적용 대상: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
팁
Microsoft Fabric의 데이터 팩토리는 더 간단한 아키텍처, 기본 제공 AI 및 새로운 기능을 갖춘 차세대 Azure 데이터 팩토리입니다. 데이터 통합을 접하는 경우 Fabric Data Factory부터 시작합니다. 기존 ADF 워크로드는 Fabric 업그레이드하여 데이터 과학, 실시간 분석 및 보고 전반에 걸쳐 새로운 기능에 액세스할 수 있습니다.
- Fabric 무료 평가판을 시작합니다.
Microsoft Fabric의 Data Factory로 Azure Data Factory를 업그레이드합니다
데이터 팩터리의 데이터 랭글링을 사용하면 ADF에서 기본적으로 대화형 Power Query 매시업을 빌드한 다음 ADF 파이프라인 내에서 대규모로 실행할 수 있습니다.
Power Query 활동 만들기
Azure Data Factory Power Query 만드는 방법에는 두 가지가 있습니다. 한 가지 방법은 더하기 아이콘을 클릭하고 팩터리 리소스 창에서 Power Query 선택하는 것입니다.

다른 메서드는 파이프라인 캔버스의 작업 창에 있습니다. Power Query 아코디언을 열고 Power Query 활동을 캔버스로 끕니다.
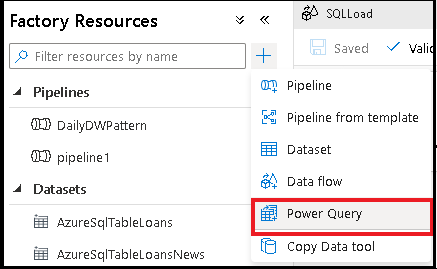
Power Query 데이터 랭글링 작업 작성
Power Query 매시업을 위해 Source 데이터 세트를 추가하세요. 기존 데이터 세트를 선택하거나 새 데이터 세트를 만들 수 있습니다. 매시업을 저장한 후 파이프라인을 만들고, Power Query 데이터 랭글링 작업을 파이프라인에 추가하고, 싱크 데이터 세트를 선택하여 ADF에 데이터 착륙 위치를 알릴 수 있습니다. 하나 이상의 원본 데이터 세트를 선택할 수 있지만 지금은 싱크가 하나만 허용됩니다. 싱크 데이터 세트 선택은 필수가 아니지만 하나 이상의 원본 데이터 세트 선택은 필수입니다.
Create 을 클릭하여 Power Query Online 매시업 편집기를 엽니다.
먼저 매시업 편집기에 대한 데이터 세트 원본을 선택합니다.

Power Query 빌드를 완료하면 저장한 다음 파이프라인을 만들 수 있습니다. 매시업을 파이프라인에 작업으로 추가해야 합니다. 싱크 데이터 세트를 만들거나 선택하여 데이터를 배치할 때입니다. 싱크된 데이터 세트의 오른쪽에 있는 두 번째 단추를 클릭하여 싱크 데이터 세트 속성을 설정할 수도 있습니다. 단일 출력 파일만 얻으려면 "최적화" 아래의 "파티션 옵션"을 "단일 파티션"으로 변경해야 합니다.

코드를 작성하지 않고 데이터 정리를 위한 Power Query를 작성합니다. 사용 가능한 함수 목록은 변환 함수를 참조하세요. ADF는 M 스크립트를 데이터 흐름 스크립트로 변환하므로 Azure Data Factory 데이터 흐름 Spark 환경을 사용하여 대규모로 Power Query 실행할 수 있습니다.

Power Query 데이터 랭글링 작업 실행 및 모니터링
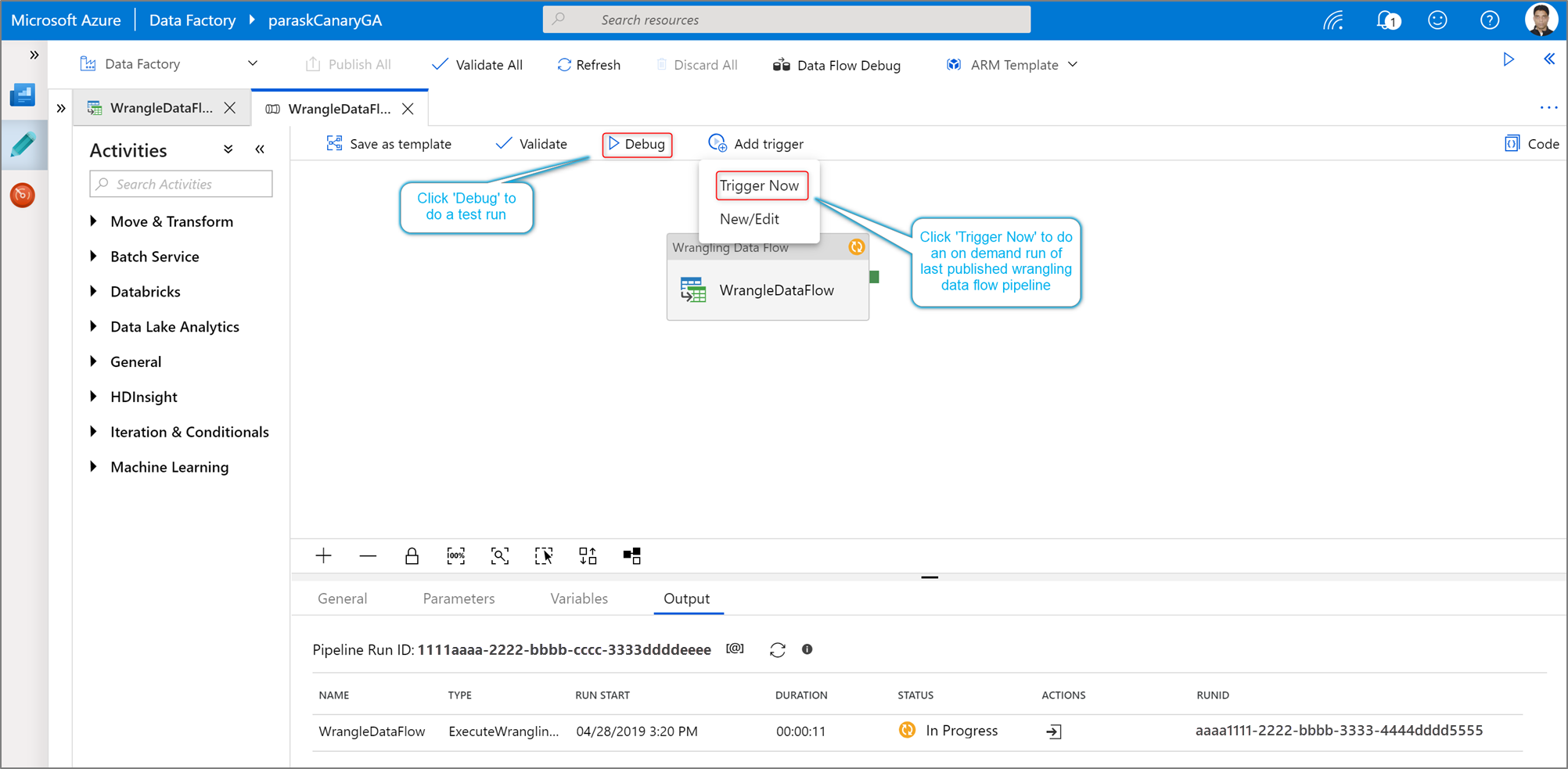
Power Query 작업의 파이프라인 디버그 실행을 실행하려면 파이프라인 캔버스에서 Debug 클릭합니다. 파이프라인을 게시하면 지금 트리거로 마지막에 게시된 파이프라인의 주문형 실행을 실행합니다. Power Query 파이프라인은 모든 기존 Azure Data Factory 트리거로 예약할 수 있습니다.
<c0><sb0>Power Query 데이터 준비 작업을 추가하는 방법을 보여주는 스크린샷입니다.</sb0></c0></c1>
트리거된 Power Query 작업 실행의 출력을 시각화하려면 모니터 탭으로 이동합니다.
관련 콘텐츠
매핑 데이터 흐름 만들기 방법에 대해 알아봅니다.