일대다 관계형 데이터를 Azure Cosmos DB for NoSQL 계정으로 마이그레이션
적용 대상: ![]() NoSQL
NoSQL
관계형 데이터베이스에서 Azure Cosmos DB for NoSQL로 마이그레이션하려면 최적화를 위해 데이터 모델을 변경해야 할 수 있습니다.
대표적인 변환은 단일 JSON 문서에 관련 하위 항목을 포함하여 데이터를 비정규화는 것입니다. 여기에는 Azure Data Factory 또는 Azure Databricks를 사용하는 몇 가지 옵션을 살펴보겠습니다. Azure Cosmos DB용 데이터 모델링에 관한 자세한 내용은 Azure Cosmos DB에서의 데이터 모델링을 참조하세요.
예제 시나리오
SQL 데이터베이스, Orders 및 OrderDetails에서 다음과 같은 테이블 두 개가 있다고 가정해보세요.
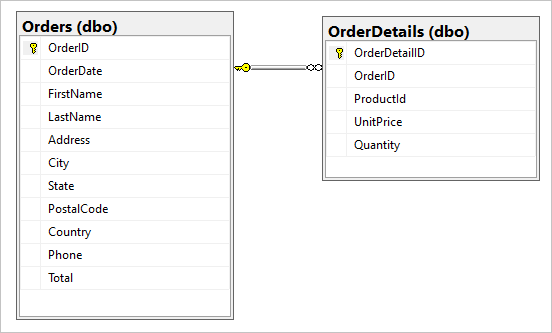
이 일대다 관계를 마이그레이션 과정에사 단일 JSON 문서로 결합하려 합니다. 단일 문서를 만들려면 FOR JSON을 사용하여 T-SQL 쿼리를 만듭니다.
SELECT
o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o;
이 쿼리의 결과에는 Orders 테이블의 데이터가 포함됩니다.

단일 Azure Data Factory(ADF) 복사 작업을 이용해 SQL 데이터를 원본으로 쿼리하고, 출력을 Azure Cosmos DB 싱크에 바로 적절한 JSON 개체로 쓰는 것이 가장 좋습니다. 현재는 복사 작업 한 번으로는 필요한 JSON 변환을 수행할 수 없습니다. 위의 쿼리 결과를 Azure Cosmos DB for NoSQL 컨테이너에 복사하면, 예상했던 JSON 배열 대신 OrderDetails 필드가 문서의 문자열 속성으로 표시됩니다.
다음 방법 중 하나를 사용하면 이러한 현재 제한을 해결할 수 있습니다.
- 복사 작업 두 개를 동원하여 Azure Data Factory 사용:
- JSON 형식 데이터를 SQL에서 중간 Blob Storage 위치로 가져오기
- JSON 텍스트 파일의 데이터를 Azure Cosmos DB에 있는 컨테이너에 로드합니다.
- Azure Databricks를 사용하여 SQL에서 읽고 Azure Cosmos DB에 쓰기 - 두 가지 옵션이 제공됩니다.
두 가지 접근 방법을 자세히 살펴보겠습니다.
Azure Data Factory
OrderDetails를 대상 Azure Cosmos DB 문서에 JSON 배열로 포함할 수는 없지만, 별도의 두 가지 복사 작업을 이용하면 문제를 해결할 수 있습니다.
복사 작업 #1: SqlJsonToBlobText
원본 데이터의 경우에는 SQL 쿼리를 사용하여 SQL Server OPENJSON 및 FOR JSON PATH 기능을 바탕으로 행당 하나의 JSON 개체(Order를 나타냄)가 있는 단일 열로 결과를 가져옵니다.
SELECT [value] FROM OPENJSON(
(SELECT
id = o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o FOR JSON PATH)
)
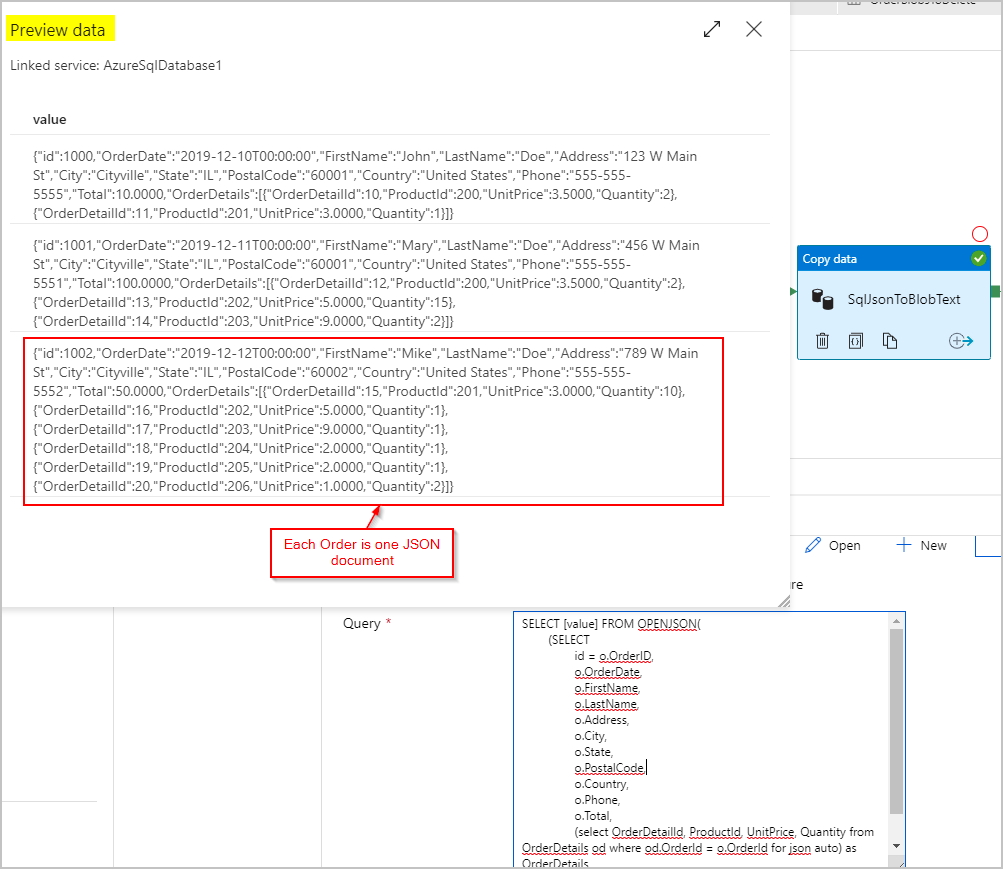
SqlJsonToBlobText 복사 작업 싱크의 경우 “구분된 텍스트”를 선택하고 Azure Blob Storage의 특정 폴더를 가리킵니다. 이 싱크에는 동적으로 생성된 고유 파일 이름(예: @concat(pipeline().RunId,'.json'))이 포함됩니다.
텍스트 파일은 실제로 “구분”되지 않으므로 쉼표를 사용하여 별도의 열로 구문 분석하지 않으려고 합니다. 또한 큰따옴표(")를 유지하고, “열 구분 기호”를 Tab("\t") 또는 데이터에 나타나지 않는 또 다른 문자로 설정한 다음, “따옴표”를 “따옴표 없음”으로 설정하려고 합니다.
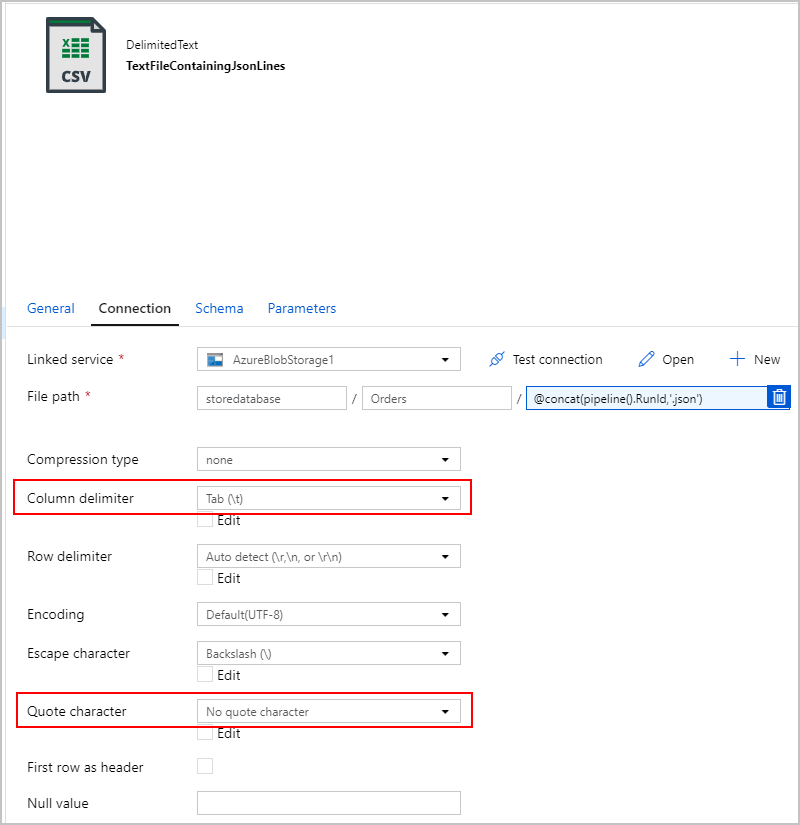
복사 작업 #2: BlobJsonToCosmos
그런 다음, 첫 번째 작업으로 생성한 텍스트 파일을 Azure Blob Storage에서 찾는 두 번째 복사 작업을 추가하여 ADF 파이프라인을 수정합니다. 이 작업은 텍스트 파일을 Azure Cosmos DB 싱크를 텍스트 파일에 있는 JSON 행당 하나의 문서로 삽입하는 "JSON" 소스로 처리합니다.
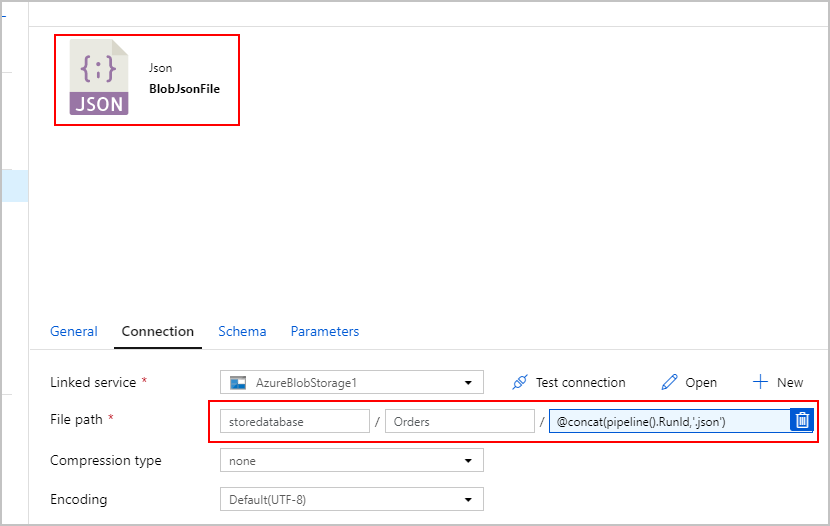
선택 사항으로, 매 실행 전에 /Orders/ 폴더에 남아 있는 이전 파일을 모두 삭제할 수 있도록 "Delete" 작업을 파이프라인에 추가했습니다. ADF 파이프라인이 이제 다음과 같이 표시될 것입니다.
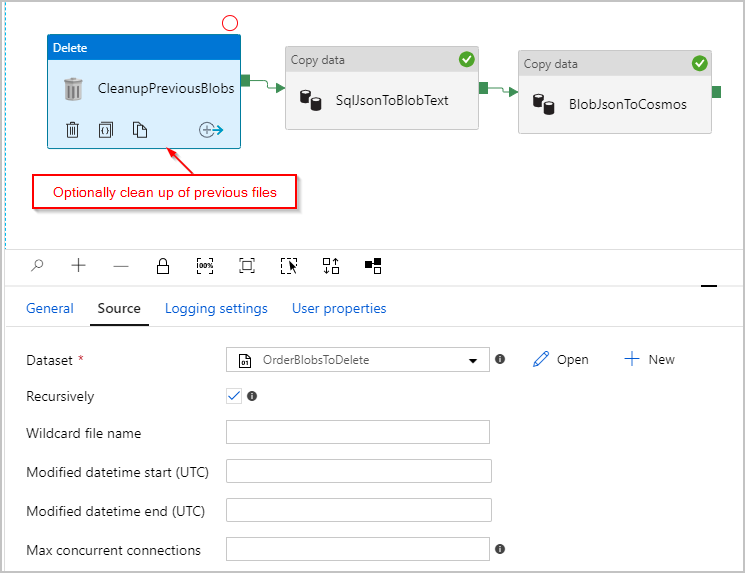
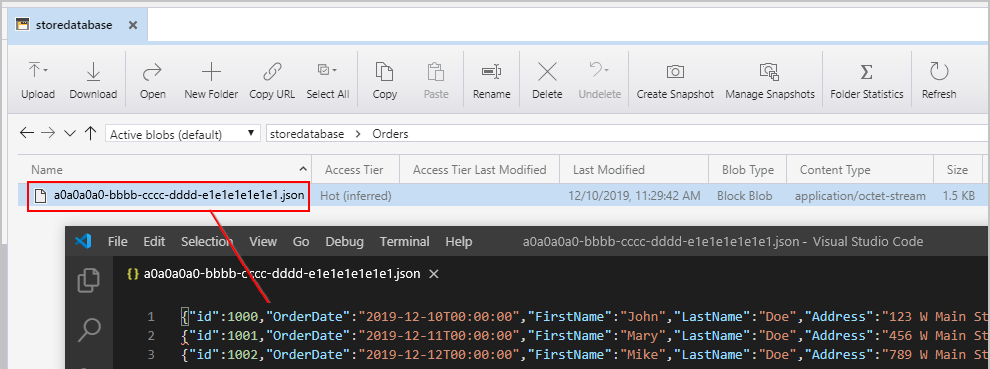
이전에 언급된 파이프라인을 트리거하면, 행당 JSON 개체가 하나씩 있는 중간 Azure Blob Storage 위치에서 파일이 생성됩니다.
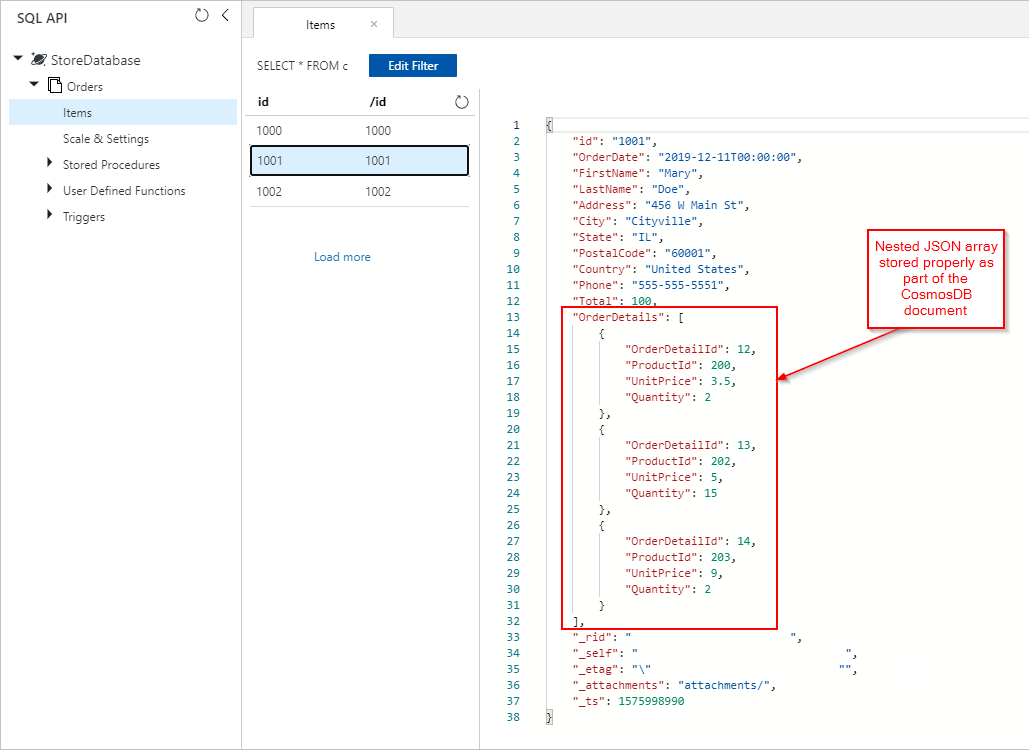
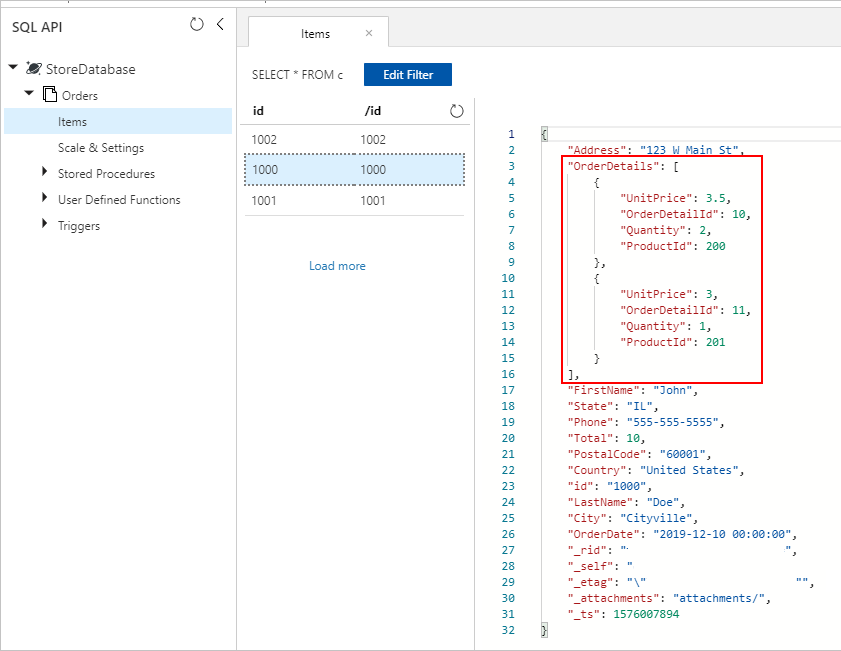
Azure Cosmos DB 컬렉션에 삽입된, 올바르게 포함된 OrderDetails가 있는 Orders 문서도 표시됩니다.
Azure Databricks
Azure Databricks에서 Spark를 사용하여 Azure Blob Storage에서 중간 텍스트/JSON 파일을 만들지 않고도 SQL Database 원본의 데이터를 Azure Cosmos DB 대상으로 복사할 수 있습니다.
참고 항목
명확성과 단순성을 위해 코드 조각은 더미 데이터베이스 암호를 명시적으로 인라인으로 포함하지만, 사용자는 원칙적으로 Azure Databricks 비밀을 사용해야 합니다.
먼저 필요한 SQL 커넥터 와 Azure Cosmos DB 커넥터 라이브러리를 만들고 Azure Databricks 클러스터에 연결합니다. 클러스터를 다시 시작하여 라이브러리가 로드되는지 확인합니다.

이제 Scala 및 Python에 대한 두 가지 샘플이 제공됩니다.
Scala
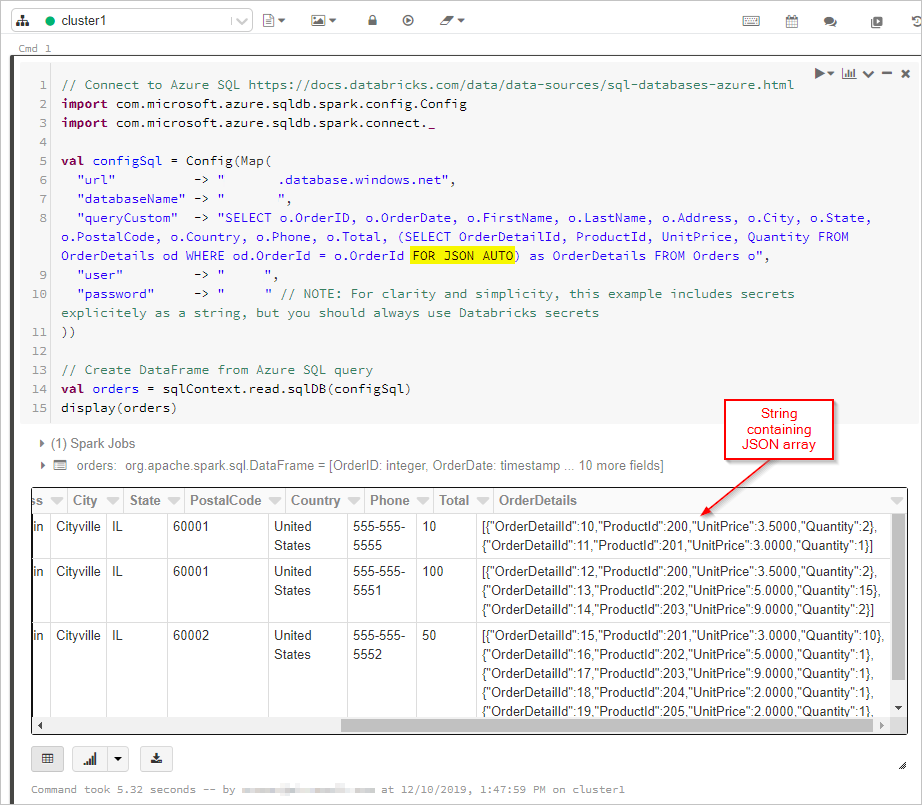
여기서는 “FOR JSON” 출력을 이용해 SQL 쿼리의 결과를 DataFrame으로 가져옵니다.
// Connect to Azure SQL /connectors/sql/
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val configSql = Config(Map(
"url" -> "xxxx.database.windows.net",
"databaseName" -> "xxxx",
"queryCustom" -> "SELECT o.OrderID, o.OrderDate, o.FirstName, o.LastName, o.Address, o.City, o.State, o.PostalCode, o.Country, o.Phone, o.Total, (SELECT OrderDetailId, ProductId, UnitPrice, Quantity FROM OrderDetails od WHERE od.OrderId = o.OrderId FOR JSON AUTO) as OrderDetails FROM Orders o",
"user" -> "xxxx",
"password" -> "xxxx" // NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
))
// Create DataFrame from Azure SQL query
val orders = sqlContext.read.sqlDB(configSql)
display(orders)
그런 다음, Azure Cosmos DB 데이터베이스와 컬렉션에 연결합니다.
// Connect to Azure Cosmos DB https://docs.databricks.com/data/data-sources/azure/cosmosdb-connector.html
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._
val configMap = Map(
"Endpoint" -> "https://xxxx.documents.azure.com:443/",
// NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
"Masterkey" -> "xxxx",
"Database" -> "StoreDatabase",
"Collection" -> "Orders")
val configAzure Cosmos DB= Config(configMap)
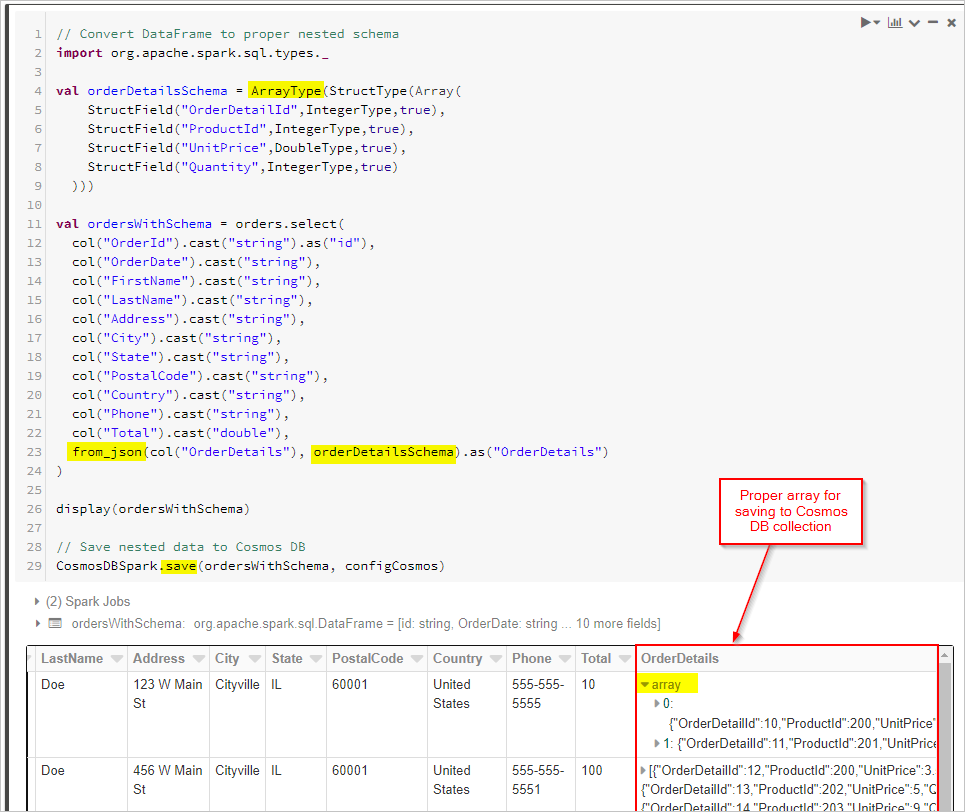
마지막으로 스키마를 정의하고 from_json을 사용하여 DataFrame을 적용한 후 CosmosDB 컬렉션에 저장합니다.
// Convert DataFrame to proper nested schema
import org.apache.spark.sql.types._
val orderDetailsSchema = ArrayType(StructType(Array(
StructField("OrderDetailId",IntegerType,true),
StructField("ProductId",IntegerType,true),
StructField("UnitPrice",DoubleType,true),
StructField("Quantity",IntegerType,true)
)))
val ordersWithSchema = orders.select(
col("OrderId").cast("string").as("id"),
col("OrderDate").cast("string"),
col("FirstName").cast("string"),
col("LastName").cast("string"),
col("Address").cast("string"),
col("City").cast("string"),
col("State").cast("string"),
col("PostalCode").cast("string"),
col("Country").cast("string"),
col("Phone").cast("string"),
col("Total").cast("double"),
from_json(col("OrderDetails"), orderDetailsSchema).as("OrderDetails")
)
display(ordersWithSchema)
// Save nested data to Azure Cosmos DB
CosmosDBSpark.save(ordersWithSchema, configCosmos)
Python
대체 접근 방식으로, 원본 데이터베이스가 FOR JSON 또는 유사한 작업을 지원하지 않는 경우 Spark에서 JSON 변환을 실행해야 할 수 있습니다. 또는 큰 데이터 세트에 대해 병렬 작업을 사용할 수 있습니다. 여기서는 PySpark 샘플을 제공합니다. 먼저 첫 번째 셀에서 원본 및 대상 데이터베이스 연결을 구성 하세요.
import uuid
import pyspark.sql.functions as F
from pyspark.sql.functions import col
from pyspark.sql.types import StringType,DateType,LongType,IntegerType,TimestampType
#JDBC connect details for SQL Server database
jdbcHostname = "jdbcHostname"
jdbcDatabase = "OrdersDB"
jdbcUsername = "jdbcUsername"
jdbcPassword = "jdbcPassword"
jdbcPort = "1433"
connectionProperties = {
"user" : jdbcUsername,
"password" : jdbcPassword,
"driver" : "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2};user={3};password={4}".format(jdbcHostname, jdbcPort, jdbcDatabase, jdbcUsername, jdbcPassword)
#Connect details for Target Azure Cosmos DB for NoSQL account
writeConfig = {
"Endpoint": "Endpoint",
"Masterkey": "Masterkey",
"Database": "OrdersDB",
"Collection": "Orders",
"Upsert": "true"
}
그런 다음, 원본 데이터베이스(이 경우에는 SQL Server)에 주문 및 주문 세부 정보 레코드를 둘 다 쿼리하고 결과를 Spark Dataframe에 전달합니다. 또한 모든 주문 ID와 병렬 작업용 스레드 풀을 포함하는 목록을 만듭니다.
import json
import ast
import pyspark.sql.functions as F
import uuid
import numpy as np
import pandas as pd
from functools import reduce
from pyspark.sql import SQLContext
from pyspark.sql.types import *
from pyspark.sql import *
from pyspark.sql.functions import exp
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.functions import array
from pyspark.sql.types import *
from multiprocessing.pool import ThreadPool
#get all orders
orders = sqlContext.read.jdbc(url=jdbcUrl, table="orders", properties=connectionProperties)
#get all order details
orderdetails = sqlContext.read.jdbc(url=jdbcUrl, table="orderdetails", properties=connectionProperties)
#get all OrderId values to pass to map function
orderids = orders.select('OrderId').collect()
#create thread pool big enough to process merge of details to orders in parallel
pool = ThreadPool(10)
그런 다음, 대상 API for NoSQL 컬렉션에 주문을 기록하는 함수를 만듭니다. 이 함수는 지정된 주문 ID에 대한 모든 주문 세부 정보를 필터링하고, JSON 배열로 변환한 다음, 배열을 JSON 문서에 삽입합니다. 그런 다음, JSON 문서는 해당 주문에 대한 대상 API for NoSQL 컨테이너에 기록됩니다.
def writeOrder(orderid):
#filter the order on current value passed from map function
order = orders.filter(orders['OrderId'] == orderid[0])
#set id to be a uuid
order = order.withColumn("id", lit(str(uuid.uuid1())))
#add details field to order dataframe
order = order.withColumn("details", lit(''))
#filter order details dataframe to get details we want to merge into the order document
orderdetailsgroup = orderdetails.filter(orderdetails['OrderId'] == orderid[0])
#convert dataframe to pandas
orderpandas = order.toPandas()
#convert the order dataframe to json and remove enclosing brackets
orderjson = orderpandas.to_json(orient='records', force_ascii=False)
orderjson = orderjson[1:-1]
#convert orderjson to a dictionaory so we can set the details element with order details later
orderjsondata = json.loads(orderjson)
#convert orderdetailsgroup dataframe to json, but only if details were returned from the earlier filter
if (orderdetailsgroup.count() !=0):
#convert orderdetailsgroup to pandas dataframe to work better with json
orderdetailsgroup = orderdetailsgroup.toPandas()
#convert orderdetailsgroup to json string
jsonstring = orderdetailsgroup.to_json(orient='records', force_ascii=False)
#convert jsonstring to dictionary to ensure correct encoding and no corrupt records
jsonstring = json.loads(jsonstring)
#set details json element in orderjsondata to jsonstring which contains orderdetailsgroup - this merges order details into the order
orderjsondata['details'] = jsonstring
#convert dictionary to json
orderjsondata = json.dumps(orderjsondata)
#read the json into spark dataframe
df = spark.read.json(sc.parallelize([orderjsondata]))
#write the dataframe (this will be a single order record with merged many-to-one order details) to Azure Cosmos DB db using spark the connector
#https://learn.microsoft.com/azure/cosmos-db/spark-connector
df.write.format("com.microsoft.azure.cosmosdb.spark").mode("append").options(**writeConfig).save()
마지막으로, 병렬로 실행하기 위해 스레드 풀에서 map 함수를 통해 Python writeOrder 함수를 호출하여 앞에서 만든 주문 ID 목록을 전달합니다.
#map order details to orders in parallel using the above function
pool.map(writeOrder, orderids)
어느 방법을 사용하더라도 결국에는 포함된 OrderDetails가 Azure Cosmos DB 컬렉션의 각 Order 문서에 올바르게 저장됩니다.
다음 단계
- Azure Cosmos DB에서의 데이터 모델링에 대해 자세히 알아보기
- Azure Cosmos DB에서 데이터를 모델링하고 분할하는 방법에 대해 자세히 알아보기