summarize 연산자
입력된 테이블의 내용을 집계하는 테이블을 생성합니다.
구문
T | summarize [ SummarizeParameters ] [[Column =] Aggregation [, ...]] [by [Column =] GroupExpression [, ...]]
구문 규칙에 대해 자세히 알아봅니다.
매개 변수
| 이름 | Type | 필수 | 설명 |
|---|---|---|---|
| 열 | string |
결과 열의 이름입니다. 기본적으로 식에서 파생된 이름입니다. | |
| 집계 | string |
✔️ | count() 또는 avg()와 같은 집계 함수에 대한 호출이며, 열 이름을 인수로 사용합니다. |
| GroupExpression | scalar | ✔️ | 입력 데이터를 참조할 수 있는 스칼라 식입니다. 출력에는 모든 그룹 식에 대한 고유 값만큼 많은 레코드가 포함됩니다. |
| SummarizeParameters | string |
동작을 제어하는 이름 = 값 형식의 공백으로 구분된 매개 변수가 0개 이상입니다. 지원되는 매개 변수를 참조하세요. |
참고 항목
입력 테이블이 비어 있으면 출력이 GroupExpression을 사용하는지 여부에 따라 달라집니다.
- GroupExpression이 제공되지 않으면 출력은 단일(빈) 행이 됩니다.
- GroupExpression이 제공되면 출력에 행이 없습니다.
지원되는 매개 변수
반품
입력 행은 식 값 by 이 동일한 그룹으로 정렬됩니다. 그런 다음, 지정된 집계 함수가 각 그룹에 대해 계산되어 각 그룹에 대해 행을 생성합니다. 결과에는 각 계산된 집계에 by 대해 하나 이상의 열과 열이 포함됩니다. (일부 집계 함수는 여러 열을 반환합니다.)
결과에는 값의 고유한 조합(0일 수 있음)이 있는 만큼의 by 행이 있습니다. 그룹 키가 제공되지 않으면 결과에 단일 레코드가 있습니다.
숫자 값 bin() 의 범위에 대해 요약하려면 범위를 줄여 불연속 값으로 줄입니다.
참고 항목
- 집계 및 그룹화 식 모두에 대해 임의의 식을 제공할 수 있지만 단순 열 이름을 사용하거나 숫자 열에 적용
bin()하는 것이 더 효율적입니다. - datetime 열에 대한 자동 시간별 bin은 더 이상 지원되지 않습니다. 대신 명시적 범주화를 사용합니다. 예들 들어
summarize by bin(timestamp, 1h)입니다.
집계의 기본값
다음 표에는 집계의 기본값이 요약되어 있습니다.
| 연산자 | Default value |
|---|---|
count(), countif(), dcount(), dcountif(), count_distinct(), sum(), sumif(), variance()varianceif(), stdev()stdevif() |
0 |
make_bag(), make_bag_if(), make_list(), make_list_if(), make_set()make_set_if() |
빈 동적 배열([]) |
| 나머지 | null |
참고 항목
null 값을 포함하는 엔터티에 이러한 집계를 적용하는 경우 null 값은 무시되며 계산에 포함되지 않습니다. 예제는 집계 기본값을 참조 하세요.
예제
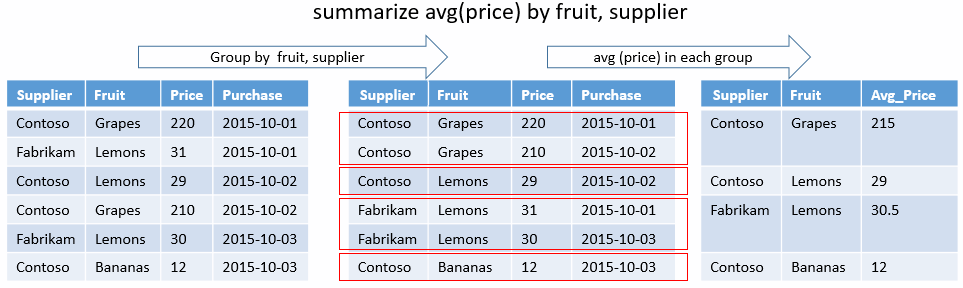
고유한 조합
다음 쿼리는 직접적인 부상을 초래한 폭풍의 State 고유한 조합과 EventType 그 조합을 결정합니다. 집계 함수는 없으며 그룹별 키만 있습니다. 출력은 해당 결과에 대한 열만 표시합니다.
StormEvents
| where InjuriesDirect > 0
| summarize by State, EventType
출력
다음 표에서는 처음 5개 행만 보여 줍니다. 전체 출력을 보려면 쿼리를 실행합니다.
| State(상태) | EventType |
|---|---|
| TEXAS | 뇌우를 동반한 바람 |
| TEXAS | Flash Flood |
| TEXAS | 겨울 날씨 |
| TEXAS | 강풍 |
| TEXAS | 홍수 |
| ... | ... |
최소 및 최대 타임스탬프
하와이에서 최소 및 최대 폭우 폭풍을 찾습니다. group-by 절이 없으므로 출력에 행이 하나만 있습니다.
StormEvents
| where State == "HAWAII" and EventType == "Heavy Rain"
| project Duration = EndTime - StartTime
| summarize Min = min(Duration), Max = max(Duration)
출력
| Min | Max |
|---|---|
| 01:08:00 | 11:55:00 |
고유 개수
활동이 발생하는 도시 수를 보여 주는 각 대륙에 대한 행을 만듭니다. "대륙"에 대한 값이 거의 없으므로 'by' 절에는 그룹화 함수가 필요하지 않습니다.
StormEvents
| summarize TypesOfStorms=dcount(EventType) by State
| sort by TypesOfStorms
출력
다음 표에서는 처음 5개 행만 보여 줍니다. 전체 출력을 보려면 쿼리를 실행합니다.
| State(상태) | TypesOfStorms |
|---|---|
| TEXAS | 27 |
| 캘리포니아 | 26 |
| PENNSYLVANIA | 25 |
| 그루지야 | 24 |
| 일리노이주 | 23 |
| ... | ... |
히스토그램
다음 예제에서는 폭풍이 1일 이상 지속된 히스토그램 폭풍 이벤트 유형을 계산합니다. Duration 값이 많으므로 해당 값을 bin() 1일 간격으로 그룹화합니다.
StormEvents
| project EventType, Duration = EndTime - StartTime
| where Duration > 1d
| summarize EventCount=count() by EventType, Length=bin(Duration, 1d)
| sort by Length
출력
| EventType | Length | EventCount |
|---|---|---|
| 가뭄 | 30.00:00:00 | 1646 |
| Wildfire | 30.00:00:00 | 11 |
| 열 | 30.00:00:00 | 14 |
| 홍수 | 30.00:00:00 | 20 |
| Heavy Rain | 29.00:00:00 | 42 |
| ... | ... | ... |
기본값 집계
연산자의 summarize 입력에 하나 이상의 빈 그룹별 키가 있는 경우 그 결과도 비어 있습니다.
연산자의 summarize 입력에 빈 그룹별 키가 없는 경우 결과는 자세한 내용은 집계의 summarize 기본값을 참조하세요.
datatable(x:long)[]
| summarize any_x=take_any(x), arg_max_x=arg_max(x, *), arg_min_x=arg_min(x, *), avg(x), buildschema(todynamic(tostring(x))), max(x), min(x), percentile(x, 55), hll(x) ,stdev(x), sum(x), sumif(x, x > 0), tdigest(x), variance(x)
출력
| any_x | arg_max_x | arg_min_x | avg_x | schema_x | max_x | min_x | percentile_x_55 | hll_x | stdev_x | sum_x | sumif_x | tdigest_x | variance_x |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NaN | 0 | 0 | 0 | 0 |
결과는 avg_x(x) 0으로 나누기 때문입니다 NaN .
datatable(x:long)[]
| summarize count(x), countif(x > 0) , dcount(x), dcountif(x, x > 0)
출력
| count_x | countif_ | dcount_x | dcountif_x |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
datatable(x:long)[]
| summarize make_set(x), make_list(x)
출력
| set_x | list_x |
|---|---|
| [] | [] |
집계 평균은 null이 아닌 모든 값을 합산하고 계산에 참여한 값만 계산합니다(null을 고려하지 않음).
range x from 1 to 4 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize sum(y), avg(y)
출력
| sum_y | avg_y |
|---|---|
| 15 | 5 |
일반 개수는 null을 계산합니다.
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize count(y)
출력
| count_y |
|---|
| 2 |
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize make_set(y), make_set(y)
출력
| set_y | set_y1 |
|---|---|
| [5.0] | [5.0] |
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기