적용 대상:
![]() 카산드라
카산드라
이 문서에서는 Azure Cosmos DB for Apache Cassandra에서 분할이 작동하는 방식을 설명합니다.
API for Cassandra는 애플리케이션의 성능 요구 사항을 충족하기 위해 분할을 사용하여 키스페이스의 개별 테이블을 스케일링합니다. 테이블의 각 레코드와 연결된 파티션 키 값에 따라 파티션이 구성됩니다. 파티션의 모든 레코드에는 동일한 파티션 키 값이 있습니다. Azure Cosmos DB는 테이블의 스케일링 수준 및 성능 요구 사항을 효율적으로 충족하기 위해 물리적 리소스에 파티션을 배치하는 작업을 투명하게 자동으로 관리합니다. 애플리케이션의 처리량 및 스토리지 요구 사항이 증가함에 따라 Azure Cosmos DB는 더 많은 물리적 머신 간에 데이터를 이동하고 균형을 조정합니다.
개발자 관점에서 분할은 네이티브 Apache Cassandra에서와 동일한 방식으로 Azure Cosmos DB for Apache Cassandra에서 작동합니다. 그러나 이면에는 몇 가지 차이점이 있습니다.
Apache Cassandra 및 Azure Cosmos DB 간 차이점
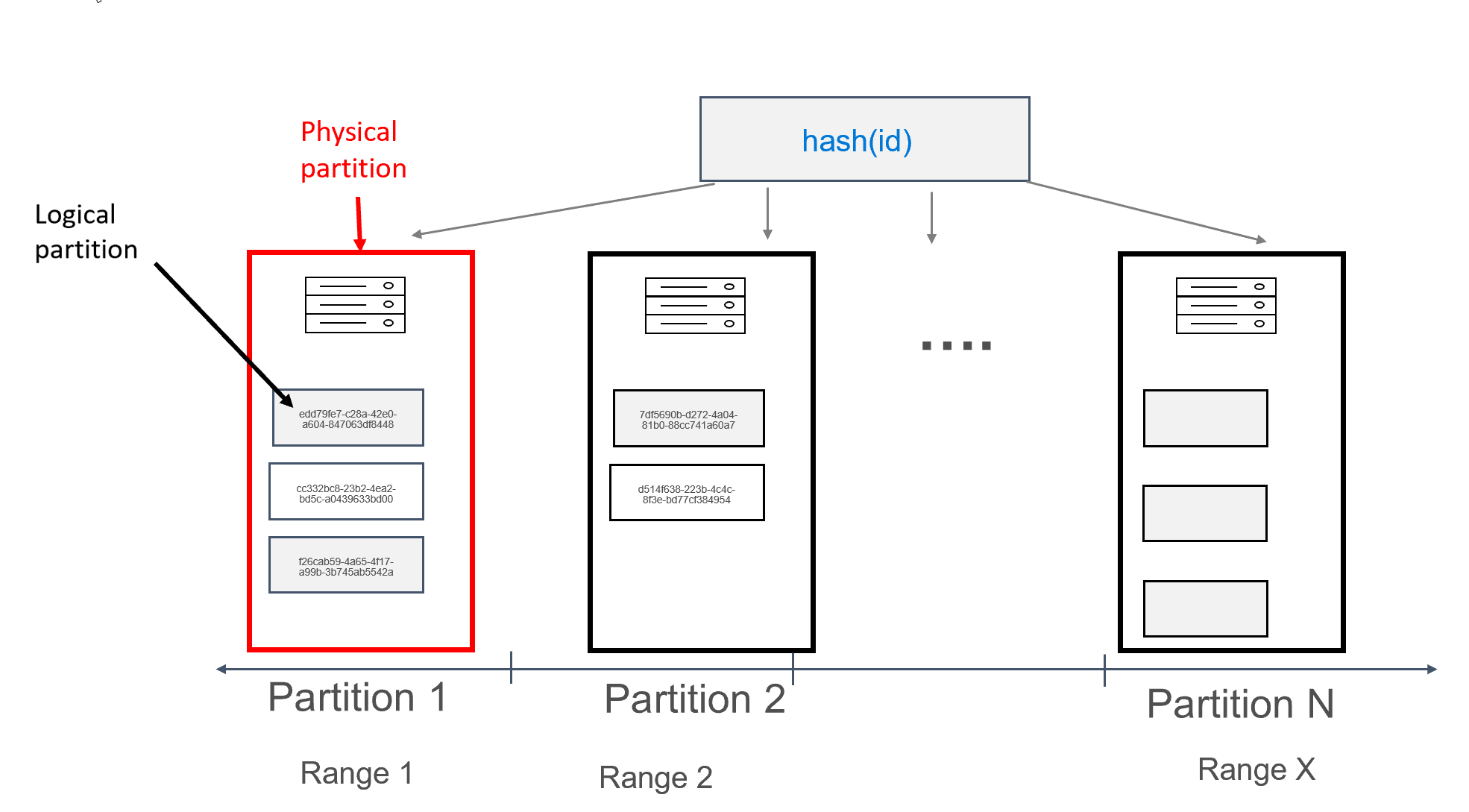
Azure Cosmos DB에서는 파티션이 저장되는 각 머신 자체를 물리적 파티션이라고 합니다. 물리적 파티션은 가상 머신과 유사한, 전용 컴퓨팅 단위 또는 물리적 리소스 세트입니다. Azure Cosmos DB에서는 이 컴퓨팅 단위에 저장된 각 파티션을 논리 파티션이라고 합니다. Apache Cassandra에 이미 익숙한 경우 Cassandra의 일반 파티션과 동일한 방식으로 논리 파티션을 간주할 수 있습니다.
Apache Cassandra에서는 파티션에 저장할 수 있는 데이터 크기를 100MB로 제한하는 것이 좋습니다. Azure Cosmos DB용 API for Cassandra는 논리 파티션당 최대 20GB, 물리적 파티션당 최대 30GB의 데이터를 허용합니다. Apache Cassandra와 달리 Azure Cosmos DB에서는 물리적 파티션에서 사용할 수 있는 컴퓨팅 용량이 요청 단위라는 단일 메트릭을 사용하여 표시되므로 코어, 메모리 또는 IOPS가 아닌 초당 요청(읽기 또는 쓰기) 수 측면에서 워크로드를 측정할 수 있습니다. 따라서 각 요청의 비용을 파악한 후 보다 간단하게 용량 계획을 세울 수 있습니다. 각 물리적 파티션에서 최대 10,000RU의 컴퓨팅을 사용할 수 있습니다. 스케일링 수준 옵션에 대한 자세한 내용은 API for Cassandra의 탄력적 스케일링에 대한 문서를 참조하세요.
Azure Cosmos DB에서 각 물리적 파티션은 복제본 세트라고도 하는 복제본 집합으로 구성되며, 파티션당 4개 이상의 복제본을 포함합니다. 반면에, Apache Cassandra에서는 복제 계수를 1로 설정할 수 있습니다. 그러나 이 경우, 데이터를 포함하는 유일한 노드가 중단되면 가용성이 낮아집니다. API for Cassandra에는 항상 복제 계수 4(쿼럼 3)가 있습니다. Azure Cosmos DB는 복제본 세트를 자동으로 관리하는 반면, Apache Cassandra에서는 다양한 도구를 사용하여 유지 관리해야 합니다.
Apache Cassandra에는 파티션 키의 해시인 토큰 개념이 있습니다. 토큰은 murmur3 64바이트 해시를 기반으로 하고, 값은 -2^63에서 -2^63 - 1 사이입니다. Apache Cassandra에서는 이 범위를 일반적으로 “토큰 링”이라고 합니다. 토큰 링은 토큰 범위에 배포되고, 네이티브 Apache Cassandra 클러스터에 있는 노드 간에 범위가 나뉩니다. Azure Cosmos DB의 분할도 유사한 방식으로 구현됩니다. 단, 다른 해시 알고리즘이 사용되고 내부 토큰 링이 더 큽니다. 그러나 외부적으로는 Apache Cassandra와 동일한 토큰 범위(즉, -2^63에서 -2^63 - 1 사이)가 노출됩니다.
기본 키
API for Cassandra의 모든 테이블에는 primary key가 정의되어 있어야 합니다. 기본 키의 구문은 다음과 같습니다.
column_name cql_type_definition PRIMARY KEY
여러 사용자의 메시지를 저장하는 사용자 테이블을 만든다고 가정합니다.
CREATE TABLE uprofile.user (
id UUID PRIMARY KEY,
user text,
message text);
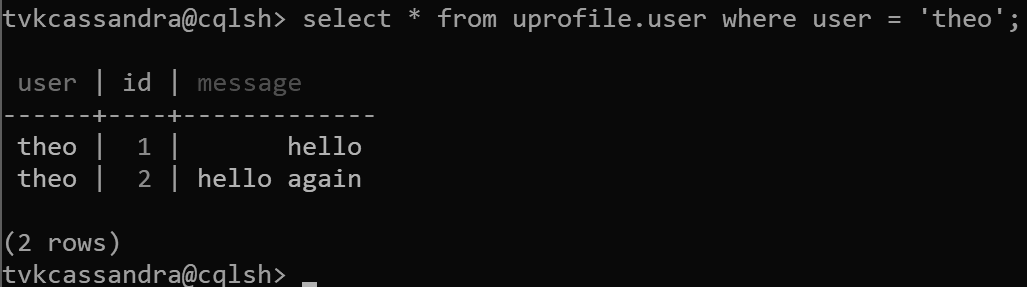
이 디자인에서는 id 필드를 기본 키로 정의했습니다. 기본 키는 테이블 레코드의 식별자 역할을 하며, Azure Cosmos DB에서 파티션 키로도 사용됩니다. 기본 키가 앞에서 설명한 방식으로 정의된 경우 각 파티션에는 단일 레코드만 있습니다. 따라서 데이터베이스에 데이터를 쓸 때 완벽하게 수평을 이루고 스케일링 가능한 배포가 가능하며, 키-값 조회 사용 사례에 적합합니다. 애플리케이션은 읽기 성능을 최대화하기 위해 테이블에서 데이터를 읽을 때마다 기본 키를 제공해야 합니다.
복합 기본 키
Apache Cassandra에는 compound keys 개념도 있습니다. 복합 primary key는 둘 이상의 열로 구성됩니다. 첫 번째 열은 partition key이고, 추가 열은 clustering keys입니다.
compound primary key의 구문은 다음과 같습니다.
PRIMARY KEY (partition_key_column_name, clustering_column_name [, ...])
위의 디자인을 변경하여 지정된 사용자의 메시지를 효율적으로 검색할 수 있도록 한다고 가정합니다.
CREATE TABLE uprofile.user (
user text,
id int,
message text,
PRIMARY KEY (user, id));
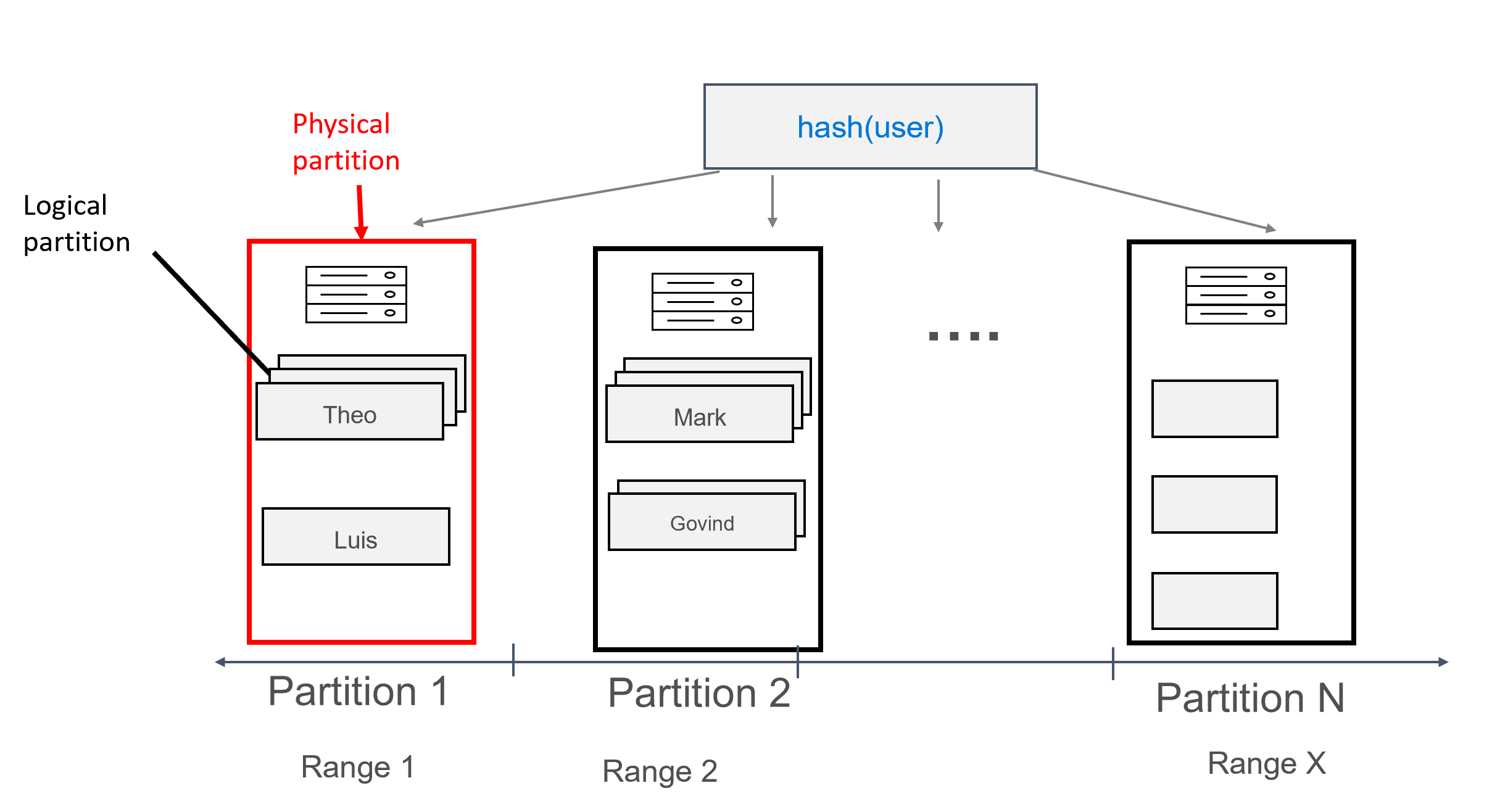
이 디자인에서는 이제 user를 파티션 키로, id를 클러스터링 키로 정의합니다. 클러스터링 키를 원하는 개수만큼 정의할 수 있지만, 동일한 파티션에 여러 레코드가 추가되도록 하려면 클러스터링 키의 각 값(또는 값 조합)이 고유해야 합니다. 예를 들면 다음과 같습니다.
insert into uprofile.user (user, id, message) values ('theo', 1, 'hello');
insert into uprofile.user (user, id, message) values ('theo', 2, 'hello again');
반환 시 데이터가 Apache Cassandra에서 예상한 대로 클러스터링 키로 정렬됩니다.
경고
복합 기본 키가 있는 테이블의 데이터를 쿼리할 때 클러스터링 키를 제외하고 파티션 키 및 다른 인덱싱되지 않은 필드를 필터링하려면 보조 인덱스를 파티션 키에 명시적으로 추가해야 합니다.
CREATE INDEX ON uprofile.user (user);
Azure Cosmos DB for Apache Cassandra는 기본적으로 파티션 키에 인덱스를 적용하지 않으며 이 시나리오의 인덱스는 쿼리 성능을 크게 개선시킬 수 있습니다. 자세한 내용은 보조 인덱싱에 대한 문서를 검토합니다.
데이터가 이런 방식으로 모델링된 경우 여러 레코드를 사용자별로 그룹화하여 각 파티션에 할당할 수 있습니다. 따라서 partition key(예제에서는 user)를 통해 효율적으로 라우팅되는 쿼리를 실행하여 지정된 사용자의 모든 메시지를 가져올 수 있습니다.
복합 파티션 키
복합 파티션 키는 기본적으로 복합 키와 동일한 방식으로 작동합니다. 단, 여러 열을 복합 파티션 키로 지정할 수 있습니다. 복합 파티션 키의 구문은 다음과 같습니다.
PRIMARY KEY (
(partition_key_column_name[, ...]),
clustering_column_name [, ...]);
예를 들어 firstname 및 lastname의 고유 조합이 파티션 키를 구성하고 id가 클러스터링 키인 다음 구문을 사용할 수 있습니다.
CREATE TABLE uprofile.user (
firstname text,
lastname text,
id int,
message text,
PRIMARY KEY ((firstname, lastname), id) );
다음 단계
- Azure Cosmos DB의 분할 및 수평적 스케일링에 대해 알아봅니다.
- Azure Cosmos DB에서 프로비전된 처리량에 대한 자세한 정보
- Azure Cosmos DB에서 글로벌 배포에 대한 자세한 정보