사용자 지정 신경망 음성이란?
CNV(사용자 지정 신경망 음성)는 애플리케이션에 대한 특별한 사용자 지정 합성 음성을 만들 수 있는 텍스트 음성 변환 기능입니다. 사용자 지정 신경망 음성을 사용하면 사용자 음성 샘플을 학습 데이터로 제공하여 브랜드 또는 캐릭터에 대한 매우 자연스러운 음성을 빌드할 수 있습니다.
Important
사용자 지정 신경망 음성 액세스는 자격 및 사용 조건에 따라 제한됩니다. 접수 양식에서 액세스 권한을 요청하세요.
고품질 음성을 만들기 위해 전문 녹음/녹화에 투자하기 전에 CNV(사용자 지정 신경망 음성) Lite를 시연 및 평가하는 누구나 CNV에 액세스할 수 있습니다.
텍스트 음성 변환은 지원되는 각 언어에 대해 미리 빌드된 신경망 음성과 함께 사용할 수 있습니다. 고유한 음성이 필요하지 않은 경우 미리 빌드된 신경망 음성은 대부분의 텍스트 음성 변환 시나리오에서 잘 작동합니다.
사용자 지정 신경망 음성은 신경망 텍스트 음성 변환 기술과 다국어, 다중 스피커, 유니버설 모델을 기반으로 합니다. 말하기 스타일 또는 적응 가능한 크로스 언어가 풍부한 합성 음성을 만들 수 있습니다. 사용자 지정 신경망 음성의 실제적이고 자연스러운 음성은 브랜드를 대표하고, 머신을 의인화할 수 있으며, 사용자가 대화로 애플리케이션을 조작할 수 있도록 합니다. 사용자 지정 신경망 음성에 대해 지원되는 언어를 참조하세요.
작동 방식
사용자 지정 신경망 음성을 만들려면 Speech Studio를 사용하여 녹음된 오디오 및 해당 스크립트를 업로드하고, 모델을 학습시키고, 음성을 사용자 지정 엔드포인트에 배포합니다.
팁
고품질 음성을 만들기 위해 전문 녹음에 투자하기 전에 CNV(사용자 지정 신경망 음성) Lite를 사용해 CNV를 데모하고 평가합니다.
뛰어난 사용자 지정 신경망 음성을 만들려면 음성 디자인 및 데이터 준비에서 시스템에 음성 모델 배포에 이르기까지 각 단계에서 신중한 품질 제어가 필요합니다.
Speech Studio를 시작하기 전에 몇 가지 고려 사항은 다음과 같습니다.
- 간략한 가상 사용자 문서를 사용하여 브랜드를 나타내는 음성 가상 사용자를 디자인합니다. 이 문서는 음성 특징 및 음성 성격과 같은 요소를 정의합니다. 이렇게 하면 스크립트 정의, 성우 선택, 학습 및 음성 튜닝을 포함하여 사용자 지정 신경망 음성 모델을 만드는 프로세스를 안내할 수 있습니다.
- 녹음 스크립트를 선택하여 음성에 대한 사용자 시나리오를 나타냅니다. 예를 들어 고객 서비스 봇을 만드는 경우 봇 대화의 구를 녹음 스크립트로 사용할 수 있습니다. 명령문, 질문, 느낌표를 포함하여 스크립트에 다양한 문장 형식을 포함합니다.
다음은 Speech Studio에서 사용자 지정 신경망 음성을 만드는 단계에 대한 개요입니다.
- 데이터, 음성 모델, 테스트 및 엔드포인트를 포함하는 프로젝트를 만듭니다. 각 프로젝트는 국가/지역 및 언어에 따라 다릅니다. 여러 음성을 만들려는 경우 각 음성에 대한 프로젝트를 만드는 것이 좋습니다.
- 성우 설정 신경망 음성을 학습하려면 먼저 성우의 동의 설명 녹음을 제출해야 합니다. 성우 설명은 성우가 음성 데이터를 사용하여 사용자 지정 음성 모델을 학습시키는 데 동의한다는 설명을 읽는 녹음입니다.
- 올바른 형식으로 학습 데이터를 준비합니다. 높은 신호 대 잡음비를 달성하려면 오디오 녹음을 전문 품질 녹음 스튜디오에서 캡처하는 것이 좋습니다. 음성 모델의 품질은 학습 데이터에 따라 크게 달라집니다. 음성의 표현 방식에서 일관된 볼륨, 말하기 속도, 피치 및 일관성이 필요합니다.
- 음성 모델을 학습합니다. 사용자 지정 신경망 음성을 만들려면 발화를 최소 300개 이상 선택합니다. 일련의 데이터 품질 검사는 업로드할 때 자동으로 수행됩니다. 고품질 음성 모델을 빌드하려면 오류를 수정하고 다시 제출해야 합니다.
- 음성을 테스트합니다. 앱에 대한 다양한 사용 사례를 다루는 음성 모델에 대한 테스트 스크립트를 준비합니다. 다양한 콘텐츠의 품질을 보다 광범위하게 테스트할 수 있도록 학습 데이터 세트 내외부에서 스크립트를 사용하는 것이 좋습니다.
- 앱에서 음성 모델을 배포하고 사용합니다.
미리 빌드된 신경망 음성을 사용하는 것과 마찬가지로 사용자 지정 음성을 튜닝, 조정 및 사용할 수 있습니다. 실시간으로 텍스트를 음성으로 변환하거나 텍스트 입력을 사용하여 오프라인으로 오디오 콘텐츠를 생성합니다. REST API, Speech SDK 또는 Speech Studio를 사용합니다.
팁
Speech SDK 및 사용자 지정 음성 REST API를 사용하여 사용자 지정 신경망 음성을 학습할 수도 있습니다.
애플리케이션에서 사용자 지정 신경망 음성을 사용하는 방법을 알아보려면 GitHub의 음성 SDK 리포지토리에서 코드 샘플을 확인합니다.
학습된 음성 모델의 스타일과 특성은 학습에 사용되는 성우의 녹음 스타일과 품질에 따라 달라집니다. 그러나 음성 모델에 API를 호출하여 가상 음성을 생성할 때 SSML(Speech Synthesis Markup Language)을 사용하여 몇 가지를 조정할 수 있습니다. SSML은 텍스트를 오디오로 변환하기 위해 텍스트 음성 변환 서비스와 통신하는 데 사용되는 표시 언어입니다. 피치, 속도, 음조 및 발음 수정 등을 조정할 수 있습니다. 음성 모델이 여러 스타일로 빌드되면 SSML을 사용하여 스타일을 전환할 수도 있습니다.
구성 요소 시퀀스
사용자 지정 신경망 음성은 텍스트 분석기, 인공신경망 음향 모델 및 인공신경망 보코더의 세 가지 주요 구성 요소로 구성됩니다. 텍스트에서 자연스러운 합성 음성을 생성하기 위해 텍스트는 먼저 텍스트 분석기에 입력됩니다. 그러면 출력이 음소 시퀀스의 형태로 제공됩니다. 음소는 한 단어를 특정 언어의 다른 단어와 구분하는 소리의 기본 단위입니다. 음소 시퀀스는 텍스트에 제공된 단어의 발음을 정의합니다.
다음으로 음소 시퀀스는 인공신경망 음향 모델로 이동하여 음성 신호를 정의하는 음향 특징을 예측합니다. 음향 특징에는 음색, 말하기 스타일, 속도, 음조 및 강세 패턴이 포함됩니다. 마지막으로 인공신경망 보코더는 음향 특징을 가청 음파로 변환하여 합성 음성을 생성합니다.
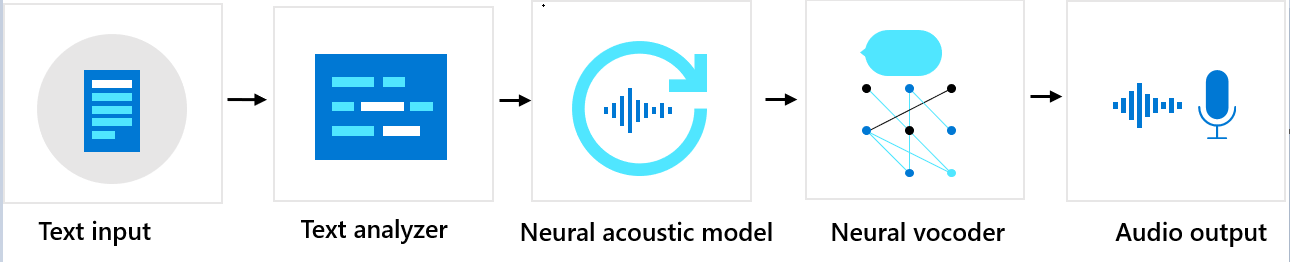
인공신경망 텍스트 음성 변환 음성 모델은 인간 음성의 녹음 샘플을 기반으로 하는 심층 신경망을 사용하여 학습됩니다. 자세한 내용은 이 Microsoft 블로그 게시물을 참조하세요. 인공신경망 보코더를 학습시키는 방법에 대한 자세한 내용은 이 Microsoft 블로그 게시물을 참조하세요.
사용자 지정 신경망 음성으로 마이그레이션
이전 버전의 Custom Voice(2024년 2월에 사용 중지 예정)를 사용하는 경우 사용자 지정 신경망 음성으로 마이그레이션하는 방법을 참조하세요.
책임 있는 AI
AI 시스템에는 기술뿐만 아니라 이를 사용하는 사람, 영향을 받는 사람, 배포되는 환경도 포함됩니다. 시스템에서의 책임감 있는 AI 사용 및 배포에 대해 알아보려면 투명성 참고 사항을 읽어보세요.
- 사용자 지정 신경망 음성 대한 투명성 고지 및 사용 사례
- 사용자 지정 신경망 음성 사용에 대한 특성 및 제한 사항
- 사용자 지정 신경망 음성에 대한 제한된 액세스
- 합성 음성 기술에 대한 책임 있는 배포 지침
- 성우 공개
- 공개 디자인 지침
- 공개 디자인 패턴
- 텍스트 음성 변환 통합을 위한 행동 강령
- 사용자 지정 신경망 음성에 대한 데이터, 개인 정보 및 보안