적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
Microsoft Fabric의 데이터 팩토리는 더 간단한 아키텍처, 기본 제공 AI 및 새로운 기능을 갖춘 차세대 Azure 데이터 팩토리입니다. 데이터 통합을 접하는 경우 Fabric Data Factory부터 시작합니다. 기존 ADF 워크로드는 Fabric 업그레이드하여 데이터 과학, 실시간 분석 및 보고 전반에 걸쳐 새로운 기능에 액세스할 수 있습니다.
- Fabric 무료 평가판을 시작합니다.
Microsoft Fabric의 Data Factory로 Azure Data Factory를 업그레이드합니다
데이터 흐름은 Azure Data Factory 파이프라인과 Azure Synapse Analytics 파이프라인 모두에서 사용할 수 있습니다. 이 문서는 매핑 데이터 흐름에 적용됩니다. 변환을 접하는 경우 매핑 데이터 흐름을 사용하여 데이터 변환 소개 문서를 참조하세요.
팁
Dataflow Gen2에서 동일한 변환(그룹화 기준)에 대한 내용은 데이터 흐름 사용자를 위한 Dataflow Gen2 가이드를 참조하세요.
집계 변환에서는 데이터 스트림의 열 집계를 정의합니다. 식 작성기를 사용하여 SUM, MIN, MAX, COUNT 같은 다양한 유형의 집계를 기존 열 또는 계산 열로 그룹화하여 정의할 수 있습니다.
그룹 기준
집계에서 group by 절로 사용할 새 계산 열을 만들거나 기존 열을 선택합니다. 기존 열을 사용하려면 드롭다운에서 선택합니다. 새 계산 열을 만들려면 절을 마우스로 가리키고 계산 열을 클릭합니다. 데이터 흐름 식 작성기가 열립니다. 계산 열을 만든 후에는 다음으로 이름 지정 필드에 출력 열 이름을 입력합니다. group by 절을 더 추가하려는 경우 기존 절을 마우스로 가리키고 더하기 아이콘을 클릭합니다.
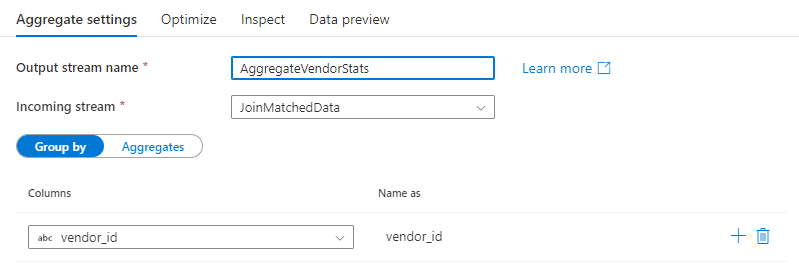
집계 변환에서 group by 절은 선택 사항입니다.
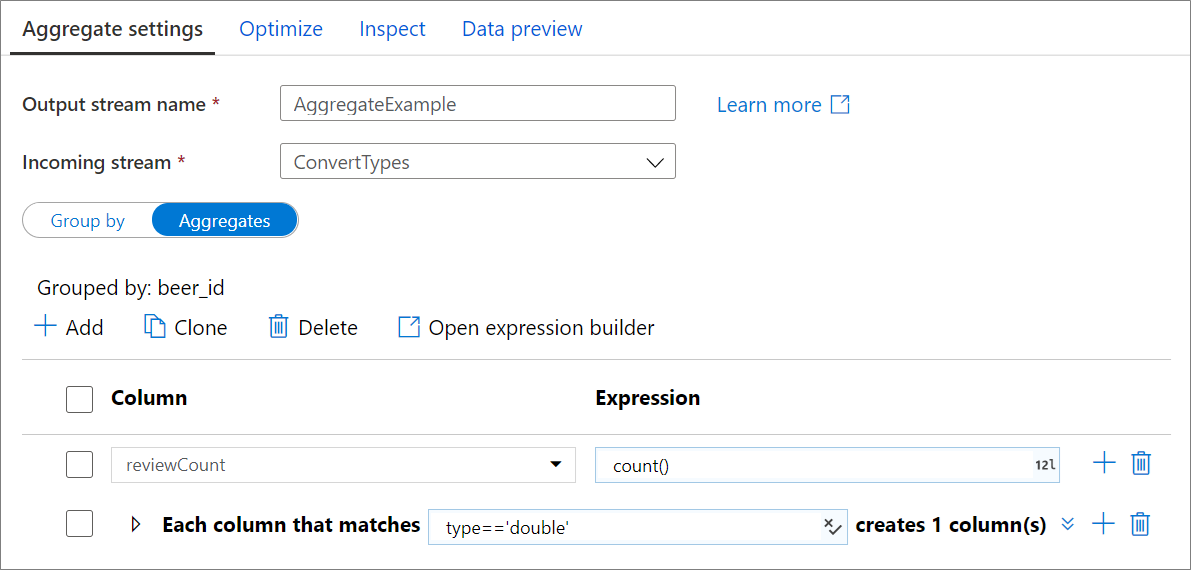
집계 열
집계 탭으로 이동하여 집계 식을 작성합니다. 기존 열을 집계로 덮어쓰거나 새 필드를 새 이름으로 만들 수 있습니다. 열 이름 선택기 옆의 오른쪽 상자에 집계 식이 입력됩니다. 식을 편집하려면 텍스트 상자를 클릭하고 식 작성기를 엽니다. 집계 열을 더 추가하려면 열 목록 위의 추가를 클릭하거나 기존 집계 열 옆에 있는 더하기 아이콘을 클릭합니다. 열 추가 또는 열 패턴 추가를 선택합니다. 각 집계 식은 집계 함수를 하나 이상 포함해야 합니다.
참고
디버그 모드의 식 작성기에서는 집계 함수로 데이터 미리 보기를 생성할 수 없습니다. 집계 변환의 데이터 미리 보기를 보려면 식 작성기를 닫고 ‘데이터 미리 보기’ 탭을 통해 데이터를 확인합니다.
열 패턴
열 패턴을 사용하여 열 집합에 동일한 집계를 적용할 수 있습니다. 이 기능은 기본적으로 삭제되는 입력 스키마의 많은 열을 유지하려는 경우에 유용합니다.
first()와 같은 휴리스틱을 사용하여 집계를 통해 입력 열을 유지할 수 있습니다.
행 및 열 다시 연결
집계 변환은 SQL 집계 select 쿼리와 유사합니다. group by 절이나 집계 함수에 포함되지 않은 열은 집계 변환의 출력으로 이동하지 않습니다. 집계된 출력에 다른 열을 포함하려는 경우 다음 방법 중 하나를 수행합니다.
-
last()또는first()와 같은 집계 함수를 사용하여 추가 열을 포함합니다. - 자체 조인 패턴을 사용하여 열을 출력 스트림에 다시 조인합니다.
중복 행 제거
집계 변환은 일반적으로 원본 데이터에서 중복 항목을 제거하거나 식별하는 데 사용됩니다. 이 프로세스를 중복 제거라고 합니다. 그룹화 기준 키 세트를 기반으로 원하는 추론을 사용하여 유지할 중복 행을 결정하세요. 일반적인 휴리스틱은 first(), last(), max(), min()입니다.
열 패턴을 사용하여 group by 열을 제외한 모든 열에 규칙을 적용할 수 있습니다.
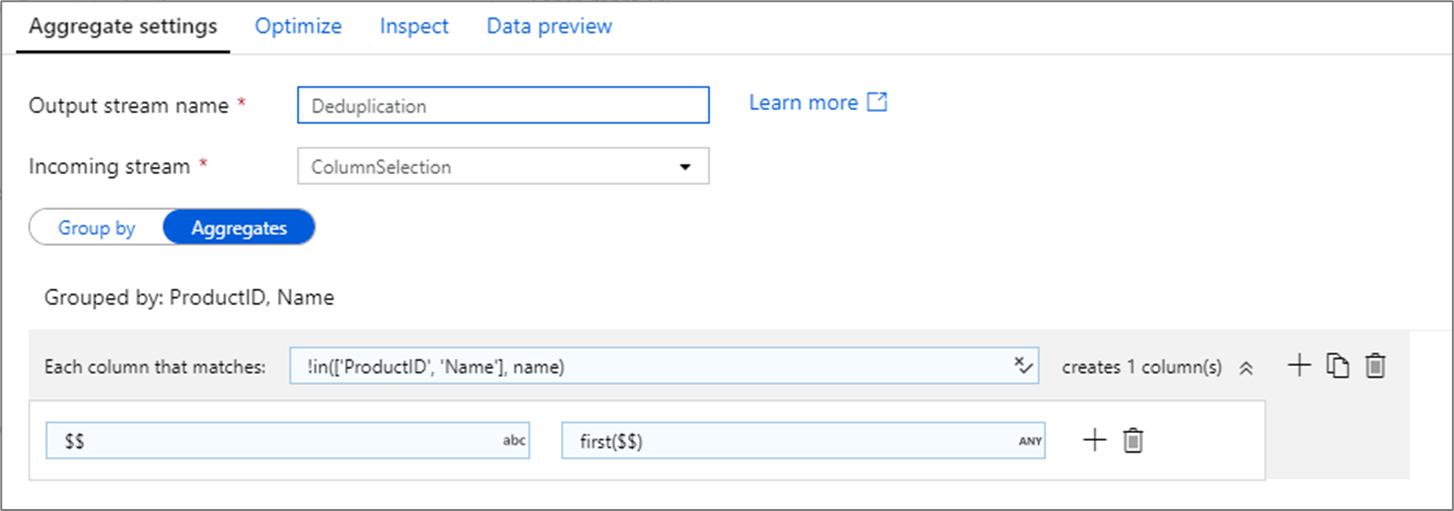
위의 예제에서는 ProductID 및 Name 열이 그룹화에 사용됩니다. 두 열의 값이 같은 두 행은 중복 항목으로 간주됩니다. 이 집계 변환에서는 일치하는 첫 번째 행의 값만 유지되고 다른 모든 값은 삭제됩니다. 열 패턴 구문을 사용하여 이름이 ProductID 및 Name이 아닌 모든 열은 기존 열 이름에 매핑되고 일치하는 첫 번째 행의 값이 지정됩니다. 출력 스키마는 입력 스키마와 같습니다.
데이터 유효성 검사 시나리오에서는 count() 함수를 사용하여 중복 항목 수를 계산할 수 있습니다.
데이터 흐름 스크립트
구문
<incomingStream>
aggregate(
groupBy(
<groupByColumnName> = <groupByExpression1>,
<groupByExpression2>
),
<aggregateColumn1> = <aggregateExpression1>,
<aggregateColumn2> = <aggregateExpression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <aggregateTransformationName>
예시
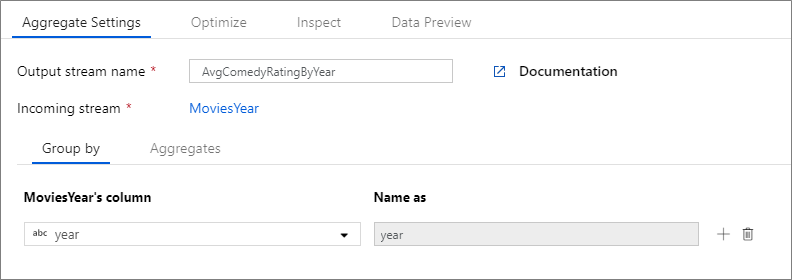
아래 예제에서는 들어오는 스트림 MoviesYear를 사용하고 year 열을 기준으로 행을 그룹화합니다. 이 변환은 avgrating 열의 평균으로 계산되는 집계 열 Rating을 만듭니다. 집계 변환의 이름은 AvgComedyRatingsByYear입니다.
UI에서 이 변환은 아래 이미지와 같습니다.
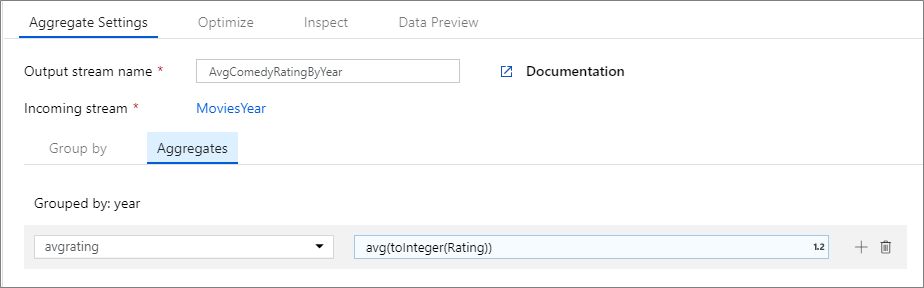
이 변환의 데이터 흐름 스크립트는 아래 코드 조각에 나와 있습니다.
MoviesYear aggregate(
groupBy(year),
avgrating = avg(toInteger(Rating))
) ~> AvgComedyRatingByYear
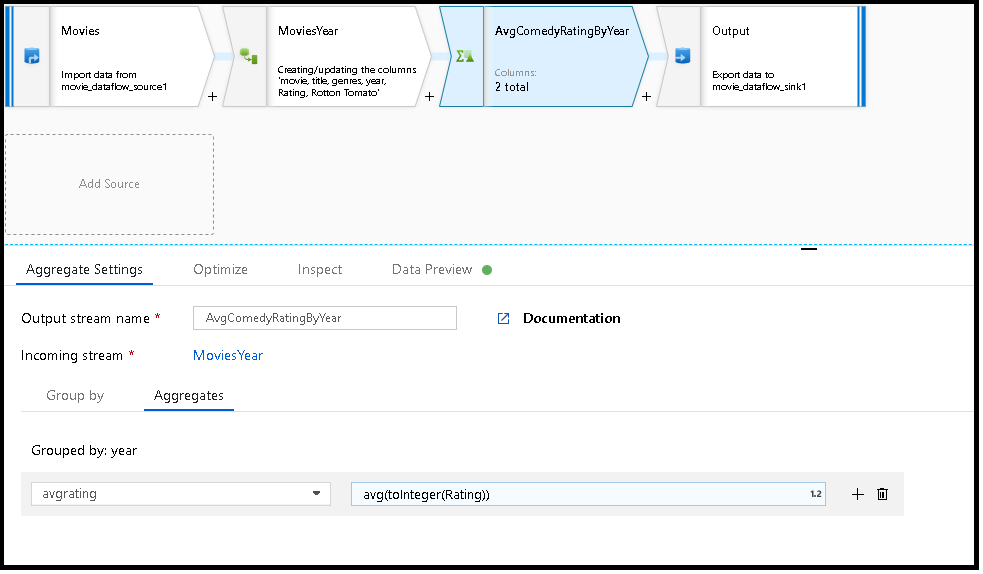
MoviesYear: year 및 title 열을 정의하는 파생 열 AvgComedyRatingByYear: 연도별로 그룹화된 코메디 평균 등급의 집계 변환 avgrating: 집계된 값을 포함하기 위해 생성되는 새 열의 이름
MoviesYear aggregate(groupBy(year),
avgrating = avg(toInteger(Rating))) ~> AvgComedyRatingByYear
관련 콘텐츠
- 창 변환을 사용하여 창 기반 집계 정의