테이블 업데이트 정책을 사용하기 위한 일반적인 시나리오는 무엇인가요?
이 섹션에서는 업데이트 정책을 사용하는 몇 가지 잘 알려진 시나리오에 대해 설명합니다. 상황이 비슷한 경우 이러한 시나리오를 채택하는 것이 좋습니다.
이 문서에서는 다음과 같은 일반적인 시나리오에 대해 알아봅니다.
Medallion 아키텍처 데이터 보강
테이블의 업데이트 정책은 신속한 변환을 적용하는 효율적인 방법을 제공하며 패브릭의 medallion Lakehouse 아키텍처와 호환됩니다.
medallion 아키텍처에서 원시 데이터가 랜딩 테이블(브론즈 계층)에 배치될 때 업데이트 정책을 사용하여 초기 변환을 적용하고 보강된 출력을 실버 계층 테이블에 저장할 수 있습니다. 이 프로세스는 실버 계층 테이블의 데이터가 또 다른 업데이트 정책을 트리거하여 데이터를 추가로 구체화하고 골드 계층 테이블에 수분을 공급할 수 있는 계단식 프로세스일 수 있습니다.
다음 다이어그램에서는 Get_Values 데이터 보강 업데이트 정책의 예를 보여 줍니다. 보강된 데이터는 계산된 타임스탬프 값과 원시 데이터를 기반으로 하는 조회 값을 포함하는 실버 계층 테이블에 출력됩니다.

데이터 라우팅
데이터 보강의 특별한 경우는 원시 데이터 요소에 데이터 자체의 하나 이상의 특성을 기반으로 다른 테이블로 라우팅해야 하는 데이터가 포함되어 있는 경우에 발생합니다.
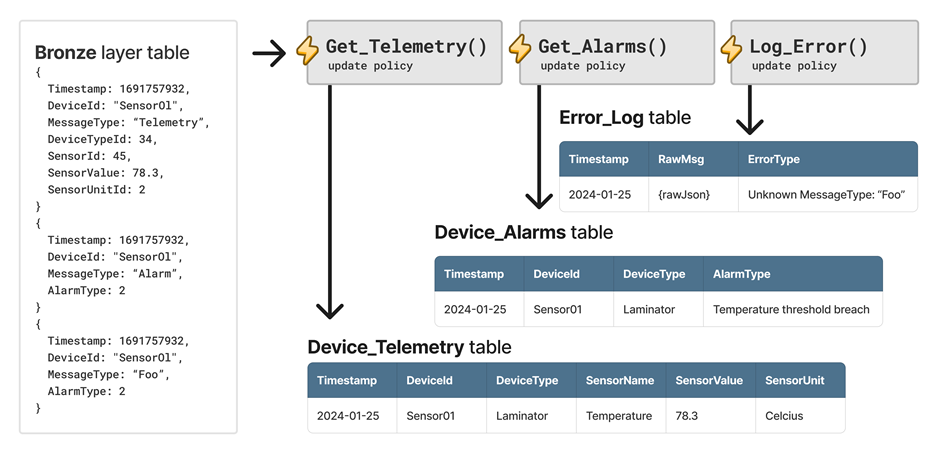
이전 시나리오와 동일한 기본 데이터를 사용하는 예제를 고려해 보십시오. 하지만 이번에는 세 개의 메시지가 있습니다. 첫 번째 메시지는 디바이스 원격 분석 메시지이고, 두 번째 메시지는 디바이스 경보 메시지이고, 세 번째 메시지는 오류입니다.
이 시나리오를 처리하기 위해 세 가지 업데이트 정책이 사용됩니다. Get_Telemetry 업데이트 정책은 디바이스 원격 분석 메시지를 필터링하고, 데이터를 보강하고, Device_Telemetry 테이블에 저장합니다. 마찬가지로 Get_Alarms 업데이트 정책은 데이터를 Device_Alarms 테이블에 저장합니다. 마지막으로 Log_Error 업데이트 정책은 알 수 없는 메시지를 Error_Log 테이블로 보내 연산자가 잘못된 형식의 메시지 또는 예기치 않은 스키마 진화를 검색할 수 있도록 합니다.
다음 다이어그램에서는 세 가지 업데이트 정책이 있는 예제를 보여 줍니다.
데이터 모델 최적화
테이블의 업데이트 정책은 속도를 위해 빌드됩니다. 테이블은 일반적으로 성능 및 유용성에 최적화된 데이터 모델 개발을 지원하는 star 스키마 디자인을 준수합니다.
star 스키마에서 테이블을 쿼리하려면 종종 테이블을 조인해야 합니다. 그러나 테이블 조인은 특히 대량의 데이터를 쿼리할 때 성능 문제가 발생할 수 있습니다. 쿼리 성능을 향상시키기 위해 수집 시 비정규화된 데이터를 저장하여 모델을 평면화할 수 있습니다.
수집 시간에 테이블을 조인하면 작은 데이터 일괄 처리에서 작동하는 이점이 추가되어 조인의 계산 비용이 줄어듭니다. 이 방법은 다운스트림 쿼리의 성능을 크게 향상시킬 수 있습니다.
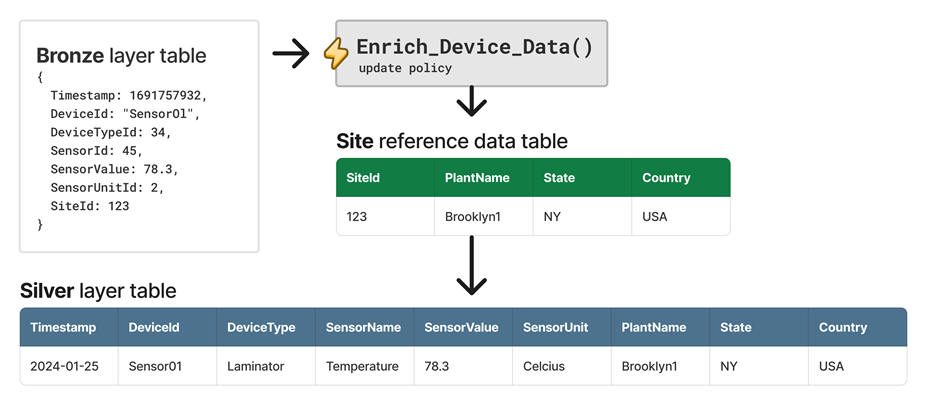
예를 들어 차원 테이블에서 값을 조회하여 디바이스에서 원시 원격 분석 데이터를 보강할 수 있습니다. 업데이트 정책은 수집 시간에 조회를 수행하고 비정규화된 테이블에 출력을 저장할 수 있습니다. 또한 참조 데이터 테이블에서 원본으로 데이터를 사용하여 출력을 확장할 수 있습니다.
다음 다이어그램에서는 Enrich_Device_Data 라는 업데이트 정책을 구성하는 예제를 보여 줍니다. 사이트 참조 데이터 테이블에서 원본으로 데이터를 사용하여 출력 데이터를 확장합니다.
관련 콘텐츠
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기