적용 대상: ![]() MongoDB
MongoDB
이 마이그레이션 가이드는 데이터베이스를 MongoDB에서 Azure Cosmos DB API for MongoDB로 마이그레이션하는 시리즈의 일부입니다. 중요한 마이그레이션 단계는 아래와 같이 마이그레이션 사전 작업, 마이그레이션 및 마이그레이션 사후 작업입니다.

Azure Databricks를 사용한 데이터 마이그레이션
Azure Databricks는 Apache Spark에 대한 PaaS(Platform as a Service) 제품입니다. 대규모 데이터 세트에서 오프라인 마이그레이션을 수행하는 방법을 제공합니다. Azure Databricks를 사용하여 MongoDB에서 Azure Cosmos DB for MongoDB로 데이터베이스를 오프라인으로 마이그레이션할 수 있습니다.
이 자습서에서는 다음을 수행하는 방법을 배우게 됩니다.
Azure Databricks 클러스터 프로비전
종속성 추가
Scala 또는 Python Notebook 만들기 및 실행
마이그레이션 성능 최적화
마이그레이션 중에 관찰될 수 있는 속도 제한 오류 문제 해결
필수 조건
이 자습서를 완료하려면 다음이 필요합니다.
- 처리량 예상 및 분할 키 선택과 같은 사전 마이그레이션 단계를 완료합니다.
- Azure Cosmos DB for MongoDB 계정을 만듭니다.
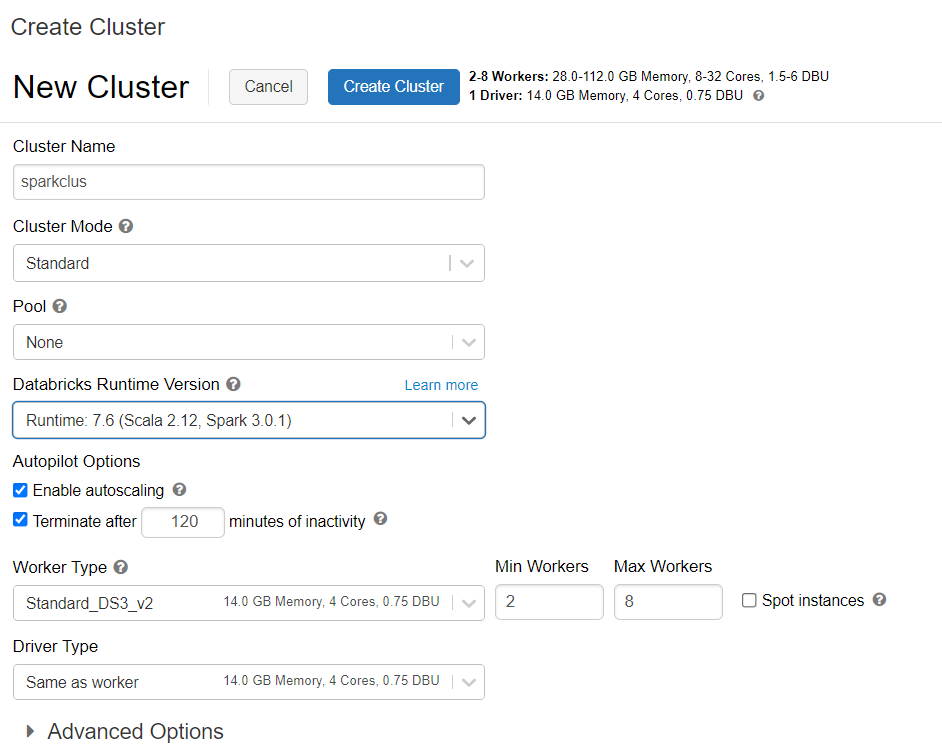
Azure Databricks 클러스터 프로비전
지침에 따라 Azure Databricks 클러스터를 프로비저닝할 수 있습니다. Spark 3.0을 지원하는 Databricks Runtime 버전 7.6을 선택하는 것이 좋습니다.
종속성 추가
클러스터에 MongoDB Connector for Spark 라이브러리를 추가하여 기본 MongoDB 및 Azure Cosmos DB for MongoDB 엔드포인트에 모두 연결합니다. 클러스터에서 라이브러리>새로 설치>Maven을 선택한 다음, org.mongodb.spark:mongo-spark-connector_2.12:3.0.1 Maven 좌표를 추가합니다.
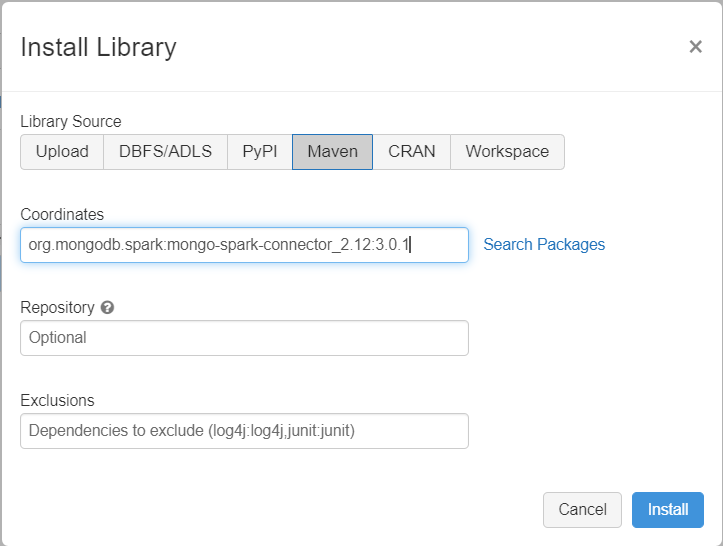
설치를 선택한 다음 설치가 완료되면 클러스터를 다시 시작합니다.
참고 항목
MongoDB Connector for Spark 라이브러리가 설치된 후 Databricks 클러스터를 다시 시작해야 합니다.
그런 다음, 마이그레이션을 위해 Scala 또는 Python Notebook을 만들 수 있습니다.
마이그레이션을 위한 Scala Notebook 만들기
Databricks에서 Scala Notebook을 만듭니다. 다음 코드를 실행하기 전에 변수에 올바른 값을 입력해야 합니다.
import com.mongodb.spark._
import com.mongodb.spark.config._
import org.apache.spark._
import org.apache.spark.sql._
var sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
var sourceDb = "<DB NAME>"
var sourceCollection = "<COLLECTIONNAME>"
var targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
var targetDb = "<DB NAME>"
var targetCollection = "<COLLECTIONNAME>"
val readConfig = ReadConfig(Map(
"spark.mongodb.input.uri" -> sourceConnectionString,
"spark.mongodb.input.database" -> sourceDb,
"spark.mongodb.input.collection" -> sourceCollection,
))
val writeConfig = WriteConfig(Map(
"spark.mongodb.output.uri" -> targetConnectionString,
"spark.mongodb.output.database" -> targetDb,
"spark.mongodb.output.collection" -> targetCollection,
"spark.mongodb.output.maxBatchSize" -> "8000"
))
val sparkSession = SparkSession
.builder()
.appName("Data transfer using spark")
.getOrCreate()
val customRdd = MongoSpark.load(sparkSession, readConfig)
MongoSpark.save(customRdd, writeConfig)
마이그레이션을 위한 Python Notebook 만들기
Databricks에서 Python Notebook을 만듭니다. 다음 코드를 실행하기 전에 변수에 올바른 값을 입력해야 합니다.
from pyspark.sql import SparkSession
sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
sourceDb = "<DB NAME>"
sourceCollection = "<COLLECTIONNAME>"
targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
targetDb = "<DB NAME>"
targetCollection = "<COLLECTIONNAME>"
my_spark = SparkSession \
.builder \
.appName("myApp") \
.getOrCreate()
df = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").option("uri", sourceConnectionString).option("database", sourceDb).option("collection", sourceCollection).load()
df.write.format("mongo").mode("append").option("uri", targetConnectionString).option("maxBatchSize",2500).option("database", targetDb).option("collection", targetCollection).save()
마이그레이션 성능 최적화
마이그레이션 성능은 다음 구성을 통해 조정할 수 있습니다.
Spark 클러스터의 작업자 및 코어 수: 작업자가 많을수록 작업을 실행하는 데 필요한 컴퓨팅 분할이 더 많아집니다.
maxBatchSize:
maxBatchSize값은 데이터가 대상 Azure Cosmos DB 컬렉션에 저장되는 속도를 제어합니다. 그러나 maxBatchSize가 컬렉션 처리량에 비해 너무 높으면 속도 제한 오류가 발생할 수 있습니다.Spark 클러스터의 실행자 수, 작성되는 각 문서의 잠재적 크기(RU 비용) 및 대상 컬렉션 처리량 제한에 따라 작업자 수와 maxBatchSize를 조정해야 합니다.
팁
maxBatchSize = 컬렉션 처리량/(문서 1개의 RU 비용 * Spark 작업자 수 * 작업자당 CPU 코어 수)
MongoDB Spark partitioner 및 partitionKey: 사용되는 기본 partitioner는 MongoDefaultPartitioner이고 기본 partitionKey는 _id입니다. 입력 구성 속성
spark.mongodb.input.partitioner에 값MongoSamplePartitioner를 할당하여 partitioner를 변경할 수 있습니다. 마찬가지로, 입력 구성 속성spark.mongodb.input.partitioner.partitionKey에 적절한 필드 이름을 할당하여 partitionKey를 변경할 수 있습니다. 오른쪽 partitionKey는 데이터 기울이기(동일한 분할 키 값에 대해 많은 수의 레코드가 기록됨)를 방지하는 데 도움이 될 수 있습니다.데이터 전송 중 인덱스 사용 안 함: 대량의 데이터 마이그레이션의 경우 인덱스, 특히 대상 컬렉션의 와일드카드 인덱스를 사용하지 않도록 설정하는 것이 좋습니다. 인덱스는 각 문서를 작성하기 위한 RU 비용을 증가시킵니다. 이러한 RU를 해제하면 데이터 전송 속도를 개선하는 데 도움이 될 수 있습니다. 데이터가 마이그레이션되면 인덱스를 사용하도록 설정할 수 있습니다.
문제 해결
시간 초과 오류(오류 코드 50)
Azure Cosmos DB for MongoDB 데이터베이스에 대한 작업에 50 오류 코드가 표시될 수 있습니다. 다음 시나리오에서는 시간 초과 오류가 발생할 수 있습니다.
- 데이터베이스에 할당된 처리량이 낮음: 대상 컬렉션에 충분한 처리량이 할당되었는지 확인합니다.
- 큰 데이터 볼륨으로 인한 과도한 데이터 기울이기. 특정 테이블로 마이그레이션할 데이터가 많지만 데이터에 상당한 기울이기가 있는 경우 테이블에 프로비저닝된 여러 요청 단위가 있더라도 여전히 비율 제한이 발생할 수 있습니다. 요청 단위는 실제 파티션 간에 균등하게 분할되며 과도한 데이터 기울이기로 인해 단일 분할에 대한 요청 병목 현상이 발생할 수 있습니다. 데이터 기울이기는 동일한 분할 키 값에 대한 많은 수의 레코드를 의미합니다.
속도 제한(오류 코드 16500)
Azure Cosmos DB for MongoDB 데이터베이스에 대한 작업에 16500 오류 코드가 표시될 수 있습니다. 이는 속도 제한 오류이며 이전 계정이나 서버 측 다시 시도 기능이 사용하지 않도록 설정된 계정에서 관찰될 수 있습니다.
- 서버 측 다시 시도 사용: SSR(서버 측 다시 시도) 기능을 사용하도록 설정하고 서버가 속도 제한 작업을 자동으로 다시 시도하도록 합니다.
마이그레이션 후 최적화
데이터를 마이그레이션한 후 Azure Cosmos DB에 연결하여 데이터를 관리할 수 있습니다. 인덱싱 정책 최적화와 같은 다른 마이그레이션 후 단계를 따르거나, 기본 일관성 수준을 업데이트하거나, Azure Cosmos DB 계정에 대한 전역 배포를 구성할 수도 있습니다. 자세한 내용은 마이그레이션 후 최적화 문서를 참조하세요.
추가 리소스
- Azure Cosmos DB로 마이그레이션하기 위한 용량 계획을 수행하려고 하시나요?
- 기존 데이터베이스 클러스터의 vCore 및 서버 수만을 알고 있는 경우, vCore 또는 vCPU를 사용하여 요청 단위 추정을 참조하세요
- 현재 데이터베이스 워크로드에 대한 일반적인 요청 비율을 알고 있는 경우 Azure Cosmos DB 용량 계획 도구를 사용하여 요청 단위 예측에 대해 읽어보세요.