적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
Microsoft Fabric의 데이터 팩토리는 더 간단한 아키텍처, 기본 제공 AI 및 새로운 기능을 갖춘 차세대 Azure 데이터 팩토리입니다. 데이터 통합을 접하는 경우 Fabric Data Factory부터 시작합니다. 기존 ADF 워크로드는 Fabric 업그레이드하여 데이터 과학, 실시간 분석 및 보고 전반에 걸쳐 새로운 기능에 액세스할 수 있습니다.
- Fabric 무료 평가판을 시작합니다.
Microsoft Fabric의 Data Factory로 Azure Data Factory를 업그레이드합니다
데이터 흐름은 Azure Data Factory 파이프라인과 Azure Synapse Analytics 파이프라인 모두에서 사용할 수 있습니다. 이 문서는 매핑 데이터 흐름에 적용됩니다. 변환을 접하는 경우 매핑 데이터 흐름을 사용하여 데이터 변환 소개 문서를 참조하세요.
팁
Dataflow Gen2의 대등한 변환(구문 분석)에 대해서는 데이터 흐름 사용자 매핑을 위한 Dataflow Gen2 가이드를 참조하세요.
문서 형식의 문자열인 데이터의 텍스트 열을 구문 분석하려면 구문 분석 변환을 사용합니다. 구문 분석할 수 있는 현재 지원되는 포함 문서 형식은 JSON, XML 및 구분 기호로 분리된 텍스트입니다.
설정
구문 분석 변환 구성 패널에서 먼저 인라인으로 구문 분석하려는 열에 포함된 데이터 형식을 선택합니다. 구문 분석 변환에는 다음과 같은 구성 설정도 포함됩니다.

Column
파생 열 및 집계와 마찬가지로, 열 속성에서 드롭다운 메뉴를 사용하여 기존 열을 선택하고 수정할 수 있습니다. 또는 여기에 새 열의 이름을 입력할 수 있습니다. ADF는 구문 분석된 원본 데이터를 이 열에 저장합니다. 대부분의 경우 들어오는 포함된 문서 문자열 필드를 구문 분석하는 새 열을 정의하고 싶을 것입니다.
식
식 작성기를 사용하여 구문 분석에 사용할 원본을 설정합니다. 원본을 설정하면 구문 분석하려는 자체 포함 데이터가 있는 원본 열을 선택하는 것만큼 간단할 수도 있고, 구문 분석할 복잡한 식을 만들 수도 있습니다.
예제 식
원본 문자열 데이터:
chrome|steel|plastic- 식:
(desc1 as string, desc2 as string, desc3 as string)
- 식:
원본 JSON 데이터:
{"ts":1409318650332,"userId":"309","sessionId":1879,"page":"NextSong","auth":"Logged In","method":"PUT","status":200,"level":"free","itemInSession":2,"registration":1384448}- 식:
(level as string, registration as long)
- 식:
원본 중첩된 JSON 데이터:
{"car" : {"model" : "camaro", "year" : 1989}, "color" : "white", "transmission" : "v8"}- 식:
(car as (model as string, year as integer), color as string, transmission as string)
- 식:
원본 XML 데이터:
<Customers><Customer>122</Customer><CompanyName>Great Lakes Food Market</CompanyName></Customers>- 식:
(Customers as (Customer as integer, CompanyName as string))
- 식:
특성 데이터가 있는 원본 XML:
<cars><car model="camaro"><year>1989</year></car></cars>- 식:
(cars as (car as ({@model} as string, year as integer)))
- 식:
예약된 문자가 있는 식:
{ "best-score": { "section 1": 1234 } }- 위의 식은
best-score의 ‘-’ 문자가 빼기 연산으로 해석되기 때문에 작동하지 않습니다. 이러한 경우 대괄호 표기법으로 변수를 사용하여 JSON 엔진에 텍스트를 문자 그대로 해석하도록 지시합니다.var bestScore = data["best-score"]; { bestScore : { "section 1": 1234 } }
- 위의 식은
참고: 복합 형식에서 특성을 추출하는 동안 오류가 발생하는 경우(특히 @model) 해결 방법은 복합 형식을 문자열로 변환하고, @ 기호(특히, replace(toString(your_xml_string_parsed_column_name.cars.car),'@','') )를 제거한 다음, 구문 분석 JSON 변환 작업을 사용하는 것입니다.
출력 열 형식
다음은 단일 열에 기록되는 파싱 결과로부터 대상 출력 스키마를 구성하는 위치입니다. 구문 분석에서 출력에 대한 스키마를 설정하는 가장 쉬운 방법은 식 작성기의 오른쪽 상단에 있는 '형식 검색' 단추를 선택하는 것입니다. ADF는 파싱 중인 문자열 필드에서 스키마를 자동으로 식별하고 이를 출력 표현식에 설정하려고 시도합니다.
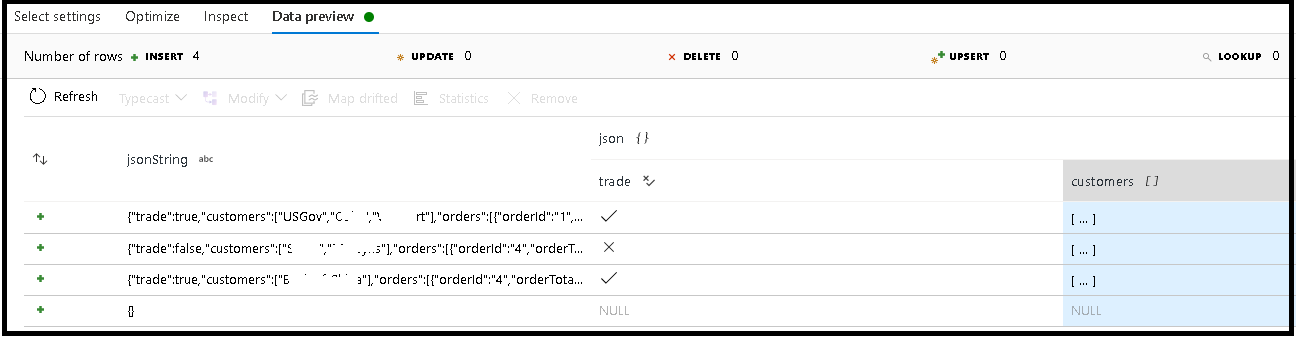
이 예제에서는 일반 텍스트이지만 JSON 구조로 형식이 지정된 들어오는 필드 “jsonString”의 구문 분석을 정의했습니다. 다음 스키마를 사용하여 구문 분석된 결과를 "json"이라는 새 열에 JSON으로 저장하겠습니다.
(trade as boolean, customers as string[])
검사 탭 및 데이터 미리 보기를 참조하여 출력이 올바르게 매핑되었는지 확인합니다.
파생 열 작업을 사용하여 계층적 데이터(즉, 식 필드의 your_complex_column_name.car.model)를 추출합니다.
예제
source(output(
name as string,
location as string,
satellites as string[],
goods as (trade as boolean, customers as string[], orders as (orderId as string, orderTotal as double, shipped as (orderItems as (itemName as string, itemQty as string)[]))[])
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
documentForm: 'documentPerLine') ~> JsonSource
source(output(
movieId as string,
title as string,
genres as string
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false) ~> CsvSource
JsonSource derive(jsonString = toString(goods)) ~> StringifyJson
StringifyJson parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json',
documentForm: 'arrayOfDocuments') ~> ParseJson
CsvSource derive(csvString = 'Id|name|year\n\'1\'|\'test1\'|\'1999\'') ~> CsvString
CsvString parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
ParseJson select(mapColumn(
jsonString,
json
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedJson
ParseCsv select(mapColumn(
csvString,
csv
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedCsv
데이터 흐름 스크립트
구문
예제
parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json|XML|delimited',
documentForm: 'singleDocument') ~> ParseJson
parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv