적용 대상:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() 카산드라
카산드라
![]() 그렘린
그렘린
![]() 테이블
테이블
Azure Cosmos DB는 스키마에 구애되지 않는 데이터베이스로, 스키마나 인덱스 관리를 처리하지 않고도 애플리케이션을 반복할 수 있습니다. 기본적으로 Azure Cosmos DB는 스키마 정의나 보조 인덱스 구성 없이도 컨테이너의 전체 항목에 대해 모든 자산을 자동으로 인덱싱합니다.
이 문서에서는 Azure Cosmos DB가 데이터를 인덱싱하는 방법과 인덱스를 사용하여 쿼리 성능을 향상시키는 방법을 설명합니다. 인덱싱 정책을 사용자 지정하는 방법을 살펴보기 전에 이 섹션을 진행하는 것이 좋습니다.
항목에서 트리로
항목이 컨테이너에 저장될 때마다 해당 콘텐츠는 JSON 문서에 프로젝션된 다음, 트리 표현으로 변환됩니다. 이 변환은 해당 항목의 모든 속성이 트리의 노드로 표시됨을 의미합니다. 의사 루트 노드는 항목의 모든 1단계 속성을 부모로 하여 만들어집니다. 리프 노드에는 항목에서 전달하는 실제 스칼라 값이 포함됩니다.
다음 항목을 예로 들어 보겠습니다.
{
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
이 트리는 예제 JSON 항목을 나타냅니다.
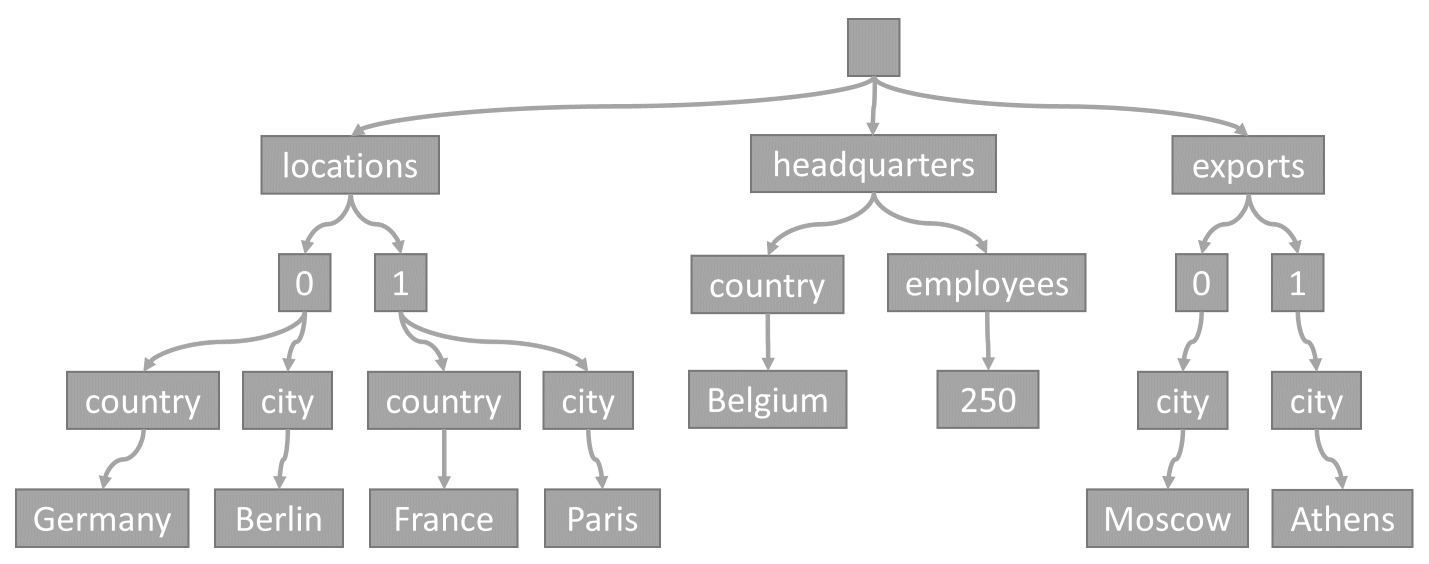
배열이 트리에 인코딩되는 방법을 살펴보면, 배열의 모든 항목이 배열 내 해당 항목의 인덱스로 레이블이 지정된 중간 노드를 갖습니다(0, 1 등).
트리에서 속성 경로
Azure Cosmos DB는 시스템에서 해당 트리 내의 경로를 사용하여 속성을 참조할 수 있기 때문에 항목을 트리로 변환합니다. 속성의 경로를 가져오기 위해 루트 노드에서 해당 속성까지 트리를 트래버스하고 트래버스한 각 노드의 레이블을 연결할 수 있습니다.
이전에 설명한 예제 항목의 각 속성에 대한 경로는 다음과 같습니다.
-
/locations/0/country: "독일" -
/locations/0/city: "베를린" -
/locations/1/country: "프랑스" -
/locations/1/city: "파리" -
/headquarters/country: "벨기에" -
/headquarters/employees: 250 -
/exports/0/city: "모스코바" -
/exports/1/city: "아테네"
Azure Cosmos DB는 항목이 기록될 때 각 속성의 경로와 해당 값을 효과적으로 인덱싱합니다.
인덱스 형식
Azure Cosmos DB는 현재 3가지 유형의 인덱스를 지원합니다. 이러한 인덱스 유형은 인덱싱 정책을 정의할 때 구성할 수 있습니다.
범위 인덱스
범위 인덱스는 순서가 지정된 트리형 구조를 기반으로 합니다. 범위 인덱스 유형의 용도는 다음과 같습니다.
등호 쿼리:
SELECT * FROM container c WHERE c.property = 'value'SELECT * FROM c WHERE c.property IN ("value1", "value2", "value3")배열 요소에서 등호 일치
SELECT * FROM c WHERE ARRAY_CONTAINS(c.tags, "tag1")범위 쿼리:
SELECT * FROM container c WHERE c.property > 'value'참고
>,<,>=,<=,!=에 대한 작업속성이 있는지 확인:
SELECT * FROM c WHERE IS_DEFINED(c.property)문자열 시스템 함수:
SELECT * FROM c WHERE CONTAINS(c.property, "value")SELECT * FROM c WHERE STRINGEQUALS(c.property, "value")ORDER BY쿼리:SELECT * FROM container c ORDER BY c.propertyJOIN쿼리:SELECT child FROM container c JOIN child IN c.properties WHERE child = 'value'
범위 인덱스는 스칼라 값(문자열 또는 숫자)에 사용할 수 있습니다. 새로 만든 컨테이너에 대한 기본 인덱싱 정책은 모든 문자열 또는 숫자에 대해 범위 인덱스를 적용합니다. 범위 인덱스를 구성하는 방법을 알아보려면 Azure Cosmos DB에서 인덱싱 정책 관리를 참조하세요.
참고
단일 속성으로 정렬하는 절은 ORDER BY항상 범위 인덱스가 필요하며 참조하는 경로에 범위 인덱스가 없으면 실패합니다. 마찬가지로 여러 ORDER BY 속성으로 정렬되는 쿼리에는 항상 복합 인덱스가 필요합니다.
공간 인덱스
공간 인덱스를 사용하면 점, 선, 다각형 및 다각형과 같은 지리 공간 개체에 대해 효율적인 쿼리를 수행할 수 있습니다. 이러한 쿼리는 , ST_DISTANCEST_WITHIN 키워드를 사용합니다ST_INTERSECTS. 공간 인덱스 유형을 사용하는 몇 가지 예제는 다음과 같습니다.
지리 공간적 거리 쿼리:
SELECT * FROM container c WHERE ST_DISTANCE(c.property, { "type": "Point", "coordinates": [0.0, 10.0] }) < 40쿼리 내 지리 공간:
SELECT * FROM container c WHERE ST_WITHIN(c.property, {"type": "Point", "coordinates": [0.0, 10.0] })지리 공간적 교차 쿼리:
SELECT * FROM c WHERE ST_INTERSECTS(c.property, { 'type':'Polygon', 'coordinates': [[ [31.8, -5], [32, -5], [31.8, -5] ]] })
공간 인덱스는 올바른 형식의 GeoJSON 개체에 사용할 수 있습니다. 현재 점, 선 문자열, 다각형 및 다중 다각형이 지원됩니다. 공간 인덱스를 구성하는 방법을 알아보려면 Azure Cosmos DB에서 인덱싱 정책 관리를 참조하세요.
복합 인덱스
복합 인덱스는 여러 필드에 대해 작업을 수행할 때 효율성을 높입니다. 복합 인덱스 유형의 용도는 다음과 같습니다.
여러 속성에 대한
ORDER BY쿼리:SELECT * FROM container c ORDER BY c.property1, c.property2필터 및
ORDER BY를 사용하여 쿼리합니다. 이러한 쿼리는 필터 속성이ORDER BY절에 추가된 경우 복합 인덱스를 활용할 수 있습니다.SELECT * FROM container c WHERE c.property1 = 'value' ORDER BY c.property1, c.property2최소한 하나 이상의 속성이 동등 필터인 두 개 이상의 속성에 대한 필터가 있는 쿼리:
SELECT * FROM container c WHERE c.property1 = 'value' AND c.property2 > 'value'
하나의 필터 조건자가 인덱스 형식 중 하나를 사용하는 한, 쿼리 엔진은 나머지를 검사하기 전에 먼저 이를 평가합니다. 예를 들어 다음과 같은 SELECT * FROM c WHERE c.firstName = "Andrew" and CONTAINS(c.lastName, "Liu")SQL 쿼리가 있는 경우
이 쿼리는 먼저 인덱스를 사용하여 firstName = "Andrew"인 항목을 필터링합니다. 그런 다음, 모든 firstName = "Andrew" 항목을 후속 파이프라인을 통해 전달하여 CONTAINS 필터 조건자를 평가합니다.
CONTAINS와 같은 전체 검사를 수행하는 함수를 사용하면 쿼리 속도를 높이고 전체 컨테이너 검사를 방지할 수 있습니다. 인덱스를 사용하여 이러한 쿼리 속도를 높이는 필터 조건자를 더 추가할 수 있습니다. 필터 절의 순서는 중요하지 않습니다. 쿼리 엔진이 더 선택적인 조건자를 파악하고 그에 따라 쿼리를 실행합니다.
복합 인덱스를 구성하는 방법을 알아보려면 Azure Cosmos DB에서 인덱싱 정책 관리를 참조하세요.
벡터 인덱스
벡터 인덱스는 VectorDistance 시스템 함수를 사용하여 벡터 검색을 수행할 때 효율성을 높입니다. 벡터 검색은 벡터 인덱스 사용 시 대기 시간이 훨씬 짧고 처리량이 높으며 RU 사용량이 줄어듭니다. NoSQL용 Azure Cosmos DB는 크기가 4,096인 모든 벡터 포함(텍스트, 이미지, 멀티모달 등)을 지원합니다.
벡터 인덱스를 구성하는 방법을 알아보려면 벡터 인덱싱 정책 예제를 참조하세요.
ORDER BY벡터 검색 쿼리:SELECT TOP 10 * FROM c ORDER BY VectorDistance(c.vector1, c.vector2)벡터 검색 쿼리의 유사성 점수 프로젝션:
SELECT TOP 10 c.name, VectorDistance(c.vector1, c.vector2) AS SimilarityScore FROM c ORDER BY VectorDistance(c.vector1, c.vector2)유사성 점수에 대한 범위 필터입니다.
SELECT TOP 10 * FROM c WHERE VectorDistance(c.vector1, c.vector2) > 0.8 ORDER BY VectorDistance(c.vector1, c.vector2)
중요합니다
현재 벡터 정책과 벡터 인덱스는 만들기 후 변경할 수 없습니다. 변경하려면 새 컬렉션을 만듭니다.
인덱스 사용
쿼리 엔진에서 쿼리 필터를 평가할 수 있는 5가지 방법이 있습니다. 가장 효율적인 순으로 정렬됩니다. 아래에는 가장 효율적인 방법에서 가장 덜 효율적인 방법으로의 순으로 정렬되어 있습니다.
- 인덱스 검색
- 정확한 인덱스 검사
- 확장된 인덱스 검사
- 전체 인덱스 검사
- 전체 검사
속성 경로를 인덱싱하면 쿼리 엔진에서 자동으로 인덱스를 최대한 효율적으로 사용합니다. 새 속성 경로를 인덱싱하는 것 외에는 쿼리에서 인덱스를 사용하는 방법을 최적화하기 위해 아무것도 구성할 필요가 없습니다. 쿼리의 RU 요금은 인덱스 사용 RU 요금과 항목 로드 RU 요금의 조합입니다.
다음 표에서는 Azure Cosmos DB에서 인덱스를 사용하는 다양한 방법을 요약합니다.
| 인덱스 조회 유형 | 설명 | 일반적인 예제 | 인덱스 사용 RU 요금 | 트랜잭션 데이터 저장소에서 항목을 로드하는 데 따른 RU 요금 |
|---|---|---|---|---|
| 인덱스 검색 | 인덱싱된 필요한 값만 읽기 및 트랜잭션 데이터 저장소에서 일치하는 항목만 로드 | 같음 필터, IN | 같음 필터당 상수 | 쿼리 결과의 항목 수에 따라 증가 |
| 정확한 인덱스 검사 | 인덱싱된 값의 이진 검색 및 트랜잭션 데이터 저장소에서 일치하는 항목만 로드 | 범위 비교(>, <, <= 또는 >=), StartsWith | 인덱스 검색과 비슷함, 인덱싱된 속성의 카디널리티에 따라 약간 증가 | 쿼리 결과의 항목 수에 따라 증가 |
| 확장된 인덱스 검사 | 인덱싱된 값의 최적화된 검색(그러나 이진 검색보다 효율성이 낮음) 및 트랜잭션 데이터 저장소에서 일치하는 항목만 로드 | StartsWith(대/소문자 구분 안 함), StringEquals(대/소문자 구분 안 함) | 인덱싱된 속성의 카디널리티에 따라 약간 증가 | 쿼리 결과의 항목 수에 따라 증가 |
| 전체 인덱스 검사 | 인덱싱된 값의 고유 집합 읽기 및 트랜잭션 데이터 저장소에서 일치하는 항목만 로드 | Contains, EndsWith, RegexMatch, LIKE | 인덱싱된 속성의 카디널리티에 따라 선형적으로 증가 | 쿼리 결과의 항목 수에 따라 증가 |
| 전체 검사 | 트랜잭션 데이터 저장소에서 모든 항목 로드 | Upper, Lower | 해당 없음 | 컨테이너의 항목 수에 따라 증가 |
쿼리를 작성하는 경우 인덱스를 최대한 효율적으로 사용하는 필터 조건자를 사용해야 합니다. 예를 들어 StartsWith 또는 Contains 중 하나가 사용 사례에 적합한 경우 전체 인덱스 검사 대신 정확한 인덱스 검사를 수행하므로 StartsWith를 선택해야 합니다.
인덱스 사용 세부 정보
이 섹션에서는 쿼리에서 인덱스를 사용하는 방법에 대해 자세히 설명합니다. 이 수준의 세부 정보는 Azure Cosmos DB를 시작하는 방법을 배울 필요는 없지만 호기심 많은 사용자를 위해 자세히 설명되어 있습니다. 이 문서의 앞부분에서 공유한 예제 항목을 참조합니다.
예제 항목:
{
"id": 1,
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
{
"id": 2,
"locations": [
{ "country": "Ireland", "city": "Dublin" }
],
"headquarters": { "country": "Belgium", "employees": 200 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" },
{ "city": "London" }
]
}
Azure Cosmos DB는 반전된 인덱스를 사용합니다. 인덱스는 각 JSON 경로를 해당 값이 포함된 항목 집합에 매핑하여 작동합니다. 항목 ID 매핑은 컨테이너에 대한 다양한 인덱스 페이지에서 표시됩니다. 다음은 두 가지 예제 항목을 포함하는 컨테이너에 대한 반전된 인덱스의 샘플 다이어그램입니다.
| 경로 | 값 | 항목 ID 목록 |
|---|---|---|
| /locations/0/국가 | 독일 | 1 |
| /locations/0/국가 | 아일랜드 | 2 |
| /locations/0/city | 베를린 | 1 |
| /locations/0/city | 더블린 | 2 |
| /locations/1/country | 프랑스 | 1 |
| /locations/1/city | 파리 | 1 |
| /본사/국가 | 벨기에 | 1, 2 |
| /본사/직원 | 200 | 2 |
| /본사/직원 | 250 | 1 |
반전된 인덱스에는 두 가지 중요한 특성이 있습니다.
- 지정된 경로에 대한 값은 오름차순으로 정렬됩니다. 따라서 쿼리 엔진은 인덱스에서
ORDER BY를 쉽게 제공할 수 있습니다. - 지정된 경로에 대해 쿼리 엔진은 가능한 값의 고유 집합을 검사하여 결과가 있는 인덱스 페이지를 식별할 수 있습니다.
쿼리 엔진은 다음 네 가지 방법으로 반전된 인덱스를 활용할 수 있습니다.
인덱스 검색
다음과 같은 쿼리를 고려해 보세요.
SELECT location
FROM location IN company.locations
WHERE location.country = 'France'
쿼리 조건자(위치가 국가 또는 지역으로 "프랑스"인 항목 필터링)는 이 다이어그램에 강조 표시된 경로와 일치합니다.
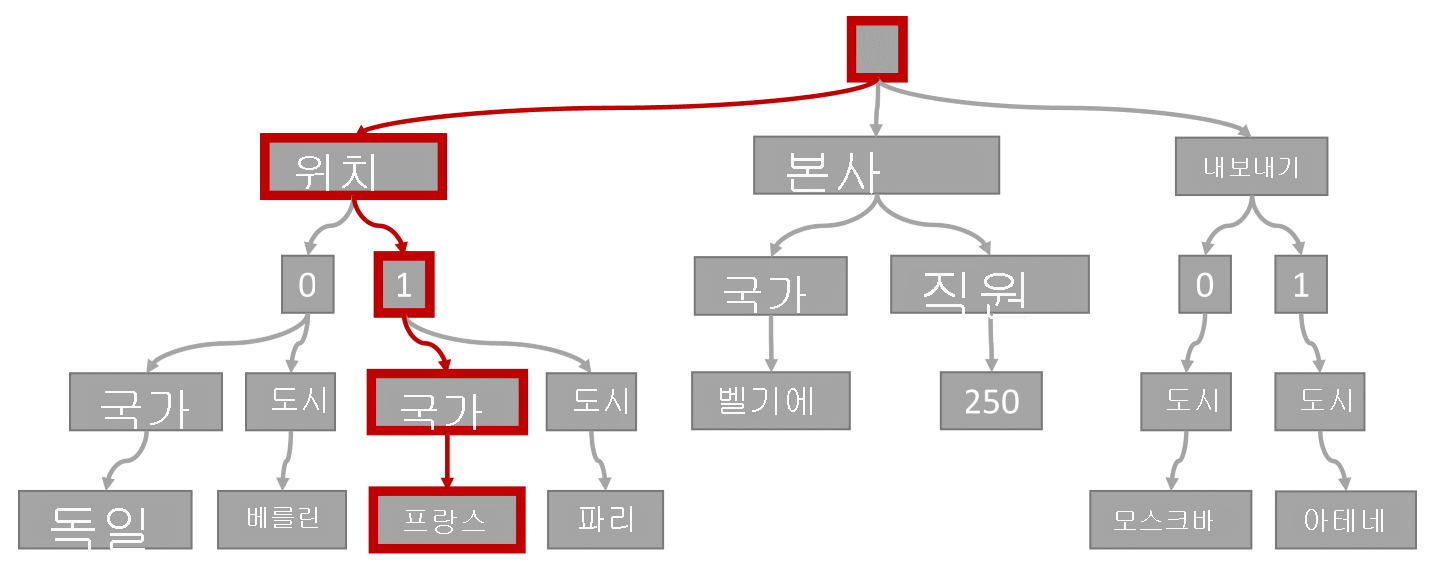
이 쿼리에는 같음 필터가 있으므로 이 트리를 트래버스한 후에 쿼리 결과가 포함된 인덱스 페이지를 빠르게 식별할 수 있습니다. 이 경우 쿼리 엔진에서 항목 1이 포함된 인덱스 페이지를 읽습니다. 인덱스 검색은 인덱스를 사용하는 가장 효율적인 방법입니다. 인덱스 검색을 사용하면 필요한 인덱스 페이지만 읽고 쿼리 결과의 항목만 로드합니다. 따라서 인덱스 조회 시간과 인덱스 조회 RU 요금은 총 데이터 볼륨에 관계없이 매우 낮습니다.
정확한 인덱스 검사
다음과 같은 쿼리를 고려해 보세요.
SELECT *
FROM company
WHERE company.headquarters.employees > 200
쿼리 조건자(직원 수가 200명을 초과하는 항목 필터링)는 headquarters/employees 경로의 정확한 인덱스 검사를 통해 평가할 수 있습니다. 정확한 인덱스 검사를 수행하는 경우 쿼리 엔진은 가능한 값의 고유 집합에 대한 이진 검색을 수행하여 200 경로에 대한 값(headquarters/employees)의 위치를 찾는 것으로 시작합니다. 각 경로의 값은 오름차순으로 정렬되므로 쿼리 엔진에서 이진 검색을 쉽게 수행할 수 있습니다. 쿼리 엔진에서 값(200)을 찾으면 나머지 인덱스 페이지를 모두 읽기 시작합니다(오름차순으로 이동).
쿼리 엔진은 불필요한 인덱스 페이지 검사를 방지하기 위해 이진 검색을 수행할 수 있으므로 정확한 인덱스 검사에는 인덱스 검색 작업과 비슷한 대기 시간과 RU 요금이 포함되는 경향이 있습니다.
확장된 인덱스 검사
다음과 같은 쿼리를 고려해 보세요.
SELECT *
FROM company
WHERE STARTSWITH(company.headquarters.country, "United", true)
쿼리 조건자(대/소문자를 구분하지 않는 "United"로 시작하는 위치에 본사가 있는 항목 필터링)는 경로의 headquarters/country 확장된 인덱스 검색을 사용하여 평가할 수 있습니다. 확장된 인덱스 검사를 수행하는 작업에는 모든 인덱스 페이지를 검사할 필요가 없도록 방지하는 데 도움이 되는 최적화가 있지먄, 정확한 인덱스 검사의 이진 검색보다 약간 더 많은 비용이 들어갑니다.
예를 들어 대/소문자를 구분하지 않는 StartsWith를 평가하는 경우 쿼리 엔진은 인덱스에서 대문자 및 소문자 값의 가능한 다른 조합을 확인합니다. 이 최적화를 통해 쿼리 엔진에서 대부분의 인덱스 페이지를 읽지 않아도 됩니다. 시스템 함수마다 모든 인덱스 페이지를 읽지 않도록 방지하는 데 사용할 수 있는 최적화가 다르므로 확장된 인덱스 검사로 광범위하게 분류합니다.
전체 인덱스 검사
다음과 같은 쿼리를 고려해 보세요.
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
쿼리 조건자("United"가 포함된 위치에 본사가 있는 항목 필터링)는 headquarters/country 경로의 인덱스 검사를 통해 평가할 수 있습니다. 정확한 인덱스 검사와 달리 전체 인덱스 검사는 항상 가능한 값의 고유 집합을 검사하여 결과가 있는 인덱스 페이지를 식별합니다. 이 경우 인덱스에서 CONTAINS가 실행됩니다. 경로의 카디널리티가 증가함에 따라 인덱스 검사에 대한 인덱스 조회 시간 및 RU 요금이 증가합니다. 즉, 쿼리 엔진에서 검사해야 하는 고유한 값이 많을수록 전체 인덱스 검사를 수행하는 데 관련된 대기 시간과 RU 요금이 증가합니다.
예를 들어, town 및 country라는 두 가지 속성을 고려합니다. 도시의 카디널리티는 5,000이고 country의 카디널리티는 200입니다. 다음은 각각 속성에 대한 전체 인덱스 검사를 수행하는 CONTAINS 시스템 함수가 있는 두 가지 예제 쿼리입니다 town . 도시의 카디널리티가 country보다 높으므로 첫 번째 쿼리는 두 번째 쿼리보다 더 많은 RU를 사용합니다.
SELECT *
FROM c
WHERE CONTAINS(c.town, "Red", false)
SELECT *
FROM c
WHERE CONTAINS(c.country, "States", false)
전체 검사
경우에 따라 쿼리 엔진이 인덱스를 사용하여 쿼리 필터를 평가하지 못할 수 있습니다. 이 경우 쿼리 엔진은 쿼리 필터를 평가하기 위해 트랜잭션 저장소의 모든 항목을 로드해야 합니다. 전체 검사는 인덱스를 사용하지 않으며, 총 데이터 크기에 따라 선형적으로 증가하는 RU 요금이 있습니다. 다행히도 전체 검사가 필요한 작업은 드뭅니다.
정의된 벡터 인덱스가 없는 벡터 검색 쿼리
벡터 인덱스 정책을 정의하지 않고 VectorDistance 절에서 ORDER BY 시스템 함수를 사용하면 전체 검색이 수행되며, 이 경우 벡터 인덱스 정책을 정의했을 때보다 RU 요금이 더 높아집니다. 마찬가지로, VectorDistance를 사용하고 무차별 대입 방식의 불리언 값을 true로 설정했으나 벡터 경로에 대한 flat 인덱스가 정의되어 있지 않으면 전체 검색이 발생합니다.
복합 필터 식이 있는 쿼리
이전 예제에서는 단순 필터 식이 있는 쿼리(예: 단일 같음 또는 범위 필터만 있는 쿼리)만 고려했습니다. 실제로 대부분의 쿼리에는 훨씬 더 복잡한 필터 식이 있습니다.
다음과 같은 쿼리를 고려해 보세요.
SELECT *
FROM company
WHERE company.headquarters.employees = 200 AND CONTAINS(company.headquarters.country, "United")
이 쿼리를 실행하려면 쿼리 엔진에서 headquarters/employees에 대한 인덱스 검색과 headquarters/country에 대한 전체 인덱스 검사를 수행해야 합니다. 쿼리 엔진에는 쿼리 필터 식을 최대한 효율적으로 평가하는 데 사용하는 내부 추론이 있습니다. 이 경우 쿼리 엔진은 인덱스 검색을 먼저 수행하여 불필요한 인덱스 페이지를 읽을 필요가 없습니다. 예를 들어 50개의 항목만 같음 필터와 일치하는 경우 쿼리 엔진은 해당 50개의 항목이 포함된 인덱스 페이지에서 CONTAINS만 평가하면 됩니다. 전체 컨테이너에 대한 전체 인덱스 검사는 필요하지 않습니다.
스칼라 집계 함수에 대한 인덱스 사용률
집계 함수가 있는 쿼리는 전적으로 인덱스만 사용해야 합니다.
경우에 따라 인덱스에서 가양성을 반환할 수 있습니다. 예를 들어 인덱스로 CONTAINS 평가할 때 인덱스의 일치 항목 수가 쿼리 결과 수를 초과할 수 있습니다. 쿼리 엔진은 모든 인덱스 일치 항목을 로드하고, 로드된 항목에 대한 필터를 평가하고, 올바른 결과만 반환합니다.
대부분의 쿼리에서 가양성 인덱스 일치 항목을 로드해도 인덱스 사용률에 뚜렷한 영향을 주지 않습니다.
예를 들어 다음 쿼리를 참조하십시오.
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
시스템 함수는 CONTAINS 일부 잘못된 긍정 일치 항목을 반환할 수 있으므로, 쿼리 엔진은 로드된 각 항목이 필터 식과 일치하는지 확인해야 합니다. 이 예제에서 쿼리 엔진은 몇 가지 항목을 추가로 로드하기만 하면 되므로 인덱스 사용률 및 RU 요금에 미치는 영향은 최소화됩니다.
그러나 집계 함수가 있는 쿼리는 전적으로 해당 인덱스만 사용해야 합니다. 예를 들어 COUNT 집계가 있는 다음과 같은 쿼리를 고려합니다.
SELECT COUNT(1)
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
첫 번째 예제와 마찬가지로 시스템 함수는 CONTAINS 잘못된 긍정 일치 항목을 반환할 수 있습니다. 그러나 SELECT * 쿼리와 달리 COUNT 쿼리는 로드한 항목의 필터 식을 평가하여 모든 인덱스 일치 항목을 확인할 수 없습니다.
COUNT 쿼리는 전적으로 인덱스만 사용해야 하므로 필터 식이 가양성 일치 항목을 반환할 가능성이 있는 경우 쿼리 엔진에서 전체 검사를 사용합니다.
다음과 같은 집계 함수가 있는 쿼리는 전적으로 인덱스만 사용해야 하므로 일부 시스템 함수를 평가하려면 전체 검사가 필요합니다.