이 문서에서는 다양한 Azure 지역에서 Azure Data Explorer 리소스, 관리 및 수집을 복제하여 Azure 지역 중단을 준비하는 방법을 자세히 설명합니다. Azure Event Hubs를 사용한 데이터 수집의 예가 제공됩니다. 다양한 아키텍처 구성에 대한 비용 최적화도 논의됩니다. 아키텍처 고려 사항 및 복구 솔루션에 대한 자세한 내용은 비즈니스 연속성 개요를 참조하세요.
데이터를 보호하기 위해 Azure 지역 중단 준비
Azure Data Explorer는 전체 Azure 지역의 중단에 대한 자동 보호를 지원하지 않습니다. 이러한 중단은 지진과 같은 자연 재해 중에 발생할 수 있습니다. 재해 복구 상황에 대한 솔루션이 필요한 경우 다음 단계를 수행하여 비즈니스 연속성을 보장합니다. 이 단계에서는 두 개의 Azure 쌍을 이루는 지역에서 클러스터, 관리 및 데이터 수집을 복제합니다.
- 2개의 Azure 쌍을 이루는 지역에서 2개 이상의 독립 클러스터를 만듭니다.
- 새 테이블 만들기 또는 각 클러스터의 사용자 역할 관리와 같은 모든 관리 작업을 복제합니다.
- 병렬로 각 클러스터에 데이터를 수집합니다.
여러 독립 클러스터 만들기
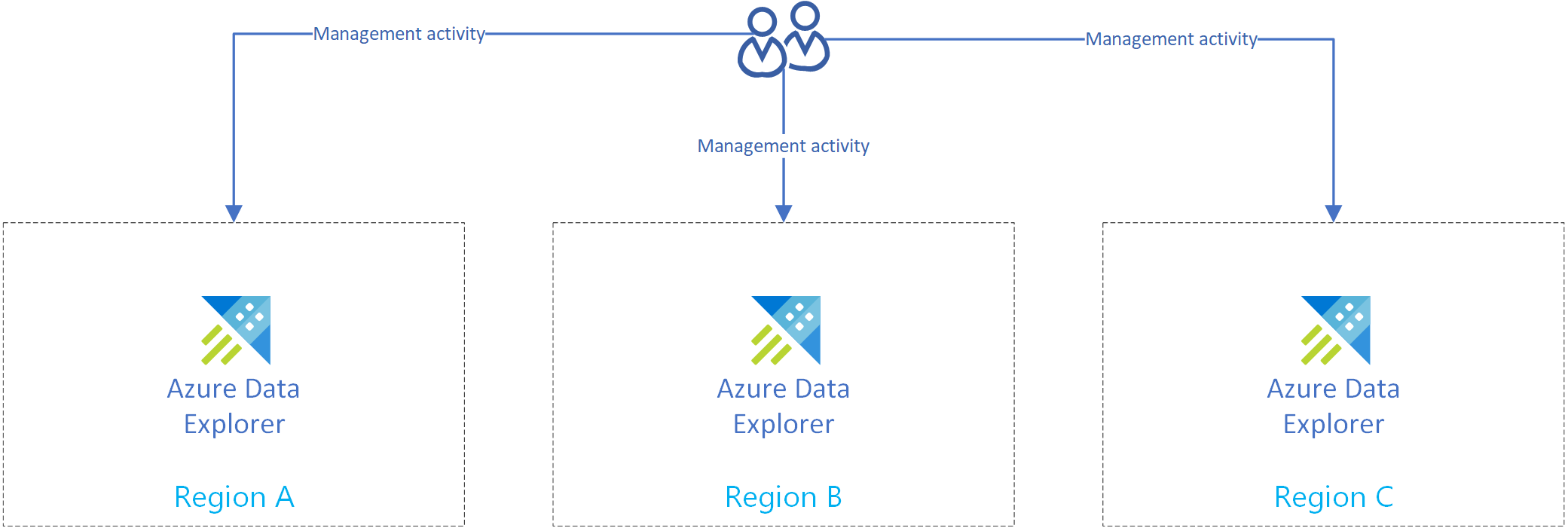
둘 이상의 지역에서 둘 이상의 Azure Data Explorer 클러스터를 만듭니다. 이러한 클러스터 중 둘 이상이 Azure 쌍을 이루는 지역에 만들어졌는지 확인합니다.
다음 이미지는 3개의 서로 다른 지역에 있는 클러스터인 복제본을 보여 줍니다.

관리 작업 복제
모든 복제본에서 동일한 클러스터 구성을 갖도록 관리 작업을 복제합니다.
각 복제본에 다음을 동일하게 만듭니다.
- 데이터베이스: Azure Portal 또는 SDK 중 하나를 사용하여 새 데이터베이스를 만들 수 있습니다.
- 테이블
- 매핑
- 정책
각 복제본의 인증 및 권한 부여를 관리합니다.
이벤트 허브 수집을 사용하는 재해 복구 솔루션
데이터를 보호하기 위해 Azure 지역 중단 준비를 완료하면 데이터와 관리가 여러 지역에 분산됩니다. 한 지역에서 중단이 발생하면 Azure Data Explorer는 다른 복제본을 사용할 수 있습니다.
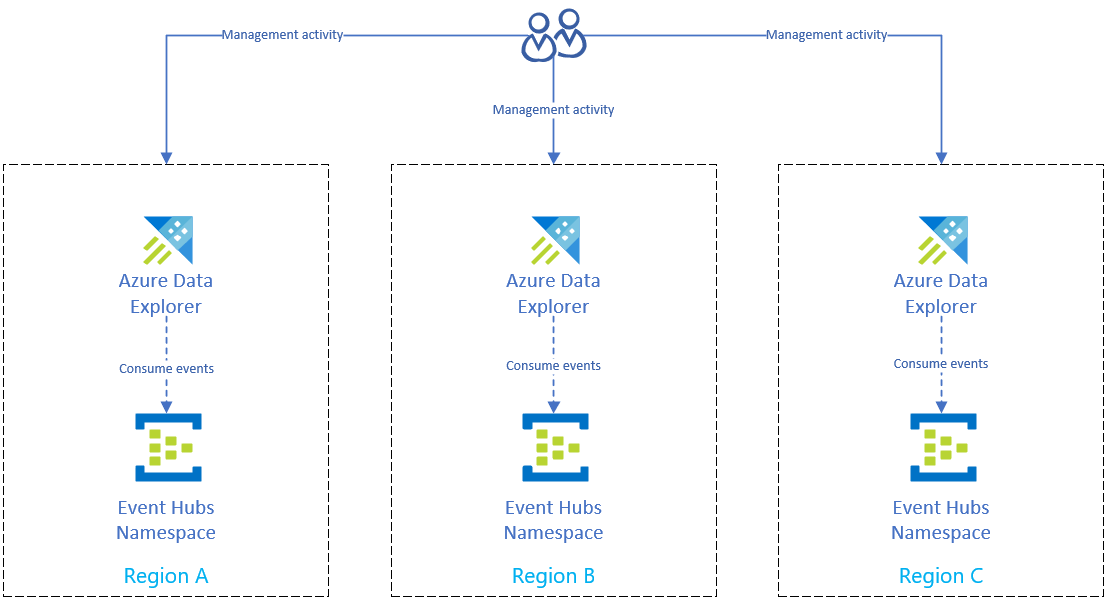
이벤트 허브를 사용하여 수집 설정
데이터를 Azure Event Hubs에서 각 지역의 Azure Data Explorer 클러스터로 수집하려면 먼저 각 지역에서 Azure Event Hubs 설정을 복제합니다. 그런 다음, 해당 Event Hubs에서 데이터를 수집하도록 각 지역의 Azure Data Explorer 복제본을 구성합니다.
참고
Azure Event Hubs/IoT Hub/스토리지를 통한 수집은 강력합니다. 일정 기간 동안 클러스터를 사용할 수 없는 경우 나중에 따라잡고 보류 중인 메시지 또는 Blob을 삽입합니다. 이 프로세스는 검사점에 의존합니다.
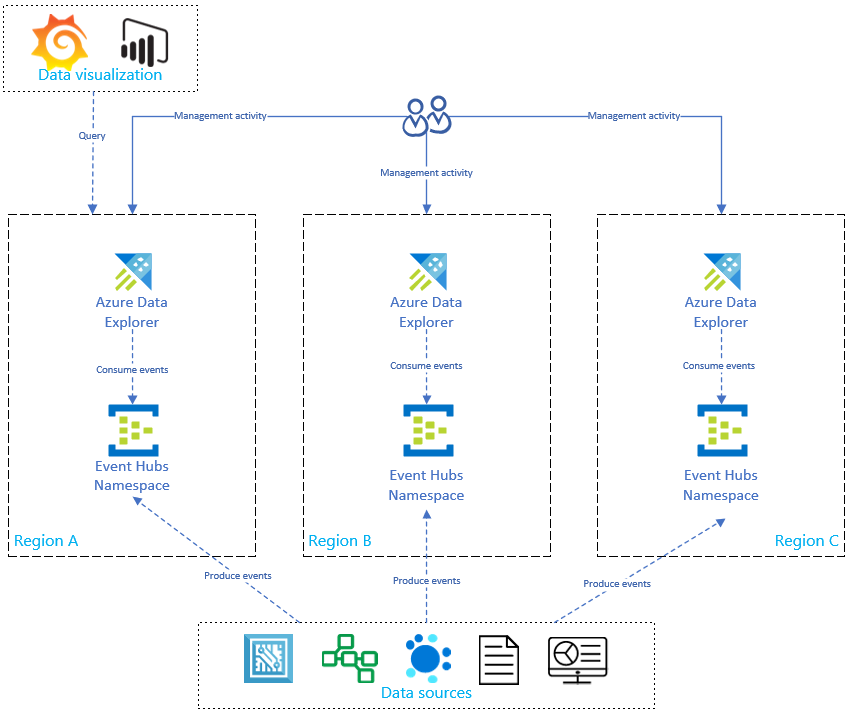
아래 다이어그램에 표시된 것처럼 데이터 원본에서 모든 지역의 이벤트 허브에 대한 이벤트를 생성하고, 각 Azure Data Explorer 복제본에서 이벤트를 사용합니다. Power BI, Grafana 또는 SDK 기반 WebApp과 같은 데이터 시각화 구성 요소는 복제본 중 하나를 쿼리할 수 있습니다.
비용 최적화
이제 다음 방법 중 일부를 사용하여 복제본을 최적화할 준비가 되었습니다.
주문형 데이터 복구 구성 만들기
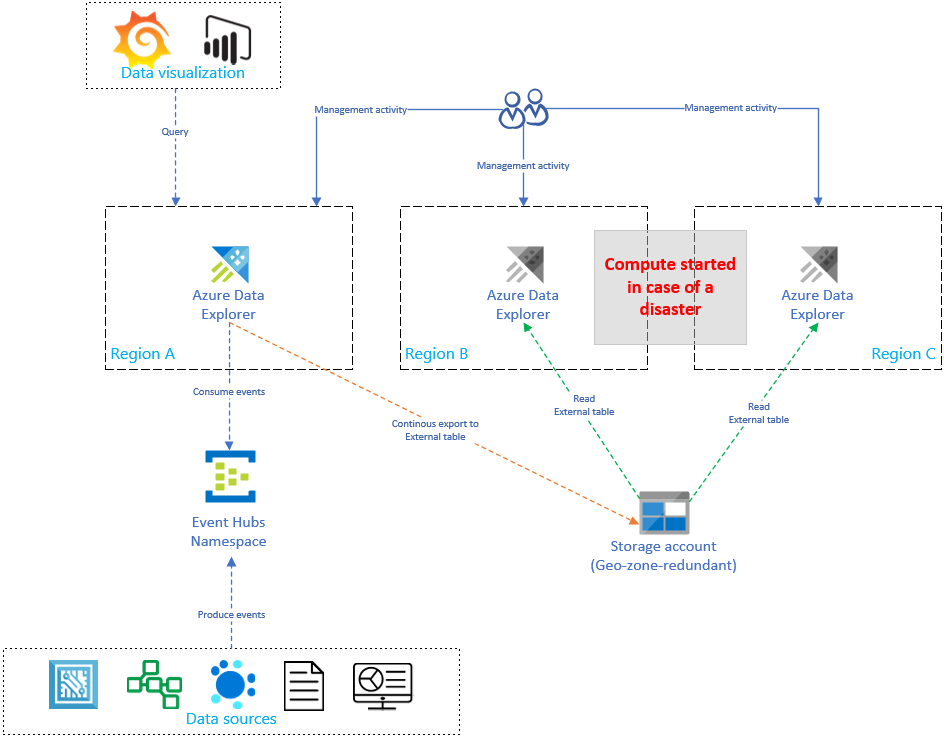
Azure Data Explorer 설정을 복제하고 업데이트하면 복제본 수에 따라 비용이 선형적으로 증가합니다. 비용을 최적화하기 위해 아키텍처 변형을 구현하여 시간, 장애 조치(failover) 및 비용의 균형을 맞출 수 있습니다. 주문형 데이터베이스 복구 구성에서 수동 Azure Data Explorer 복제본을 도입하여 비용 최적화가 구현되었습니다. 이러한 복제본은 기본 지역(예: 지역 A)에 재해가 발생한 경우에만 켜집니다. 지역 B 및 C의 복제본은 연중무휴 활성 상태일 필요가 없으므로 비용이 크게 절감됩니다. 그러나 대부분의 경우 이러한 복제본의 성능은 기본 클러스터만큼 좋지 않습니다. 자세한 정보는 주문형 데이터 복구 구성을 참조하세요.
아래 이미지에서는 하나의 클러스터만 이벤트 허브에서 데이터를 수집하고 있습니다. 지역 A의 기본 클러스터는 스토리지 계정으로 모든 데이터의 지속적으로 데이터 내보내기를 수행합니다. 보조 복제본은 외부 테이블을 사용하여 데이터에 액세스할 수 있습니다.
복제본 시작 및 중지
다음 방법 중 하나를 사용하여 보조 복제본을 시작 및 중지할 수 있습니다.
Azure Portal의 개요 탭에 있는 중지 단추. 자세한 내용은 클러스터 중지 및 다시 시작을 참조하세요.
Azure CLI:
az kusto cluster stop --name=<clusterName> --resource-group=<rgName> --subscription=<subscriptionId>"
고가용성 애플리케이션 서비스 구현
Azure App Service BCDR 클라이언트 만들기
이 섹션에서는 단일 기본 및 여러 보조 Azure Data Explorer 클러스터에 대한 연결을 지원하는 Azure App Service를 만드는 방법을 보여 줍니다. 다음 이미지는 Azure App Service 설정을 보여 줍니다.

팁
동일한 서비스의 복제본 간에 여러 연결이 있으면 가용성이 향상됩니다. 이 설정은 지역 가동이 중단된 인스턴트에만 유용한 것은 아닙니다.
이 앱 서비스에 대한 상용구 코드를 사용합니다. 다중 클러스터 클라이언트를 구현하기 위해 AdxBcdrClient 클래스가 만들어졌습니다. 이 클라이언트를 사용하여 실행되는 각 쿼리는 먼저 기본 클러스터로 전송됩니다. 오류가 발생하면 쿼리가 보조 복제본으로 전송됩니다.
사용자 지정 애플리케이션 인사이트 메트릭을 사용하여 성능을 측정하고 기본 및 보조 클러스터에 대한 배포를 요청합니다.
Azure App Service BCDR 클라이언트 테스트
여러 Azure Data Explorer 복제본을 사용하여 테스트를 실행했습니다. 기본 및 보조 클러스터의 시뮬레이션 중단 후 앱 서비스 BCDR 클라이언트가 의도한 대로 작동하는 것을 볼 수 있습니다.
Azure Data Explorer 클러스터는 서유럽(2xD14v2 기본), 동남아시아 및 미국 동부(2xD11v2)에 분산되어 있습니다.

참고
응답 시간은 SKU가 다르고 전 세계 규모의 쿼리로 인해 느려집니다.
동적 또는 정적 라우팅 수행
요청의 동적 또는 정적 라우팅에 Azure Traffic Manager 라우팅 방법을 사용합니다. Azure Traffic Manager는 앱 서비스 트래픽을 배포할 수 있는 DNS 기반 트래픽 부하 분산 장치입니다. 이 트래픽은 고가용성 및 응답성을 제공하면서 글로벌 Azure 지역의 서비스에 최적화됩니다.
Azure Front Door 기반 라우팅을 사용할 수도 있습니다. 이러한 두 방법을 비교하려면 Azure의 애플리케이션 배달 제품군을 사용한 부하 분산을 참조 하세요.
활성-활성 구성에서 비용 최적화
재해 복구에 활성-활성 구성을 사용하면 비용이 선형적으로 증가합니다. 비용에는 노드, 스토리지, 태그 및 대역폭에 대한 증가된 네트워킹 비용이 포함됩니다.
최적화된 자동 크기 조정을 사용하여 비용 최적화
최적화된 자동 크기 조정 기능을 사용하여 보조 클러스터에 대한 수평적 크기 조정을 구성합니다. 수집 부하를 처리할 수 있도록 차원을 지정해야 합니다. 기본 클러스터에 연결할 수 없으면 보조 클러스터에 더 많은 트래픽이 발생하고 구성에 따라 크기 조정됩니다.
이 예에서 최적화된 자동 크기 조정을 사용하면 모든 복제본에서 동일한 수평 및 수직 크기 조정을 사용하는 것과 비교하여 약 50%의 비용을 절약할 수 있습니다.