적용 대상:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
기업용 올인원 분석 솔루션인 Microsoft Fabric의 Data Factory를 사용해 보세요. Microsoft Fabric은 데이터 이동부터 데이터 과학, 실시간 분석, 비즈니스 인텔리전스 및 보고에 이르기까지 모든 것을 다룹니다. 무료로 새 평가판을 시작하는 방법을 알아봅니다!
Azure Data Lake Storage Gen2는 Azure Blob Storage를 기반으로 하는 빅 데이터 분석 전용의 기능 세트입니다. 이를 사용하면 파일 시스템 및 개체 스토리지 패러다임을 모두 사용하여 데이터를 조작할 수 있습니다.
ADF(Azure Data Factory)는 완전 관리형 클라우드 기반 데이터 통합 서비스입니다. 분석 솔루션을 빌드할 때 서비스를 사용하여 풍부한 온-프레미스 및 크라우드 기반 데이터 저장소의 데이터로 레이크를 채우고 시간을 절약할 수 있습니다. 지원되는 커넥터의 자세한 목록은 지원되는 데이터 저장소 표를 참조하세요.
Azure Data Factory는 스케일 아웃, 관리되는 데이터 이동 솔루션을 제공합니다. ADF의 스케일 아웃 아키텍처로 인해 높은 처리량으로 데이터를 수집할 수 있습니다. 자세한 내용은 복사 작업 성능을 참조하세요.
이 아티클에서는 Data Factory 복사 데이터 도구를 사용하여 Amazon Web Services S3 서비스의 데이터를 Azure Data Lake Storage Gen2로 로드하는 방법을 설명합니다. 다른 데이터 저장소 유형에서 데이터를 복사할 때도 이와 유사한 단계를 따를 수 있습니다.
팁
Azure Data Lake Storage Gen1에서 Gen2로 데이터를 복사하는 방법은 이 연습을 참조하세요.
필수 조건
- Azure 구독: Azure 구독이 아직 없는 경우 시작하기 전에 무료 계정을 만듭니다.
- Data Lake Storage Gen2를 사용하는 Azure Storage 계정: Storage 계정이 없는 경우 계정을 만듭니다.
- 데이터를 포함하는 S3 버킷을 포함한 AWS 계정: 이 아티클에서는 Amazon S3에서 데이터를 복사하는 방법을 보여줍니다. 다음과 같은 유사한 단계를 수행하여 다른 데이터 저장소를 사용할 수 있습니다.
데이터 팩터리 만들기
아직 Data Factory를 만들지 않은 경우 빠른 시작: Azure Portal 및 Azure Data Factory Studio를 사용하여 Data Factory 만들기 단계에 따라 Data Factory를 만듭니다. 만든 후 Azure Portal에서 데이터 팩터리로 이동합니다.
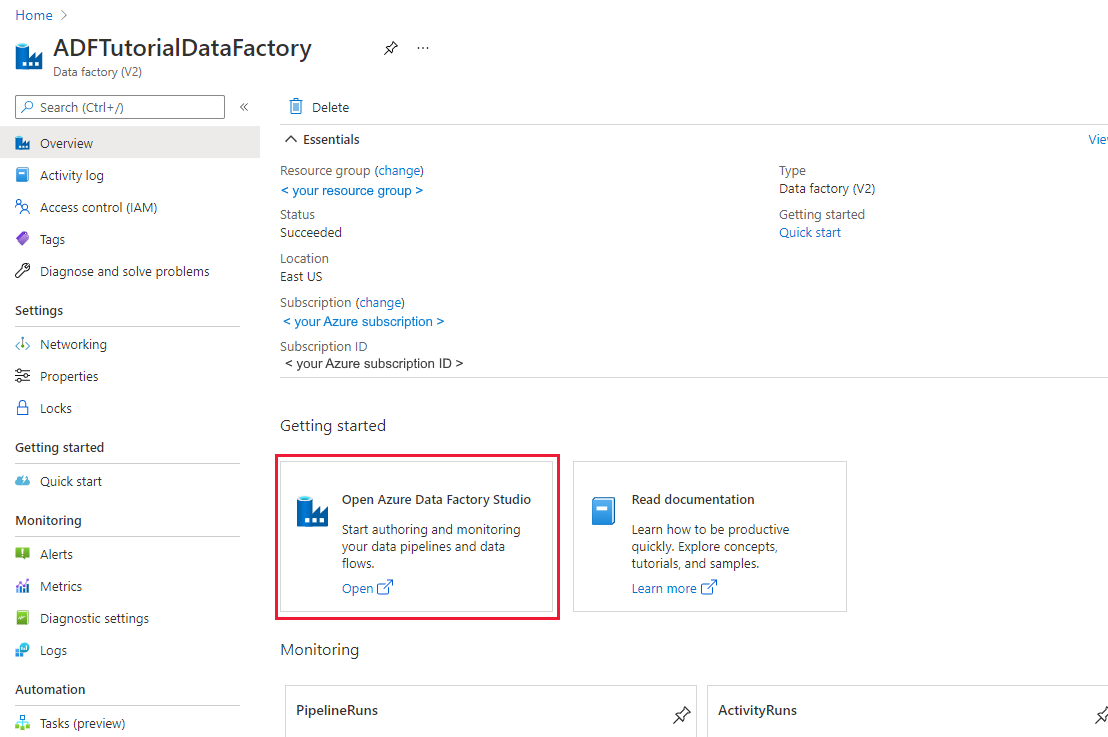
Azure Data Factory Studio 열기 타일에서 열기를 선택하여 별도의 탭에서 데이터 통합 애플리케이션을 시작합니다.
Azure Data Lake Storage Gen2에 데이터 로드
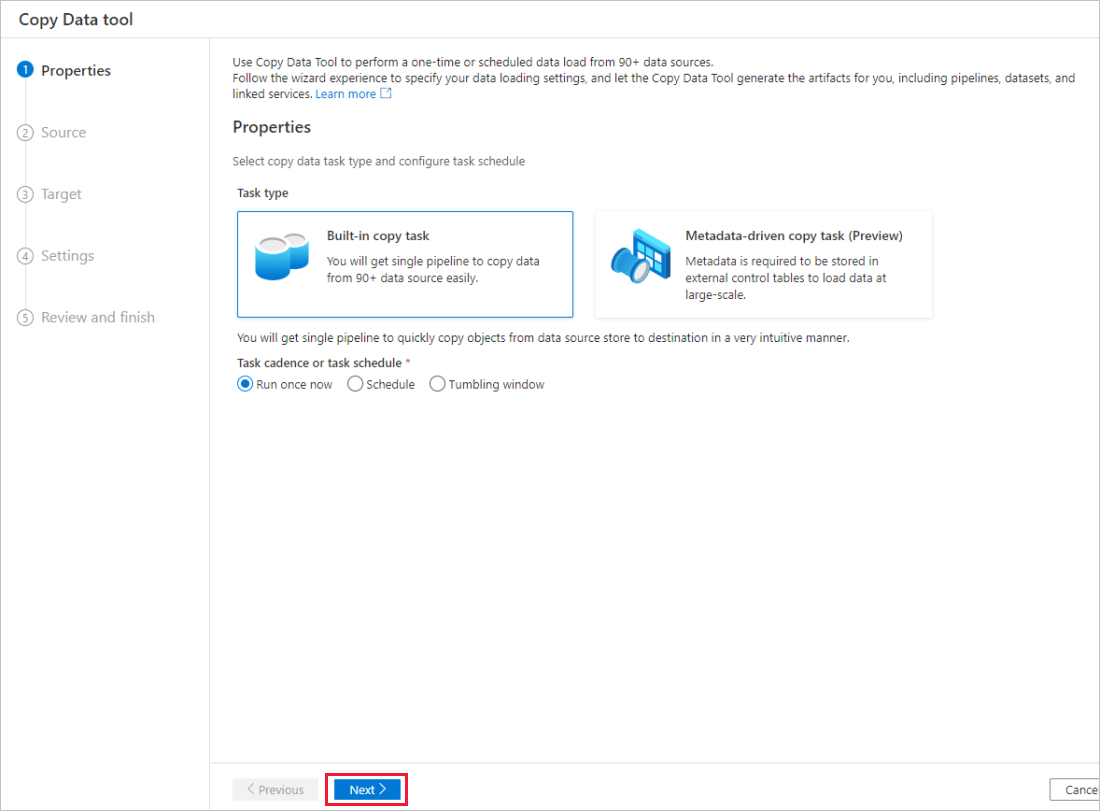
Azure Data Factory 홈페이지에서 수집 타일을 선택하여 데이터 복사 도구를 시작합니다.
속성 페이지에 있는 작업 유형 아래에서 기본 제공 복사 작업을 선택한 후 작업 주기 또는 작업 일정에서 지금 한 번 실행을 선택한 후 다음을 선택합니다.
원본 데이터 저장소 페이지에서 다음 단계를 완료합니다.
+새 연결을 선택합니다. 커넥터 갤러리에서 Amazon S3을 선택하고 계속을 선택합니다.

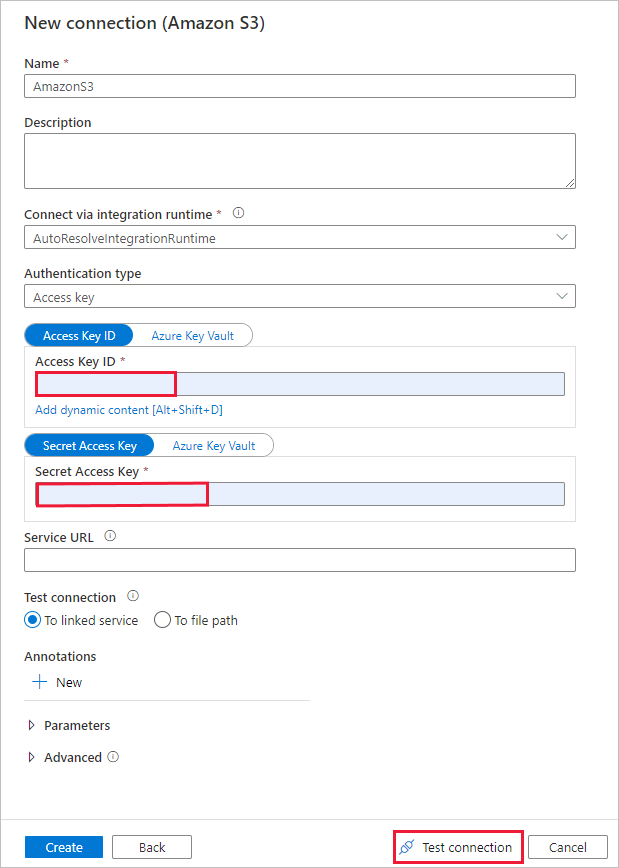
새 연결(Amazon S3) 페이지에서 다음 단계를 수행합니다.
- 액세스 키 ID 값을 지정합니다.
- 비밀 액세스 키 값을 지정합니다.
- 연결 테스트를 선택하여 설정의 유효성을 검사한 후 만들기를 선택합니다.
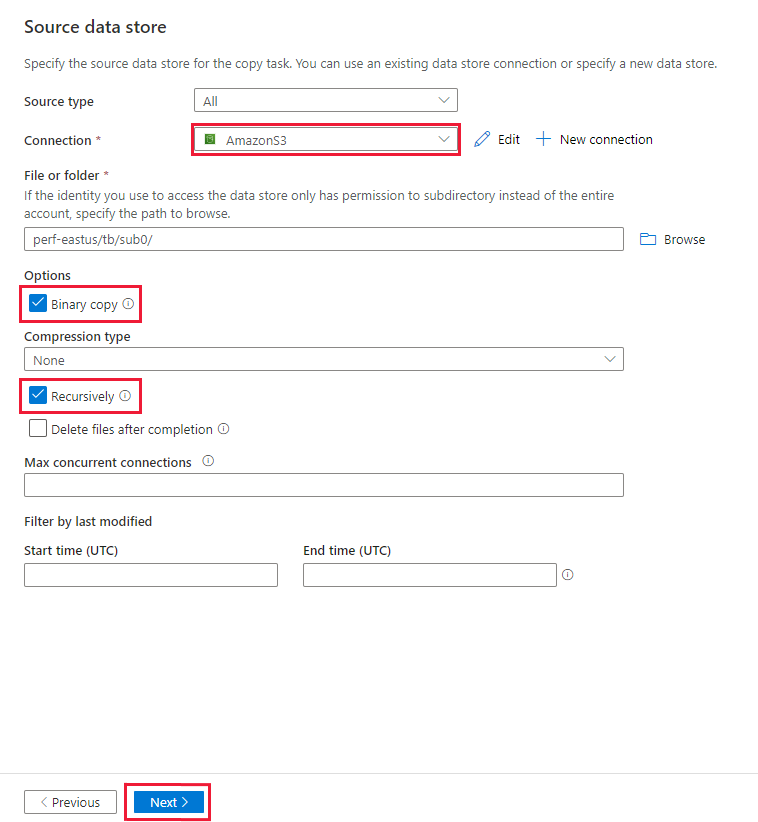
원본 데이터 저장소 페이지의 연결 블록에서 새로 생성된 Amazon S3 연결이 선택되어 있는지 확인합니다.
파일 또는 폴더 섹션에서 복사할 폴더와 파일을 찾습니다. 폴더/파일을 선택한 다음, 확인을 선택합니다.
재귀적으로 및 이진 복사 옵션을 선택하여 복사 동작을 지정합니다. 다음을 선택합니다.
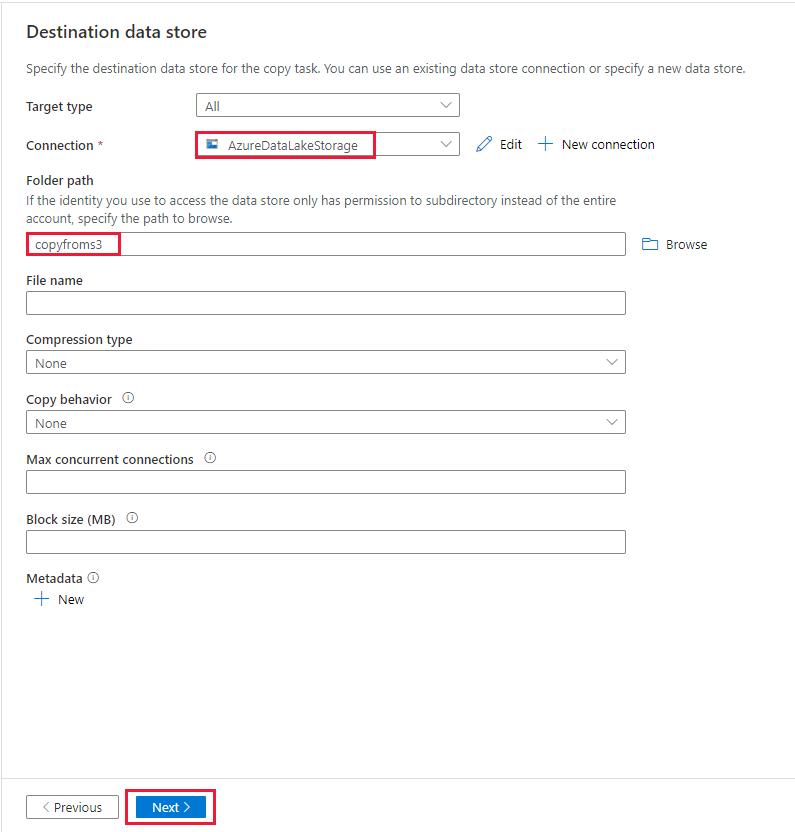
대상 데이터 저장소 페이지에서 다음 단계를 완료합니다.
+ 새 연결을 선택한 다음, Azure Data Lake Storage Gen2를 선택하고 계속을 선택합니다.
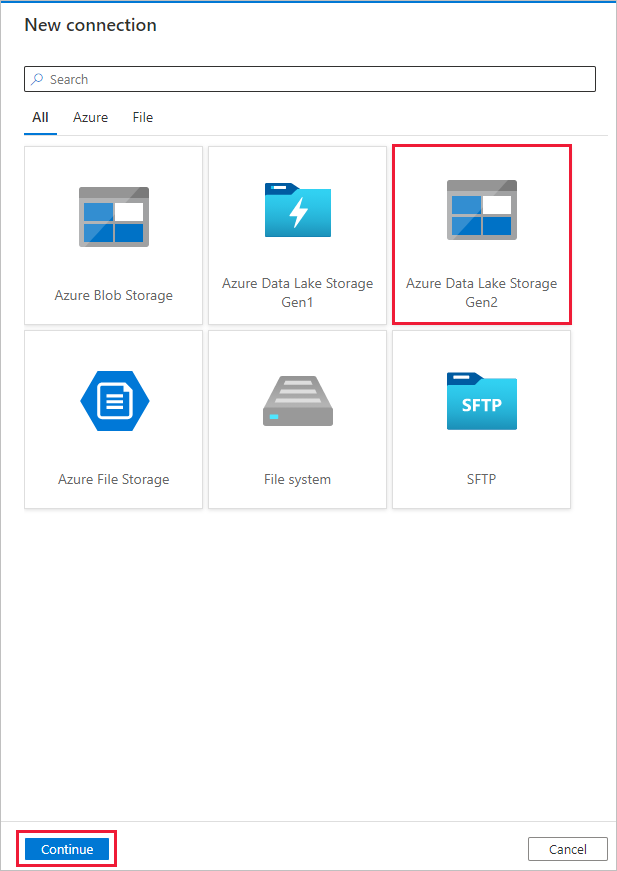
새 연결(Azure Data Lake Storage Gen2) 페이지의 “스토리지 계정 이름” 드롭다운 목록에서 Data Lake Storage Gen2 지원 계정을 선택하고 만들기를 선택하여 연결을 만듭니다.
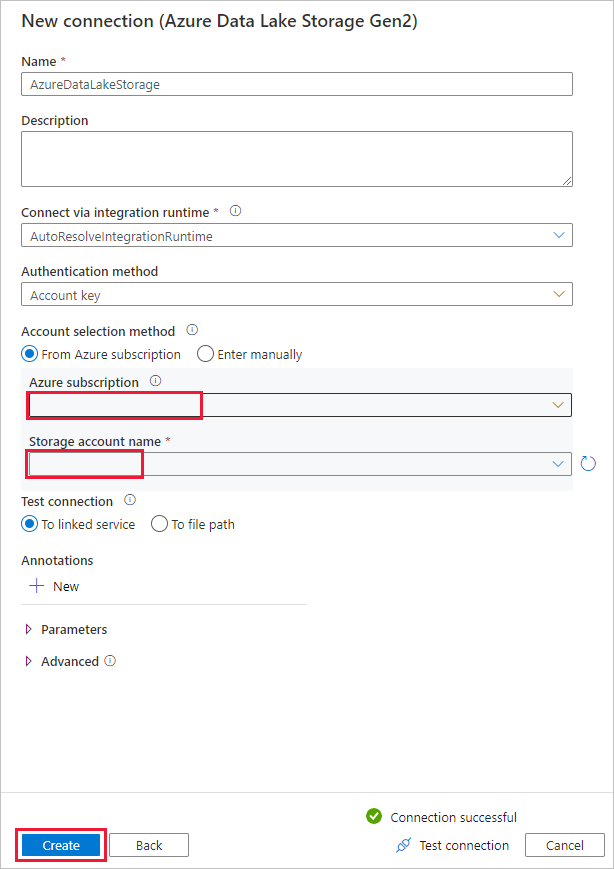
대상 데이터 저장소 페이지의 연결 블록에서 새로 만든 연결을 선택합니다. 그런 다음, 폴더 경로에서 출력 폴더 이름으로 copyfroms3을 입력하고 다음을 선택합니다. ADF에서 복사 중 해당 ADLS Gen2 파일 시스템 및 하위 폴더를 만듭니다(없는 경우).
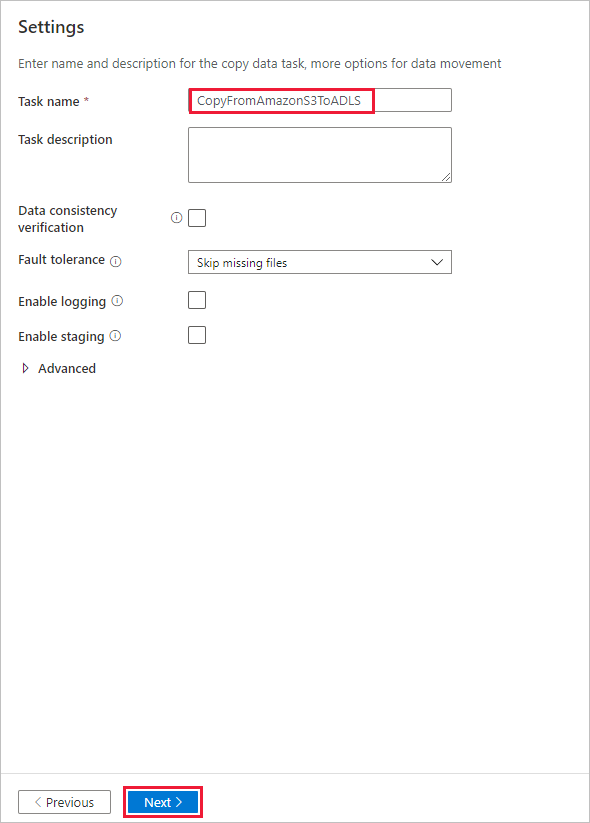
설정 페이지에서 작업 이름 필드에 대해 CopyFromAmazonS3ToADLS를 지정한 후 다음을 선택하여 기본 설정을 사용합니다.
요약 페이지에서 설정을 검토하고 다음을 선택합니다.
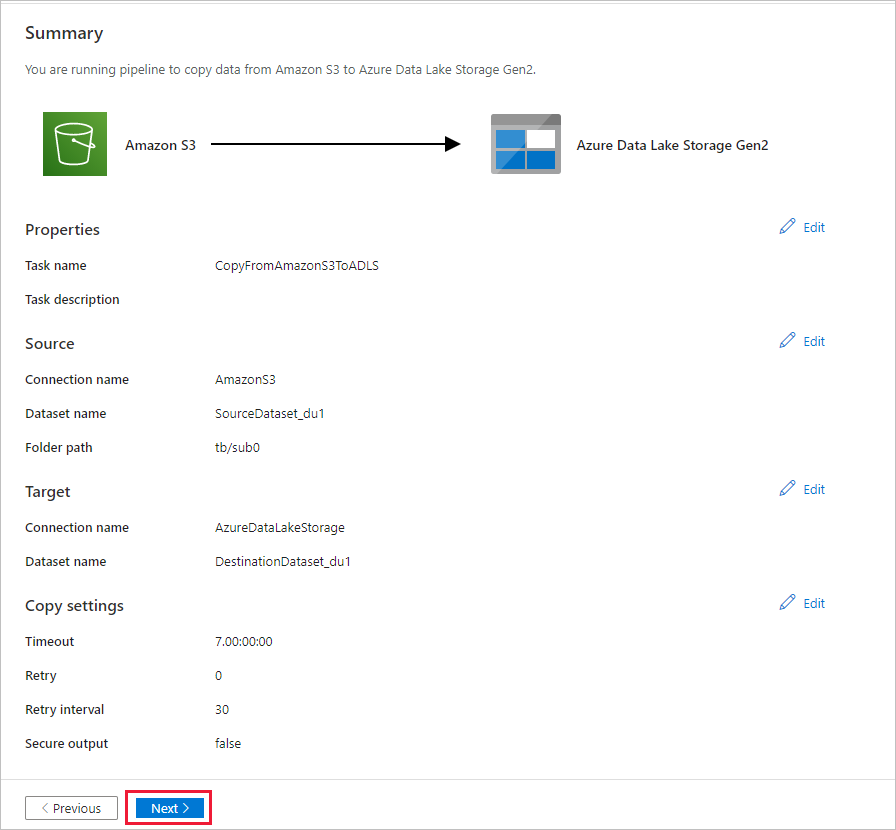
배포 페이지에서 모니터링을 선택하여 파이프라인(작업)을 모니터링합니다.
파이프라인 실행이 성공적으로 완료되면 수동 트리거로 트리거된 파이프라인 실행이 표시됩니다. 파이프라인 이름 열 아래의 링크를 사용하여 활동 세부 정보를 보고 파이프라인을 다시 실행할 수 있습니다.
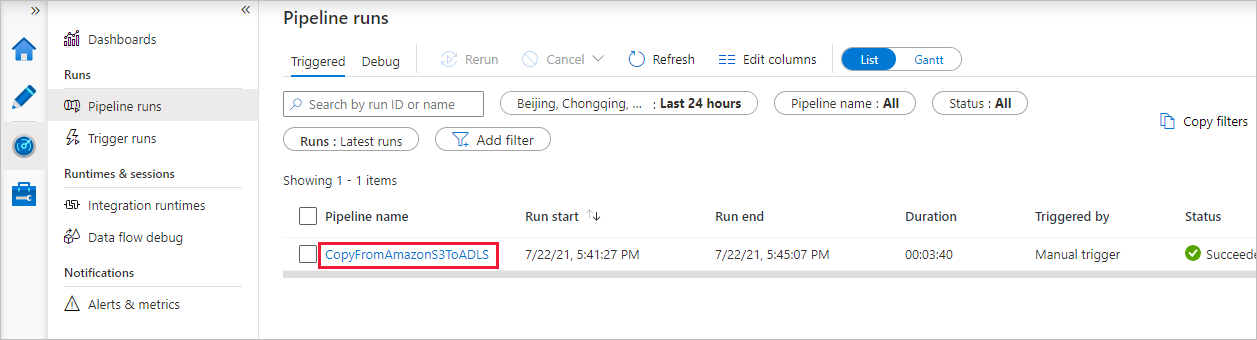
파이프라인 실행과 관련된 활동 실행을 보려면 파이프라인 이름 열에서 CopyFromAmazonS3ToADLS 링크를 선택합니다. 복사 작업에 대한 자세한 내용을 보려면 작업 이름 열 아래의 세부 정보 링크(안경 아이콘)를 선택합니다. 원본에서 싱크로 복사된 데이터 양, 데이터 처리량, 해당 기간의 실행 단계, 사용된 구성과 같은 세부 정보를 모니터링할 수 있습니다.
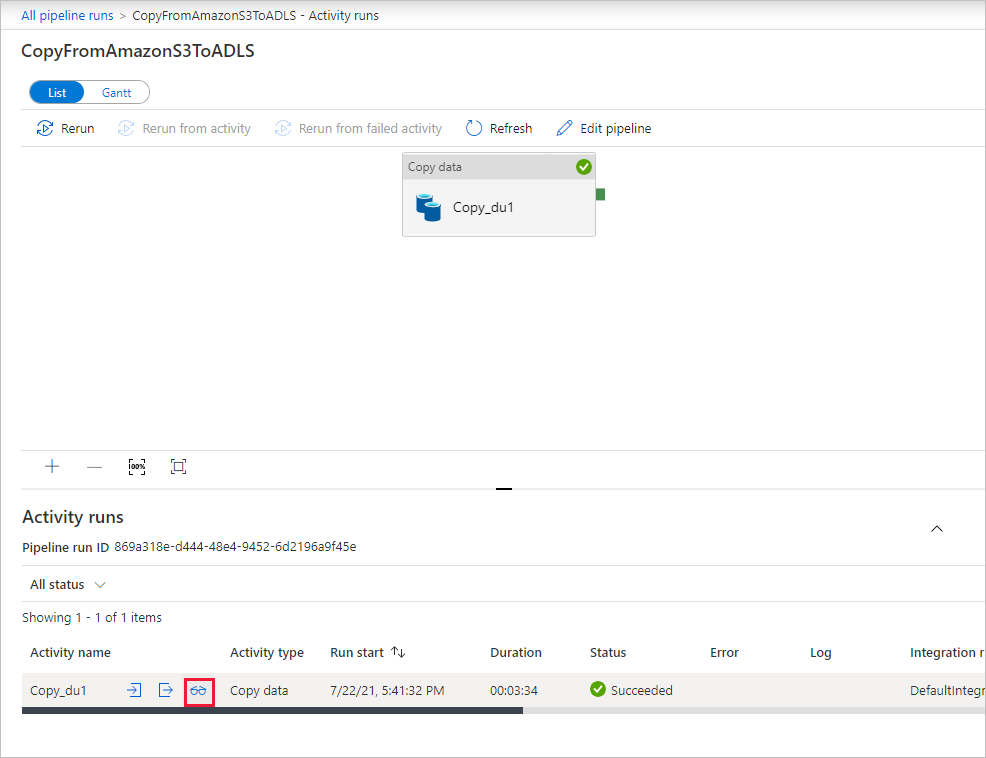
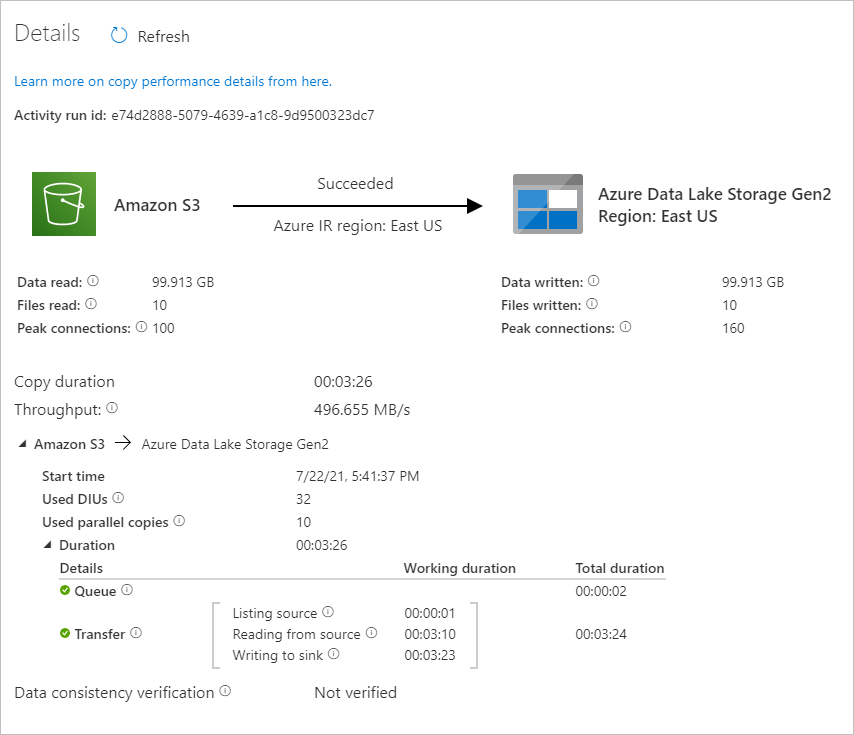
보기를 새로 고치려면 새로 고침을 선택합니다. “파이프라인 실행” 보기로 돌아가려면 위쪽에 있는 모든 파이프라인 실행을 선택합니다.
데이터가 Data Lake Storage Gen2 계정에 복사되었는지 확인합니다.