이 문서에서는 Azure Databricks UI의 네이티브 컴퓨팅 메트릭 도구를 사용하여 주요 하드웨어 및 Spark 메트릭을 수집하는 방법을 설명합니다. 메트릭 UI는 다목적 및 작업 컴퓨팅에 사용할 수 있습니다.
참고事项
Notebook 및 작업을 위한 서버리스 컴퓨팅은 메트릭 UI 대신 쿼리 인사이트를 활용합니다. 서버리스 컴퓨팅 메트릭에 대한 자세한 내용은 쿼리 인사이트 보기를 참조 하세요.
메트릭은 일반적인 지연 시간이 1분 미만인 거의 실시간으로 사용할 수 있습니다. 메트릭은 고객의 스토리지가 아닌 Azure Databricks 관리 스토리지에 저장됩니다.
이러한 새로운 메트릭은 Ganglia와 어떻게 다른가요?
새 컴퓨팅 메트릭 UI는 Spark 사용량 및 내부 Databricks 프로세스를 포함하여 클러스터의 리소스 사용량을 보다 포괄적으로 볼 수 있습니다. 반면, Ganglia UI는 Spark 컨테이너 사용량만 측정합니다. 이러한 차이로 인해 두 인터페이스 간의 메트릭 값이 불일치할 수 있습니다.
컴퓨팅 메트릭 UI에 액세스
컴퓨팅 메트릭 UI를 보려면 다음을 수행합니다.
- 사이드바에서 컴퓨팅을 클릭합니다.
- 메트릭을 보려는 컴퓨팅 리소스를 클릭합니다.
- 메트릭 탭을 클릭합니다.
하드웨어 메트릭은 기본적으로 표시됩니다. Spark 메트릭을 보려면 하드웨어
기간별로 메트릭 필터링
날짜 선택기 필터를 사용하여 시간 범위를 선택하여 기록 메트릭을 볼 수 있습니다. 메트릭은 1분마다 수집되므로 지난 30일의 일, 시간 또는 분 범위를 기준으로 필터링할 수 있습니다. 달력 아이콘을 클릭하여 미리 정의된 데이터 범위에서 선택하거나 텍스트 상자 내부를 클릭하여 사용자 지정 값을 정의합니다.
참고事项
차트에 표시되는 시간 간격은 보는 시간에 따라 조정됩니다. 대부분의 메트릭은 현재 보고 있는 시간 간격에 따라 평균입니다.
새로 고침 단추를 클릭하여 최신 메트릭을 가져올 수도 있습니다.
노드 수준에서 메트릭 보기
컴퓨팅 드롭다운 메뉴를 클릭하고 메트릭을 보려는 노드를 선택하여 개별 노드에 대한 메트릭을 볼 수 있습니다. GPU 메트릭은 개별 노드 수준에서만 사용할 수 있습니다. 개별 노드에는 Spark 메트릭을 사용할 수 없습니다.
참고事项
특정 노드를 선택하지 않으면 클러스터 내의 모든 노드(드라이버 포함)에 대해 평균 결과가 계산됩니다.
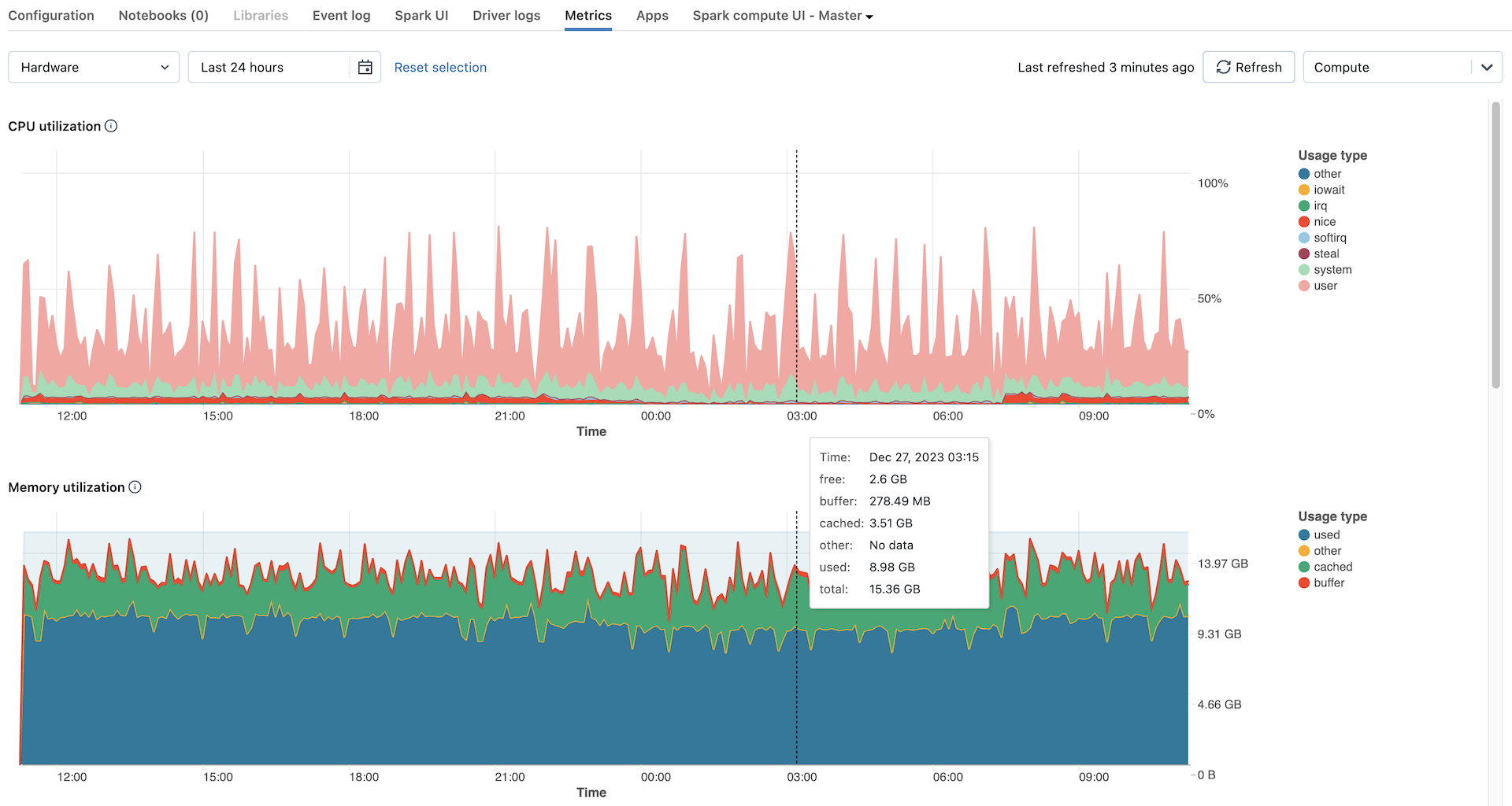
하드웨어 메트릭 차트
컴퓨팅 메트릭 UI에서 볼 수 있는 하드웨어 메트릭 차트는 다음과 같습니다.
- 서버 부하 분산: 이 차트는 각 노드에 대해 지난 1분 동안의 CPU 사용률을 보여줍니다.
-
CPU 사용률: 총 CPU 초 비용을 기준으로 각 모드에서 CPU가 소요된 시간의 백분율입니다. 메트릭은 차트에 표시되는 시간 간격을 기준으로 평균을 계산합니다. 추적된 모드는 다음과 같습니다.
- 게스트: VM을 실행하는 경우 해당 VM에서 사용하는 CPU
- iowait: I/O를 기다리는 데 소요된 시간
- 유휴: CPU에 수행할 작업이 없는 시간
- irq: 인터럽트 요청에 소요된 시간
- nice: 프로세스 우선 순위가 다른 작업보다 낮은 경우, 즉 'niceness' 값이 양수일 때 사용되는 시간
- softirq: 소프트웨어 인터럽트 요청에 소요된 시간
- 훔치기: VM인 경우 CPU에서 다른 VM이 "훔친" 시간
- system: 커널에 소요된 시간
- user: userland에서 소요된 시간
-
메모리 사용률: 각 모드별 총 메모리 사용량(바이트 단위로 측정되고 차트에 표시되는 시간 간격에 따라 평균)입니다. 다음 사용 유형이 추적됩니다.
- used: 사용된 메모리(컴퓨팅에서 실행되는 백그라운드 프로세스에서 사용되는 메모리 포함)
- free: 사용되지 않는 메모리
- 버퍼: 커널 버퍼에서 사용되는 메모리
- cached: OS 수준의 파일 시스템 캐시에서 사용되는 메모리
- 메모리 교환 사용률: 각 모드별 총 메모리 스왑 사용량(바이트 단위로 측정되고 차트에 표시되는 시간 간격에 따라 평균)입니다.
- 사용 가능한 파일 시스템 공간: 각 탑재 지점의 총 파일 시스템 사용량(바이트 단위로 측정되고 차트에 표시되는 시간 간격에 따라 평균)입니다.
- 네트워크를 통해 수신됨: 각 디바이스에서 네트워크를 통해 수신된 바이트 수이며 차트에 표시되는 시간 간격을 기준으로 평균을 계산합니다.
- 네트워크를 통해 전송됨: 각 디바이스에서 네트워크를 통해 전송되는 바이트 수이며 차트에 표시되는 시간 간격에 따라 평균을 계산합니다.
- 활성 노드 수: 지정된 컴퓨팅에 대한 모든 타임스탬프의 활성 노드 수를 보여 줍니다.
Spark 메트릭 차트
컴퓨팅 메트릭 UI에서 볼 수 있는 Spark 메트릭 차트는 다음과 같습니다.
- 서버 부하 분산: 이 차트는 각 노드에 대해 지난 1분 동안의 CPU 사용률을 보여줍니다.
- 활성 작업: 지정된 시간에 실행되는 총 작업 수이며 차트에 표시되는 시간 간격을 기준으로 평균을 계산합니다.
- 실패한 총 작업: 실행기에서 실패한 총 작업 수이며 차트에 표시되는 시간 간격을 기준으로 평균을 계산합니다.
- 완료된 총 작업 수: 실행기에서 완료된 총 작업 수이며 차트에 표시되는 시간 간격을 기준으로 평균을 계산합니다.
- 총 작업수: 실행기의 모든 작업(실행 중, 실패 및 완료)의 총 수이며 차트에 표시되는 시간 간격을 기준으로 평균을 계산합니다.
-
총 순서 섞기 읽기: 차트에 표시되는 시간 간격에 따라 바이트 단위로 측정되고 평균을 계산한 순서 섞기 읽기 데이터의 총 크기입니다.
Shuffle read는 단계의 시작 부분에 있는 모든 실행기에서 직렬화된 읽기 데이터의 합계를 의미합니다. -
총 순서 섞기 쓰기: 차트에 표시되는 시간 간격에 따라 바이트 단위로 측정되고 평균을 계산한 순서 섞기 쓰기 데이터의 총 크기입니다.
Shuffle Write는 전송하기 전에 모든 실행기에서 기록된 모든 직렬화된 데이터의 합계입니다(일반적으로 단계의 끝에 표시됨). - 총 작업 기간: JVM이 실행기에서 작업을 실행하는 데 소요된 총 경과 시간이며, 차트에 표시되는 시간 간격을 기준으로 초 단위로 측정되고 평균이 계산됩니다.
GPU 메트릭 차트
참고事项
GPU 메트릭은 Databricks Runtime ML 13.3 이상에서만 사용할 수 있습니다.
컴퓨팅 메트릭 UI에서 볼 수 있는 GPU 메트릭 차트는 다음과 같습니다.
- 서버 부하 분산: 이 차트는 각 노드에 대해 지난 1분 동안의 CPU 사용률을 보여줍니다.
- GPU 디코더별 사용률: 차트에 표시되는 시간 간격에 따라 평균으로 계산된 GPU 디코더 사용률입니다.
- GPU별 인코더 사용률: 차트에 표시되는 시간 간격에 따라 평균으로 계산된 GPU 인코더 사용률입니다.
- GPU 프레임당 버퍼 메모리 사용률 바이트: 차트에 표시되는 시간 간격에 따라 프레임 버퍼 메모리 사용률(바이트 단위로 측정되고 평균)입니다.
- GPU당 메모리 사용률: 차트에 표시되는 시간 간격에 따라 평균으로 계산된 GPU 메모리 사용률의 비율입니다.
- GPU별 사용률: 차트에 표시되는 시간 간격에 따라 평균으로 계산된 GPU 사용률입니다.
문제 해결
기간 동안 불완전하거나 누락된 메트릭이 표시되는 경우 다음 문제 중 하나일 수 있습니다.
- 메트릭 쿼리 및 저장을 담당하는 Databricks 서비스의 중단.
- 고객 측의 네트워크 문제입니다.
- 컴퓨팅이 현재 비정상 상태이거나 과거에 비정상 상태였습니다.