상태 검사
CycleCloud는 VM의 상태를 확인하는 두 가지 메커니즘을 제공합니다. 노드 상태 검사는 프로비전 단계 중에 검사를 수행하고 비정상 VM의 조인을 방지하는 최신 기능이며, HealthCheck는 VM이 클러스터를 노드로 조인한 후 주기적으로 실행합니다.
노드 상태 검사
노드 상태 검사는 VM이 CycleCloud 클러스터에 조인하도록 허용되기 전에 비정상 하드웨어를 검색할 수 있습니다. 이 기능의 현재 버전은 /opt/azurehpc/test/azurehpc-health-checks/에서 찾을 수 있는 공식 AzureHPC 이미지에 기본 제공되는 상태 검사 스크립트를 실행합니다. 이러한 스크립트의 원본은 AzureHPC 노드 상태 검사 리포지토리에 있지만 클러스터의 AzureHPC 이미지 버전에 기본 제공되는 버전은 리포지토리에서 사용할 수 있는 최신 버전이 아닐 수 있습니다.
요구 사항
현재 버전의 Node Health Checks는 2023년 11월 7일 이후에 릴리스된 AzureHPC 이미지(azurehpc-health-checks 버전 v2.0.6 이상 포함) 및 해당 이미지에서 파생된 사용자 지정 이미지만 지원합니다. 노드 상태 검사는 현재 Windows에서 지원되지 않습니다.
Slurm 클러스터에 대한 노드 상태 검사 사용
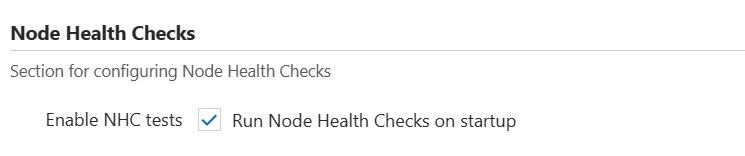
Slurm 클러스터 만들기 양식은 고급 설정 탭 아래에 있는 노드 상태 검사를 사용하도록 설정하는 확인란을 제공합니다. 확인란을 선택하면 클러스터의 HPC 노드 배열에서 노드 상태 검사를 사용할 수 있습니다. 다른 노드 배열(또는 다른 클러스터 유형)에서 노드 상태 검사를 사용하도록 설정하려면 사용자 지정 클러스터 템플릿을 사용해야 합니다.
실행 중인 클러스터에서 확인란의 선택을 취소하면 노드 상태 검사를 사용하지 않도록 설정할 수 있습니다. 변경 내용이 적용되려면 노드 배열을 축소할 필요가 없습니다.
노드 상태 검사 결과 이해
VM이 상태 검사를 통과하면 소프트웨어 구성 단계로 이동합니다.
VM이 상태 검사 스크립트에 실패하면 오류 메시지가 CycleCloud로 전송되고 VM이 클러스터에 조인되지 않도록 자동으로 방지됩니다.
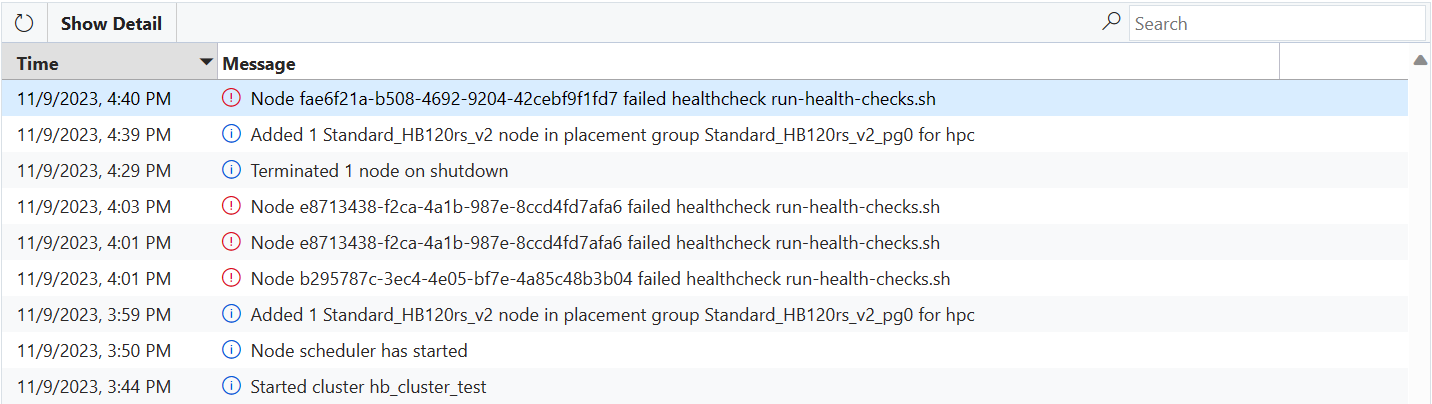
오버 프로비저닝이 사용하도록 설정된 NodeArray에서 VM이 시작된 경우(예: Slurm hpc 노드 배열) 오버 프로비저닝의 일부로 VM을 자동으로 교체해야 합니다. 이 경우 필요한 작업이 없으며 클러스터에 조인하기 위해 정상 VM이 선택됩니다(하나 이상의 VM이 검사에 실패했음을 나타내는 오류 메시지가 클러스터 페이지에 표시됨).
단일 노드에 대해 VM이 시작되거나, 오버 프로비전이 비활성화된 노드 배열(예: Slurm htc Node Array)이 있거나, 오버 프로비저닝에서 지원하는 것보다 더 많은 VM이 상태 검사에 실패하면 노드가 실패 상태로 이동하고 할당이 실패합니다. CycleCloud는 문제를 해결하기 위해 VM을 다시 이미지화하려고 시도할 수 있지만, 다시 이미지가 실패하면 노드를 종료하고 교체해야 합니다(관리자가 수동으로 또는 자동 크기 조정기에 의해 자동으로).
참고
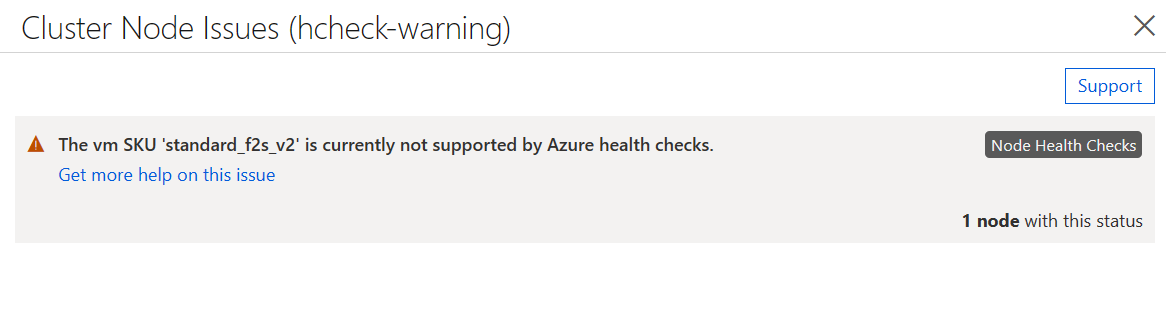
노드 상태 검사를 사용하도록 설정했지만 VM 이미지가 위의 요구 사항을 충족하지 않는 경우 모든 VM이 클러스터에 조인할 수 있지만 상태 검사가 지원되지 않음을 나타내는 경고가 포함됩니다.
특성 참조
| attribute | Type | 정의 |
|---|---|---|
| EnableNodeHealthChecks | Boolean | (선택 사항) 이 노드 또는 노드 배열에 대해 부팅 중 노드 상태 검사 사용 |
HealthCheck
Azure CycleCloud는 HealthCheck라는 비정상 상태에 있는 VM(가상 머신)을 종료하는 메커니즘을 제공합니다. 시스템 및 사용자 정의 스크립트(Python 및 Bash)는 VM의 전반적인 상태를 확인하기 위해 주기적으로(Windows에서 5분, Linux에서 10분) 실행됩니다. HealthCheck를 사용하면 관리자가 수동으로 모니터링하고 수정하지 않고도 VM을 종료해야 하는 조건을 정의할 수 있습니다.
기본 제공 HealthCheck 스크립트
CycleCloud 지원 VM에는 두 가지 기본 HealthCheck 스크립트가 함께 제공됩니다.
-
converge_timeout 스크립트는 시작 후 4시간 이내에 소프트웨어 구성을 완료하지 않은 instance 종료합니다. 이 시간 제한 기간은 설정(초 단위로 정의됨)으로
cyclecloud.keepalive.timeout제어할 수 있습니다. - scheduled_shutdown 스크립트는 unix 타임스탬프 초의 종료 시간을 제공하는 한 줄과 설명이 포함된 선택적 두 번째 줄이 포함된 $JETPACK_HOME/run/scheduled_shutdown 작성자 파일을 찾습니다. 현재 시간이 파일에서 가장 빠른 타임스탬프보다 나을 경우 VM은 비정상으로 간주됩니다.
작동 방식
HealthCheck 스크립트는 $JETPACK_HOME/config/healthcheck.d 디렉터리에 있습니다. Linux는 Python 및 Bash 스크립트를 모두 지원하지만 Windows는 Python 스크립트만 지원합니다. 스크립트는 VM의 상태를 결정해야 합니다. VM이 비정상인 것으로 확인되면 스크립트는 VM이 비정상이며 종료되어야 한다는 것을 CycleCloud에 나타내는 의 254상태 함께 종료해야 합니다.
HealthCheck를 실행하는 VM에 로그온하는 경우 jetpack keepalive 명령을 실행하여 VM이 종료되지 않도록 할 수 있습니다. Linux 인스턴스에서 시간 프레임을 지정하거나 forever Windows forever 에서 유일한 옵션인 동안에 기간을 지정할 수 있습니다.
참고
VM이 비정상으로 확인되면 HealthCheck 에이전트는 CycleCloud에 VM을 종료하도록 요청합니다. VM은 명령을 통해 shutdown 로컬로 종료되지 않습니다. VM이 CycleCloud와 통신할 수 없는 경우 CycleCloud에 도달할 수 있는 시간까지 비정상이더라도 VM은 계속 작동합니다.
예제
간단한 예제로 Linux VM이 24시간 이상 활성화되지 않도록 하는 HealthCheck 스크립트를 작성합니다. 이 스크립트를 사용하여 우선 순위가 낮은 제거를 시뮬레이션하여 워크플로가 제거된 VM에 어떻게 반응하는지 테스트할 수 있습니다. 이 스크립트는 /opt/cycle/jetpack/config/healthcheck.d/healthcheck_example.sh에 배치됩니다.
#!/bin/bash
# Get the uptime of the system (in seconds) and check to see if it is
# greater than 86,400 (24 hours in seconds). If it is, exit 254 to
# signal that the VM is unhealthy.
if (( $(cat /proc/uptime | awk '{print ($1 > 86400)}'))); then
exit 254
fi
참고
이 스크립트는 CycleCloud 프로젝트를 통해 또는 사용자 지정 이미지를 만들 때 직접 추가하여 VM에 배치할 수 있습니다.