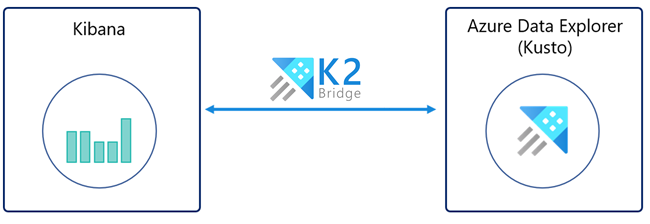
K2Bridge(Kibana-Kusto Bridge)를 사용하면 Azure Data Explorer를 데이터 원본으로 사용하고 Kibana에서 해당 데이터를 시각화할 수 있습니다. K2Bridge는 컨테이너화된 오픈 소스 애플리케이션입니다. Kibana 인스턴스와 Azure Data Explorer 클러스터 간의 프록시 역할을 합니다. 이 문서에서는 K2Bridge를 사용하여 해당 연결을 만드는 방법을 설명합니다.
K2Bridge는 Kibana 쿼리를 KQL(Kusto 쿼리 언어)로 변환하고 Azure Data Explorer 결과를 Kibana로 다시 보냅니다.
K2Bridge는 Kibana의 검색, 시각화 및 대시보드 탭을 지원합니다.
검색 탭을 사용하여 다음을 수행할 수 있습니다.
- 데이터를 검색하고 탐색합니다.
- 결과를 필터링합니다.
- 결과 그리드에서 필드를 추가하거나 제거합니다.
- 레코드 내용을 봅니다.
- 검색을 저장하고 공유합니다.
시각화 탭을 사용하여 다음을 수행할 수 있습니다.
- 가로 막대형 차트, 원형 차트, 데이터 테이블, 열 지도 등과 같은 시각화 요소를 만듭니다.
- 시각화 저장
대시보드 탭을 사용하여 다음을 수행할 수 있습니다.
- 새 시각화 또는 저장된 시각화 요소를 사용하여 패널을 만듭니다.
- 대시보드를 저장합니다.
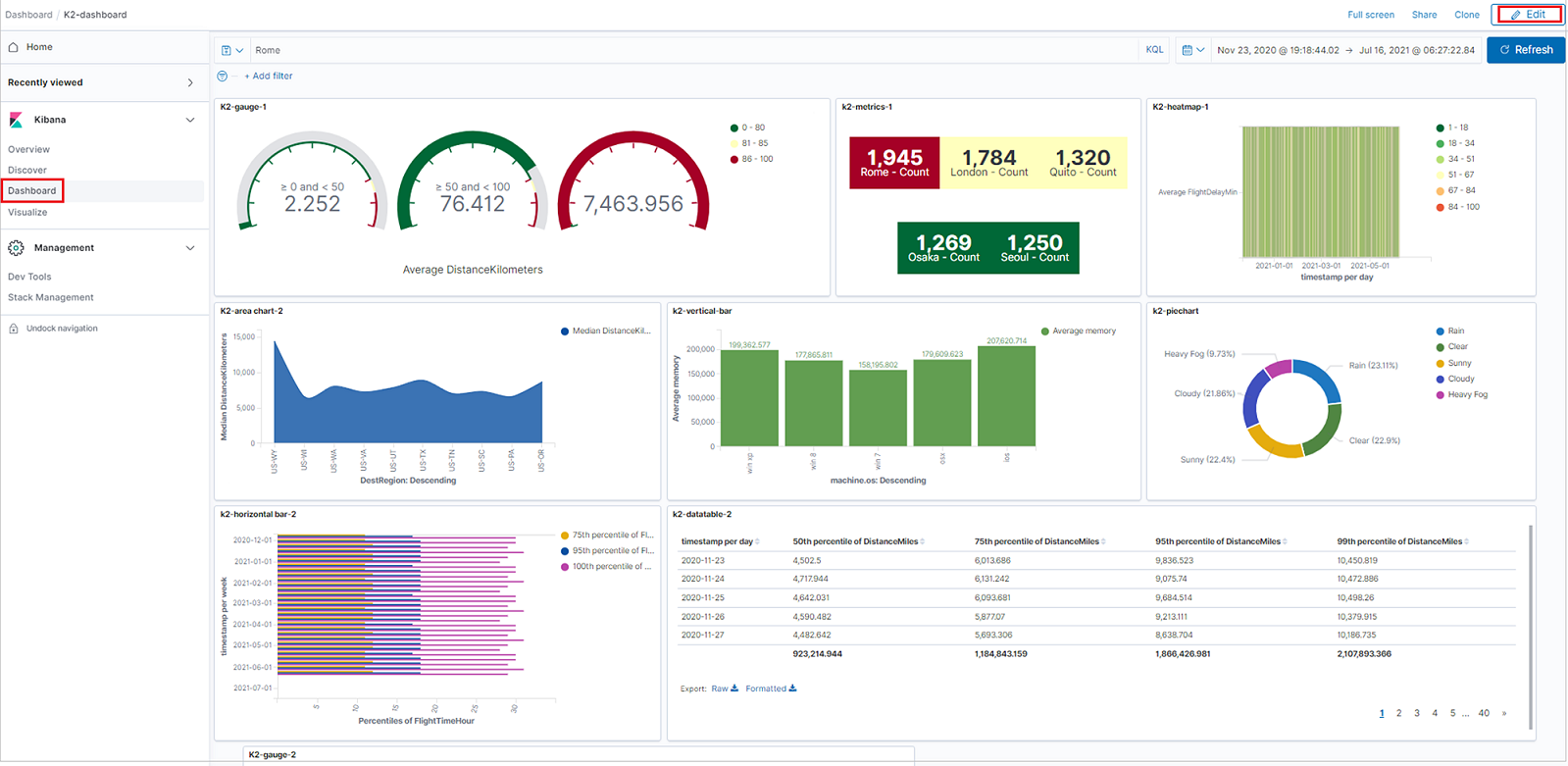
다음 이미지는 K2Bridge에 의해 Azure Data Explorer에 바인딩된 Kibana 인스턴스를 보여 줍니다. Kibana의 사용자 환경은 변경되지 않았습니다.

사전 요구 사항
Kibana의 Azure Data Explorer에서 데이터를 시각화하려면 먼저 다음을 준비합니다.
- Azure 구독 무료 Azure 계정을 만듭니다.
- Azure Data Explorer 클러스터 및 데이터베이스. 클러스터의 URL과 데이터베이스 이름이 필요합니다.
- Helm v3, Kubernetes 패키지 관리자.
- AKS(Azure Kubernetes Service) 클러스터 또는 기타 Kubernetes 클러스터. 버전 1.21.2 이상(Azure Kubernetes Service 노드 3개 이상)을 사용합니다. 버전 1.21.2는 테스트 및 확인됩니다. AKS 클러스터가 필요한 경우 Azure CLI를 사용하거나 Azure Portal을 사용하여 AKS 클러스터를 배포하는 방법을 참조하세요.
- 클라이언트 ID 및 클라이언트 암호를 포함하여 Azure Data Explorer에서 데이터를 볼 수 있는 권한이 있는 Microsoft Entra 서비스 주체입니다. 또는 시스템 할당 관리 ID를 사용할 수 있습니다.
Microsoft Entra 서비스 주체를 사용하도록 선택한 경우 Microsoft Entra 서비스 주체를 만들어야 합니다. 설치를 위해 ClientID 및 비밀이 필요합니다. 뷰어 권한이 있는 서비스 주체를 권장하고 더 높은 수준의 권한을 사용하지 않는 것이 좋습니다. 권한을 할당하려면 Azure Portal에서 데이터베이스 권한 관리를 참조하거나 관리 명령을 사용하여 데이터베이스 보안 역할을 관리합니다.
시스템 할당 ID를 사용하도록 선택하는 경우 에이전트 풀 관리 ID ClientID (생성된 "[MC_xxxx]" 리소스 그룹에 있음)를 가져와야 합니다.
AKS(Azure Kubernetes Service)에서 K2Bridge 실행
기본적으로 K2Bridge의 Helm 차트는 MCR(Microsoft Container Registry)에 있는 공개적으로 사용 가능한 이미지를 참조합니다. MCR에는 자격 증명이 필요하지 않습니다.
필요한 Helm 차트를 다운로드합니다.
Helm에 Elasticsearch 종속성을 추가합니다. K2Bridge는 작은 내부 Elasticsearch 인스턴스를 사용하기 때문에 종속성이 필요합니다. 인스턴스는 인덱스 패턴 쿼리 및 저장된 쿼리와 같은 메타데이터 관련 요청에 사용됩니다. 이 내부 인스턴스는 비즈니스 데이터를 저장하지 않습니다. 인스턴스를 구현 세부 정보로 간주할 수 있습니다.
Helm에 Elasticsearch 종속성을 추가하려면 다음 명령을 실행합니다.
helm repo add elastic https://helm.elastic.co helm repo updateGitHub 리포지토리의 차트 디렉터리에서 K2Bridge 차트를 가져오려면:
GitHub에서 리포지토리를 복제합니다.
K2Bridges 루트 리포지토리 디렉터리로 이동합니다.
다음 명령을 실행합니다.
helm dependency update charts/k2bridge
K2Bridge를 배포합니다.
변수를 환경에 맞는 올바른 값으로 설정합니다.
ADX_URL=[YOUR_ADX_CLUSTER_URL] #For example, https://mycluster.westeurope.kusto.windows.net ADX_DATABASE=[YOUR_ADX_DATABASE_NAME] ADX_CLIENT_ID=[SERVICE_PRINCIPAL_CLIENT_ID] ADX_CLIENT_SECRET=[SERVICE_PRINCIPAL_CLIENT_SECRET] ADX_TENANT_ID=[SERVICE_PRINCIPAL_TENANT_ID]참고 사항
관리 ID
ADX_CLIENT_ID를 사용하는 경우 값은 생성된[_MC_xxxx_]리소스 그룹에 있는 관리 ID의 클라이언트 ID입니다. 자세한 내용은 MC_ 리소스 그룹을 참조하세요.ADX_CLIENT_SECRET는 Microsoft Entra 서비스 주체를 사용하는 경우에만 필요합니다.선택적으로 Application Insights 원격 분석을 사용하도록 설정합니다. Application Insights를 처음 사용하는 경우 Application Insights 리소스를 만듭니다. 변수에 계측 키를 복사합니다.
APPLICATION_INSIGHTS_KEY=[INSTRUMENTATION_KEY] COLLECT_TELEMETRY=trueK2Bridge 차트를 설치합니다. 시각화 및 대시보드는 Kibana 7.10 버전에서만 지원됩니다. 최신 이미지 태그는 각각 Kibana 6.8 및 Kibana 7.10을 지원하는 6.8_latest 및 7.16_latest입니다. '7.16_latest' 이미지는 Kibana OSS 7.10.2를 지원하며 내부 Elasticsearch 인스턴스는 7.16.2입니다.
Microsoft Entra 서비스 주체를 사용한 경우:
helm install k2bridge charts/k2bridge -n k2bridge --set settings.adxClusterUrl="$ADX_URL" --set settings.adxDefaultDatabaseName="$ADX_DATABASE" --set settings.aadClientId="$ADX_CLIENT_ID" --set settings.aadClientSecret="$ADX_CLIENT_SECRET" --set settings.aadTenantId="$ADX_TENANT_ID" [--set image.tag=6.8_latest/7.16_latest] [--set image.repository=$REPOSITORY_NAME/$CONTAINER_NAME] [--set privateRegistry="$IMAGE_PULL_SECRET_NAME"] [--set settings.collectTelemetry=$COLLECT_TELEMETRY]또는 관리 ID를 사용한 경우:
helm install k2bridge charts/k2bridge -n k2bridge --set settings.adxClusterUrl="$ADX_URL" --set settings.adxDefaultDatabaseName="$ADX_DATABASE" --set settings.aadClientId="$ADX_CLIENT_ID" --set settings.useManagedIdentity=true --set settings.aadTenantId="$ADX_TENANT_ID" [--set image.tag=7.16_latest] [--set settings.collectTelemetry=$COLLECT_TELEMETRY]구성에서 전체 구성 옵션 집합을 찾을 수 있습니다.
이전 명령의 출력은 Kibana를 배포하는 다음 Helm 명령을 제안합니다. 선택적으로 다음 명령을 실행합니다.
helm install kibana elastic/kibana --version 7.17.3 -n k2bridge --set image=docker.elastic.co/kibana/kibana-oss --set imageTag=7.10.2 --set elasticsearchHosts=http://k2bridge:8080포트 전달을 사용하여 localhost에서 Kibana에 액세스합니다.
kubectl port-forward service/kibana-kibana 5601 --namespace k2bridgehttp://127.0.0.1:5601로 이동하여 Kibana에 연결합니다.
사용자에게 Kibana를 노출합니다. 여러 가지 방법이 있습니다. 사용하는 방법은 사용 사례에 따라 크게 다릅니다.
예를 들어 서비스를 부하 분산 장치 서비스로 노출할 수 있습니다. 이렇게 하려면 이전 Kibana Helm install 명령에 --set service.type=LoadBalancer 매개 변수를 추가합니다.
그런 후 다음 명령을 실행합니다.
kubectl get service -w -n k2bridge출력은 다음과 같습니다.
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kibana-kibana LoadBalancer xx.xx.xx.xx <pending> 5601:30128/TCP 4m24s그런 다음 표시되는 생성된 EXTERNAL-IP 값을 사용할 수 있습니다. 브라우저를 열고 <EXTERNAL-IP>:5601로 이동하여 Kibana에 액세스하는 데 사용합니다.
데이터에 액세스할 수 있도록 인덱스 패턴을 구성합니다.
새로운 Kibana 인스턴스에서:
- Kibana를 엽니다.
- 관리로 이동합니다.
- 인덱스 패턴을 선택합니다.
- 인덱스 패턴을 만듭니다. 인덱스 이름은 별표(*) 없이 테이블 이름 또는 함수 이름과 정확히 일치해야 합니다. 목록에서 해당 라인을 복사할 수 있습니다.
참고 사항
다른 Kubernetes 공급자에서 K2Bridge를 실행하려면 values.yaml의 Elasticsearch storageClassName 값을 공급자가 제안한 값과 일치하도록 변경합니다.
데이터 검색
Azure Data Explorer가 Kibana의 데이터 원본으로 구성된 경우 Kibana를 사용하여 데이터를 탐색할 수 있습니다.

Kibana에서 검색 탭을 선택합니다.
인덱스 패턴 목록에서 탐색할 데이터 원본을 정의하는 인덱스 패턴을 선택합니다. 여기서 인덱스 패턴은 Azure Data Explorer 테이블입니다.
데이터에 시간 필터 필드가 있는 경우 시간 범위를 지정할 수 있습니다. 검색 페이지의 오른쪽 상단에서 시간 필터를 선택합니다. 기본적으로 페이지에는 지난 15분 동안의 데이터가 표시됩니다.

결과 테이블에는 처음 500개의 레코드가 표시됩니다. 문서를 확장하여 JSON 또는 테이블 형식의 필드 데이터를 검사할 수 있습니다.
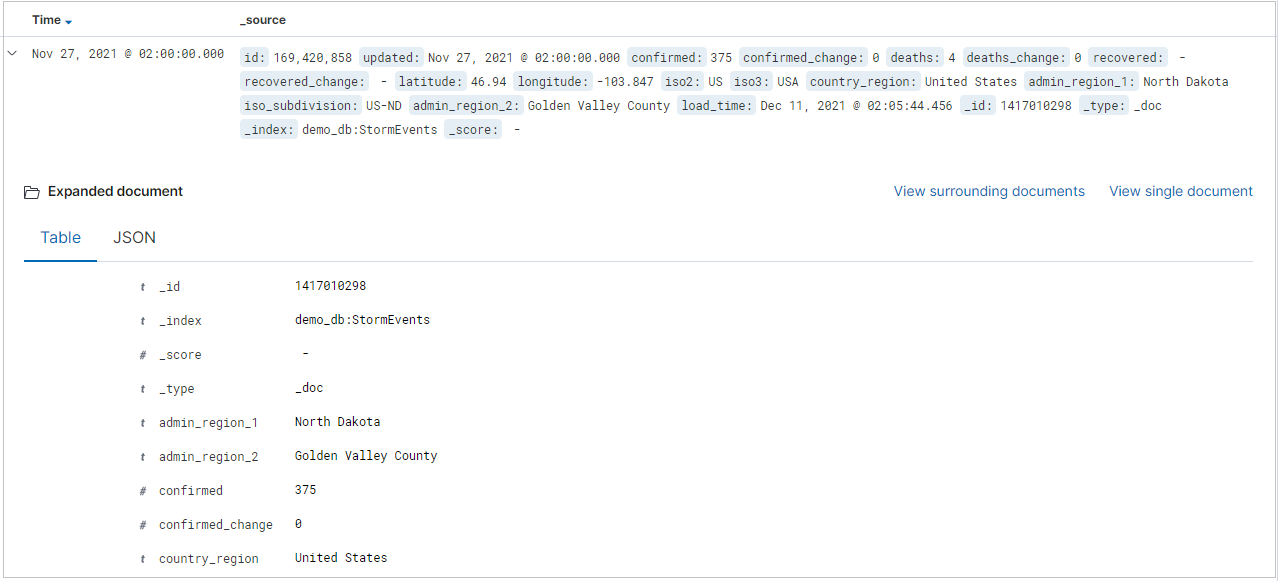
필드 이름 옆에 있는 추가를 선택하여 결과 테이블에 특정 열을 추가할 수 있습니다. 기본적으로 결과 테이블에는 _source 열과, 시간 필드가 있는 경우 시간 열이 포함됩니다.
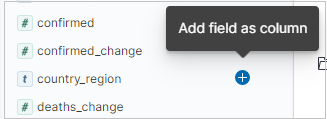
쿼리 표시줄에서 다음을 통해 데이터를 검색할 수 있습니다.
- 검색어를 입력합니다.
- Lucene 쿼리 구문 사용하기. 예:
- 이 값을 포함하는 모든 레코드를 찾으려면 "오류"를 검색합니다.
- "상태: 200"을 검색하여 상태 값이 200인 모든 레코드를 가져옵니다.
- 논리 연산자 AND, OR 및 NOT 사용.
- 별표(*) 및 물음표(?) 와일드카드 문자 사용. 예를 들어 쿼리 "destination_city: L*"은 대상 도시 값이 "L" 또는 "l"로 시작하는 레코드와 일치합니다. (K2Bridge는 대/소문자를 구분하지 않습니다.)

참고 사항
Kibana의 Lucene 쿼리 구문만 지원됩니다. Kibana Query Language(Kibana 쿼리 언어)를 의미하는 KQL 옵션을 사용하지 마세요.
팁
검색에서 더 많은 검색 규칙과 논리를 찾을 수 있습니다.
검색 결과를 필터링하려면 사용 가능한 필드 목록을 사용합니다. 필드 목록에서 다음을 볼 수 있습니다.
- 필드의 상위 5개 값입니다.
- 필드를 포함하는 레코드의 수입니다.
- 각 값을 포함하는 레코드의 백분율입니다.
팁
특정 값을 가진 모든 레코드를 찾으려면 돋보기를 사용합니다.
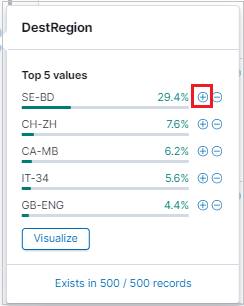
돋보기를 사용하여 결과를 필터링하고 결과 테이블의 각 레코드에 대한 결과 테이블 형식 보기를 볼 수도 있습니다.

검색을 보관하기 위해 저장 또는 공유를 선택합니다.

데이터 시각화
Kibana 시각화를 사용하여 Azure Data Explorer 데이터를 한눈에 볼 수 있습니다.
검색 탭에서 시각화 만들기
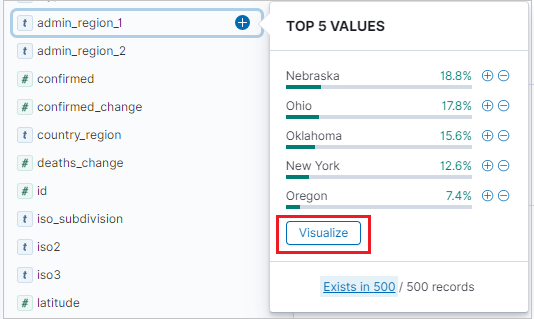
세로 막대 시각화를 만들려면 검색 탭에서 사용 가능한 필드 측면 표시줄을 찾습니다.
필드 이름을 선택한 다음, 시각화를 클릭합니다.
시각화 탭이 열리고 시각화가 표시됩니다. 시각화의 데이터 및 메트릭을 편집하려면 시각화 탭에서 시각화 만들기도 참조하세요.
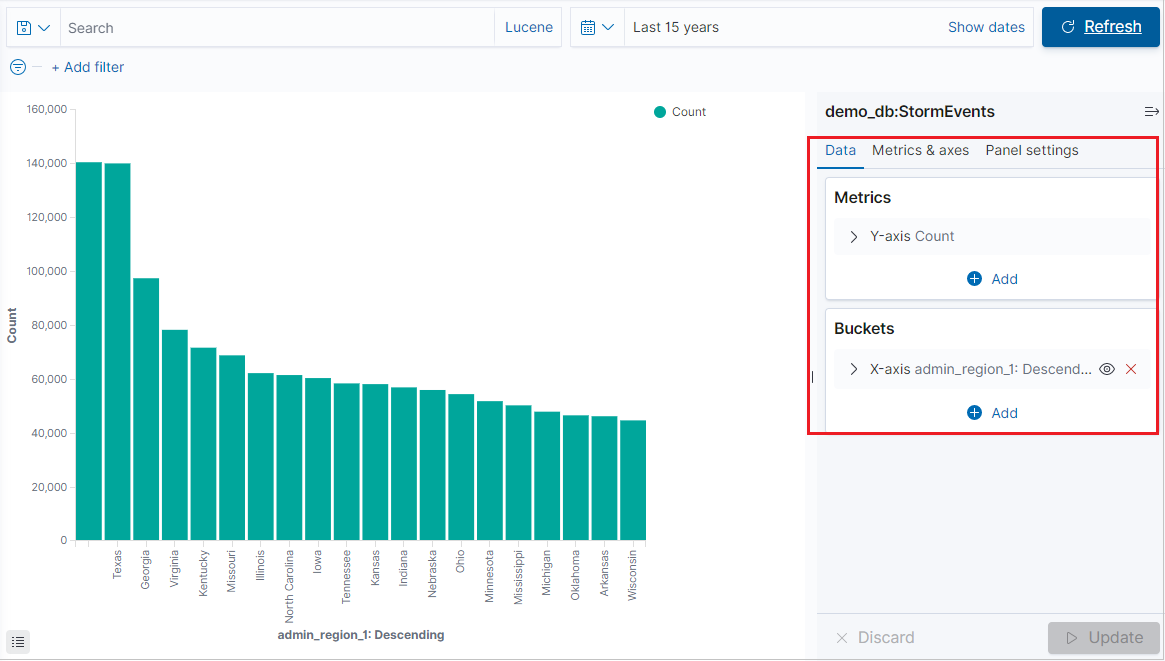
시각화 탭에서 시각화 만들기
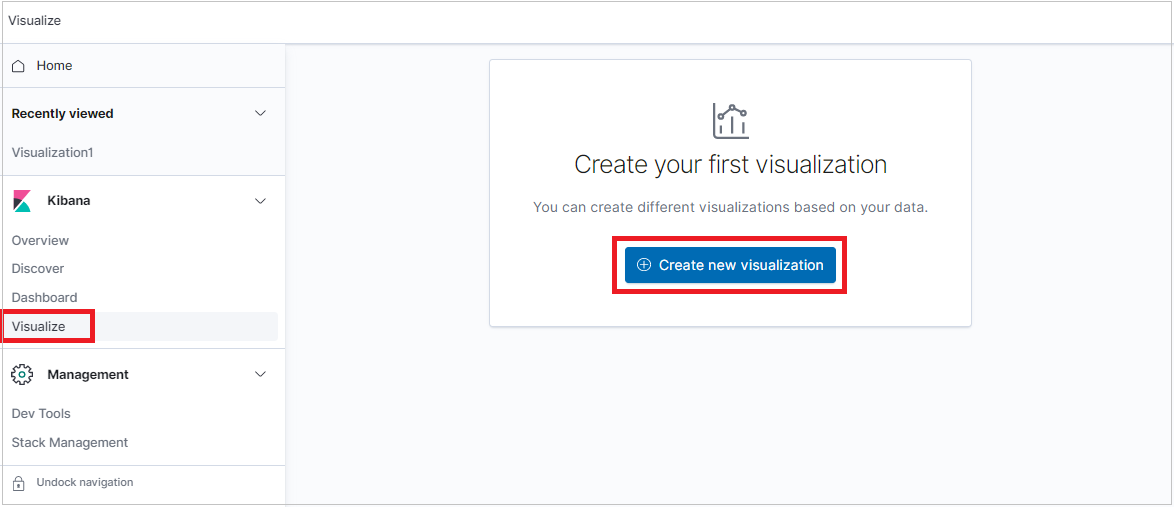
시각화 탭을 선택하고 시각화 만들기를 클릭합니다.
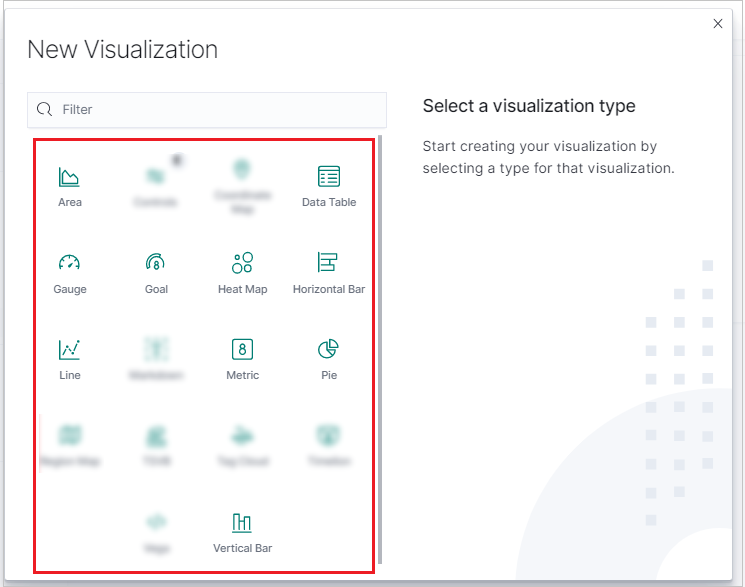
새 시각화 창에서 시각화 유형을 선택합니다.
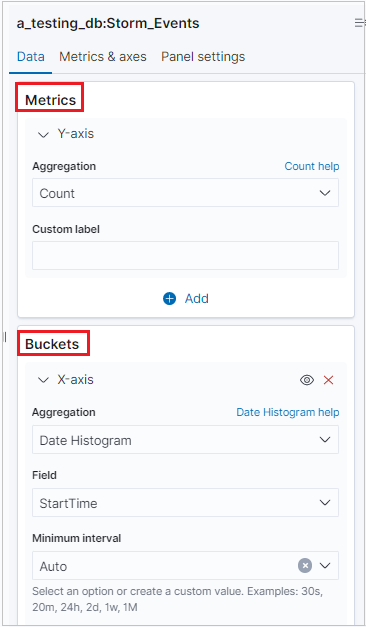
시각화가 생성되면 메트릭을 편집하고 단일 버킷에 추가할 수 있습니다.
참고 사항
K2Bridge는 단일 버킷 집계를 지원합니다. 일부 집계는 검색 옵션을 지원합니다. Kibana 쿼리 언어 구문을 나타내는 KQL 옵션이 아닌 Lucene 구문을 사용합니다.
중요
- 지원되는 시각화는
Vertical bar,Area chart,Line chart,Horizontal bar,Pie chart,Gauge,Data table,Heat map,Goal chart및Metric chart입니다. - 지원되는 메트릭은
Average,Count,Max,Median,Min,Percentiles,Standard deviation,Sum,Top hits및Unique count입니다. -
Percentiles ranks메트릭은 지원되지 않습니다. - 버킷 집계 사용은 선택 사항으로, 버킷 집계 없이도 데이터를 시각화할 수 있습니다.
- 지원되는 버킷은
No bucket aggregation,Date histogram,Filters,Range,Date range,Histogram및Terms입니다. -
IPv4 range및Significant terms버킷은 지원되지 않습니다.
대시보드 만들기
Kibana 시각화를 사용하여 대시보드를 만들어 Azure Data Explorer 데이터의 한눈에 보기 요약, 비교 및 대조를 수행할 수 있습니다.
대시보드를 만들려면 대시보드 탭을 선택한 다음, 새 대시보드 만들기를 클릭합니다.
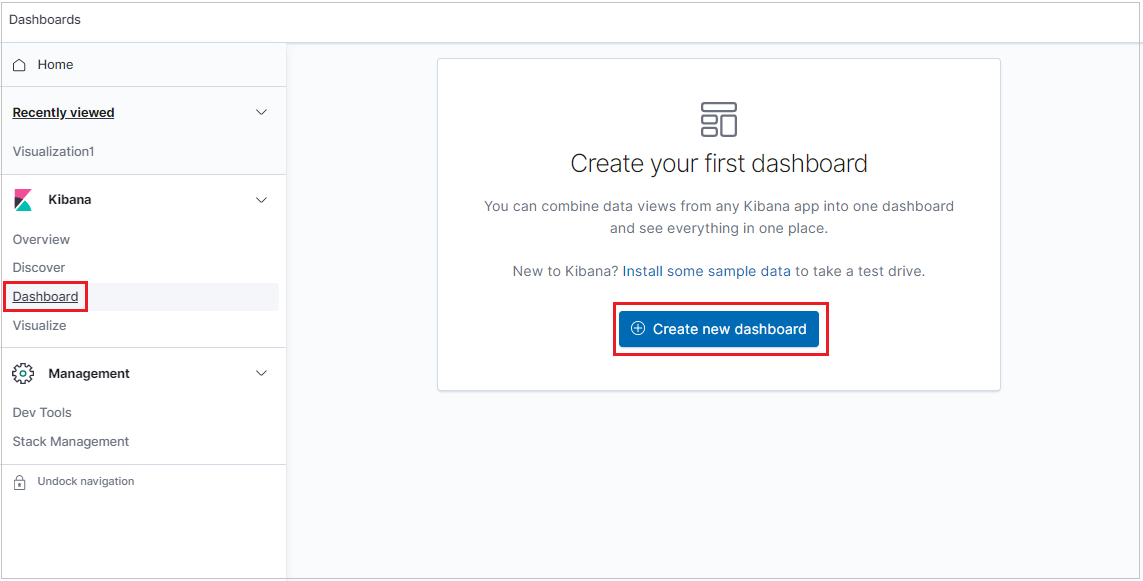
새 대시보드가 편집 모드로 열립니다.
새 시각화 패널을 추가하려면 새로 만들기를 클릭합니다.
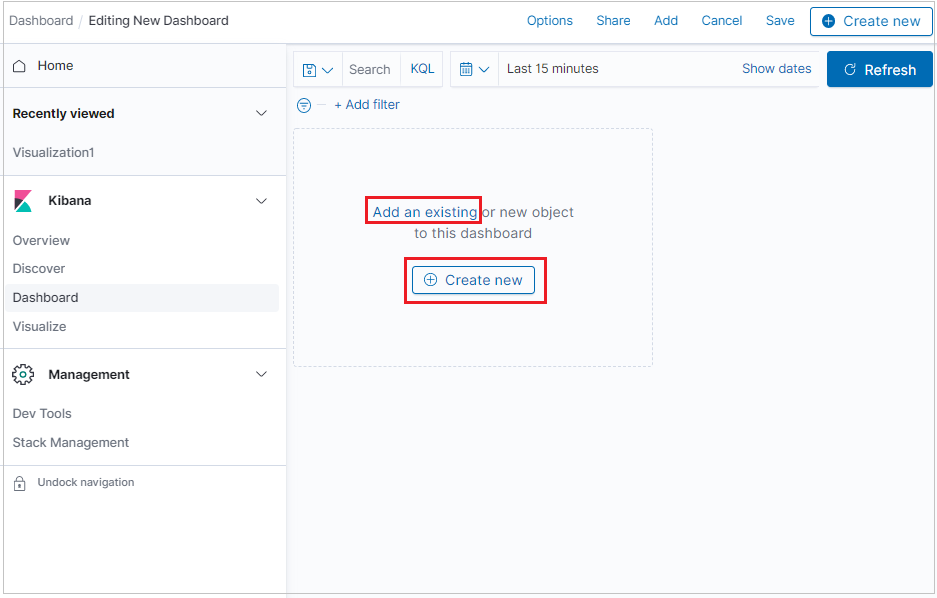
이미 만든 시각화를 추가하려면 기존 항목 추가를 클릭하고 시각화를 선택합니다.
패널을 정렬하고, 우선 순위별로 패널을 구성하고, 패널 크기를 조정하는 등의 작업을 수행하려면 편집을 클릭하고, 다음 옵션을 사용합니다.
- 패널을 이동하려면 패널 머리글을 클릭하고 누른 다음, 새 위치로 끕니다.
- 패널 크기를 조정하려면 크기 조정 컨트롤을 클릭한 다음, 새 차원으로 끕니다.