series_decompose_anomalies()
변칙 검색은 계열 분해를 기반으로 합니다. 자세한 내용은 series_decompose()를 참조하세요.
함수는 계열(동적 숫자 배열)이 포함된 식을 입력으로 사용하고 점수가 있는 비정상적인 점을 추출합니다.
Syntax
series_decompose_anomalies (시리즈, [ 임계값,계절,, 추세Test_points,AD_method,Seasonality_threshold ])
구문 규칙에 대해 자세히 알아보세요.
매개 변수
| 이름 | 형식 | 필수 | Description |
|---|---|---|---|
| 계열 | dynamic |
✔️ | 숫자 값의 배열로, 일반적으로 메이크 계열 또는 make_list 연산자의 결과 출력입니다. |
| 임계값 | real |
변칙 임계값입니다. 기본값은 경미하거나 더 강한 변칙을 검색하기 위한 1.5k 값입니다. | |
| 계절성 | int |
계절 분석을 제어합니다. 가능한 값은 다음과 같습니다. - -1: series_periods_detect 사용하여 계절성을 자동 검색합니다. 이것은 기본값입니다.- 정수 기간: 예상되는 기간(bin 수)을 지정하는 양의 정수입니다. 예를 들어 계열이 bin에 있는 1h 경우 주별 기간은 168개의 bin입니다.- 0: 계절성이 없으므로 이 구성 요소 추출을 건너뜁니다. |
|
| 추세 | string |
추세 분석을 제어합니다. 가능한 값은 다음과 같습니다. - avg: 추세 구성 요소를 로 average(x)정의합니다. 이것이 기본값입니다.- linefit: 선형 회귀를 사용하여 추세 구성 요소를 추출합니다.- none: 추세가 없으므로 이 구성 요소 추출을 건너뜁니다. |
|
| Test_points | int |
학습 또는 회귀 프로세스에서 제외할 계열의 끝에 있는 점 수를 지정하는 양의 정수입니다. 이 매개 변수는 예측 목적으로 설정해야 합니다. 기본값은 0입니다. | |
| AD_method | string |
다음 값 중 하나를 포함하는 잔차 시계열의 변칙 검색 메서드를 제어합니다. - ctukey: 사용자 지정 10번째-90번째 백분위수 범위가 있는 Tukey의 펜스 테스트 입니다. 이것이 기본값입니다.- tukey: 표준 25번째-75번째 백분위수 범위를 사용하는 Tukey의 펜스 테스트 입니다.잔차 시계열에 대한 자세한 내용은 series_outliers 참조하세요. |
|
| Seasonality_threshold | real |
계절성이 자동 검색으로 설정된 경우 계절성 점수에 대한 임계값입니다. 기본 점수 임계값은 0.6입니다. 자세한 내용은 series_periods_detect. |
반환
함수는 다음 각 계열을 반환합니다.
ad_flag: 각각 위쪽/아래쪽/변칙 없음을 표시하는 (+1, -1, 0)을 포함하는 3항 계열ad_score: 변칙 점수baseline: 분해에 따른 계열의 예측 값입니다.
알고리즘
이 함수는 다음 단계를 따릅니다.
- 각 매개 변수를 사용하여 series_decompose() 를 호출하여 기준선 및 잔차 계열을 만듭니다.
- 잔차 계열에서 선택한 변칙 검색 방법으로 series_outliers() 를 적용하여 ad_score 계열을 계산합니다.
- ad_score 임계값을 적용하여 ad_flag 계열을 계산하여 각각 변칙을 표시/축소/표시하지 않습니다.
예제
주간 계절성에서 변칙 검색
다음 예제에서는 주별 계절성을 사용하여 계열을 생성한 다음 이 계열에 몇 가지 이상값을 추가합니다. series_decompose_anomalies 계절성을 자동으로 검색하고 반복 패턴을 캡처하는 기준을 생성합니다. 추가한 이상값은 ad_score 구성 요소에서 명확하게 확인할 수 있습니다.
let ts=range t from 1 to 24*7*5 step 1
| extend Timestamp = datetime(2018-03-01 05:00) + 1h * t
| extend y = 2*rand() + iff((t/24)%7>=5, 10.0, 15.0) - (((t%24)/10)*((t%24)/10)) // generate a series with weekly seasonality
| extend y=iff(t==150 or t==200 or t==780, y-8.0, y) // add some dip outliers
| extend y=iff(t==300 or t==400 or t==600, y+8.0, y) // add some spike outliers
| summarize Timestamp=make_list(Timestamp, 10000),y=make_list(y, 10000);
ts
| extend series_decompose_anomalies(y)
| render timechart
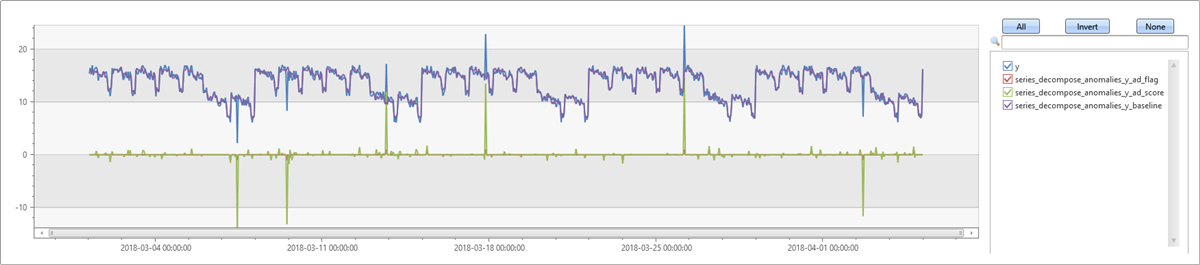
추세를 사용하여 주간 계절성에서 변칙 검색
이 예제에서는 이전 예제의 계열에 추세를 추가합니다. 먼저 추세 기본값이 평균만 사용하고 추세를 avg 계산하지 않는 기본 매개 변수를 사용하여 를 실행 series_decompose_anomalies 합니다. 생성된 기준은 추세를 포함하지 않으며 이전 예제에 비해 정확도가 낮습니다. 따라서 데이터에 삽입한 일부 이상값은 높은 분산으로 인해 검색되지 않습니다.
let ts=range t from 1 to 24*7*5 step 1
| extend Timestamp = datetime(2018-03-01 05:00) + 1h * t
| extend y = 2*rand() + iff((t/24)%7>=5, 5.0, 15.0) - (((t%24)/10)*((t%24)/10)) + t/72.0 // generate a series with weekly seasonality and ongoing trend
| extend y=iff(t==150 or t==200 or t==780, y-8.0, y) // add some dip outliers
| extend y=iff(t==300 or t==400 or t==600, y+8.0, y) // add some spike outliers
| summarize Timestamp=make_list(Timestamp, 10000),y=make_list(y, 10000);
ts
| extend series_decompose_anomalies(y)
| extend series_decompose_anomalies_y_ad_flag =
series_multiply(10, series_decompose_anomalies_y_ad_flag) // multiply by 10 for visualization purposes
| render timechart
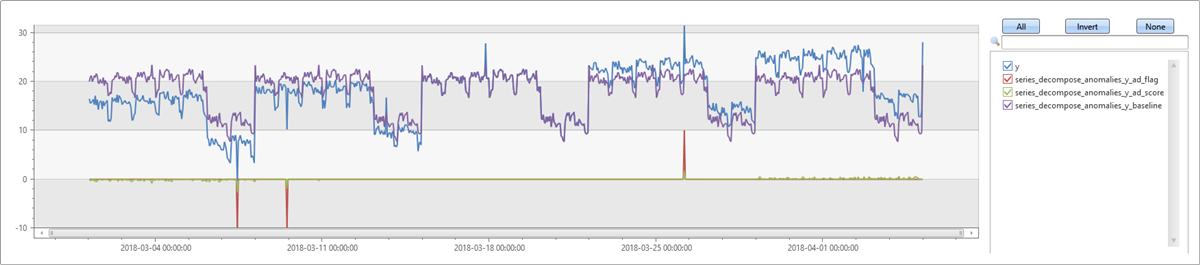
다음으로 동일한 예제를 실행하지만 계열에서 추세가 예상되므로 추세 매개 변수에 를 지정합니다 linefit . 기준이 입력 계열에 훨씬 더 가깝다는 것을 알 수 있습니다. 삽입된 모든 이상값이 검색되고 일부 가양성도 검색됩니다. 임계값 조정에 대한 다음 예제를 참조하세요.
let ts=range t from 1 to 24*7*5 step 1
| extend Timestamp = datetime(2018-03-01 05:00) + 1h * t
| extend y = 2*rand() + iff((t/24)%7>=5, 5.0, 15.0) - (((t%24)/10)*((t%24)/10)) + t/72.0 // generate a series with weekly seasonality and ongoing trend
| extend y=iff(t==150 or t==200 or t==780, y-8.0, y) // add some dip outliers
| extend y=iff(t==300 or t==400 or t==600, y+8.0, y) // add some spike outliers
| summarize Timestamp=make_list(Timestamp, 10000),y=make_list(y, 10000);
ts
| extend series_decompose_anomalies(y, 1.5, -1, 'linefit')
| extend series_decompose_anomalies_y_ad_flag =
series_multiply(10, series_decompose_anomalies_y_ad_flag) // multiply by 10 for visualization purposes
| render timechart
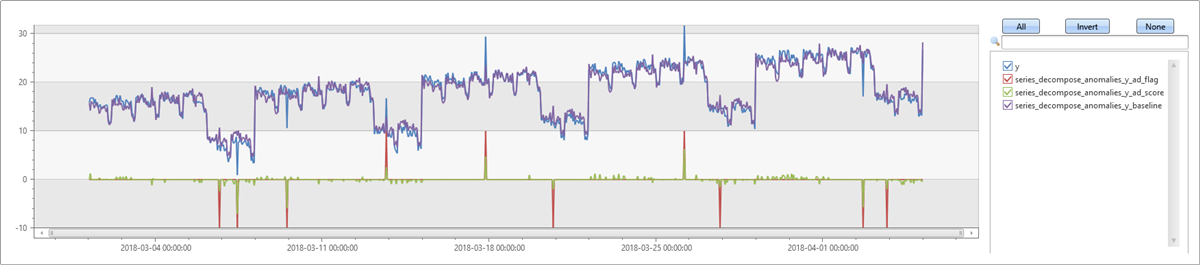
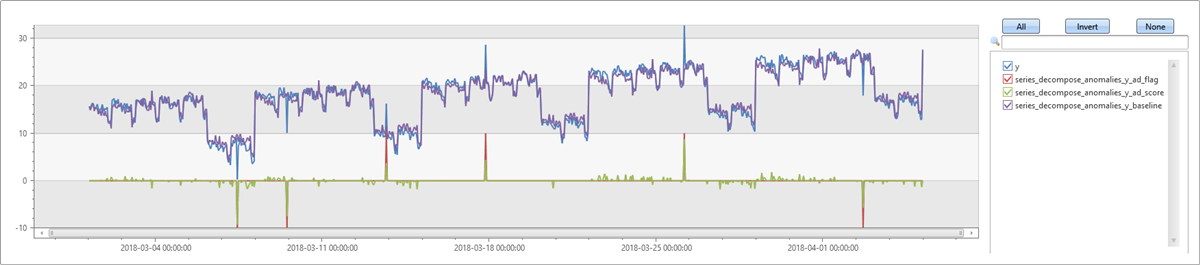
변칙 검색 임계값 조정
이전 예제에서 몇 가지 시끄러운 지점이 변칙으로 검색되었습니다. 이제 변칙 검색 임계값을 기본값인 1.5에서 2.5로 늘입니다. 더 강력한 변칙만 검색되도록 이 중심 간 범위를 사용합니다. 이제 데이터에 삽입한 이상값만 검색됩니다.
let ts=range t from 1 to 24*7*5 step 1
| extend Timestamp = datetime(2018-03-01 05:00) + 1h * t
| extend y = 2*rand() + iff((t/24)%7>=5, 5.0, 15.0) - (((t%24)/10)*((t%24)/10)) + t/72.0 // generate a series with weekly seasonality and onlgoing trend
| extend y=iff(t==150 or t==200 or t==780, y-8.0, y) // add some dip outliers
| extend y=iff(t==300 or t==400 or t==600, y+8.0, y) // add some spike outliers
| summarize Timestamp=make_list(Timestamp, 10000),y=make_list(y, 10000);
ts
| extend series_decompose_anomalies(y, 2.5, -1, 'linefit')
| extend series_decompose_anomalies_y_ad_flag =
series_multiply(10, series_decompose_anomalies_y_ad_flag) // multiply by 10 for visualization purposes
| render timechart
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기