중요합니다
Azure Cosmos DB for PostgreSQL은 더 이상 새 프로젝트에 지원되지 않습니다. 새 프로젝트에는 이 서비스를 사용하지 마세요. 대신 다음 두 서비스 중 하나를 사용합니다.
99.999% SLA(가용성 서비스 수준 약정), 인스턴트 자동 크기 조정 및 여러 지역에서 자동 장애 조치(failover)를 사용하는 대규모 시나리오용으로 설계된 분산 데이터베이스 솔루션에는 NoSQL용 Azure Cosmos DB를 사용합니다.
오픈 소스 Citus 확장을 사용하여 분할된 PostgreSQL용 Azure Database for PostgreSQL의 탄력적 클러스터 기능을 사용합니다.
분할 키를 사용하여 큰 테이블 공동 배치
실시간 운영 분석 애플리케이션에 대한 분할 키를 선택하려면 다음 지침을 따릅니다.
- 큰 테이블에 공통적인 열을 선택합니다.
- 데이터의 기본 차원 또는 애플리케이션의 중심부인 열을 선택합니다. 몇 가지 예는 다음과 같습니다.
- 금융 환경에서 보안 추세를 분석하는 애플리케이션은
security_id를 사용합니다. - 웹 사이트 사용 메트릭을 분석하려는 사용자 분석 워크로드에서는
user_id가 적절한 배포 열이 될 수 있습니다.
- 금융 환경에서 보안 추세를 분석하는 애플리케이션은
큰 테이블을 공동 배치하여 SQL 쿼리를 병렬로 작업자 노드로 푸시할 수 있습니다. 쿼리를 푸시다운하면 네트워크를 통해 노드 간에 데이터가 섞이는 것을 방지할 수 있습니다. JOIN, 집계, 롤업, 필터, LIMIT와 같은 작업을 효율적으로 실행할 수 있습니다.
공동 배치된 테이블에서 병렬 분산 쿼리를 시각화하려면 다음 다이어그램을 고려합니다.
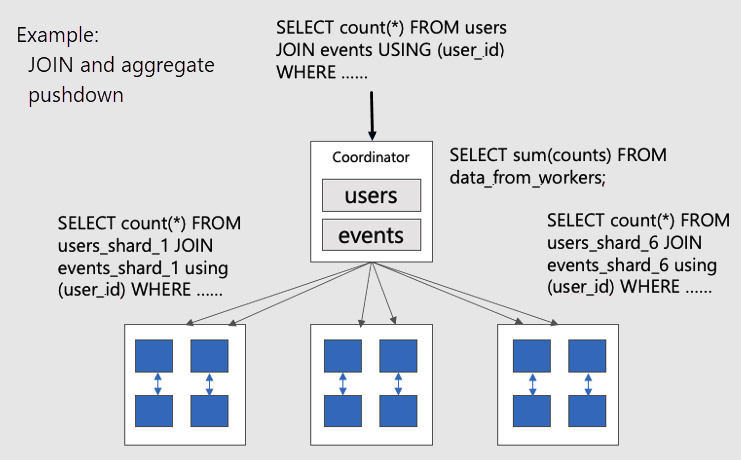
users 및 events 테이블은 모두 user_id로 분할되므로 동일한 사용자 ID에 대한 관련 행이 동일한 작업자 노드에 함께 배치됩니다. SQL JOIN은 작업자 간에 정보를 가져오지 않고도 발생할 수 있습니다.
실시간 앱을 위한 최적의 데이터 모델
계속해서 사용자 웹 사이트 방문 및 메트릭을 분석하는 애플리케이션의 예를 살펴보겠습니다. 두 개의 "팩트" 테이블(사용자 및 이벤트)과 다른 작은 "차원" 테이블이 있습니다.
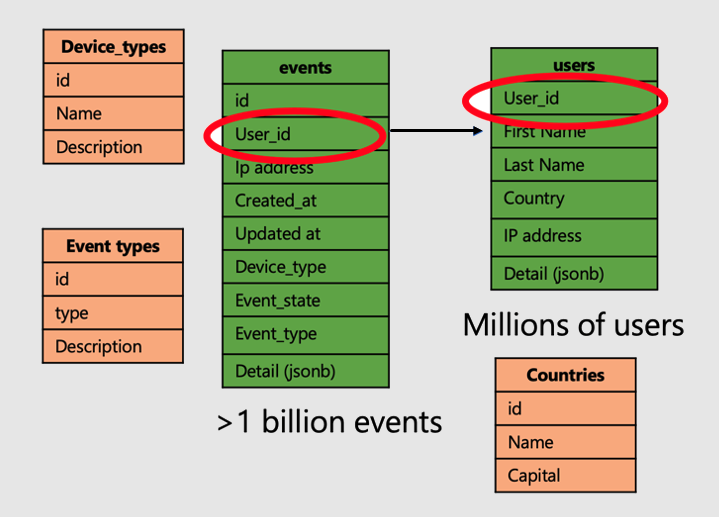
Azure Cosmos DB for PostgreSQL에서 분산 테이블의 강력한 기능을 적용하려면 다음 단계를 따릅니다.
- 공통 열에 큰 팩트 테이블을 배포합니다. Microsoft의 경우 사용자와 이벤트는
user_id에 배포됩니다. - 작은/차원 테이블(
device_types,countries및 `event_types)을 참조 테이블로 표시합니다. - 분산 테이블의 기본, 고유 및 외래 키 제약 조건에 분산 열을 포함해야 합니다. 열을 포함하려면 키를 복합으로 지정해야 할 수 있습니다. 참조 테이블에 대한 키를 업데이트해야 합니다.
- 대규모 분산 테이블을 조인할 때는 분할 키를 사용하여 조인해야 합니다.
-- Distribute the fact tables
SELECT create_distributed_table('users', 'user_id');
SELECT create_distributed_table('products', 'user_id', colocate_with => 'users');
-- Turn dimension tables into reference tables, with synchronized copies
-- maintained on every worker node
SELECT create_reference_table('countries');
-- similarly for device_types and event_types...
다음 단계
이제 확장 가능한 앱에 대한 데이터 모델링 탐색을 완료했습니다. 다음 단계는 선택한 프로그래밍 언어로 데이터베이스를 연결하고 쿼리하는 것입니다.