Azure Data Factory의 델타 형식
적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
이 문서에서는 델타 형식을 사용하여 Azure Data Lake Store Gen2 또는 Azure Blob Storage에 저장된 델타 레이크 간에 데이터를 복사하는 방법을 강조 표시합니다. 이 커넥터는 매핑 데이터 흐름에서 원본 및 싱크로 인라인 데이터 세트로 사용할 수 있습니다.
매핑 데이터 흐름 속성
이 커넥터는 매핑 데이터 흐름에서 원본 및 싱크로 인라인 데이터 세트로 사용할 수 있습니다.
원본 속성
아래 표에서는 델타 원본에서 지원하는 속성을 나열합니다. 이러한 속성은 원본 옵션 탭에서 편집할 수 있습니다.
| 이름 | 설명 | 필수 | 허용된 값 | 데이터 흐름 스크립트 속성 |
|---|---|---|---|---|
| 형식 | 형식은 다음이어야 합니다. delta |
예 | delta |
format |
| 파일 시스템 | 델타 레이크의 컨테이너/파일 시스템 | 예 | 문자열 | fileSystem |
| Folder path | 델타 레이크의 디렉터리 | 예 | 문자열 | folderPath |
| 압축 유형 | 델타 테이블의 압축 형식 | 아니요 | bzip2gzipdeflateZipDeflatesnappylz4 |
compressionType |
| Compression level | 압축이 가능한 한 빨리 완료되는지 또는 결과 파일을 최적으로 압축해야 하는지 여부를 선택합니다. | 지정된 경우 compressedType 필수입니다. |
Optimal 또는 Fastest |
compressionLevel |
| 시간 이동 | 델타 테이블의 이전 스냅샷 쿼리할지 여부를 선택합니다. | 아니요 | 타임스탬프별 쿼리: 타임스탬프 버전별 쿼리: 정수 |
timestampAsOf versionAsOf |
| 파일을 찾을 수 없음 허용 | true이면 파일이 없으면 오류가 throw되지 않습니다. | 아니요 | true 또는 false |
ignoreNoFilesFound |
스키마 가져오기
델타는 인라인 데이터 세트로만 사용할 수 있으며 기본적으로 연결된 스키마가 없습니다. 열 메타데이터를 가져오려면 프로젝션 탭에서 스키마 가져오기 단추를 클릭합니다. 이렇게 하면 모음에서 지정한 열 이름 및 데이터 형식을 참조할 수 있습니다. 스키마 를 가져오려면 데이터 흐름 디버그 세션 이 활성 상태여야 하며 가리킬 기존 CDM 엔터티 정의 파일이 있어야 합니다.
델타 원본 스크립트 예제
source(output(movieId as integer,
title as string,
releaseDate as date,
rated as boolean,
screenedOn as timestamp,
ticketPrice as decimal(10,2)
),
store: 'local',
format: 'delta',
versionAsOf: 0,
allowSchemaDrift: false,
folderPath: $tempPath + '/delta'
) ~> movies
싱크 속성
다음 표에는 델타 싱크에서 지원하는 속성이 나와 있습니다. 설정 탭에서 이러한 속성을 편집할 수 있습니다.
| 이름 | 설명 | 필수 | 허용된 값 | 데이터 흐름 스크립트 속성 |
|---|---|---|---|---|
| 형식 | 형식은 다음이어야 합니다. delta |
예 | delta |
format |
| 파일 시스템 | 델타 레이크의 컨테이너/파일 시스템 | 예 | 문자열 | fileSystem |
| Folder path | 델타 레이크의 디렉터리 | 예 | 문자열 | folderPath |
| 압축 유형 | 델타 테이블의 압축 형식 | 아니요 | bzip2gzipdeflateZipDeflatesnappylz4TarGZiptar |
compressionType |
| Compression level | 압축이 가능한 한 빨리 완료되는지 또는 결과 파일을 최적으로 압축해야 하는지 여부를 선택합니다. | 지정된 경우 compressedType 필수입니다. |
Optimal 또는 Fastest |
compressionLevel |
| 진공 | 현재 테이블 버전과 더 이상 관련이 없는 지정된 기간보다 오래된 파일을 삭제합니다. 값이 0 이하인 경우 진공 작업이 수행되지 않습니다. | 예 | 정수 | 진공 |
| 테이블 작업 | 싱크에서 대상 델타 테이블로 수행할 작업을 ADF에 알려줍니다. 그대로 두고 새 행을 추가하거나, 기존 테이블 정의 및 데이터를 새 메타데이터 및 데이터로 덮어쓰거나, 기존 테이블 구조를 유지하되 먼저 모든 행을 자른 다음, 새 행을 삽입할 수 있습니다. | 아니요 | 없음, 자르기, 덮어쓰기 | deltaTruncate, 덮어쓰기 |
| Update 메서드 | "삽입 허용"을 단독으로 선택하거나 새 델타 테이블에 쓸 때 대상은 행 정책 집합에 관계없이 들어오는 모든 행을 받습니다. 데이터에 다른 행 정책의 행이 포함된 경우 이전 필터 변환을 사용하여 제외해야 합니다. 모든 업데이트 메서드를 선택하면 이전의 행 변경 변환을 사용하여 행 정책 집합에 따라 행이 삽입/삭제/업서트/업데이트되는 병합이 수행됩니다. |
예 | true 또는 false |
삽입 가능 Deletable upsertable 업데이트할 |
| 최적화된 쓰기 | Spark 실행기에서 내부 순서 섞기를 최적화하여 쓰기 작업에 대해 더 높은 처리량을 달성합니다. 따라서 더 큰 크기의 파티션과 파일이 더 적어질 수 있습니다. | 아니요 | true 또는 false |
optimizedWrite: true |
| 자동 압축 | 쓰기 작업이 완료되면 Spark에서 자동으로 명령을 실행 OPTIMIZE 하여 데이터를 다시 구성하여 필요한 경우 더 많은 파티션을 생성하여 향후 읽기 성능을 향상합니다. |
아니요 | true 또는 false |
autoCompact: true |
델타 싱크 스크립트 예제
연결된 데이터 흐름 스크립트는 다음과 같습니다.
moviesAltered sink(
input(movieId as integer,
title as string
),
mapColumn(
movieId,
title
),
insertable: true,
updateable: true,
deletable: true,
upsertable: false,
keys: ['movieId'],
store: 'local',
format: 'delta',
vacuum: 180,
folderPath: $tempPath + '/delta'
) ~> movieDB
파티션 정리가 포함된 델타 싱크
위의 업데이트 방법(즉, 업데이트/upsert/삭제)에서 이 옵션을 사용하여 검사되는 파티션 수를 제한할 수 있습니다. 이 조건을 충족하는 파티션만 대상 저장소에서 가져옵니다. 파티션 열이 취할 수 있는 고정 값 집합을 지정할 수 있습니다.
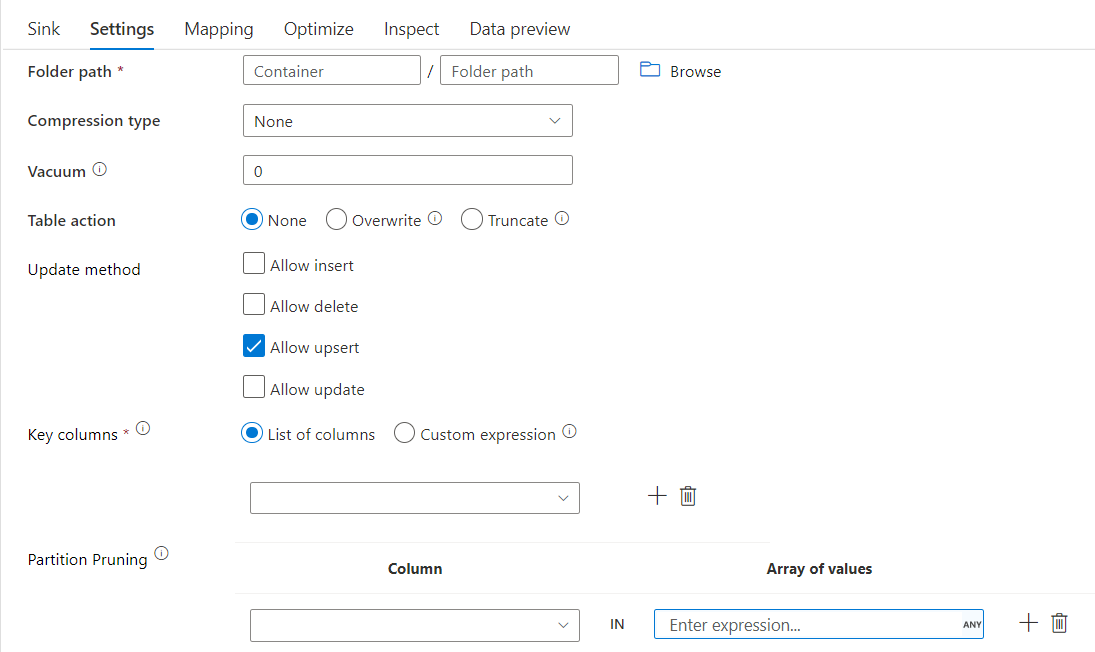
파티션 정리가 포함된 델타 싱크 스크립트 예
샘플 스크립트는 아래와 같습니다.
DerivedColumn1 sink(
input(movieId as integer,
title as string
),
allowSchemaDrift: true,
validateSchema: false,
format: 'delta',
container: 'deltaContainer',
folderPath: 'deltaPath',
mergeSchema: false,
autoCompact: false,
optimizedWrite: false,
vacuum: 0,
deletable:false,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
pruneCondition:['part_col' -> ([5, 8])],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink2
델타는 모든 파티션 대신 대상 델타 저장소에서 part_col == 5 및 8인 2개의 파티션만 읽습니다. part_col은 대상 델타 데이터를 분할하는 기준이 되는 열입니다. 원본 데이터에 있을 필요는 없습니다.
델타 싱크 최적화 옵션
설정 탭에서는 델타 싱크 변환을 최적화하는 세 가지 옵션을 더 찾습니다.
병합 스키마 옵션을 사용하면 스키마 진화가 가능합니다. 즉, 현재 들어오는 스트림에 있지만 대상 델타 테이블에 없는 열은 해당 스키마에 자동으로 추가됩니다. 이 옵션은 모든 업데이트 메서드에서 지원됩니다.
자동 압축이 사용하도록 설정된 경우 개별 쓰기 후 변환은 파일을 더 압축할 수 있는지 확인하고 빠른 OPTIMIZE 작업(1GB 대신 128MB 파일 크기 사용)을 실행하여 작은 파일 수가 가장 많은 파티션에 대해 파일을 추가로 압축합니다. 자동 압축을 사용하면 많은 수의 작은 파일을 더 적은 수의 큰 파일로 합칠 수 있습니다. 자동 압축은 파일이 50개 이상인 경우에만 시작됩니다. 압축 작업이 수행되면 테이블의 새 버전을 만들고 이전 여러 파일의 데이터를 포함하는 새 파일을 압축된 압축 형식으로 씁니다.
쓰기 최적화가 사용하도록 설정되면 싱크 변환은 각 테이블 파티션에 대해 128MB 파일 쓰기를 시도하여 실제 데이터를 기반으로 파티션 크기를 동적으로 최적화합니다. 이는 대략적인 크기이며 데이터 세트 특성에 따라 다를 수 있습니다. 최적화된 쓰기는 쓰기 및 후속 읽기의 전반적인 효율성을 개선시킵니다. 후속 읽기의 성능이 향상되도록 파티션을 구성합니다.
팁
데이터가 처리된 후 Sink가 Spark Delta Lake Optimize 명령을 실행하기 때문에 최적화된 쓰기 프로세스는 전체 ETL 작업의 속도를 늦춥니다. 따라서 최적화된 쓰기는 신중하게 사용하는 것이 좋습니다. 예를 들어 시간별 데이터 파이프라인이 있는 경우 최적화된 쓰기를 사용하여 매일 데이터 흐름을 실행합니다.
알려진 제한 사항
델타 싱크에 쓸 때 기록된 행 수가 모니터링 출력에 표시되지 않는 알려진 제한 사항이 있습니다.
관련 콘텐츠
- 매핑 데이터 흐름에서 원본 변환을 만듭니다.
- 매핑 데이터 흐름에서 싱크 변환을 만듭니다.
- 행을 삽입, 업데이트, upsert 또는 삭제로 표시하는 행 변경 변환을 만듭니다.