활동성 프로브 구성
컨테이너화된 애플리케이션이 장기간 실행되어 손상되면 컨테이너를 다시 시작하여 복구해야 할 수도 있습니다. Azure Container Instances는 중요 기능이 작동하지 않는 경우 다시 시작하도록 컨테이너 그룹 내에서 컨테이너를 구성할 수 있도록 활동성 프로브를 지원합니다. 활동성 프로브는 Kubernetes 활동성 프로브처럼 동작합니다.
이 문서에서는 활동성 프로브가 포함된 컨테이너 그룹을 배포하는 방법을 설명하고, 시뮬레이션된 비정상 컨테이너를 다시 시작하는 방법을 보여줍니다.
또한 Azure Container Instances은 준비된 경우에만 트래픽이 컨테이너에 도달할 수 있도록 구성할 수 있는 준비 상태 프로브를 지원합니다.
YAML 배포
다음 코드 조각이 포함된 liveness-probe.yaml 파일을 만듭니다. 이 파일은 결국 비정상 상태가 되는 NGINX 컨테이너를 구성하는 컨테이너 그룹을 정의합니다.
apiVersion: 2019-12-01
location: eastus
name: livenesstest
properties:
containers:
- name: mycontainer
properties:
image: mcr.microsoft.com/oss/nginx/nginx:1.15.5-alpine
command:
- "/bin/sh"
- "-c"
- "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
ports: []
resources:
requests:
cpu: 1.0
memoryInGB: 1.5
livenessProbe:
exec:
command:
- "cat"
- "/tmp/healthy"
periodSeconds: 5
osType: Linux
restartPolicy: Always
tags: null
type: Microsoft.ContainerInstance/containerGroups
다음 명령을 실행하여 앞에 있는 YAML 구성으로 이 컨테이너 그룹을 배포합니다.
az container create --resource-group myResourceGroup --name livenesstest -f liveness-probe.yaml
시작 명령
이 배포에는 컨테이너가 처음 실행을 시작할 때 실행되는 시작 명령이 정의된 command 속성이 포함되어 있습니다. 이 속성에는 문자열 배열이 사용됩니다. 이 명령은 비정상 상태를 입력하는 컨테이너를 시뮬레이션 합니다.
먼저 bash 세션을 시작하고 /tmp 디렉터리 내에 healthy라는 파일을 작성합니다. 그 후 30초 동안 대기했다가 파일을 삭제하고 10분간 대기합니다.
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
활동성 명령
이 배포는 활동성 검사 역할을 하는 exec 활동성 명령을 지원하는 livenessProbe를 정의합니다. 이 명령이 0이 아닌 값으로 종료되면 컨테이너가 종료되고 다시 시작되어 healthy 파일을 찾을 수 없다는 신호를 보냅니다. 이 명령이 종료 코드 0으로 무사히 종료되면 아무 작업도 수행되지 않습니다.
periodSeconds 속성은 활동성 명령을 5초마다 실행해야 한다고 지정합니다.
활동성 출력 확인
처음 30초 안에는 시작 명령에서 만든 healthy 파일이 존재합니다. 활동성 명령이 healthy 파일의 존재 여부를 확인하면 상태 코드에서는 성공을 알리는 0을 반환하므로 다시 시작이 발생하지 않습니다.
30초 후 cat /tmp/healthy 명령이 실패하고 비정상 및 중지 이벤트가 발생합니다.
이러한 이벤트는 Azure Portal 또는 Azure CLI에서 볼 수 있습니다.
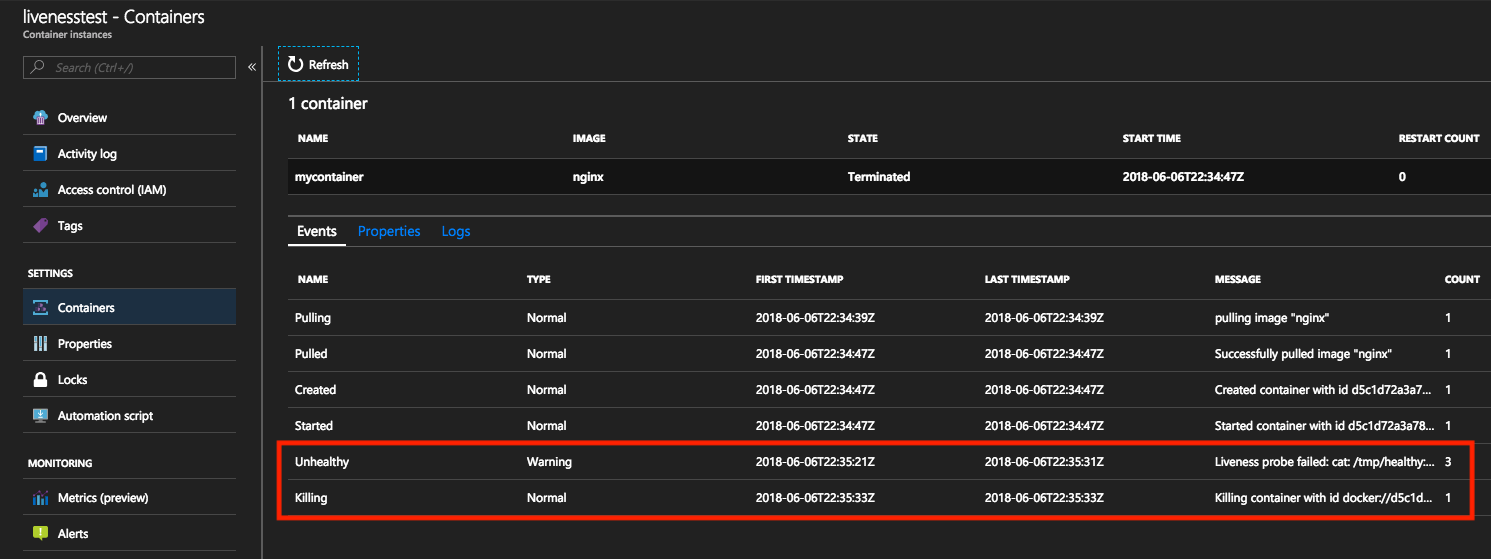
Azure Portal에서 이벤트를 보면 Unhealthy 형식의 이벤트는 활동성 명령이 실패하는 즉시 트리거됩니다. 후속 이벤트는 Killing 형식이며, 다시 시작될 수 있도록 컨테이너 삭제를 나타냅니다. 이 이벤트가 발생할 때마다 컨테이너의 다시 시작 횟수가 증가합니다.
다시 시작이 즉시 완료되므로 공용 IP 주소나 노드 관련 콘텐츠 같은 리소스는 그대로 유지됩니다.

활동성 프로브가 지속적으로 실패하여 다시 시작을 너무 많이 트리거하면 컨테이너의 백오프 지연이 급격하게 증가합니다.
활동성 프로브 및 다시 시작 정책
다시 시작 정책은 활동성 프로브에 의해 트리거되는 다시 시작 동작보다 우선합니다. 예를 들어 restartPolicy = Never 및 활동성 프로브를 설정하면 활동성 검사 실패 시 컨테이너 그룹이 다시 시작되지 않습니다. 그 대신 컨테이너 그룹은 컨테이너 그룹의 다시 시작 정책 Never를 따릅니다.
다음 단계
필수 구성 요소 함수가 제대로 작동하지 않는 경우 자동으로 다시 시작되도록 설정하려면 작업 기반 시나리오는 활동성 프로브가 필요할 수 있습니다. 작업 기반 컨테이너 실행에 대한 자세한 내용은 Azure Container Instances에서 컨테이너화된 작업 실행을 참조하세요.