적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
Microsoft Fabric의 데이터 팩토리는 더 간단한 아키텍처, 기본 제공 AI 및 새로운 기능을 갖춘 차세대 Azure 데이터 팩토리입니다. 데이터 통합을 접하는 경우 Fabric Data Factory부터 시작합니다. 기존 ADF 워크로드는 Fabric 업그레이드하여 데이터 과학, 실시간 분석 및 보고 전반에 걸쳐 새로운 기능에 액세스할 수 있습니다.
- Fabric 무료 평가판을 시작합니다.
Microsoft Fabric의 Data Factory로 Azure Data Factory를 업그레이드합니다
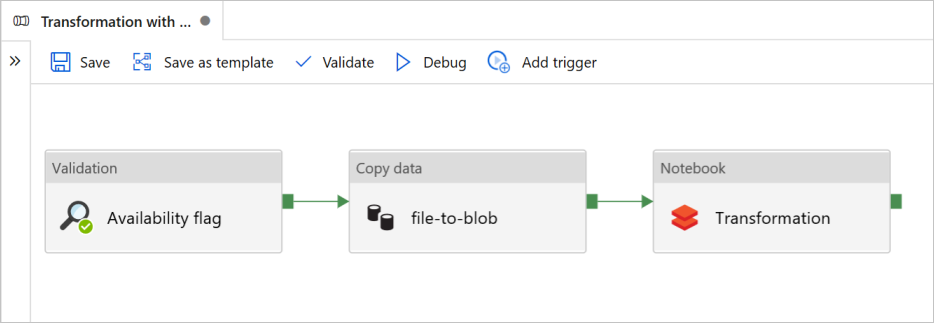
이 자습서에서는 Azure Data Factory Validation, Copy 데이터 및 Notebook 활동을 포함하는 엔드 투 엔드 파이프라인을 만듭니다.
유효성 검사를 사용하면 복사 및 분석 작업을 트리거하기 전에 원본 데이터 세트가 다운스트림에 대한 사용 준비가 됩니다.
Copy 데이터 원본 데이터 세트를 싱크 스토리지에 복제합니다. 이 데이터 세트는 Azure Databricks Notebook에서 DBFS로 탑재됩니다. 해당 방식으로 Spark를 통해 데이터 세트를 직접 사용할 수 있습니다.
Notebook은 데이터 세트를 변환하는 Databricks Notebook을 트리거합니다. 또한 처리된 폴더 또는 Azure Synapse Analytics 데이터 세트를 추가합니다.
간단히 말해, 이 자습서의 템플릿은 예약된 트리거를 만들지 않습니다. 필요한 경우에는 추가할 수 있습니다.
필수 조건
싱크로 사용하기 위해
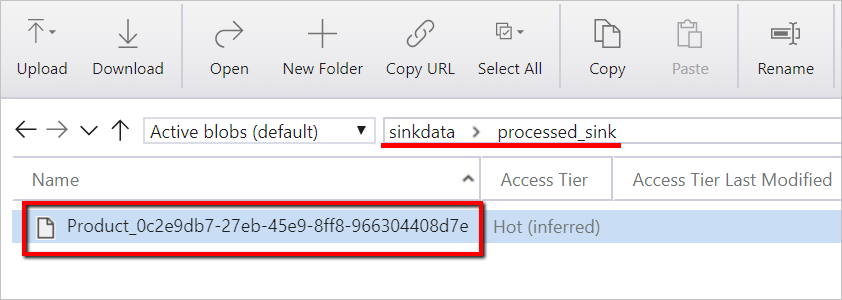
sinkdata라는 컨테이너가 있는 Azure Blob Storage 계정입니다.스토리지 계정 이름, 컨테이너 이름 및 액세스 키를 적어둡니다. 템플릿의 뒷부분에서 해당 값이 필요합니다.
Azure Databricks 작업 영역입니다.
변환을 위해 Notebook 가져오기
Databricks 워크스페이스로 변환 노트북을 가져오려면 다음을 수행합니다.
Azure Databricks 작업 영역에 로그인합니다.
작업 영역에서 폴더를 마우스 오른쪽 단추로 클릭하고 가져오기를 선택합니다.
URL에서 가져오기를 선택합니다. 문자 상자에
https://adflabstaging1.blob.core.windows.net/share/Transformations.html을 입력합니다.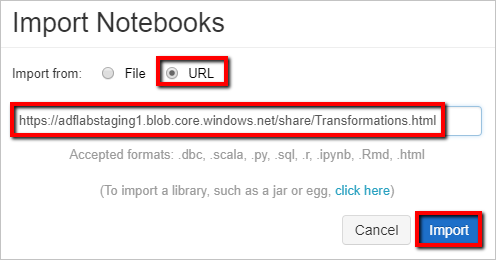
이제 당신의 스토리지 연결 정보를 사용하여 Transformation 노트북을 업데이트해 보겠습니다.
가져온 Notebook에서 다음의 코드 조각과 같이 명령 5로 이동합니다.
-
<storage name>과<access key>를 사용자의 스토리지 연결 정보로 바꿉니다. -
sinkdata컨테이너에 스토리지 계정을 사용합니다.
# Supply storageName and accessKey values storageName = "<storage name>" accessKey = "<access key>" try: dbutils.fs.mount( source = "wasbs://sinkdata\@"+storageName+".blob.core.windows.net/", mount_point = "/mnt/Data Factorydata", extra_configs = {"fs.azure.account.key."+storageName+".blob.core.windows.net": accessKey}) except Exception as e: # The error message has a long stack track. This code tries to print just the relevant line indicating what failed. import re result = re.findall(r"\^\s\*Caused by:\s*\S+:\s\*(.*)\$", e.message, flags=re.MULTILINE) if result: print result[-1] \# Print only the relevant error message else: print e \# Otherwise print the whole stack trace.-
Databricks에 액세스할 Data Factory에 대해 Databricks 액세스 토큰을 생성합니다.
- Azure Databricks 작업 영역의 위쪽 표시줄에서 Azure Databricks 사용자 이름을 선택한 다음 드롭다운에서 설정을 선택합니다.
- 개발자를 선택합니다.
- 그런 다음 액세스 토큰 옆에 있는 관리를 선택합니다.
- Generate new token(새 토큰 생성)을 탭합니다.
- (선택 사항) 나중에 이 토큰을 식별할 수 있도록 하는 설명을 입력하고 토큰의 기본 수명을 90일로 변경합니다. 수명이 없는 토큰을 만들려면(권장하지 않음) 수명(일) 상자를 비워 둡니다(공백).
- 생성을 선택합니다.
- 표시된 토큰을 안전한 위치에 복사한 다음 완료를 선택합니다.
나중에 Databricks에 연결된 서비스를 만드는 데 사용하기 위해 액세스 토큰을 저장합니다. 액세스 토큰은 dapi32db32cbb4w6eee18b7d87e45exxxxxx과 유사합니다.
이 템플릿을 사용하는 방법 알아보기
Azure Databricks 템플릿 Transformation with Azure Databricks으로 이동하여 다음 연결에 대한 새 연결된 서비스를 만듭니다.
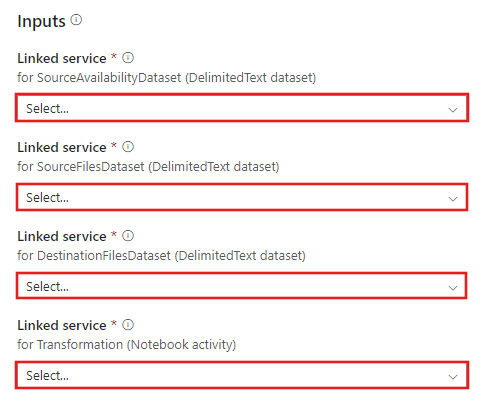
원본 Blob 연결 -원본 데이터에 액세스합니다.
이 연습에서는 원본 파일을 포함하는 공용 Blob Storage를 사용할 수 있습니다. 구성에 대한 다음 스크린샷을 참조합니다. 다음 SAS URL을 사용하여 원본 스토리지(읽기 전용 액세스)에 연결합니다.
https://storagewithdata.blob.core.windows.net/data?sv=2018-03-28&si=read%20and%20list&sr=c&sig=PuyyS6%2FKdB2JxcZN0kPlmHSBlD8uIKyzhBWmWzznkBw%3D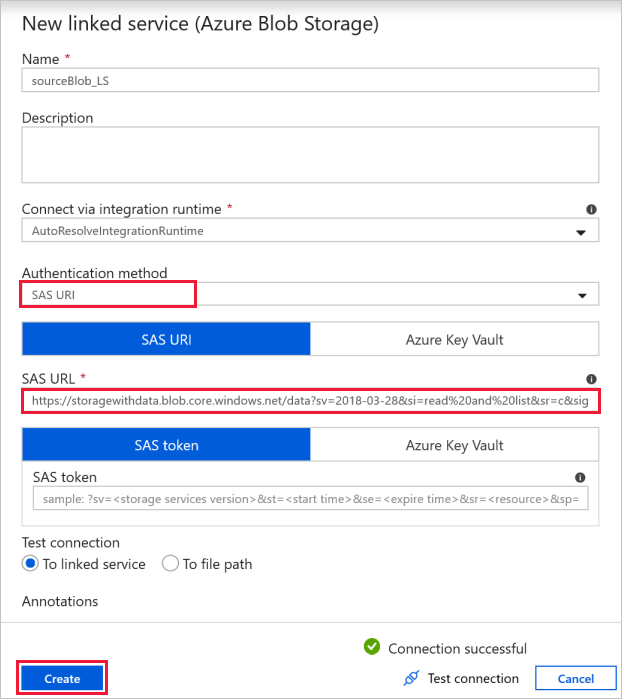
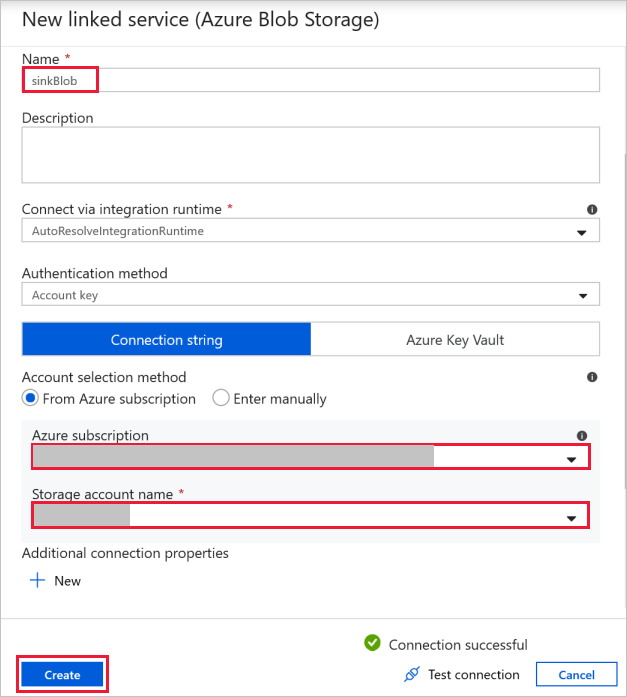
대상 Blob 연결 - 복사된 데이터를 저장하기 위해 사용합니다.
새로 열린 연결된 서비스 창에서 대상 Blob 저장소를 선택합니다.
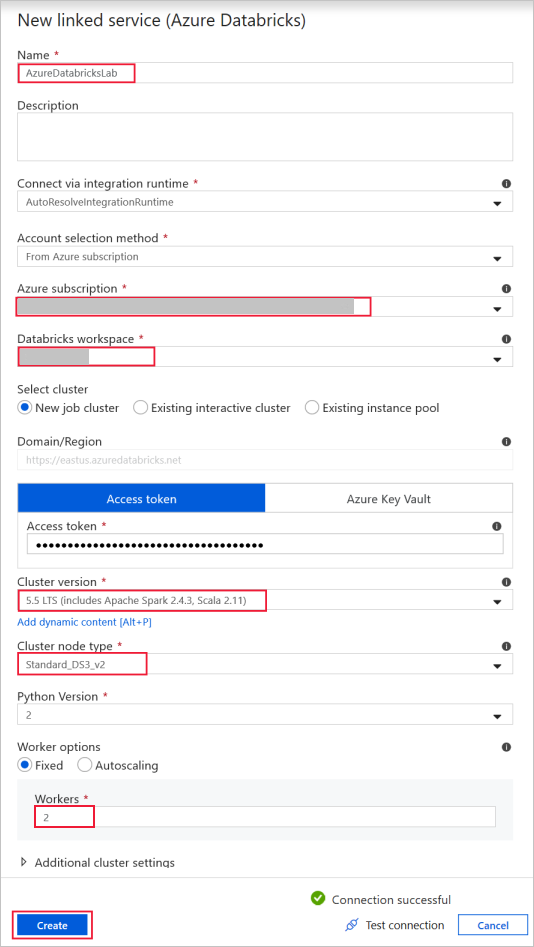
Azure Databricks - Databricks 클러스터에 연결합니다.
이전에 생성한 액세스 키를 사용하여 Databricks로 연결된 서비스를 만듭니다. 대화형 클러스터가 있는 경우 선택할 수 있습니다. 이 예제에서는 새 작업 클러스터 옵션을 사용합니다.
이 템플릿 사용을 선택합니다. 만들어진 파이프라인을 볼 수 있습니다.
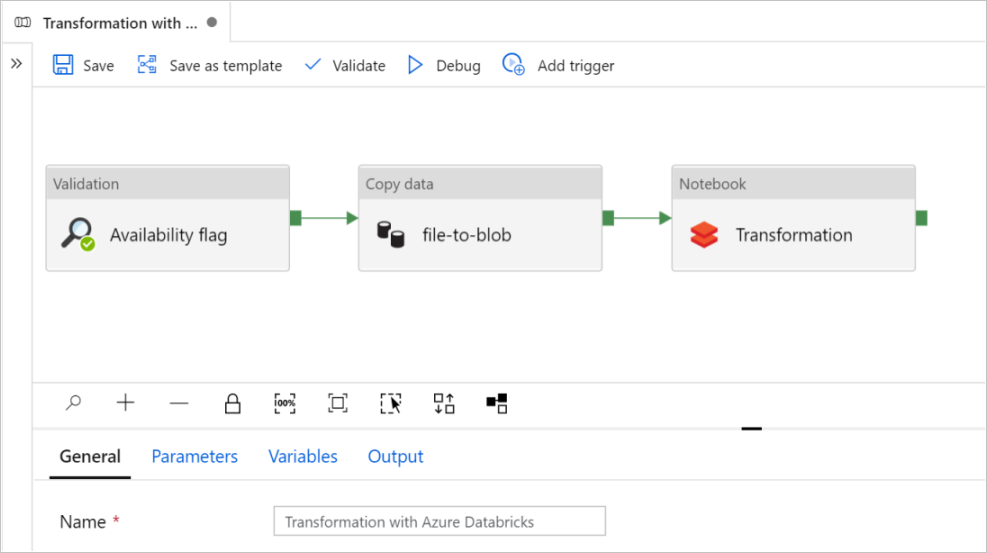
파이프라인 소개 및 구성
새 파이프라인에서 대부분의 설정은 기본값을 사용하여 자동으로 구성됩니다. 파이프라인의 구성을 검토하고 필요한 변경 작업을 수행합니다.
유효성 검사 작업 가용성 플래그에서 원본 데이터 세트 값이
SourceAvailabilityDataset이전에 만든 것으로 설정되어 있는지 확인합니다.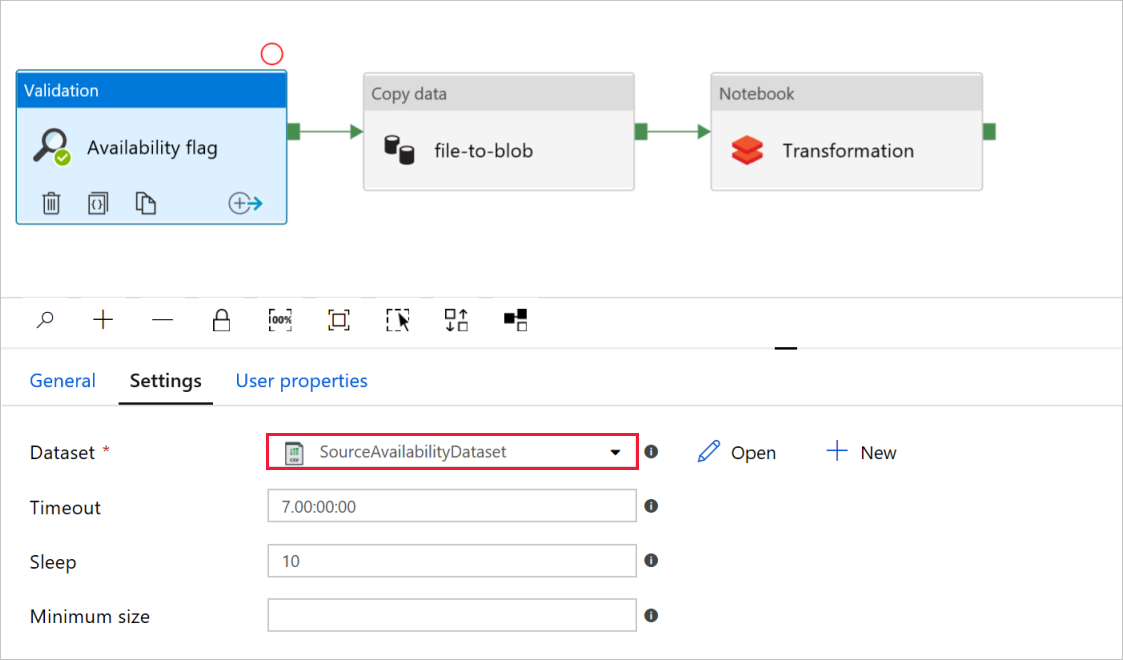
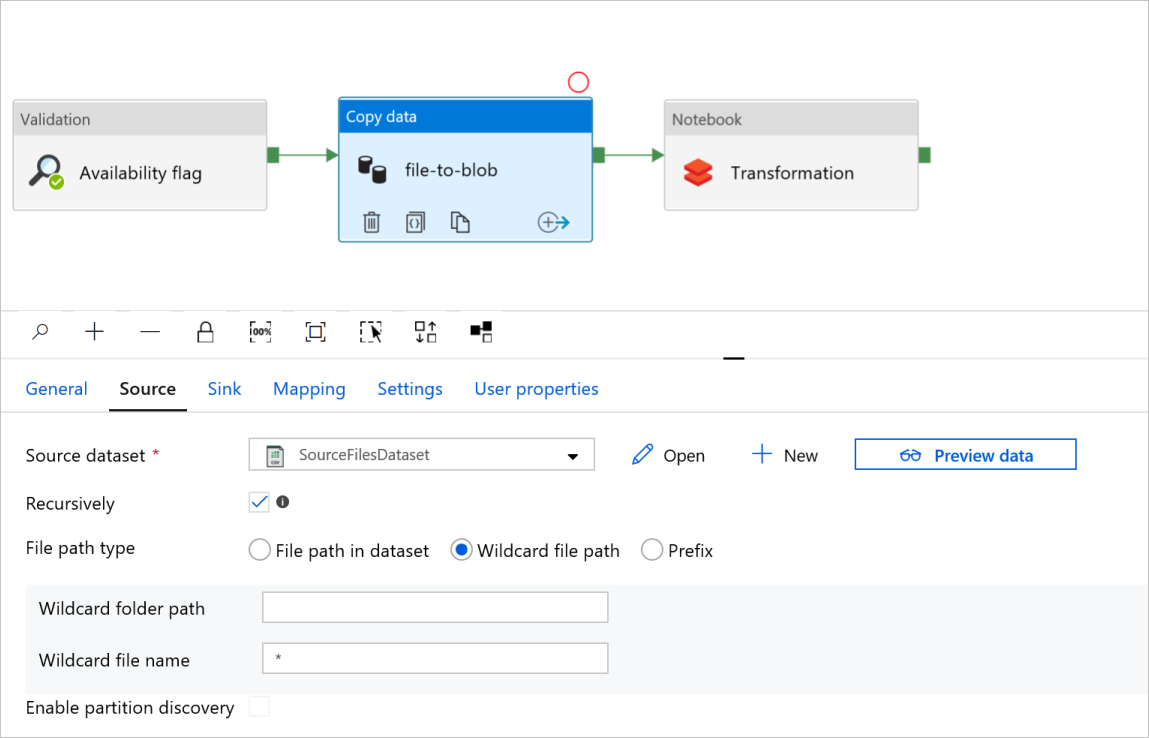
데이터 작업 파일을 Blob으로 복사에서 원본 및 싱크 탭을 선택합니다. 필요한 경우 설정을 변경합니다.
원본 탭
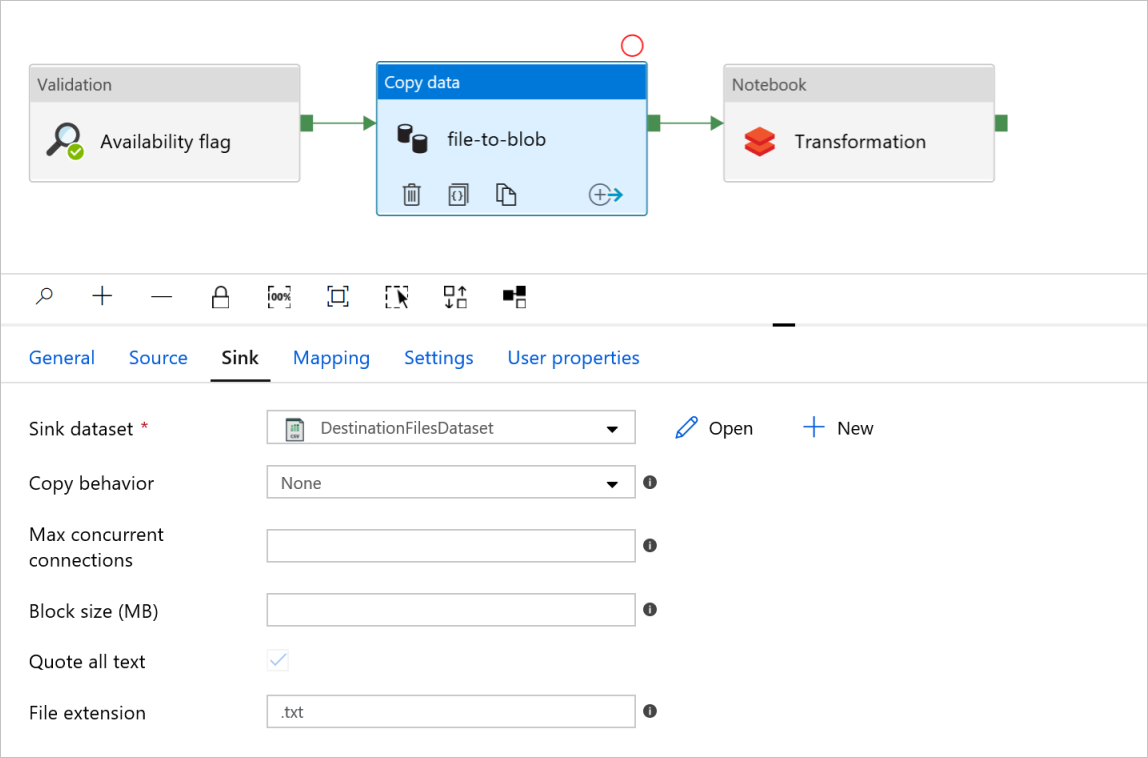
싱크 탭
Notebook 활동 변환에서 필요에 따라 경로와 설정을 검토하고 업데이트합니다.
Databricks 연결된 서비스는 다음과 같이 이전 단계의 값으로 미리 채워져야 합니다.
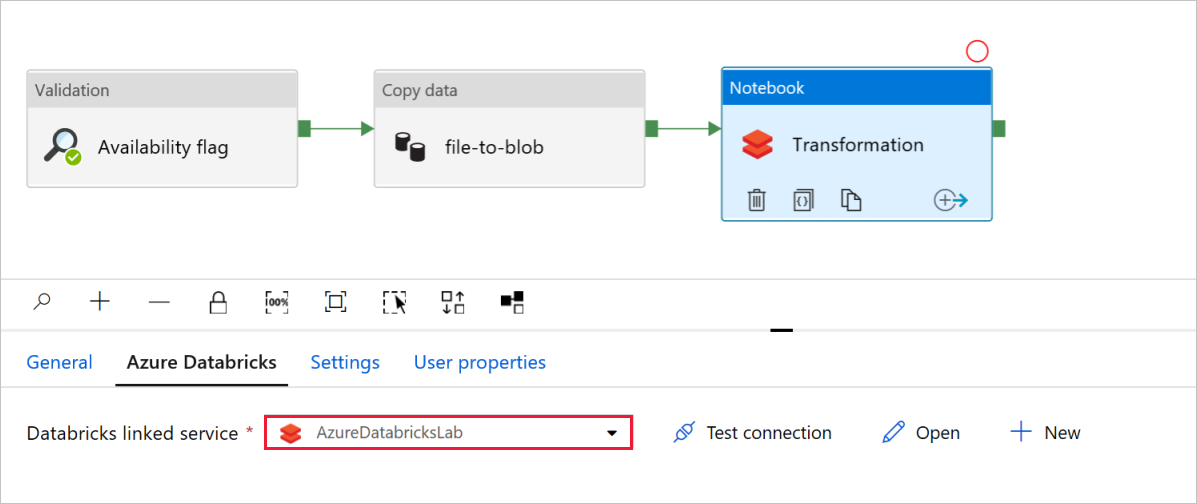
Notebook 설정을 확인하기 위해서 다음을 수행합니다.
설정 탭을 선택합니다. Notebook 경로의 경우 기본 경로가 올바른지 확인합니다. 올바른 Notebook 경로를 찾아서 선택해야 할 수 있습니다.
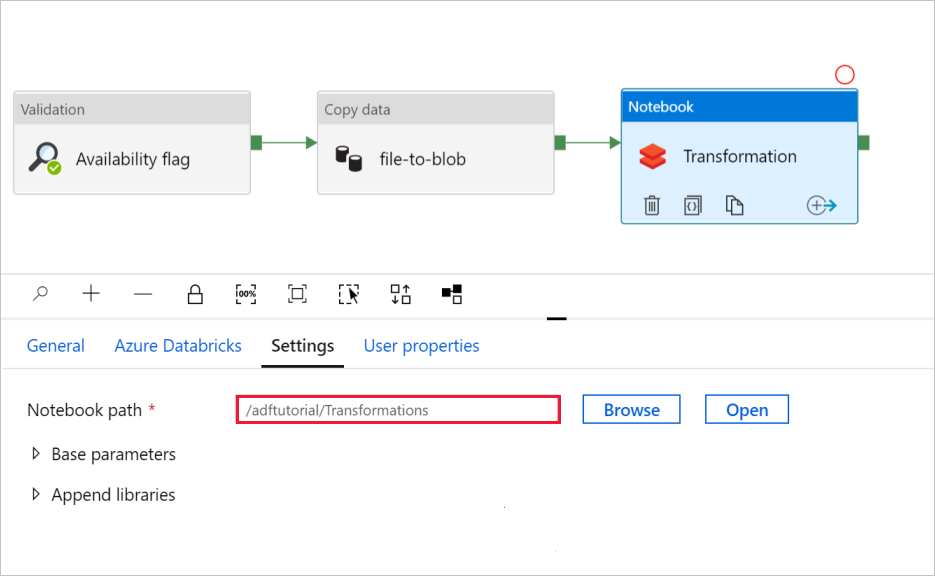
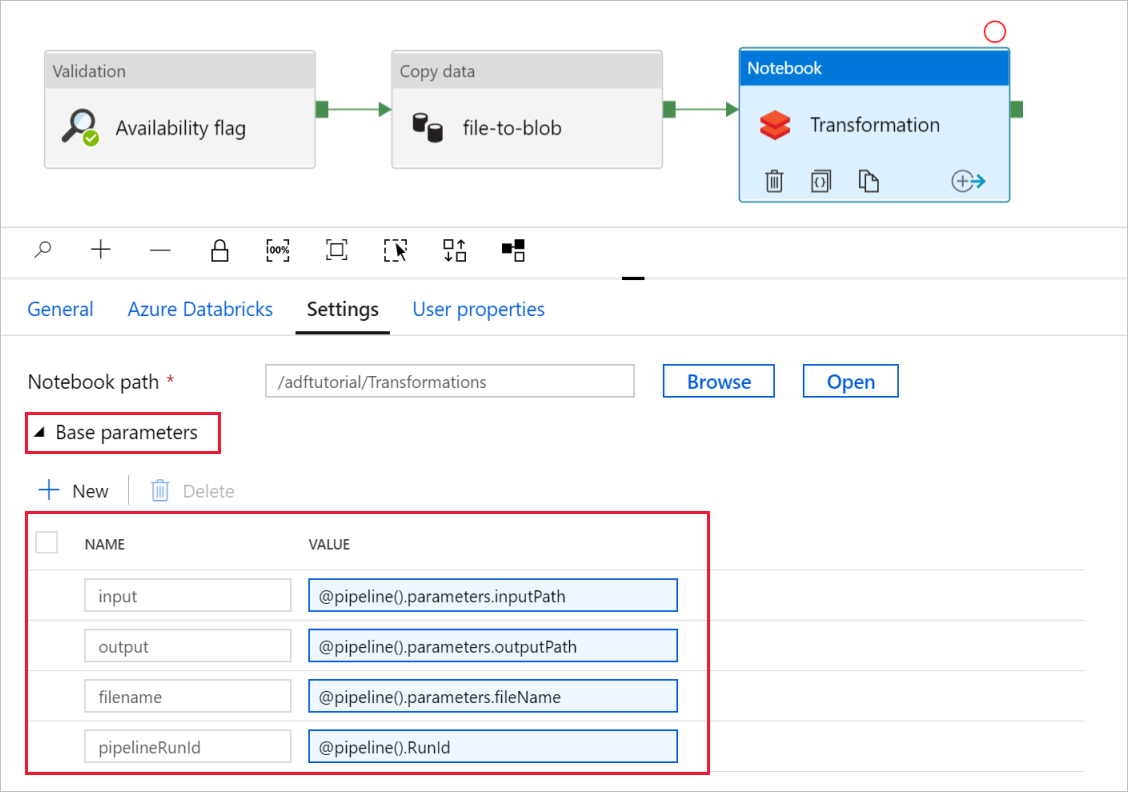
기본 매개 변수 선택기를 확장하고 다음 스크린샷에 표시된 것과 일치하는 매개 변수를 확인합니다. 해당 매개 변수는 Data Factory에서 Databricks Notebook으로 전달됩니다.
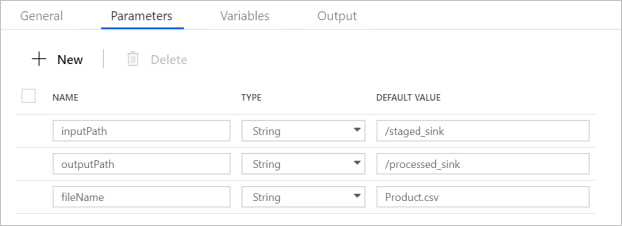
파이프라인 매개 변수가 다음 스크린샷에 표시된 것과 일치하는지 확인합니다.
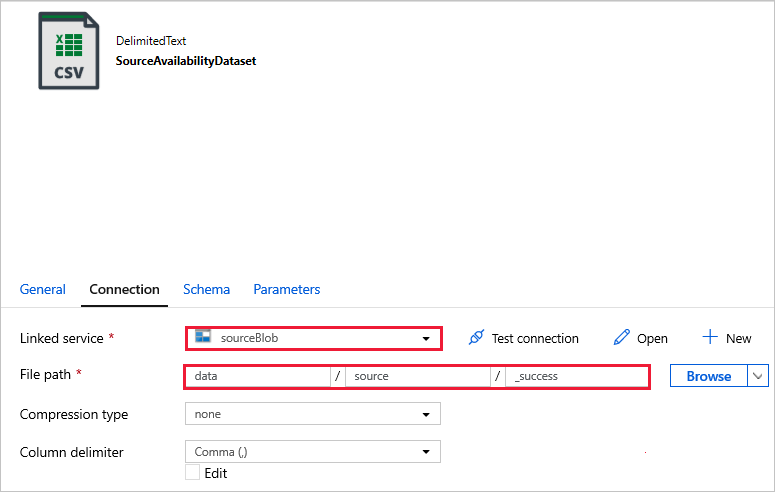
데이터 세트에 연결합니다.
참고
아래 데이터 세트에서 파일 경로가 템플릿에 자동으로 지정되었습니다. 변경이 필요한 경우, 연결 오류가 발생할 수 있으므로 컨테이너와 디렉터리에 대한 경로를 지정했는지 확인합니다.
SourceAvailabilityDataset -원본 데이터를 사용할 수 있는지 확인합니다.
SourceFilesDataset -원본 데이터에 액세스합니다.
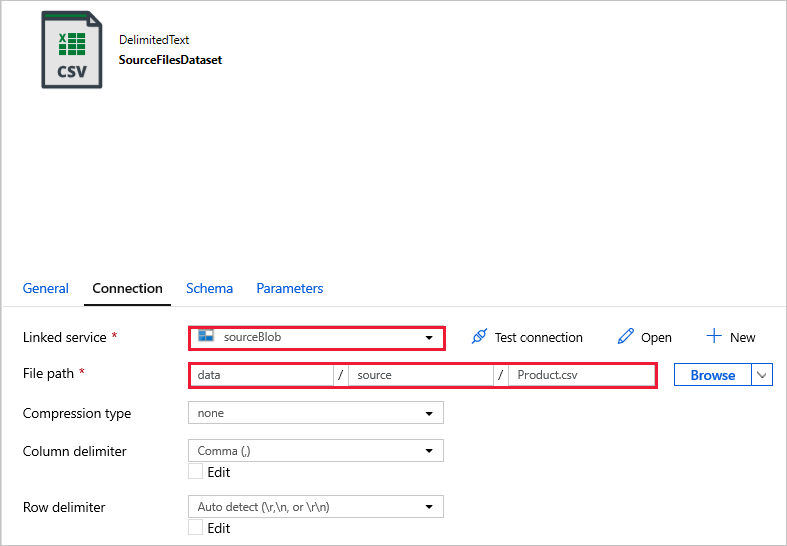
DestinationFilesDataset -데이터를 싱크 대상 위치로 복사합니다. 다음 값을 사용합니다.
이전 단계에서 만든 연결된 서비스 -
sinkBlob_LS파일 경로 -
sinkdata/staged_sink.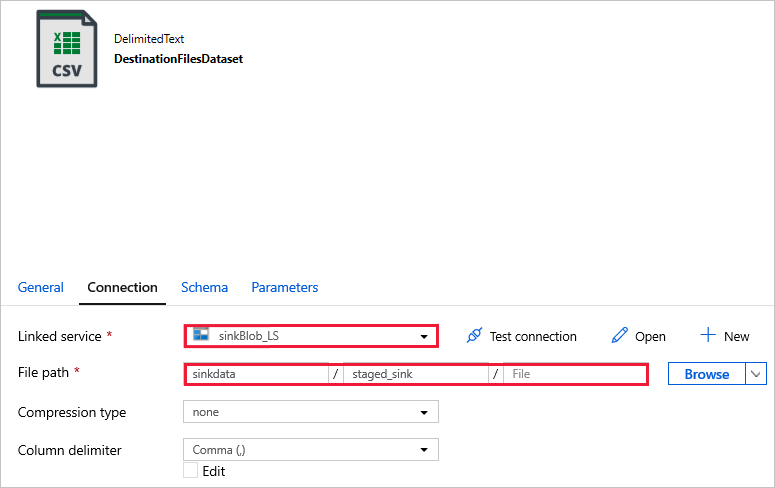
디버그를 선택하여 파이프라인을 실행합니다. 자세한 Spark 로그를 보려면 Databricks 로그 링크를 확인합니다.
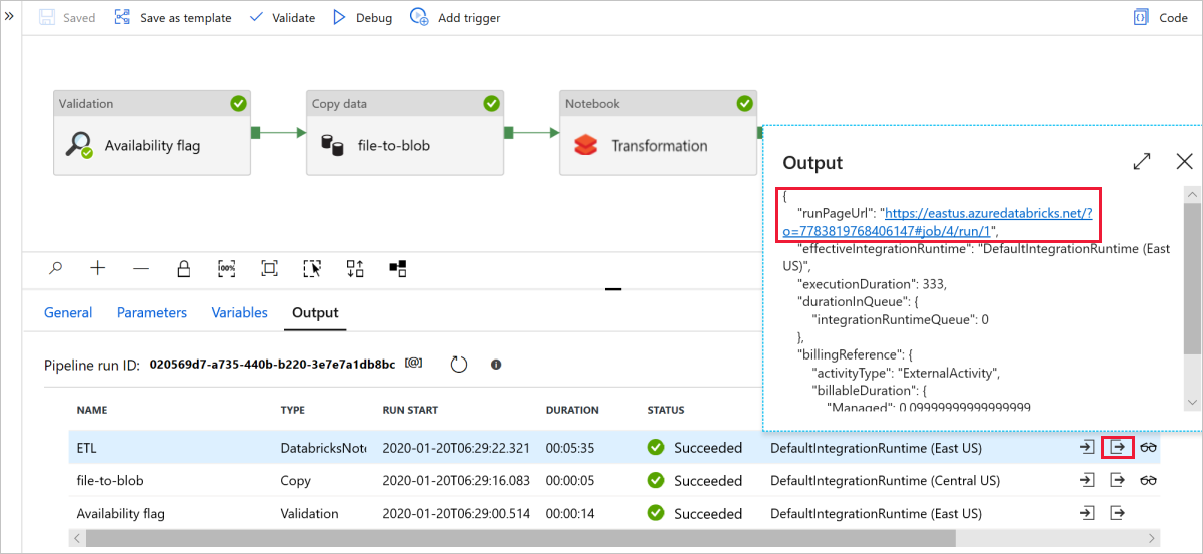
Azure Storage Explorer 사용하여 데이터 파일을 확인할 수도 있습니다.
참고
Data Factory 파이프라인 실행과 상관관계 지정을 위해 이 예제에서는 Data Factory의 파이프라인 실행 ID를 출력 폴더에 추가합니다. 이렇게 하면 각 실행에 의해 생성된 파일을 추적하는 데 도움이 됩니다.