를 선택합니다.
루프 평가에 필요한 평가 이름 및 날짜 범위의 데이터를 입력합니다. 날짜 범위에는 평가에 집중하는 날짜만 포함되어야 합니다.
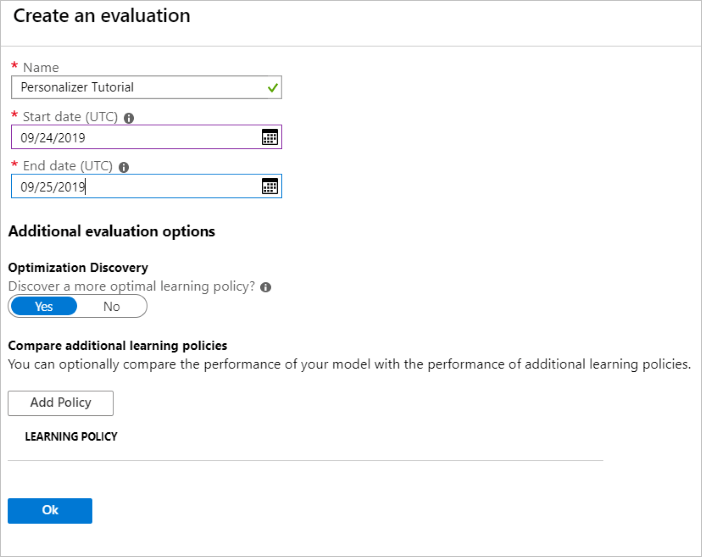
이 오프라인 평가를 실행하는 목적은 이 루프에 사용되는 기능과 작업에 대해 더 나은 학습 정책이 있는지 확인하는 것입니다. 더 나은 학습 정책을 찾으려면 최적화 검색이 설정되어 있는지 확인합니다.
확인을 선택하여 평가를 시작합니다.
이 평가 페이지에서 새 평가 및 해당 현재 상태가 나열됩니다. 이 평가에는 보유한 데이터의 양에 따라 시간이 걸릴 수 있습니다. 몇 분 후에 이 페이지로 돌아와서 결과를 볼 수 있습니다.
평가가 완료되면 평가를 선택한 다음, 다른 학습 정책 비교를 선택합니다. 여기서는 사용 가능한 학습 정책과 이러한 정책이 데이터에서 동작하는 방법을 보여 줍니다.
테이블에서 맨 위에 있는 학습 정책을 선택하고, 적용을 선택합니다. 그러면 가장 적합한 학습 정책을 모델에 적용하고 다시 학습시킵니다.
모델 업데이트 빈도를 5분으로 변경
- 여전히 Azure Portal의 Personalizer 리소스에서 구성 페이지를 선택합니다.
- 모델 업데이트 빈도 및 보상 대기 시간을 5분으로 변경하고, 저장을 선택합니다.
보상 대기 시간 및 모델 업데이트 빈도에 대해 자세히 알아보세요.
#Verify new learning policy and times
get_service_settings()
출력의 rewardWaitTime 및 modelExportFrequency가 모두 5분으로 설정되어 있는지 확인합니다.
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:05:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:05:00', 'logRetentionDays': -1}
User count 4
Coffee count 4
새 학습 정책 유효성 검사
Azure Notebooks 파일로 돌아가서 동일한 루프를 실행하지만 2,000회만 반복합니다. 서비스에 대한 총 호출 수를 확인하려면 Azure Portal에서 메트릭 차트를 정기적으로 새로 고칩니다. 약 4,000개의 호출이 있으면 루프의 각 반복에 대한 순위 및 보상 호출과 반복이 수행됩니다.
# max iterations
num_requests = 2000
# check last mod date N% of time - currently 10%
lastModCheck2 = int(num_requests * .10)
jsonTemplate2 = rankactionsjsonobj
# main iterations
[count2, rewards2] = iterations(num_requests, lastModCheck2, jsonTemplate)
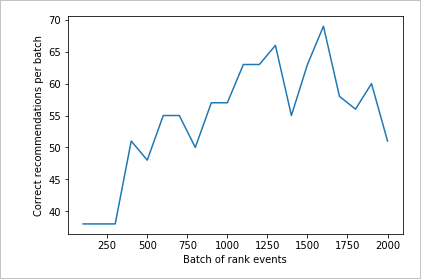
2,000개 순위 요청에 대한 실행 차트
createChart 함수를 실행합니다.
createChart(count2,rewards2)
두 번째 차트 검토
두 번째 차트에서는 사용자 기본 설정에 맞게 순위 예측이 눈에 띄게 증가했음을 보여 줍니다.
리소스 정리
자습서 시리즈를 계속 진행하지 않으려면 다음 리소스를 정리합니다.
- Azure Notebook 프로젝트를 삭제합니다.
- Personalizer 리소스를 삭제합니다.
다음 단계
이 샘플에 사용된 Jupyter Notebook 및 데이터 파일은 Personalizer용 GitHub 리포지토리에서 사용할 수 있습니다.