viseme으로 얼굴 위치 가져오기
참고 항목
viseme ID 및 혼합 셰이프에 지원되는 로캘을 탐색하려면 지원되는 모든 로캘 목록을 참조하세요. SVG(확장성 있는 벡터 그래픽)는 en-US 로캘에만 지원됩니다.
viseme은 음성 언어로 된 음소의 시각적 설명입니다. 사람이 말하는 동안 얼굴과 입의 위치를 정의합니다. 각 viseme은 특정 음소 세트에 대한 주요 얼굴 포즈를 묘사합니다.
viseme을 사용하여 2D 및 3D 아바타 모델의 움직임을 제어하여 얼굴 위치가 합성 음성과 가장 잘 맞춰지도록 할 수 있습니다. 이렇게 시작할 수 있는 작업의 예는 다음과 같습니다.
- 고객을 위한 다중 모드 통합 서비스를 구축하여 지능형 키오스크를 위한 애니메이션 가상 음성 도우미를 만듭니다.
- 몰입형 뉴스 방송을 만들고 자연스러운 얼굴과 입의 움직임으로 대상 그룹의 경험을 개선합니다.
- 동적 콘텐츠로 대화할 수 있는 더 많은 대화형 게임 아바타 및 만화 캐릭터를 생성합니다.
- 언어 학습자가 각 단어와 음소의 입 동작을 이해하는 데 도움이 되는 효과적인 언어 교육 비디오를 만듭니다.
- 청각 장애가 있는 사용자는 시각적으로 소리를 포착할 수 있고 애니메이션 얼굴의 viseme을 보여주는 "입술 읽기" 음성 콘텐츠를 선택할 수도 있습니다.
viseme에 대한 자세한 내용은 이 소개 비디오를 참조하세요.
음성을 사용하여 viseme을 생성하는 전체 워크플로
인공신경망 TTS(인공신경망 텍스트 음성 변환)는 입력 텍스트 또는 SSML(음성 합성 태그 언어)을 실제 같은 합성된 음성으로 바꿉니다. 음성 오디오 출력에는 viseme ID, SVG(확장성 있는 벡터 그래픽) 또는 혼합 모양이 함께 제공될 수 있습니다. 2D 또는 3D 렌더링 엔진을 사용하면 이러한 viseme 이벤트로 아바타에 애니메이션을 적용할 수 있습니다.
viseme의 전체 워크플로는 다음 순서도에 설명되어 있습니다.
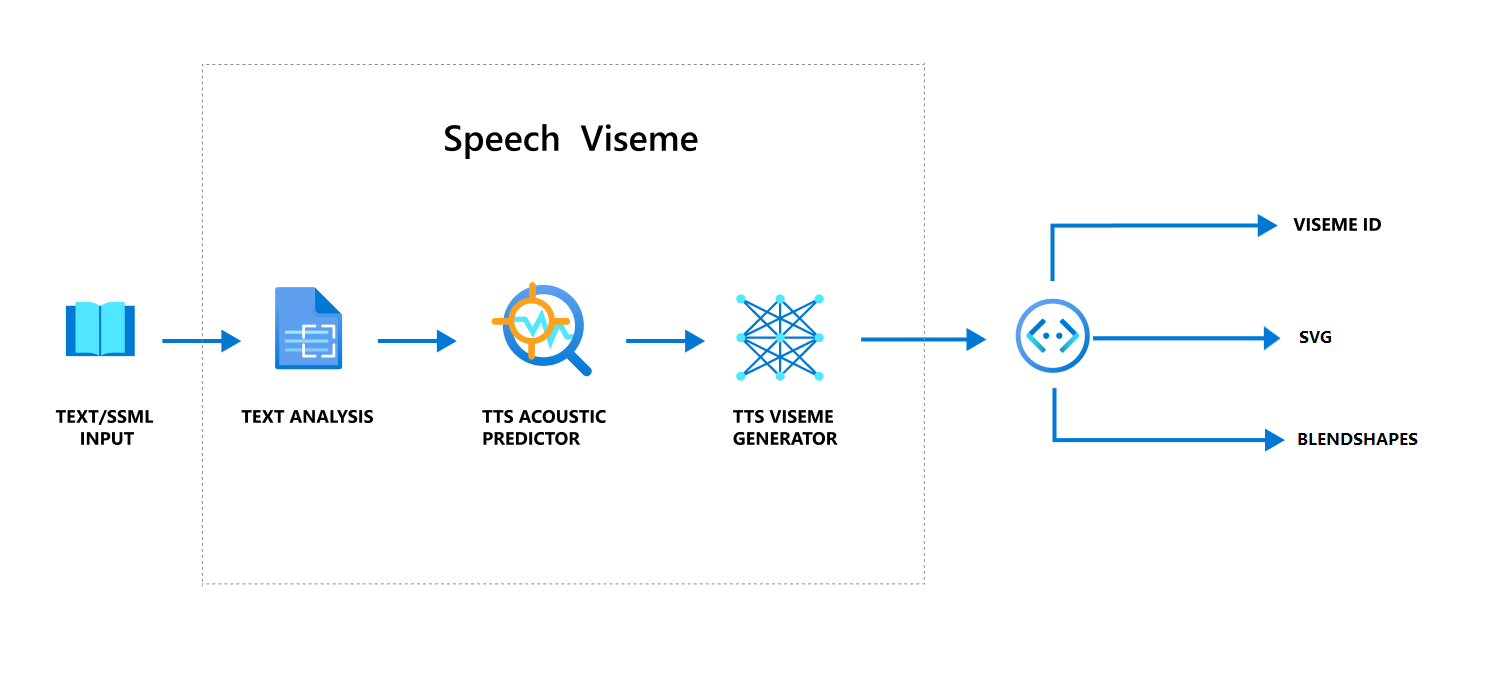
Viseme ID
Viseme ID는 viseme를 지정하는 정수 번호를 나타냅니다. 각각 특정 음소 세트에 대한 입 위치를 묘사하는 22개의 다른 viseme를 제공합니다. viseme과 음소 간에는 일대일 대응이 없습니다. s 및 z와 같이 생성될 때 화자의 얼굴에서 동일하게 보이기 때문에 종종 몇 가지 음소는 단일 viseme에 해당합니다. 자세한 내용은 음소와 viseme ID 매핑에 대한 표를 참조하세요.
음성 오디오 출력에는 viseme ID 및 Audio offset가 포함될 수 있습니다. Audio offset은 각 viseme의 시작 시간을 틱(100나노초) 단위로 표시하는 오프셋 타임스탬프를 나타냅니다.
viseme에 음소 매핑
Viseme는 언어 및 로캘에 따라 다릅니다. 각 로캘에는 특정 음소에 해당하는 viseme 세트가 있습니다. SSML 발음 기호 설명서는 viseme ID를 해당 IPA(국제 발음 기호) 음소에 매핑합니다. 이 섹션의 표에서는 viseme ID와 입 위치 간의 매핑 관계를 보여 줍니다. 각 viseme ID에 대한 일반적인 IPA 음소가 나열되어 있습니다.
| Viseme ID | IPA | 입 위치 |
|---|---|---|
| 0 | 침묵 |  |
| 1 | æ, ə, ʌ |
 |
| 2 | ɑ |
 |
| 3 | ɔ |
 |
| 4 | ɛ, ʊ |
 |
| 5 | ɝ |
 |
| 6 | j, i, ɪ |
 |
| 7 | w, u |
 |
| 8 | o |
 |
| 9 | aʊ |
 |
| 10 | ɔɪ |
 |
| 11 | aɪ |
 |
| 12 | h |
 |
| 13 | ɹ |
 |
| 14 | l |
 |
| 15 | s, z |
 |
| 16 | ʃ, tʃ, dʒ, ʒ |
 |
| 17 | ð |
 |
| 18 | f, v |
 |
| 19 | d, t, n, θ |
 |
| 20 | k, g, ŋ |
 |
| 21 | p, b, m |
 |
2D SVG 애니메이션
2D 캐릭터의 경우 시나리오에 맞는 캐릭터를 디자인하고 각 viseme ID에 대해 SVG(Scalable Vector Graphics)를 사용하여 시간 기반 얼굴 위치를 얻을 수 있습니다.
viseme 이벤트에서 제공되는 임시 태그를 사용하면 잘 디자인된 이러한 SVG가 다듬어져 사용자에게 강력한 애니메이션을 제공합니다. 예를 들어 다음 그림에서는 언어 학습을 위해 설계된 빨간색 글자 문자를 보여 줍니다.

3D 혼합 모양 애니메이션
혼합 모양을 사용하여 디자인한 3D 캐릭터의 얼굴 움직임을 구동할 수 있습니다.
혼합 모양 JSON 문자열은 2차원 행렬로 표시됩니다. 각 행은 프레임을 나타냅니다. 각 프레임(60FPS)에는 55개의 얼굴 위치 배열이 포함되어 있습니다.
Speech SDK를 사용하여 viseme 이벤트 가져오기
합성 음성으로 viseme를 가져오려면 Speech SDK에서 VisemeReceived 이벤트를 구독합니다.
참고 항목
SVG를 요청하거나 셰이프 출력을 혼합하려면 SSML에서 mstts:viseme 요소를 사용해야 합니다. 자세한 내용은 SSML에서 viseme 요소를 사용하는 방법을 참조하세요.
다음 코드 조각은 viseme 이벤트를 구독하는 방법을 보여 줍니다.
using (var synthesizer = new SpeechSynthesizer(speechConfig, audioConfig))
{
// Subscribes to viseme received event
synthesizer.VisemeReceived += (s, e) =>
{
Console.WriteLine($"Viseme event received. Audio offset: " +
$"{e.AudioOffset / 10000}ms, viseme id: {e.VisemeId}.");
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
var result = await synthesizer.SpeakSsmlAsync(ssml);
}
auto synthesizer = SpeechSynthesizer::FromConfig(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer->VisemeReceived += [](const SpeechSynthesisVisemeEventArgs& e)
{
cout << "viseme event received. "
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
<< "Audio offset: " << e.AudioOffset / 10000 << "ms, "
<< "viseme id: " << e.VisemeId << "." << endl;
// `Animation` is an xml string for SVG or a json string for blend shapes
auto animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
auto result = synthesizer->SpeakSsmlAsync(ssml).get();
SpeechSynthesizer synthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.VisemeReceived.addEventListener((o, e) -> {
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
System.out.print("Viseme event received. Audio offset: " + e.getAudioOffset() / 10000 + "ms, ");
System.out.println("viseme id: " + e.getVisemeId() + ".");
// `Animation` is an xml string for SVG or a json string for blend shapes
String animation = e.getAnimation();
});
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
SpeechSynthesisResult result = synthesizer.SpeakSsmlAsync(ssml).get();
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
def viseme_cb(evt):
print("Viseme event received: audio offset: {}ms, viseme id: {}.".format(
evt.audio_offset / 10000, evt.viseme_id))
# `Animation` is an xml string for SVG or a json string for blend shapes
animation = evt.animation
# Subscribes to viseme received event
speech_synthesizer.viseme_received.connect(viseme_cb)
# If VisemeID is the only thing you want, you can also use `speak_text_async()`
result = speech_synthesizer.speak_ssml_async(ssml).get()
var synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.visemeReceived = function (s, e) {
window.console.log("(Viseme), Audio offset: " + e.audioOffset / 10000 + "ms. Viseme ID: " + e.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.animation;
}
// If VisemeID is the only thing you want, you can also use `speakTextAsync()`
synthesizer.speakSsmlAsync(ssml);
SPXSpeechSynthesizer *synthesizer =
[[SPXSpeechSynthesizer alloc] initWithSpeechConfiguration:speechConfig
audioConfiguration:audioConfig];
// Subscribes to viseme received event
[synthesizer addVisemeReceivedEventHandler: ^ (SPXSpeechSynthesizer *synthesizer, SPXSpeechSynthesisVisemeEventArgs *eventArgs) {
NSLog(@"Viseme event received. Audio offset: %fms, viseme id: %lu.", eventArgs.audioOffset/10000., eventArgs.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
NSString *animation = eventArgs.Animation;
}];
// If VisemeID is the only thing you want, you can also use `SpeakText`
[synthesizer speakSsml:ssml];
다음은 viseme 출력의 예제입니다.
(Viseme), Viseme ID: 1, Audio offset: 200ms.
(Viseme), Viseme ID: 5, Audio offset: 850ms.
……
(Viseme), Viseme ID: 13, Audio offset: 2350ms.
viseme 출력을 가져온 후 이러한 이벤트를 사용하여 문자 애니메이션을 수행할 수 있습니다. 나만의 캐릭터를 만들고 자동으로 캐릭터에 애니메이션을 적용할 수 있습니다.