Azure Cosmos DB 요청 빈도 너무 높음(429) 예외 진단 및 문제 해결
적용 대상: ![]() NoSQL
NoSQL
이 문서에는 API for NoSQL에 대한 다양한 429 상태 코드 오류의 알려진 원인 및 해결 방법이 포함됩니다. API for MongoDB를 사용하는 경우 상태 코드 16500을 디버그하는 방법은 API for MongoDB의 일반적인 문제 해결 문서를 참조하세요.
오류 코드 429라고도 하는 “요청 빈도 너무 높음” 예외는 Azure Cosmos DB에 대한 요청의 빈도가 제한되고 있음을 나타냅니다.
프로비저닝된 처리량을 사용하는 경우 워크로드에 필요한 초당 요청 단위(RU/초)로 측정된 처리량을 설정합니다. 읽기, 쓰기, 쿼리와 같은 서비스에 대한 데이터베이스 작업은 일정 수의 RU(요청 단위)를 사용합니다. 요청 단위에 대해 자세히 알아봅니다.
특정 1초 내에 작업이 프로비저닝된 요청 단위보다 더 많이 사용하는 경우 Azure Cosmos DB는 429 예외를 반환합니다. 1초마다 사용할 수 있는 요청 단위 수가 다시 설정됩니다.
RU/초를 변경하는 작업을 수행하기 전에 빈도 제한의 근본 원인을 파악하고 기본 문제를 해결하는 것이 중요합니다.
팁
이 문서의 지침은 프로비저닝된 처리량(자동 크기 조정 및 수동 처리량 모두)을 사용하는 데이터베이스 및 컨테이너에 적용됩니다.
다른 유형의 429 예외에 해당하는 다양한 오류 메시지가 있습니다.
- 요청 속도가 높습니다. 더 많은 요청 단위가 필요할 수 있으므로 변경 내용이 없습니다.
- 메타데이터 요청 빈도가 높아서 요청이 완료되지 않았습니다.
- 일시적인 서비스 오류로 인해 요청이 완료되지 않았습니다.
요청 빈도가 높습니다.
이는 가장 일반적인 시나리오입니다. 데이터에 대한 작업에서 사용하는 요청 단위가 프로비저닝된 RU/초 수를 초과할 때 발생합니다. 수동 처리량을 사용하는 경우 프로비저닝된 수동 처리량보다 더 많은 RU/초를 사용한 경우에 발생합니다. 자동 크기 조정을 사용하는 경우 프로비저닝된 최대 RU/초를 초과하여 사용한 경우에 발생합니다. 예를 들어, 수동 처리량이 400 RU/초로 프로비저닝된 리소스가 있는 경우 1초에 400개 이상의 요청 단위를 사용하면 429가 표시됩니다. 자동 크기 조정 최대 RU/초가 4,000 RU/초(400 RU/초에서 4000 RU/초 사이)로 프로비저닝된 리소스가 있는 경우 1초에 4,000개 이상의 요청 단위를 사용하면 429 응답이 표시됩니다.
팁
모든 작업은 사용하는 리소스 수에 따라 요금이 청구됩니다. 이러한 요금은 요청 단위로 측정됩니다. 이러한 요금에는 400, 412, 449 등과 같은 애플리케이션 오류로 인해 성공적으로 완료되지 못한 요청이 포함됩니다. 제한이나 사용량을 살펴보는 동안 사용량의 일부 패턴이 변경되어 이러한 작업이 증가하는지 조사하는 것이 좋습니다. 특히 태그 412 또는 449(실제 충돌)에 대해 검사합니다.
프로비전된 처리량에 대한 자세한 내용은 Azure Cosmos DB에서 프로비전된 처리량을 참조하세요.
1단계: 메트릭을 확인하여 429 오류가 있는 요청 비율 확인
429 오류 메시지가 표시되는 것이 반드시 데이터베이스 또는 컨테이너에 문제가 있음을 의미하지는 않습니다. 수동 처리량 또는 자동 크기 조정 처리량을 사용하는지 여부에 관계없이 적은 비율의 429 응답은 정상이며 프로비저닝한 RU/초를 최대화하고 있다는 신호입니다.
조사 방법
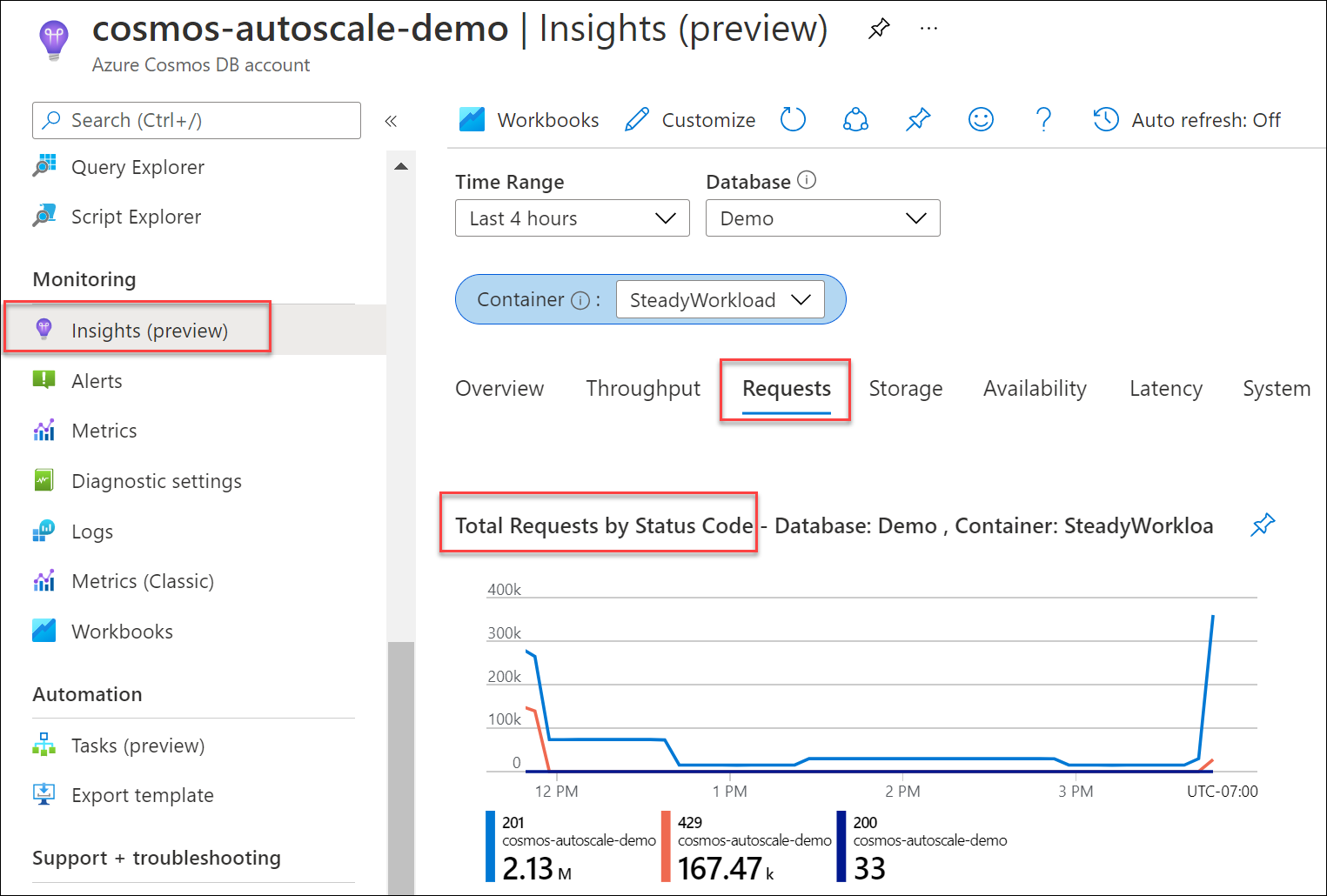
요청의 전체 성공 횟수에 비해 429 응답을 초래한 데이터베이스 또는 컨테이너에 대한 요청 비율을 확인합니다. Azure Cosmos DB 계정에서 인사이트>요청>상태 코드별 총 요청으로 이동합니다. 특정 데이터베이스 및 컨테이너로 필터링합니다.
기본적으로 Azure Cosmos DB 클라이언트 SDK 및 데이터 가져오기 도구(예: Azure Data Factory, 대량 실행기 라이브러리)는 429에서 자동으로 요청을 다시 시도합니다. 일반적으로 9회까지 다시 시도합니다. 따라서 메트릭에 429 응답이 표시되더라도 이 오류는 애플리케이션에 반환되지 않았을 수 있습니다.
권장된 솔루션
일반적으로 프로덕션 워크로드의 경우 429 응답이 있는 요청의 1~5% 사이가 표시되고 엔드투엔드 대기 시간이 허용되면 이는 RU/초가 완전히 활용되고 있다는 정상 신호입니다. 사용자가 조치할 필요는 없습니다. 그렇지 않으면 다음 문제 해결 단계로 이동합니다.
Important
이 1~5% 범위는 계정 파티션이 균등하게 분산되어 있다고 가정합니다. 파티션이 균등하게 분산되지 않은 경우 문제 파티션은 전체 속도가 낮을 수 있는 동안 많은 양의 429 오류를 반환할 수 있습니다.
자동 크기 조정을 사용하는 경우 RU/초가 최대 RU/초로 스케일링되지 않은 경우에도 데이터베이스 또는 컨테이너에서 429 응답이 표시됩니다. 설명은 자동 크기 조정을 사용하여 요청 빈도가 높음 섹션을 참조하세요.
한 가지 일반적인 질문은 "Azure Monitor 메트릭에는 429 응답이 표시되지만 자체 애플리케이션 모니터링에는 표시되지 않는 이유는 무엇입니까?"입니다. Azure Monitor 메트릭에 429 응답이 표시되지만 자체 애플리케이션에는 표시되지 않는 경우 기본적으로 Azure Cosmos DB 클라이언트 SDK의 automatically retried internally on the 429 responses 및 요청이 후속 다시 시도에서 성공했기 때문입니다. 따라서 429 상태 코드는 애플리케이션에 반환되지 않습니다. 이러한 경우 429 응답의 전체 비율은 일반적으로 매우 낮으며 전체 비율이 1~5% 사이이고 엔드투엔드 대기 시간이 애플리케이션에 허용된다고 가정하면 무시해도 됩니다.
2단계: 핫 파티션이 있는지 확인
핫 파티션은 더 높은 요청 볼륨으로 인해 하나 이상의 논리 파티션 키가 총 RU/초의 너무 작은 크기를 사용하는 경우에 발생합니다. 이는 요청을 균등하게 분산하지 않는 파티션 키 디자인으로 인해 발생할 수 있습니다. 그 결과 많은 요청이 "핫"이 되는 논리적(물리적 의미) 파티션의 작은 하위 집합으로 전달됩니다. 논리적 파티션의 모든 데이터는 하나의 물리적 파티션에 있고 총 RU/s는 물리적 파티션 간에 고르게 분산되기 때문에 핫 파티션은 429 응답을 발생시키고 처리량을 비효율적으로 사용할 수 있습니다.
핫 파티션을 발생시키는 분할 전략의 몇 가지 예제는 다음과 같습니다.
date별로 분할되는 쓰기 작업이 많은 워크로드의 IoT 디바이스 데이터를 저장하는 컨테이너가 있습니다. 단일 날짜의 모든 데이터는 동일한 논리 및 물리적 파티션에 있습니다. 매일 기록된 모든 데이터에는 동일한 날짜가 있기 때문에 매일 핫 파티션이 발생합니다.- 대신 이 시나리오의 경우
id(GUID 또는 디바이스 ID)와 같은 파티션 키 또는id와date를 결합하는 합성 파티션 키를 사용하면 값의 카디널리티를 높이고 요청 볼륨을 더 효율적으로 분산합니다.
- 대신 이 시나리오의 경우
tenantId별로 분할된 컨테이너를 사용하는 다중 테넌트 시나리오가 있습니다. 한 테넌트가 다른 테넌트보다 훨씬 더 활동적이면 핫 파티션이 발생합니다. 예를 들어, 가장 큰 테넌트에는 100,000명의 사용자가 있지만 대부분의 테넌트에는 10명 미만의 사용자가 있는 경우tenantID별로 분할되면 핫 파티션이 생성됩니다.- 이전 시나리오에서는
UserId와 같은 더 세분화된 속성별로 분할된 가장 큰 테넌트의 전용 컨테이너를 포함하는 것이 좋습니다.
- 이전 시나리오에서는
핫 파티션을 식별하는 방법
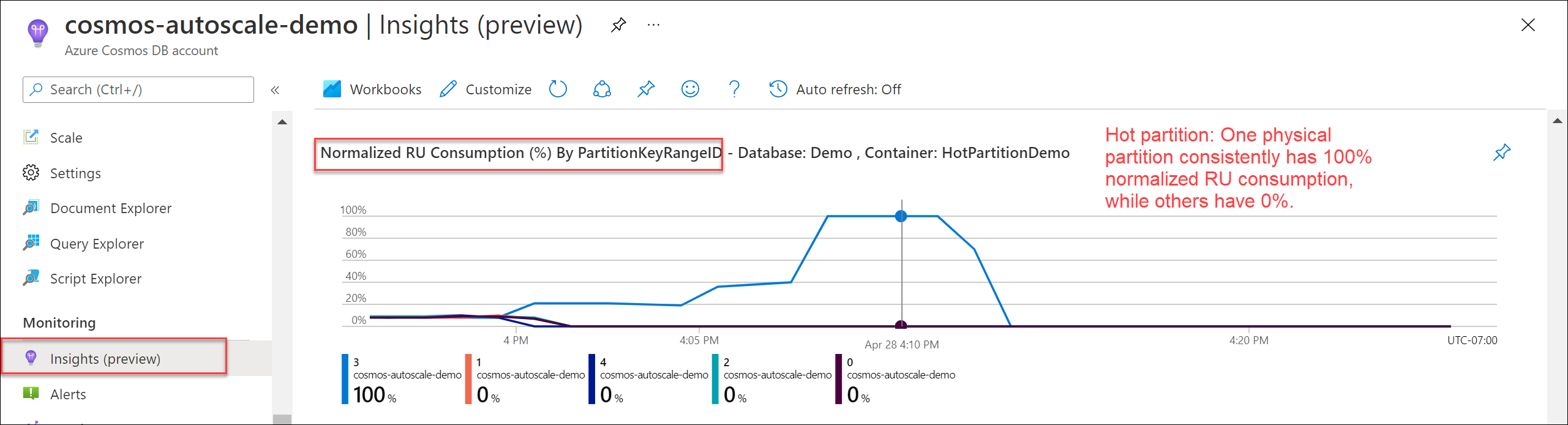
핫 파티션이 있는지 확인하려면 인사이트>처리량>PartitionKeyRangeID별 정규화된 RU 사용량(%)으로 이동합니다. 특정 데이터베이스 및 컨테이너로 필터링합니다.
각 PartitionKeyRangeId는 하나의 물리적 파티션에 매핑됩니다. 한 PartitionKeyRangeId가 다른 항목보다 정규화된 RU 사용량이 훨씬 더 높은 경우(예: 한 항목은 일관되게 100%이지만 다른 항목은 30% 이하인 경우) 핫 파티션의 표시일 수 있습니다. 정규화된 RU 사용량 메트릭에 관해 자세히 알아봅니다.
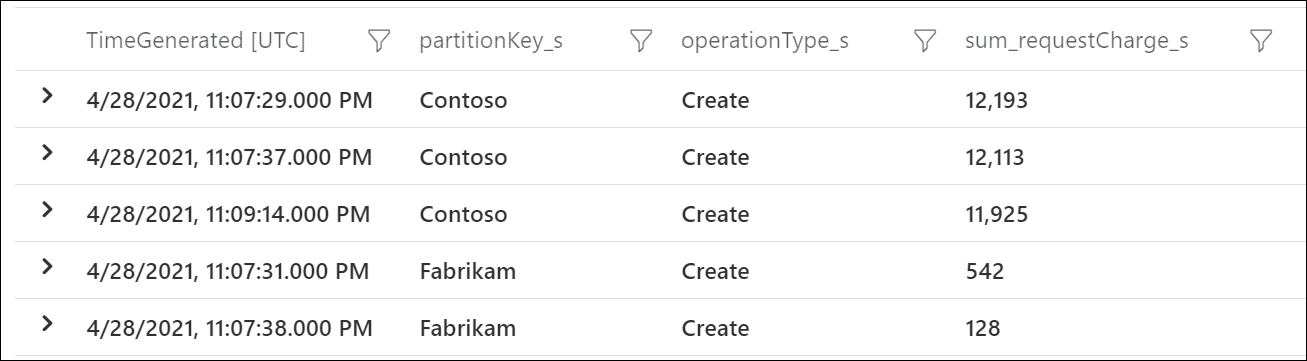
가장 많은 RU/초를 사용하는 논리 파티션 키를 확인하려면 Azure 진단 로그를 사용합니다. 이 샘플 쿼리는 각 논리 파티션 키에서 초당 사용되는 총 요청 단위의 합계를 계산합니다.
Important
진단 로그를 사용하면 수집된 데이터 볼륨에 따라 요금이 청구되는 Log Analytics 서비스에 대한 별도 요금이 발생합니다. 디버깅을 위해 제한된 시간 동안 진단 로그를 켜고 더 이상 필요하지 않은 경우 끄는 것이 좋습니다. 자세한 내용은 가격 책정 페이지를 참조하세요.
CDBPartitionKeyRUConsumption
| where TimeGenerated >= ago(24hour)
| where CollectionName == "CollectionName"
| where isnotempty(PartitionKey)
// Sum total request units consumed by logical partition key for each second
| summarize sum(RequestCharge) by PartitionKey, OperationName, bin(TimeGenerated, 1s)
| order by sum_RequestCharge desc
이 샘플 출력에서는 특정 분에 값이 “Contoso”인 논리 파티션 키가 약 12,000 RU/초를 사용했지만 값이 “Fabrikam”인 논리 파티션 키가 600 RU/초 미만을 사용했음을 보여 줍니다. 빈도 제한이 발생한 기간 동안 이 패턴이 일관되었다면 핫 파티션을 나타냅니다.
팁
모든 워크로드에는 논리 파티션 간에 요청 볼륨의 자연 변형이 있습니다. 핫 파티션이 파티션 키 선택(키 변경이 필요할 수 있음)으로 인한 기초적 왜도 또는 워크로드 패턴의 자연 변형으로 인한 일시적인 급증에 의해 발생하는지 확인해야 합니다.
권장된 솔루션
양호한 파티션 키를 선택하는 방법에 관한 지침을 검토합니다.
빈도 제한 요청의 비율이 높고 핫 파티션이 없는 경우:
- 클라이언트 SDK, Azure Portal, PowerShell, CLI 또는 ARM 템플릿을 사용하여 데이터베이스 또는 컨테이너에서 RU/초를 증가시킬 수 있습니다. 프로비저닝된 처리량(RU/초) 크기 조정 모범 사례에 따라 설정할 올바른 RU를 결정합니다.
빈도 제한 요청의 비율이 높고 기본 핫 파티션이 있는 경우:
- 장기적으로, 최상의 비용 및 성능을 위해서는 파티션 키를 변경하는 것이 좋습니다. 파티션 키는 현재 위치에서 업데이트할 수 없으므로 다른 파티션 키를 사용하여 데이터를 새 컨테이너로 마이그레이션해야 합니다. Azure Cosmos DB는 이를 위해 라이브 데이터 마이그레이션 도구를 지원합니다.
- 단기적으로, 리소스의 전반적인 RU/초를 일시적으로 늘려서 핫 파티션에 대한 더 많은 처리량을 허용할 수 있습니다. 이는 RU/초를 오버프로비저닝하고 비용이 더 많이 들기 때문에 장기 전략으로 권장되지 않습니다.
- 단기적으로 파티션 간 처리량 재배포 기능(미리 보기)을 사용하여 핫인 실제 파티션에 더 많은 RU/s를 할당할 수 있습니다. 이는 핫 물리적 파티션이 예측 가능하고 일관된 경우에만 권장됩니다.
팁
처리량을 늘리면 스케일 업 작업이 즉시 완료되거나 스케일 업하려는 RU/초 수에 따라 완료하는 데 최대 5~6시간이 필요합니다. 비동기 스케일 업 작업을 트리거하지 않고 설정할 수 있는(Azure Cosmos DB가 더 많은 물리적 파티션을 프로비저닝하는 데 필요한) 가장 높은 RU/초 수를 알아보려면 고유한 PartitionKeyRangeId 수에 10,0000 RU/초를 곱합니다. 예를 들어, 30,000 RU/초가 프로비저닝되고 5개 물리적 파티션(물리적 파티션당 6000 RU/초가 할당됨)이 있는 경우 즉각적인 스케일 업 작업에서 50,000 RU/초(물리적 파티션당 10,000 RU/초)로 늘릴 수 있습니다. >50,000 RU/초보다 크게 늘리려면 비동기 스케일 업 작업이 필요합니다. 자세한 내용은 프로비저닝된 처리량(RU/초) 크기 조정 모범 사례를 참조하세요.
3단계: 429 응답을 반환하는 요청 확인
429 응답이 있는 요청을 조사하는 방법
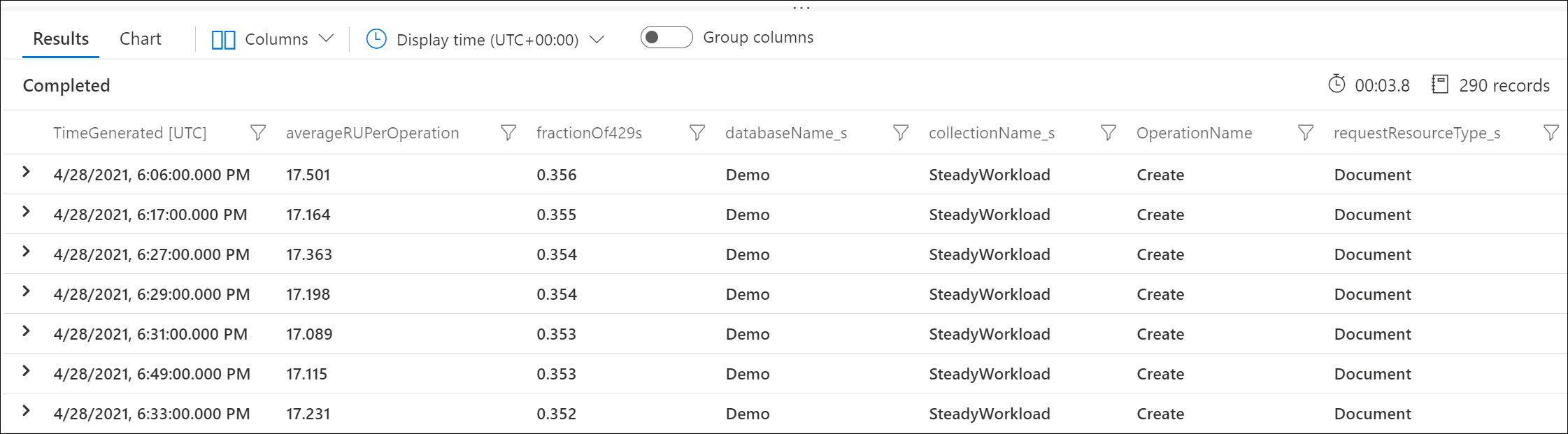
Azure 진단 로그를 사용하여 429 응답을 반환하는 요청 및 사용한 RU 수를 식별합니다. 이 샘플 쿼리는 분 수준에서 집계됩니다.
Important
진단 로그를 사용하면 수집된 데이터 볼륨에 따라 요금이 청구되는 Log Analytics 서비스에 대한 별도 요금이 발생합니다. 디버깅을 위해 제한된 시간 동안 진단 로그를 켜고 더 이상 필요하지 않은 경우 끄는 것이 좋습니다. 자세한 내용은 가격 책정 페이지를 참조하세요.
CDBDataPlaneRequests
| where TimeGenerated >= ago(24h)
| summarize throttledOperations = dcountif(ActivityId, StatusCode == 429), totalOperations = dcount(ActivityId), totalConsumedRUPerMinute = sum(RequestCharge) by DatabaseName, CollectionName, OperationName, RequestResourceType, bin(TimeGenerated, 1min)
| extend averageRUPerOperation = 1.0 * totalConsumedRUPerMinute / totalOperations
| extend fractionOf429s = 1.0 * throttledOperations / totalOperations
| order by fractionOf429s desc
예를 들어, 샘플 출력은 1분마다 문서 만들기 요청의 30%가 빈도 제한되었으며 각 요청은 평균 17 RU를 사용함을 보여 줍니다.
권장된 솔루션
Azure Cosmos DB 용량 플래너 사용
Azure Cosmos DB 용량 플래너를 사용하여 워크로드(작업 볼륨 및 유형, 문서 크기)에 따라 프로비저닝된 처리량이 가장 적합한지 파악할 수 있습니다. 보다 정확한 추정을 위해 샘플 데이터를 제공하여 추가 계산을 사용자 지정할 수 있습니다.
문서 만들기, 바꾸기 또는 upsert 요청에 대한 429 응답
- 기본적으로 API for NoSQL에서 모든 속성은 인덱싱됩니다. 필요한 속성만 인덱싱하도록 인덱싱 정책을 조정합니다. 이렇게 하면 문서 만들기 작업당 필요한 요청 단위가 감소하여 429 응답이 표시될 가능성이 감소하거나 프로비저닝된 RU/초의 동일한 양에 대해 초당 더 높은 작업을 수행할 수 있습니다.
문서 쿼리 요청에 대한 429 응답
- 높은 RU 요금이 부과되는 쿼리 문제를 해결하기 위한 지침을 따릅니다.
저장 프로시저 실행에 대한 429 응답
- 저장 프로시저는 파티션 키 값에서 쓰기 트랜잭션이 필요한 작업에 사용됩니다. 많은 읽기 또는 쿼리 작업에는 저장 프로시저를 사용하지 않는 것이 좋습니다. 최상의 성능을 위해 Azure Cosmos DB SDK를 사용하여 클라이언트 쪽에서 읽기 또는 쿼리 작업을 수행해야 합니다.
자동 크기 조정을 사용하여 요청 빈도가 높음
이 문서의 모든 지침은 수동 및 자동 크기 조정 처리량 모두에 적용됩니다.
자동 크기 조정을 사용할 때 발생하는 일반적인 질문은 "자동 크기 조정을 사용하는 경우 여전히 429 응답이 표시됩니까?"입니다.
예. 이 오류가 발생할 수 있는 다음 두 가지 주요 시나리오가 있습니다.
시나리오 1: 사용된 전체 RU/초가 데이터베이스 또는 컨테이너의 최대 RU/초를 초과하는 경우 서비스가 적절히 요청을 제한합니다. 이는 데이터베이스 또는 컨테이너의 전체 수동 프로비저닝된 처리량을 초과하는 것과 유사합니다.
시나리오 2: 핫 파티션(즉, 다른 파티션 키 값과 비교하여 과도하게 요청이 많은 논리 파티션 키 값)이 있는 경우 기본 실제 파티션이 RU/초 예산을 초과할 수 있습니다. 핫 파티션을 방지하려면 스토리지와 처리량을 모두 균등하게 분산하는 우수한 파티션 키를 선택합니다. 이는 수동 처리량을 사용할 때 핫 파티션이 있는 경우와 비슷합니다.
예를 들어, 20,000 RU/초 최대 처리량 옵션을 선택하고, 4개의 실제 파티션이 있는 200GB 스토리지를 사용하는 경우 각 실제 파티션은 최대 5,000 RU/초로 자동 크기 조정될 수 있습니다. 특정 논리 파티션 키에 핫 파티션이 있는 경우 해당 키가 상주하는 기본 실제 파티션이 5,000 RU/초를 초과하면(즉, 100% 정규화된 사용률을 초과하는 경우) 429 응답이 표시됩니다.
1단계, 2단계 및 3단계의 지침에 따라 이러한 시나리오를 디버그합니다.
또 다른 일반적인 질문은 정규화된 RU 사용량이 100%인데 자동 크기 조정이 최대 RU/초로 스케일링되지 않는 이유는 무엇입니까?입니다.
이는 일반적으로 일시적 또는 간헐적으로 사용량이 급증하는 워크로드에서 발생합니다. 자동 크기 조정을 사용하는 경우 Azure Cosmos DB는 정규화된 RU 사용량이 5초 간격의 지속적이고 연속적인 기간 동안 100%인 경우에만 RU/초를 최대 처리량으로 스케일링합니다. 이는 단 한 번의 일시적인 급증이 불필요한 크기 조정 및 더 높은 비용으로 이어지지 않도록 보장하므로 크기 조정 논리가 사용자에게 비용 친화적인지 확인하기 위해 수행됩니다. 일시적인 급증이 있는 경우 시스템은 일반적으로 이전에 RU/초로 스케일링된 값보다 높지만 최대 RU/초보다 낮은 값으로 스케일 업됩니다. 자동 크기 조정을 사용하여 정규화된 RU 사용량 메트릭을 해석하는 방법에 대해 자세히 알아봅니다.
메타데이터 요청에 대한 빈도 제한
메타데이터 빈도 제한은 데이터베이스 및/또는 컨테이너에서 대용량 메타데이터 작업을 수행할 때 발생할 수 있습니다. 메타데이터 작업은 다음을 포함합니다.
- 컨테이너 또는 데이터베이스 만들기, 읽기, 업데이트 또는 삭제
- Azure Cosmos DB 계정의 데이터베이스 또는 컨테이너 나열
- 제안을 쿼리하여 현재 프로비저닝된 처리량 확인
이 작업에 대한 시스템 예약 RU 제한이 있으므로 데이터베이스 또는 컨테이너의 프로비저닝된 RU/초를 늘리는 것은 영향을 주지 않으며 권장되지 않습니다. 컨트롤 플레인 서비스 제한을 참조하세요.
조사 방법
인사이트>시스템>상태 코드별 메타데이터 요청으로 이동합니다. 원하는 경우 특정 데이터베이스 및 컨테이너로 필터링합니다.
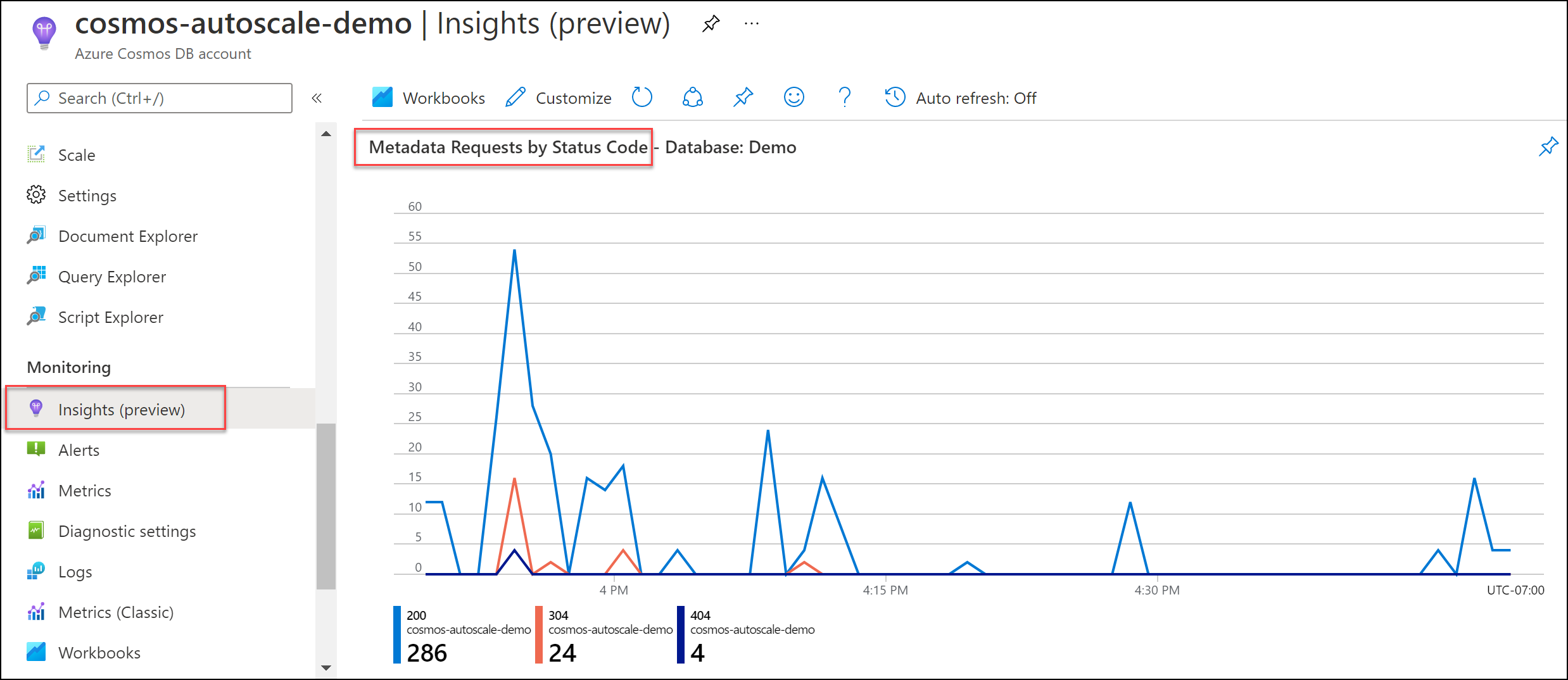
권장된 솔루션
애플리케이션이 메타데이터 작업을 수행해야 하는 경우에는 요청을 더 낮은 빈도로 전송하는 백오프 정책을 구현하는 것이 좋습니다.
정적 Azure Cosmos DB 클라이언트 인스턴스 사용 DocumentClient 또는 CosmosClient가 초기화되면 Azure Cosmos DB SDK는 일관성 수준, 데이터베이스, 컨테이너, 파티션, 제안에 관한 정보를 포함하여 계정에 관한 메타데이터를 가져옵니다. 이 초기화는 많은 수의 RU를 사용할 수 있으며 드물게 수행해야 합니다. 단일 DocumentClient 인스턴스를 사용하며 애플리케이션의 수명에 대해 사용합니다.
데이터베이스 및 컨테이너의 이름을 캐시합니다. 구성에서 데이터베이스 및 컨테이너의 이름을 검색하거나 시작할 때 이름을 캐시합니다. ReadDatabaseAsync/ReadDocumentCollectionAsync 또는 CreateDatabaseQuery/CreateDocumentCollectionQuery 같은 호출은 시스템 예약 RU 제한에서 사용되는 서비스에 대한 메타데이터 호출을 생성합니다. 이 작업은 자주 수행되지 않습니다.
일시적인 서비스 오류로 인한 빈도 제한
이 429 오류는 요청에 일시적인 서비스 오류가 발생할 때 반환됩니다. 데이터베이스 또는 컨테이너에 대한 RU/초를 늘리는 것은 영향을 주지 않으며 권장되지 않습니다.
권장된 솔루션
요청을 다시 시도하십시오. 오류가 몇 분 동안 지속되면 Azure Portal에서 지원 티켓을 제출합니다.
다음 단계
- 데이터베이스 또는 컨테이너의 정규화 RU/초 사용량을 모니터링합니다.
- Azure Cosmos DB .NET SDK를 사용하고 있는 경우 문제를 진단 및 해결합니다.
- .NET v3 및 .NET v2의 성능 지침에 대해 알아봅니다.
- Azure Cosmos DB Java v4 SDK를 사용할 때 발생하는 문제를 진단하고 해결합니다.
- Java v4 SDK의 성능 지침에 대해 알아봅니다.