매핑 데이터 흐름에서 새 분기 만들기
적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
데이터 흐름은 Azure Data Factory 및 Azure Synapse Pipelines 모두에서 사용할 수 있습니다. 이 문서는 매핑 데이터 흐름에 적용됩니다. 변환을 처음 사용하는 경우 매핑 데이터 흐름을 사용하여 데이터 변환 소개 문서를 참조하세요.
새 분기를 추가하여 동일한 데이터 스트림에 대해 여러 개의 작업 및 변환 세트를 수행할 수 있습니다. 여러 싱크에 대해 동일한 원본을 사용하거나 자체 조인 데이터를 함께 사용하려는 경우 새 분기를 추가하는 것이 유용합니다.
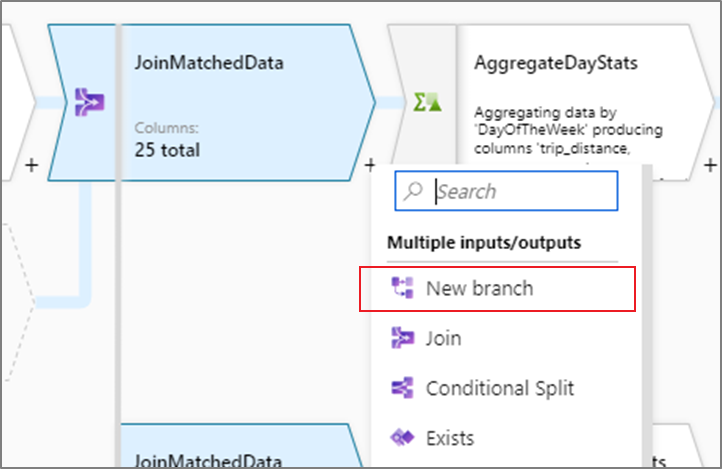
다른 변환과 유사하게 변환 목록에서 새 분기를 추가할 수 있습니다. 분기하려는 변환 뒤에 기존 변환이 있는 경우에만 새 분기를 작업으로 사용할 수 있습니다.
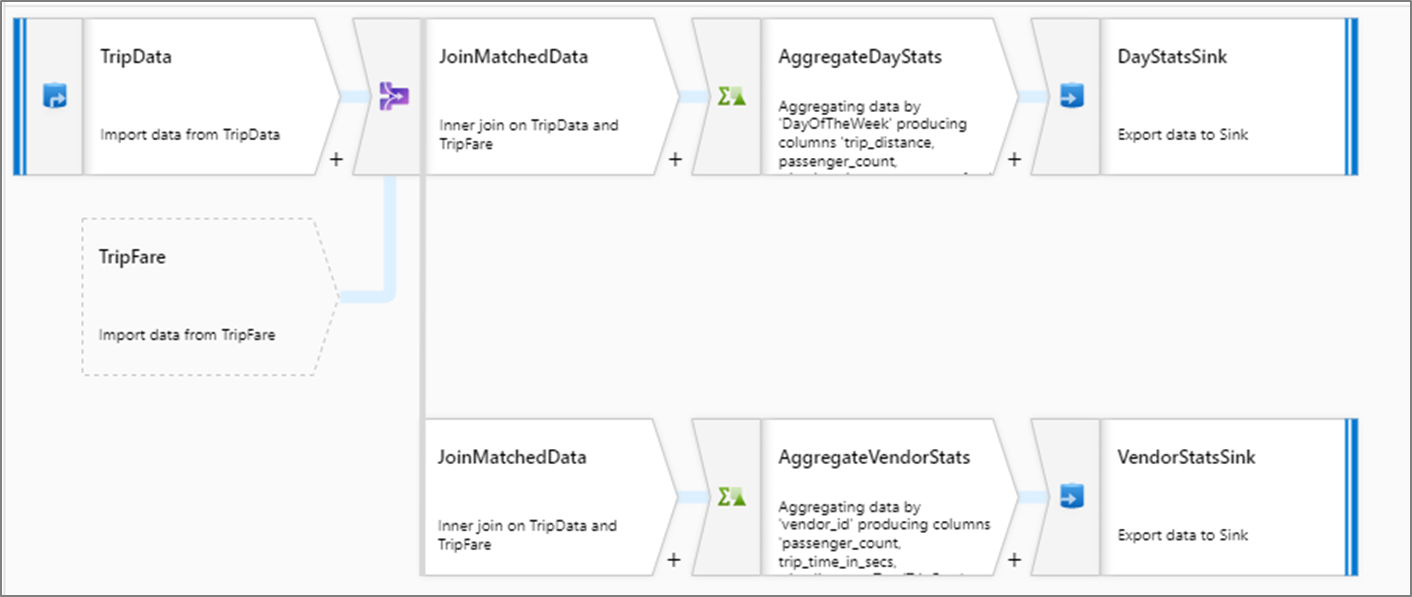
아래 예제에서 데이터 흐름은 택시 여행 데이터를 읽고 있습니다. 일별 및 공급 업체별로 집계된 출력이 필요합니다. 동일한 원본에서 읽는 두 개의 개별 데이터 흐름을 만드는 대신 새 분기를 추가할 수 있습니다. 이렇게 하면 두 집계가 동일한 데이터 흐름의 일부로 실행될 수 있습니다.
참고 항목
더하기(+)를 클릭하여 그래프에 변환을 추가하는 경우 후속 변환 블록이 있는 경우에만 새 분기 옵션이 표시됩니다. 이는 새 분기가 기존 스트림에 대한 참조를 생성하고 작동하기 위해 추가 업스트림 처리가 필요하기 때문입니다. 새 분기 옵션이 표시되지 않으면 파생 열 또는 다른 변환을 먼저 추가한 다음, 이전 블록으로 돌아가 새 분기를 옵션으로 표시합니다.
관련 콘텐츠
분기 후 데이터 흐름 변환을 사용할 수 있습니다.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기