series_fit_2lines_dynamic()
계열에 두 세그먼트 선형 회귀를 적용하여 동적 개체를 반환합니다.
동적 숫자 배열이 포함된 식을 입력으로 사용하고 계열의 추세 변화를 식별하고 정량화하기 위해 두 세그먼트 선형 회귀 를 적용합니다. 함수는 계열 인덱스를 반복합니다. 각 반복에서 계열을 두 부분으로 분할하고 series_fit_line() 또는 series_fit_line_dynamic( )를 사용하여 별도의 줄 에 맞습니다. 함수는 두 부분 각각에 선을 맞고 총 R 제곱 값을 계산합니다. 가장 좋은 분할은 R 제곱을 최대화하는 분할입니다. 함수는 다음 콘텐츠와 함께 해당 매개 변수를 동적 값으로 반환합니다.
rsquare: R 제곱 은 적합 품질의 표준 측정값입니다. [0-1] 범위의 숫자입니다. 여기서 1은 가장 적합하며 0은 데이터의 순서가 지정되지 않고 줄에 맞지 않음을 의미합니다.split_idx: 두 세그먼트에 대한 중단점의 인덱스입니다(0부터 시작).variance: 입력 데이터의 분산입니다.rvariance: 입력 데이터 값 사이의 분산인 잔차 분산입니다(두 줄 세그먼트별).line_fit: 가장 적합한 선의 일련의 값을 포함하는 숫자 배열입니다. 계열 길이는 입력 배열의 길이와 같습니다. 차트에 사용됩니다.right.rsquare: 분할의 오른쪽에 있는 줄의 r-square입니다. series_fit_line() 또는 series_fit_line_dynamic()를 참조하세요.right.slope: 오른쪽 근사 선의 기울기입니다(y=ax+b 형식).right.interception: 대략적인 왼쪽 줄의 가로채기(y=ax+b에서 b).right.variance: 분할의 오른쪽에 있는 입력 데이터의 분산입니다.right.rvariance: 분할의 오른쪽에 있는 입력 데이터의 잔차 분산입니다.left.rsquare: 분할 왼쪽에 있는 선의 r-square입니다. [series_fit_line()]를 참조하세요. (series-fit-line-function.md) 또는 series_fit_line_dynamic().left.slope: 왼쪽 근사 선의 기울기입니다(y=ax+b 형식).left.interception: 대략적인 왼쪽 줄(y=ax+b 형식)의 가로채기입니다.left.variance: 분할의 왼쪽에 있는 입력 데이터의 분산입니다.left.rvariance: 분할의 왼쪽에 있는 입력 데이터의 잔차 분산입니다.
이 연산자는 series_fit_2lines 비슷합니다. 는 달리 series-fit-2lines동적 모음을 반환합니다.
Syntax
series_fit_2lines_dynamic(시리즈)
구문 규칙에 대해 자세히 알아보세요.
매개 변수
| 이름 | 형식 | 필수 | Description |
|---|---|---|---|
| 시리즈 | dynamic |
✔️ | 숫자 값의 배열입니다. |
팁
이 함수를 사용하는 가장 편리한 방법은 make-series 연산자의 결과에 적용하는 것입니다.
예제
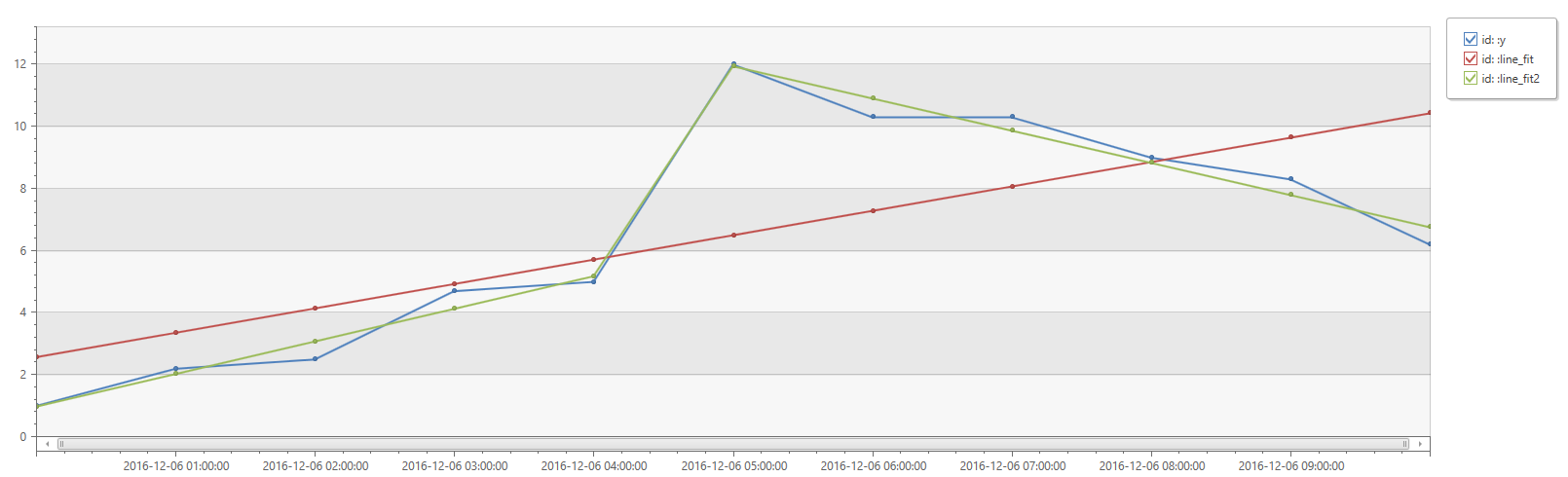
print
id=' ',
x=range(bin(now(), 1h) - 11h, bin(now(), 1h), 1h),
y=dynamic([1, 2.2, 2.5, 4.7, 5.0, 12, 10.3, 10.3, 9, 8.3, 6.2])
| extend
LineFit=series_fit_line_dynamic(y).line_fit,
LineFit2=series_fit_2lines_dynamic(y).line_fit
| project id, x, y, LineFit, LineFit2
| render timechart
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기