중요합니다
Azure Cosmos DB for PostgreSQL은 더 이상 새 프로젝트에 지원되지 않습니다. 새 프로젝트에는 이 서비스를 사용하지 마세요. 대신 다음 두 서비스 중 하나를 사용합니다.
99.999% SLA(가용성 서비스 수준 약정), 인스턴트 자동 크기 조정 및 여러 지역에서 자동 장애 조치(failover)를 사용하는 대규모 시나리오용으로 설계된 분산 데이터베이스 솔루션에는 NoSQL용 Azure Cosmos DB를 사용합니다.
오픈 소스 Citus 확장을 사용하여 분할된 PostgreSQL용 Azure Database for PostgreSQL의 탄력적 클러스터 기능을 사용합니다.
이 자습서에서는 Azure Cosmos DB for PostgreSQL을 여러 마이크로 서비스의 스토리지 백 엔드로 사용하여 이러한 클러스터의 샘플 설정 및 기본 작업을 보여 줍니다. 다음의 방법을 알아보세요.
- 클러스터 생성
- 마이크로 서비스에 대한 역할 만들기
- psql 유틸리티를 사용하여 역할 및 분산 스키마 만들기
- 샘플 서비스에 대한 테이블 만들기
- 서비스 구성
- 서비스 실행
- 데이터베이스 탐색
필수 조건
Azure 구독이 없는 경우 시작하기 전에 체험 계정을 만듭니다.
클러스터 생성
Azure Portal에 로그인하고 다음 단계에 따라 Azure Cosmos DB for PostgreSQL 클러스터를 만듭니다.
Azure Portal에서 Azure Cosmos DB for PostgreSQL 클러스터용 만들기로 이동합니다.
Azure Cosmos DB for PostgreSQL 클러스터 형식에서 다음을 수행합니다.
기본 사항 탭에서 정보를 작성합니다.
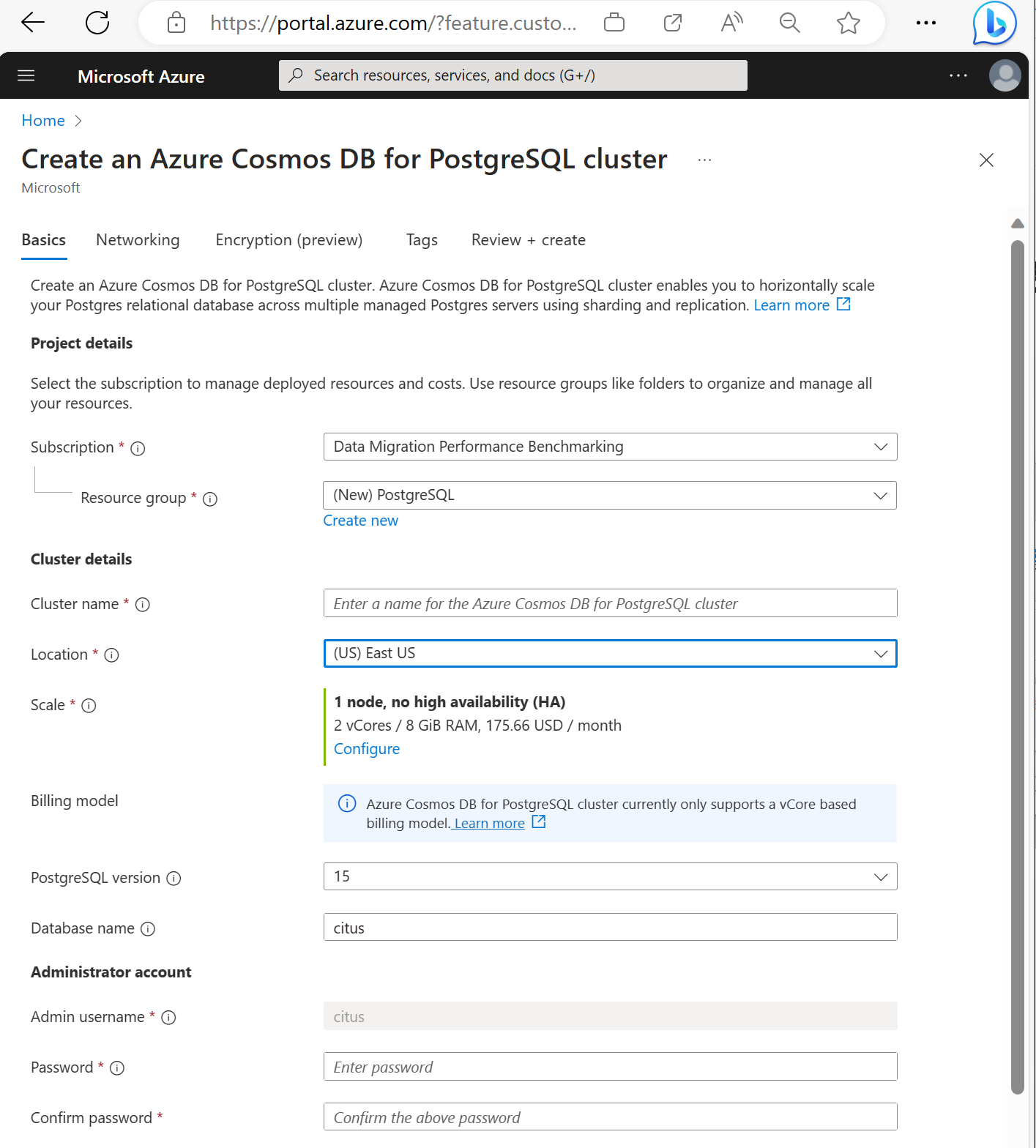
대부분의 옵션은 설명할 수 있지만 다음 사항에 유의하세요.
- 클러스터 이름에 따라 애플리케이션이 연결에 사용하는 DNS 이름이
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com형식으로 설정됩니다. - 15와 같은 주 PostgreSQL 버전을 선택할 수 있습니다. Azure Cosmos DB for PostgreSQL은 항상 선택한 주 Postgres 버전에 대한 최신 Citus 버전을 지원합니다.
- 관리 사용자 이름은
citus값이어야 합니다. - 데이터베이스 이름을 기본값 'citus'로 두거나 유일한 데이터베이스 이름을 정의할 수 있습니다. 클러스터 프로비저닝 후에는 데이터베이스 이름을 바꿀 수 없습니다.
- 클러스터 이름에 따라 애플리케이션이 연결에 사용하는 DNS 이름이
화면 아래쪽에서 다음: 네트워킹을 선택합니다.
네트워킹 화면에서 이 클러스터에 대한 Azure 내 Azure 서비스 및 리소스의 퍼블릭 액세스 허용을 선택합니다.
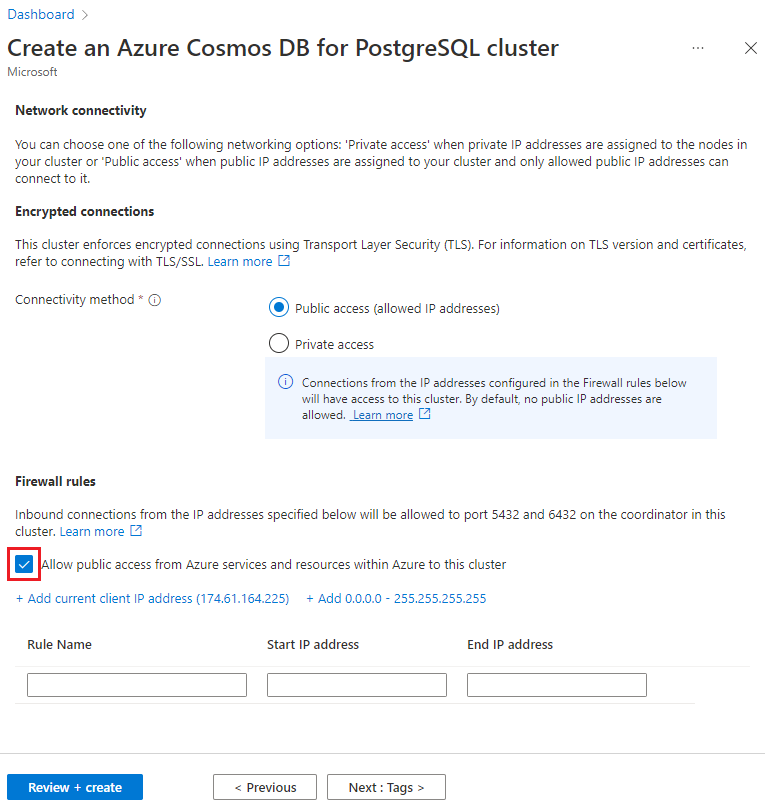
검토 + 만들기를 선택하고 유효성 검사가 통과되면 만들기를 선택하여 클러스터를 만듭니다.
설정하는 데 몇 분이 걸립니다. 이 페이지는 배포를 모니터링하도록 리디렉션됩니다. 상태가 배포 진행 중에서 배포 완료로 변경되면 리소스로 이동을 선택합니다.
마이크로 서비스에 대한 역할 만들기
분산 스키마는 Azure Cosmos DB for PostgreSQL 클러스터 내에서 재배치 가능합니다. 시스템은 사용 가능한 노드 전체에서 전체 단위로 리밸런싱할 수 있으므로 수동 할당 없이 리소스를 효율적으로 공유할 수 있습니다.
설계상 마이크로 서비스는 자체 스토리지 계층을 소유하므로 마이크로 서비스가 만들고 저장하는 테이블 및 데이터 형식에 대해 어떠한 가정도 하지 않습니다. 모든 서비스에 대한 스키마를 제공하고 데이터베이스에 연결하기 위해 고유한 ROLE을 사용한다고 가정합니다. 사용자가 연결하면 역할 이름이 search_path 시작 부분에 배치되므로 역할이 스키마 이름과 일치하면 올바른 search_path를 설정하기 위해 애플리케이션을 변경할 필요가 없습니다.
이 예에서는 세 가지 서비스를 사용합니다.
- 사용자
- 시간
- 핑 (Ping)
사용자 역할을 만드는 방법을 설명하는 단계를 따르고 각 서비스에 대해 다음 역할을 만듭니다.
userservicetimeservicepingservice
psql 유틸리티를 사용하여 분산 스키마 만들기
psql을 사용하여 Azure Cosmos DB for PostgreSQL에 연결되면 몇 가지 기본 작업을 완료할 수 있습니다.
Azure Cosmos DB for PostgreSQL에 스키마를 배포할 수 있는 방법에는 두 가지가 있습니다.
citus_schema_distribute(schema_name) 함수를 호출하여 수동으로:
CREATE SCHEMA AUTHORIZATION userservice;
CREATE SCHEMA AUTHORIZATION timeservice;
CREATE SCHEMA AUTHORIZATION pingservice;
SELECT citus_schema_distribute('userservice');
SELECT citus_schema_distribute('timeservice');
SELECT citus_schema_distribute('pingservice');
이 메서드를 사용하면 기존 일반 스키마를 분산 스키마로 변환할 수도 있습니다.
참고
분산 및 참조 테이블이 포함되지 않은 스키마만 배포할 수 있습니다.
대체 방식은 citus.enable_schema_based_sharding 구성 변수를 사용하도록 설정하는 것입니다.
SET citus.enable_schema_based_sharding TO ON;
CREATE SCHEMA AUTHORIZATION userservice;
CREATE SCHEMA AUTHORIZATION timeservice;
CREATE SCHEMA AUTHORIZATION pingservice;
변수는 현재 세션 동안 변경되거나 코디네이터 노드 매개 변수에서 영구적으로 변경될 수 있습니다. 매개 변수를 ON으로 설정하면 만들어진 모든 스키마가 기본적으로 배포됩니다.
다음을 실행하여 현재 배포된 스키마를 나열할 수 있습니다.
select * from citus_schemas;
schema_name | colocation_id | schema_size | schema_owner
-------------+---------------+-------------+--------------
userservice | 5 | 0 bytes | userservice
timeservice | 6 | 0 bytes | timeservice
pingservice | 7 | 0 bytes | pingservice
(3 rows)
샘플 서비스에 대한 테이블 만들기
이제 모든 마이크로 서비스에 대해 Azure Cosmos DB for PostgreSQL에 연결해야 합니다. \c 명령을 사용하여 기존 psql 인스턴스 내에서 사용자를 바꿀 수 있습니다.
\c citus userservice
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL
);
\c citus timeservice
CREATE TABLE query_details (
id SERIAL PRIMARY KEY,
ip_address INET NOT NULL,
query_time TIMESTAMP NOT NULL
);
\c citus pingservice
CREATE TABLE ping_results (
id SERIAL PRIMARY KEY,
host VARCHAR(255) NOT NULL,
result TEXT NOT NULL
);
서비스 구성
이 자습서에서는 간단한 서비스 집합을 사용합니다. 다음 공용 리포지토리를 복제하여 가져올 수 있습니다.
git clone https://github.com/citusdata/citus-example-microservices.git
$ tree
.
├── LICENSE
├── README.md
├── ping
│ ├── app.py
│ ├── ping.sql
│ └── requirements.txt
├── time
│ ├── app.py
│ ├── requirements.txt
│ └── time.sql
└── user
├── app.py
├── requirements.txt
└── user.sql
그러나 서비스를 실행하기 전에 Azure Cosmos DB for PostgreSQL 클러스터에 대한 user/app.py을 제공하는 ping/app.py, time/app.py 및 파일을 편집합니다.
# Database configuration
db_config = {
'host': 'c-EXAMPLE.EXAMPLE.postgres.cosmos.azure.com',
'database': 'citus',
'password': 'SECRET',
'user': 'pingservice',
'port': 5432
}
변경 후 수정된 파일을 모두 저장하고 서비스 실행의 다음 단계로 이동합니다.
서비스 실행
모든 앱 디렉터리로 변경하고 자체 Python 환경에서 실행합니다.
cd user
pipenv install
pipenv shell
python app.py
시간 및 ping 서비스에 대한 명령을 반복한 후 API를 사용할 수 있습니다.
일부 사용자를 만듭니다.
curl -X POST -H "Content-Type: application/json" -d '[
{"name": "John Doe", "email": "john@example.com"},
{"name": "Jane Smith", "email": "jane@example.com"},
{"name": "Mike Johnson", "email": "mike@example.com"},
{"name": "Emily Davis", "email": "emily@example.com"},
{"name": "David Wilson", "email": "david@example.com"},
{"name": "Sarah Thompson", "email": "sarah@example.com"},
{"name": "Alex Miller", "email": "alex@example.com"},
{"name": "Olivia Anderson", "email": "olivia@example.com"},
{"name": "Daniel Martin", "email": "daniel@example.com"},
{"name": "Sophia White", "email": "sophia@example.com"}
]' http://localhost:5000/users
만들어진 사용자를 나열합니다.
curl http://localhost:5000/users
현재 시간 가져오기:
Get current time:
example.com에 대해 ping을 실행합니다.
curl -X POST -H "Content-Type: application/json" -d '{"host": "example.com"}' http://localhost:5002/ping
데이터베이스 탐색
이제 일부 API 함수를 호출했으므로 데이터가 저장되었으며 citus_schemas가 예상한 내용을 반영하는지 확인할 수 있습니다.
select * from citus_schemas;
schema_name | colocation_id | schema_size | schema_owner
-------------+---------------+-------------+--------------
userservice | 1 | 112 kB | userservice
timeservice | 2 | 32 kB | timeservice
pingservice | 3 | 32 kB | pingservice
(3 rows)
스키마를 만들 때 Azure Cosmos DB for PostgreSQL에 스키마를 만들 컴퓨터를 알려 주지 않았습니다. 자동으로 수행되었습니다. 다음 쿼리를 사용하면 각 스키마가 어디에 있는지 확인할 수 있습니다.
select nodename,nodeport, table_name, pg_size_pretty(sum(shard_size))
from citus_shards
group by nodename,nodeport, table_name;
nodename | nodeport | table_name | pg_size_pretty
-----------+----------+---------------------------+----------------
localhost | 9701 | timeservice.query_details | 32 kB
localhost | 9702 | userservice.users | 112 kB
localhost | 9702 | pingservice.ping_results | 32 kB
이 페이지의 출력 예를 간결하게 하기 위해 Azure Cosmos DB for PostgreSQL에 표시된 대로 nodename을 사용하는 대신 이를 localhost로 바꿉니다.
localhost:9701이 작업자 1이고 localhost:9702가 작업자 2라고 가정합니다. 관리되는 서비스의 노드 이름은 더 길고 임의 요소를 포함합니다.
사용자와 ping 서비스가 두 번째 작업자 localhost:9701의 공간을 공유하는 동안 시간 서비스가 노드 localhost:9702에 도달한 것을 볼 수 있습니다. 예제 앱은 단순하고 여기에 있는 데이터 크기는 무시할 수 있지만 노드 간의 스토리지 활용이 고르지 않아 짜증이 난다고 가정해 보겠습니다. 두 개의 작은 시간 및 ping 서비스가 하나의 컴퓨터에 있고 대규모 사용자 서비스는 단독으로 존재하는 것이 더 합리적입니다.
디스크 크기에 따라 클러스터의 균형을 쉽게 리밸런싱할 수 있습니다.
select citus_rebalance_start();
NOTICE: Scheduled 1 moves as job 1
DETAIL: Rebalance scheduled as background job
HINT: To monitor progress, run: SELECT * FROM citus_rebalance_status();
citus_rebalance_start
-----------------------
1
(1 row)
완료되면 새 레이아웃이 어떻게 보이는지 확인할 수 있습니다.
select nodename,nodeport, table_name, pg_size_pretty(sum(shard_size))
from citus_shards
group by nodename,nodeport, table_name;
nodename | nodeport | table_name | pg_size_pretty
-----------+----------+---------------------------+----------------
localhost | 9701 | timeservice.query_details | 32 kB
localhost | 9701 | pingservice.ping_results | 32 kB
localhost | 9702 | userservice.users | 112 kB
(3 rows)
예상 결과에 따라 스키마가 이동되었으며 보다 균형 잡힌 클러스터가 생겼습니다. 이 작업은 애플리케이션에 대해 투명했습니다. 다시 시작할 필요도 없으며 계속해서 쿼리를 제공합니다.
다음 단계
이 자습서에서는 분산 스키마를 만들고 이를 스토리지로 사용하여 마이크로 서비스를 실행하는 방법을 알아보았습니다. 또한 스키마 기반 분할된 Azure Cosmos DB for PostgreSQL을 탐색하고 관리하는 방법도 알아보았습니다.
- 클러스터 노드 유형에 대해 알아보기