적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
Microsoft Fabric의 데이터 팩토리는 더 간단한 아키텍처, 기본 제공 AI 및 새로운 기능을 갖춘 차세대 Azure 데이터 팩토리입니다. 데이터 통합을 접하는 경우 Fabric Data Factory부터 시작합니다. 기존 ADF 워크로드는 Fabric 업그레이드하여 데이터 과학, 실시간 분석 및 보고 전반에 걸쳐 새로운 기능에 액세스할 수 있습니다.
- Fabric 무료 평가판을 시작합니다.
Microsoft Fabric의 Data Factory로 Azure Data Factory를 업그레이드합니다
Azure Data Factory 또는 Synapse Analytics pipeline의 HDInsight MapReduce 작업은 사용자 소유의 또는 온디맨드 HDInsight 클러스터에서 MapReduce 프로그램을 호출합니다. 이 문서는 데이터 변환 및 지원되는 변환 활동의 일반적인 개요를 표시하는 데이터 변환 활동 문서에서 작성합니다.
자세한 내용은 Azure Data Factory 및 Synapse Analytics에 대한 소개 문서를 읽고 이 문서를 읽기 전에 Tutorial: 데이터 변환 자습서를 수행합니다.
HDInsight Pig 및 Hive 활동을 사용하여 파이프라인에서 HDInsight 클러스터에서 Pig/Hive 스크립트를 실행하는 방법에 대한 자세한 내용은 Pig 및 Hive를 참조하세요.
UI를 사용하여 파이프라인에 HDInsight MapReduce 작업 추가
HDInsight MapReduce 작업을 파이프라인에 사용하려면 다음 단계를 완료합니다.
파이프라인 작업 창에서 MapReduce를 검색하고 MapReduce 작업을 파이프라인 캔버스로 끌어옵니다.
아직 선택되지 않은 경우 캔버스에서 새 MapReduce 작업을 선택합니다.
HDI 클러스터 탭을 선택하여 MapReduce 작업을 실행하는 데 사용할 HDInsight 클러스터에 연결된 새 서비스를 선택하거나 만듭니다.
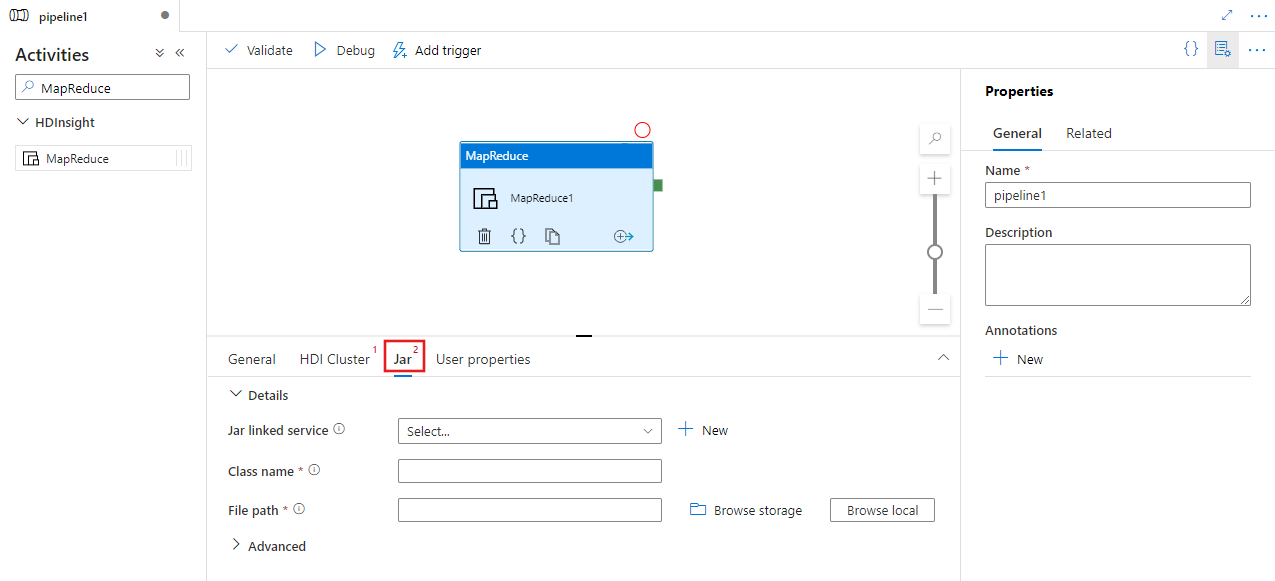
Jar 탭을 선택하여 스크립트를 호스트할 Azure Storage 계정에 새 Jar 연결된 서비스를 선택하거나 만듭니다. 실행할 클래스 이름과 스토리지 위치 내의 파일 경로를 지정합니다. Jar libs 위치, 디버깅 구성, 스크립트에 전달될 인수 및 매개 변수를 비롯한 고급 세부 정보를 구성할 수도 있습니다.
구문
{
"name": "Map Reduce Activity",
"description": "Description",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.myorg.SampleClass",
"jarLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "MyAzureStorage/jars/sample.jar",
"getDebugInfo": "Failure",
"arguments": [
"-SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
구문 세부 정보
| 속성 | 설명 | 필수 |
|---|---|---|
| 이름 | 작업의 이름 | 예 |
| 설명 | 작업이 무엇에 사용되는지 설명하는 텍스트입니다. | 아니요 |
| 종류 | MapReduce 작업의 경우 작업 유형은 HDinsightMapReduce입니다. | 예 |
| 연결된서비스명 | 연결된 서비스로 등록된 HDInsight 클러스터에 대한 참조입니다. 이 연결된 서비스에 대한 자세한 내용은 컴퓨팅 연결 서비스 문서를 참조하세요. | 예 |
| className | 실행할 클래스의 이름 | 예 |
| jarLinkedService | Jar 파일을 저장하는 데 사용되는 Azure Storage 연결된 서비스에 대한 참조입니다. 여기에서는 Azure Blob Storage 및 ADLS Gen2 연결된 서비스만 지원됩니다. 이 연결된 서비스를 지정하지 않으면 HDInsight 연결된 서비스에 정의된 Azure Storage 연결된 서비스가 사용됩니다. | 아니요 |
| 자르 파일 경로(jarFilePath) | jarLinkedService에서 참조하는 Azure Storage 저장된 Jar 파일의 경로를 제공합니다. 파일 이름은 대/소문자를 구분합니다. | 예 |
| jarlibs | jarLinkedService에 정의된 Azure Storage에 저장된 작업에서 참조된 Jar 라이브러리 파일 경로의 문자열 배열입니다. 파일 이름은 대/소문자를 구분합니다. | 아니요 |
| getDebugInfo | 로그 파일이 jarLinkedService에서 지정한 HDInsight 클러스터(또는)에서 사용하는 Azure Storage 복사되는 시기를 지정합니다. 허용되는 값: None, Always 또는 Failure. 기본값은 None입니다. | 아니요 |
| 인수 | Hadoop 작업에 대한 인수 배열을 지정합니다. 인수는 각 작업에 대한 명령줄 인수로 전달됩니다. | 아니요 |
| 정의한다 | Hive 스크립트 내에서 참조하기 위해 매개 변수를 키/값 쌍으로 지정합니다. | 아니요 |
예시
HDInsight MapReduce 작업을 사용하여 HDInsight 클러스터에서 모든 MapReduce jar 파일을 실행할 수 있습니다. 다음 파이프라인의 샘플 JSON 정의에서 HDInsight 작업은 Mahout JAR 파일을 실행하도록 구성되어 있습니다.
{
"name": "MapReduce Activity for Mahout",
"description": "Custom MapReduce to generate Mahout result",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.apache.mahout.cf.taste.hadoop.similarity.item.ItemSimilarityJob",
"jarLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "adfsamples/Mahout/jars/mahout-examples-0.9.0.2.2.7.1-34.jar",
"arguments": [
"-s",
"SIMILARITY_LOGLIKELIHOOD",
"--input",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/input",
"--output",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/output/",
"--maxSimilaritiesPerItem",
"500",
"--tempDir",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/temp/mahout"
]
}
}
arguments 섹션에 MapReduce 프로그램의 모든 인수를 지정할 수 있습니다. 런타임에 MapReduce 프레임워크의 몇 개 인수(예: mapreduce.job.tags)가 추가로 표시됩니다. MapReduce 인수로 사용자 인수를 구분하려면 다음 예제와 같이 인수로 옵션과 값을 모두 사용하는 것이 좋습니다(-s, --input, --output 등은 바로 뒤에 해당 값이 있는 옵션임).
관련 콘텐츠
다른 방법으로 데이터를 변환하는 방법을 설명하는 다음 문서를 참조하세요.