빠른 시작: MongoDB 드라이버를 사용하는 Python용 Azure Cosmos DB for MongoDB
적용 대상: ![]() MongoDB
MongoDB
MongoDB를 시작하여 Azure Cosmos DB 리소스 내에서 데이터베이스, 컬렉션 및 문서를 만듭니다. Azure 개발자 CLI를 사용하여 환경에 최소 솔루션을 배포하려면 다음 단계를 따릅니다.
MongoDB용 API 참조 설명서 | pymongo 패키지 | Azure Developer CLI
필수 조건
- 활성 구독이 있는 Azure 계정. 체험 계정을 만듭니다.
- GitHub 계정
- 활성 구독이 있는 Azure 계정. 체험 계정을 만듭니다.
- Azure Developer CLI
- Docker Desktop
설정
이 프로젝트의 개발 컨테이너를 환경에 배포합니다. 그런 다음, Azure 개발자 CLI(azd)를 사용하여 Azure Cosmos DB for MongoDB 계정을 만들고 컨테이너화된 샘플 애플리케이션을 배포합니다. 샘플 애플리케이션은 클라이언트 라이브러리를 사용하여 샘플 데이터를 관리, 만들기, 읽기 및 쿼리합니다.


Important
GitHub 계정에는 무료로 스토리지 및 핵심 시간에 대한 권한이 포함됩니다. 자세한 내용은 GitHub 계정에 포함된 스토리지 및 핵심 시간을 참조하세요.
프로젝트의 루트 디렉터리에서 터미널을 엽니다.
azd auth login을 사용하여 Azure 개발자 CLI에 인증합니다. 원하는 Azure 자격 증명을 사용하여 CLI에 인증하려면 도구에 지정된 단계를 따릅니다.azd auth login프로젝트를 초기화하려면
azd init를 사용합니다.azd init --template cosmos-db-mongodb-python-quickstart참고 항목
이 빠른 시작에서는 azure-samples/cosmos-db-mongodb-python-quickstart 템플릿 GitHub 리포지토리를 사용합니다. Azure 개발자 CLI는 이 프로젝트가 아직 없는 경우 컴퓨터에 자동으로 복제합니다.
초기화 중에 고유한 환경 이름을 구성합니다.
팁
환경 이름은 대상 리소스 그룹 이름으로도 사용됩니다. 이 빠른 시작에서는
msdocs-cosmos-db사용을 고려해보세요.azd up을 사용하여 Azure Cosmos DB 계정을 배포합니다. Bicep 템플릿은 샘플 웹 애플리케이션도 배포합니다.azd up프로비전 과정에서 구독과 원하는 위치를 선택합니다. 프로비저닝 프로세스가 완료될 때까지 기다립니다. 이 과정은 약 5분 정도 소요됩니다.
Azure 리소스 프로비전이 완료되면 실행 중인 웹 애플리케이션에 대한 URL이 출력에 포함됩니다.
Deploying services (azd deploy) (✓) Done: Deploying service web - Endpoint: <https://[container-app-sub-domain].azurecontainerapps.io> SUCCESS: Your application was provisioned and deployed to Azure in 5 minutes 0 seconds.콘솔의 URL을 사용하여 브라우저에서 웹 애플리케이션으로 이동합니다. 실행 중인 앱의 출력을 관찰합니다.

클라이언트 라이브러리 설치
requirements.txtPyMongo 및 python-dotenv 패키지를 나열하는 파일을 앱 디렉터리에 만듭니다.# requirements.txt pymongo python-dotenv가상 환경을 만들고 패키지를 설치합니다.
# py -3 uses the global python interpreter. You can also use python3 -m venv .venv. py -3 -m venv .venv source .venv/Scripts/activate pip install -r requirements.txt
개체 모델
MongoDB용 API의 리소스 계층 구조와 해당 리소스를 만들고 액세스하는 데 사용되는 개체 모델을 살펴보겠습니다. Azure Cosmos DB는 리소스를 계정, 데이터베이스, 컬렉션 및 문서로 구성된 계층 구조에 만듭니다.
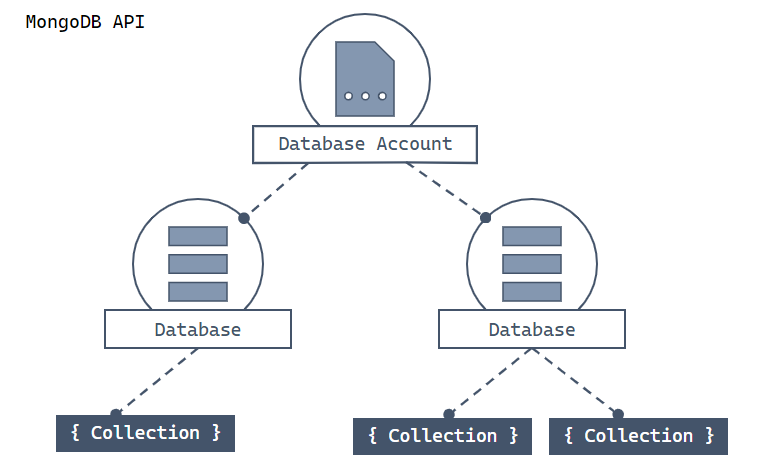
맨 위에 있는 Azure Cosmos DB 계정을 보여 주는 계층 다이어그램. 계정에는 두 개의 분할된 자식 데이터베이스가 있습니다. 분할된 데이터베이스 중 하나에는 두 개의 자식 컬렉션 분할이 포함되어 있습니다. 다른 분할된 데이터베이스에는 단일 자식 컬렉션 분할이 포함됩니다. 해당 단일 컬렉션 분할에는 3개의 자식 문서 분할이 있습니다.
각 리소스 종류는 Python 클래스로 표시됩니다. 가장 일반적인 클래스는 다음과 같습니다.
MongoClient - PyMongo로 작업할 때 첫 번째 단계는 MongoClient를 만들어 Azure Cosmos DB의 MongoDB용 API에 연결하는 것입니다. 이 클라이언트 개체는 서비스에 대한 요청을 구성하고 실행하는 데 사용됩니다.
데이터베이스 - Azure Cosmos DB의 MongoDB용 API는 하나 이상의 독립적인 데이터베이스를 지원할 수 있습니다.
컬렉션 - 데이터베이스에 하나 이상의 컬렉션이 포함될 수 있습니다. 컬렉션은 MongoDB에 저장된 문서 그룹이며 관계형 데이터베이스의 테이블과 거의 동일하다고 생각할 수 있습니다.
문서 - 문서는 키-값 쌍 집합입니다. 문서에는 동적 스키마가 있습니다. 동적 스키마는 동일한 컬렉션의 문서에 동일한 필드 또는 구조 집합이 필요하지 않음을 의미합니다. 또한 컬렉션 문서의 공통 필드에는 다양한 형식의 데이터가 포함될 수 있습니다.
엔터티 계층 구조를 자세히 알아보려면 Azure Cosmos DB 리소스 모델 문서를 참조하세요.
코드 예제
이 문서에서 설명하는 샘플 코드에서는 products라는 컬렉션을 사용하여 adventureworks라는 데이터베이스를 만듭니다. products 컬렉션은 이름, 범주, 수량 및 판매 지표와 같은 제품 세부 정보를 포함하도록 설계되었습니다. 각 제품에는 고유 식별자도 포함됩니다. 전체 샘플 코드는 https://github.com/Azure-Samples/azure-cosmos-db-mongodb-python-getting-started/tree/main/001-quickstart/에 있습니다.
아래 단계의 경우 데이터베이스는 분할을 사용하지 않으며 PyMongo 드라이버를 사용하는 동기 애플리케이션을 표시합니다. 비동기 애플리케이션의 경우 모터 드라이버를 사용합니다.
클라이언트 인증
프로젝트 디렉터리에서 run.py 파일을 만듭니다. 편집기에서 PyMongo 및 python-dotenv 패키지를 포함하여 사용할 패키지를 참조하는 데 필요한 문을 추가합니다.
import os import sys from random import randint import pymongo from dotenv import load_dotenv.env 파일에 정의된 환경 변수에서 연결 정보를 가져옵니다.
load_dotenv() CONNECTION_STRING = os.environ.get("COSMOS_CONNECTION_STRING")코드에서 사용할 상수를 정의합니다.
DB_NAME = "adventureworks" COLLECTION_NAME = "products"
Azure Cosmos DB의 API for MongoDB에 연결
MongoClient 개체를 사용하여 Azure Cosmos DB for MongoDB 리소스에 연결합니다. 연결 메서드는 데이터베이스에 대한 참조를 반환합니다.
client = pymongo.MongoClient(CONNECTION_STRING)
데이터베이스 가져오기
list_database_names 메서드를 사용하여 데이터베이스가 있는지 확인합니다. 데이터베이스가 없는 경우 데이터베이스 확장 만들기 명령을 사용하여 지정된 프로비전된 처리량을 사용하여 만듭니다.
# Create database if it doesn't exist
db = client[DB_NAME]
if DB_NAME not in client.list_database_names():
# Create a database with 400 RU throughput that can be shared across
# the DB's collections
db.command({"customAction": "CreateDatabase", "offerThroughput": 400})
print("Created db '{}' with shared throughput.\n".format(DB_NAME))
else:
print("Using database: '{}'.\n".format(DB_NAME))
컬렉션 가져오기
list_collection_names 메서드를 사용하여 컬렉션이 있는지 확인합니다. 컬렉션이 없으면 컬렉션 확장 만들기 명령을 사용하여 컬렉션을 만듭니다.
# Create collection if it doesn't exist
collection = db[COLLECTION_NAME]
if COLLECTION_NAME not in db.list_collection_names():
# Creates a unsharded collection that uses the DBs shared throughput
db.command(
{"customAction": "CreateCollection", "collection": COLLECTION_NAME}
)
print("Created collection '{}'.\n".format(COLLECTION_NAME))
else:
print("Using collection: '{}'.\n".format(COLLECTION_NAME))
인덱스 만들기
컬렉션 확장 업데이트 명령을 사용하여 인덱스를 만듭니다. 컬렉션 확장 만들기 명령에서 인덱스도 설정할 수 있습니다. 이 예제에서 인덱스를 name 속성으로 설정하면 나중에 커서 클래스 sort 메서드를 사용하여 제품 이름을 정렬할 수 있습니다.
indexes = [
{"key": {"_id": 1}, "name": "_id_1"},
{"key": {"name": 2}, "name": "_id_2"},
]
db.command(
{
"customAction": "UpdateCollection",
"collection": COLLECTION_NAME,
"indexes": indexes,
}
)
print("Indexes are: {}\n".format(sorted(collection.index_information())))
문서 만들기
adventureworks 데이터베이스에 대한 product 속성으로 문서를 만듭니다.
- category 속성입니다. 이 속성은 논리 파티션 키로 사용할 수 있습니다.
- name 속성입니다.
- 인벤토리 quantity 속성입니다.
- 제품이 판매 중인지 여부를 나타내는 sale 속성입니다.
"""Create new document and upsert (create or replace) to collection"""
product = {
"category": "gear-surf-surfboards",
"name": "Yamba Surfboard-{}".format(randint(50, 5000)),
"quantity": 1,
"sale": False,
}
result = collection.update_one(
{"name": product["name"]}, {"$set": product}, upsert=True
)
print("Upserted document with _id {}\n".format(result.upserted_id))
컬렉션 수준 작업 update_one을 호출하여 컬렉션에 문서를 만듭니다. 이 예제에서는 새 문서를 만드는 대신 upsert합니다. 제품 이름이 임의이기 때문에 이 예제에서는 Upsert가 필요하지 않습니다. 그러나 코드를 여러 번 실행하고 제품 이름이 동일한 경우를 대비하여 upsert하는 것이 좋습니다.
update_one 작업의 결과에는 후속 작업에서 사용할 수 있는 _id 필드 값이 포함됩니다. _id 속성이 자동으로 만들어졌습니다.
문서 가져오기
find_one 메서드를 사용하여 문서를 가져옵니다.
doc = collection.find_one({"_id": result.upserted_id})
print("Found a document with _id {}: {}\n".format(result.upserted_id, doc))
Azure Cosmos DB에서는 고유 식별자(_id)와 파티션 키를 모두 사용하여 비용이 저렴한 지점 읽기 작업을 수행할 수 있습니다.
쿼리 문서
문서가 삽입되면 특정 필터와 일치하는 모든 문서를 가져오는 쿼리를 실행할 수 있습니다. 이 예제에서는 특정 범주 gear-surf-surfboards와 일치하는 모든 문서를 찾습니다. 쿼리가 정의되면 Collection.find를 호출하여 Cursor 결과를 가져온 후 정렬을 사용합니다.
"""Query for documents in the collection"""
print("Products with category 'gear-surf-surfboards':\n")
allProductsQuery = {"category": "gear-surf-surfboards"}
for doc in collection.find(allProductsQuery).sort(
"name", pymongo.ASCENDING
):
print("Found a product with _id {}: {}\n".format(doc["_id"], doc))
문제 해결:
The index path corresponding to the specified order-by item is excluded.와 같은 오류가 발생하는 경우 인덱스가 만들어졌는지 확인합니다.
코드 실행
이 앱은 API for MongoDB 데이터베이스 및 컬렉션을 만들고 문서를 만든 다음, 정확히 동일한 문서를 다시 읽습니다. 마지막으로, 이 예제에서는 지정된 제품 범주와 일치하는 문서를 반환하는 쿼리를 실행합니다. 각 단계에서 예제는 수행한 단계에 대한 정보를 콘솔에 출력합니다.
앱을 실행하려면 터미널을 사용하여 애플리케이션 디렉터리로 이동하고 애플리케이션을 실행합니다.
python run.py
앱의 출력은 다음 예제와 비슷합니다.
Created db 'adventureworks' with shared throughput.
Created collection 'products'.
Indexes are: ['_id_', 'name_1']
Upserted document with _id <ID>
Found a document with _id <ID>:
{'_id': <ID>,
'category': 'gear-surf-surfboards',
'name': 'Yamba Surfboard-50',
'quantity': 1,
'sale': False}
Products with category 'gear-surf-surfboards':
Found a product with _id <ID>:
{'_id': ObjectId('<ID>'),
'name': 'Yamba Surfboard-386',
'category': 'gear-surf-surfboards',
'quantity': 1,
'sale': False}
리소스 정리
Azure Cosmos DB for NoSQL 계정이 더 이상 필요하지 않으면 해당 리소스 그룹을 삭제할 수 있습니다.
az group delete 명령을 사용하여 리소스 그룹을 삭제합니다.
az group delete --name $resourceGroupName