델타 테이블 스트리밍 읽기 및 쓰기
Delta Lake는 readStream 및 writeStream을 통해 Spark 구조적 스트리밍과 긴밀하게 통합됩니다. Delta Lake는 다음을 포함하여 일반적으로 스트리밍 시스템 및 파일과 관련된 많은 제한 사항을 극복합니다.
- 짧은 대기 시간 수집으로 생성된 작은 파일을 병합합니다.
- 둘 이상의 스트림(또는 동시 일괄 처리 작업)을 사용하여 "정확히 한 번" 처리를 유지 관리합니다.
- 스트림의 원본으로 파일을 사용할 때 새로운 파일을 효율적으로 검색합니다.
참고 항목
이 문서에서는 Delta Lake 테이블을 스트리밍 원본 및 싱크로 사용하는 방법에 대해 설명합니다. Databricks SQL에서 스트리밍 테이블을 사용하여 데이터를 로드하는 방법을 알아보려면 Databricks SQL에서 스트리밍 테이블을 사용하여 데이터 로드를 참조하세요.
Delta Lake를 사용한 스트림 정적 조인에 대한 자세한 내용은 Stream-static 조인을 참조 하세요.
원본으로서의 Delta 테이블
구조적 스트리밍은 델타 테이블을 증분 방식으로 읽습니다. 스트리밍 쿼리가 델타 테이블에 대해 활성화되어 있는 동안 새 테이블 버전이 원본 테이블에 커밋될 때 새 레코드가 멱등하게 처리됩니다.
다음 코드 예제에서는 테이블 이름 또는 파일 경로를 사용하여 스트리밍 읽기를 구성하는 방법을 보여 줍니다.
Python
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Scala
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Important
테이블에 대해 스트리밍 읽기가 시작된 후 Delta 테이블에 대한 스키마가 변경되면 쿼리가 실패합니다. 대부분의 스키마 변경의 경우 스트림을 다시 시작하여 스키마 불일치를 해결하고 처리를 계속할 수 있습니다.
Databricks Runtime 12.2 LTS 이하에서는 열 이름 바꾸기 또는 삭제와 같은 비가산적 스키마 진화를 거친 열 매핑이 활성화된 델타 테이블에서 스트리밍할 수 없습니다. 자세한 내용은 열 매핑 및 스키마 변경 내용이 포함된 스트리밍을 참조하세요.
입력 속도 제한
마이크로 일괄 처리를 제어하는 데 사용할 수 있는 옵션은 다음과 같습니다.
maxFilesPerTrigger: 모든 마이크로 일괄 처리에서 고려할 새 파일의 수입니다. 기본값은 1000입니다.maxBytesPerTrigger: 각 마이크로 일괄 처리에서 처리되는 데이터의 양입니다. 이 옵션은 "소프트 최대"를 설정합니다. 즉, 일괄 처리는 대략 이 규모의 데이터를 처리하며, 가장 작은 입력 단위가 이 제한보다 큰 경우 스트리밍 쿼리를 진행하기 위해 제한보다 더 많이 처리할 수 있습니다. 이는 기본적으로 설정되어 있지 않습니다.
maxBytesPerTrigger를 maxFilesPerTrigger와 함께 사용하는 경우 마이크로 일괄 처리는 maxFilesPerTrigger 또는 maxBytesPerTrigger 제한에 도달할 때까지 데이터를 처리합니다.
참고 항목
구성으로 인해 logRetentionDuration원본 테이블 트랜잭션이 클린 스트리밍 쿼리가 해당 버전을 처리하려고 하는 경우 기본적으로 쿼리는 데이터 손실을 방지하지 못합니다. 손실된 데이터를 무시하고 처리를 계속하는 false 옵션을 failOnDataLoss 설정할 수 있습니다.
Delta Lake CDC(변경 데이터 캡처) 피드 스트리밍
Delta Lake 변경 데이터 피드 는 업데이트 및 삭제를 포함하여 델타 테이블의 변경 내용을 기록합니다. 사용하도록 설정하면 변경 데이터 피드에서 스트리밍하고 논리를 작성하여 삽입, 업데이트 및 삭제를 다운스트림 테이블로 처리할 수 있습니다. 변경 데이터 피드 데이터 출력은 설명하는 델타 테이블과 약간 다르지만 medallion 아키텍처의 다운스트림 테이블에 증분 변경 내용을 전파하는 솔루션을 제공합니다.
Important
Databricks Runtime 12.2 LTS 이하에서는 열 이름 바꾸기 또는 삭제와 같은 비가산적 스키마 진화를 겪은 열 매핑이 활성화된 Delta 테이블의 변경 데이터 피드에서 스트리밍할 수 없습니다. 열 매핑 및 스키마 변경 내용이 포함된 스트리밍을 참조하세요.
업데이트 및 삭제 무시
구조적 스트리밍은 추가가 아닌 입력을 처리하지 않으며 원본으로 사용되는 테이블에서 수정이 발생하면 예외를 throw합니다. 다운스트림으로 자동 전파될 수 없는 변경 내용을 처리하기 위한 두 가지 주요 전략이 있습니다.
- 출력과 검사점을 삭제하고 스트림을 처음부터 다시 시작할 수 있습니다.
- 다음 두 옵션 중 하나를 설정할 수 있습니다.
ignoreDeletes: 파티션 경계에서 데이터를 삭제하는 트랜잭션을 무시합니다.skipChangeCommits: 기존 레코드를 삭제하거나 수정하는 트랜잭션을 무시합니다.skipChangeCommits는ignoreDeletes를 포함합니다.
참고 항목
Databricks Runtime 12.2 LTS 이상 skipChangeCommits 에서는 이전 설정을 ignoreChanges더 이상 사용하지 않습니다. Databricks Runtime 11.3 LTS 이하 ignoreChanges 에서 유일하게 지원되는 옵션입니다.
ignoreChanges의 의미 체계는 skipChangeCommits의 의미 체계와 크게 다릅니다. ignoreChanges를 사용하도록 설정된 경우 원본 테이블의 다시 작성된 데이터 파일은 UPDATEMERGE INTO, DELETE(파티션 내), 또는 OVERWRITE와 같은 데이터 변경 작업 후에 다시 내보내집니다. 변경되지 않은 행은 새 행과 함께 내보내지는 경우가 많으므로 다운스트림 소비자는 중복을 처리할 수 있어야 합니다. 삭제는 다운스트림으로 전파되지 않습니다. ignoreChanges는 ignoreDeletes를 포함합니다.
skipChangeCommits는 파일 변경 작업을 완전히 무시합니다. UPDATE, MERGE INTO, DELETE 및 OVERWRITE와 같은 데이터 변경 작업으로 인해 원본 테이블에서 다시 작성된 데이터 파일은 완전히 무시됩니다. 업스트림 원본 테이블의 변경 내용을 반영하려면 별도의 논리를 구현하여 이러한 변경 내용을 전파해야 합니다.
구성된 ignoreChanges 워크로드는 알려진 의미 체계를 사용하여 계속 작동하지만 Databricks는 모든 새 워크로드에 사용하는 skipChangeCommits 것이 좋습니다. 워크로드를 ignoreChanges 마이그레이션하려면 skipChangeCommits 리팩터링 논리가 필요합니다.
예시
예를 들어, date로 파티션된 date, user_email 및 action 열이 있는 user_events 테이블이 있다고 가정합니다. user_events 테이블에서 스트리밍하고 GDPR로 인해 테이블에서 데이터를 삭제해야 합니다.
파티션 경계에서 삭제하는 경우(즉, WHERE이 파티션 열에 있음) 파일은 이미 값별로 분할되어 있으므로 삭제 시 해당 파일이 메타데이터에서 드롭됩니다. 전체 데이터 파티션을 삭제하는 경우 다음을 사용할 수 있습니다.
spark.readStream.format("delta")
.option("ignoreDeletes", "true")
.load("/tmp/delta/user_events")
여러 파티션에서 데이터를 삭제하는 경우(이 예제에서는 필터링 user_email) 다음 구문을 사용합니다.
spark.readStream.format("delta")
.option("skipChangeCommits", "true")
.load("/tmp/delta/user_events")
UPDATE 문으로 user_email을 업데이트하면 문제의 user_email이 포함된 파일이 다시 작성됩니다. 변경된 데이터 파일을 무시하는 데 사용합니다 skipChangeCommits .
초기 위치 지정
다음 옵션을 사용하여 전체 테이블을 처리하지 않고 Delta Lake 스트리밍 원본의 시작점을 지정할 수 있습니다.
startingVersion: 시작할 Delta Lake 버전입니다. Databricks는 대부분의 워크로드에 대해 이 옵션을 생략하는 것이 좋습니다. 설정하지 않으면 스트림은 현재 테이블의 전체 스냅샷 포함하여 사용 가능한 최신 버전에서 시작됩니다.지정한 경우 스트림은 지정된 버전(포함)으로 시작하는 Delta 테이블에 대한 모든 변경 내용을 읽습니다. 지정된 버전을 더 이상 사용할 수 없으면 스트림이 시작되지 않습니다. 커밋 버전은 DESCRIBE HISTORY 명령 출력의
version열에서 얻을 수 있습니다.최신 변경 내용만 반환하려면 .를 지정합니다
latest.startingTimestamp: 시작할 타임스탬프입니다. 타임스탬프(포함)에 커밋된 모든 테이블 변경 내용은 스트리밍 판독기에서 읽습니다. 제공된 타임스탬프가 모든 테이블 커밋 앞에 오는 경우 스트리밍 읽기는 사용 가능한 가장 빠른 타임스탬프로 시작됩니다. 다음 중 하나입니다.- 타임스탬프 문자열입니다. 예들 들어
"2019-01-01T00:00:00.000Z"입니다. - 날짜 문자열입니다. 예들 들어
"2019-01-01"입니다.
- 타임스탬프 문자열입니다. 예들 들어
두 옵션을 동시에 설정할 수 없습니다. 새 스트리밍 쿼리를 시작할 때만 적용됩니다. 스트리밍 쿼리가 시작되고 진행 상황이 검사점에 기록된 경우 이러한 옵션은 무시됩니다.
Important
지정된 버전 또는 타임스탬프에서 스트리밍 원본을 시작할 수 있지만 스트리밍 원본의 스키마는 항상 Delta 테이블의 최신 스키마입니다. 지정된 버전 또는 타임스탬프 이후에 Delta 테이블에 호환되지 않는 스키마 변경 내용이 없는지 확인해야 합니다. 그렇지 않으면 잘못된 스키마로 데이터를 읽을 때 스트리밍 원본이 잘못된 결과를 반환할 수 있습니다.
예시
예를 들어, 테이블 user_events가 있다고 가정합니다. 버전 5 이후의 변경 내용을 읽으려면 다음을 사용합니다.
spark.readStream.format("delta")
.option("startingVersion", "5")
.load("/tmp/delta/user_events")
2018년 10월 18일 이후의 변경 내용을 읽으려면 다음을 사용합니다.
spark.readStream.format("delta")
.option("startingTimestamp", "2018-10-18")
.load("/tmp/delta/user_events")
데이터 삭제 없이 초기 스냅샷 처리
참고 항목
이 기능은 Databricks Runtime 11.3 LTS 이상에서 사용할 수 있습니다. 이 기능은 공개 미리 보기 상태입니다.
델타 테이블을 스트림 원본으로 사용하는 경우 쿼리가 먼저 테이블에 있는 모든 데이터를 처리합니다. 이 버전의 델타 테이블을 초기 스냅샷이라고 합니다. 기본적으로 델타 테이블의 데이터 파일은 마지막으로 수정된 파일을 기준으로 처리됩니다. 그러나 마지막 수정 시간이 반드시 레코드 이벤트 시간 순서를 나타내는 것은 아닙니다.
워터마크가 정의된 상태 저장 스트리밍 쿼리에서 수정 시간에 따라 파일을 처리하면 레코드가 잘못된 순서로 처리될 수 있습니다. 이렇게 하면 워터마크에 의해 레코드가 지연 이벤트로 떨어질 수 있습니다.
다음 옵션을 사용해서 데이터 삭제 문제를 방지할 수 있습니다.
- withEventTimeOrder: 초기 스냅샷을 이벤트 시간 순서로 처리할지 여부입니다.
이벤트 시간 순서를 사용하면 초기 스냅샷 데이터의 이벤트 시간 범위가 시간 버킷으로 분할됩니다. 각 마이크로 일괄 처리는 시간 범위 내에서 데이터를 필터링하여 버킷을 처리합니다. maxFilesPerTrigger 및 maxBytesPerTrigger 구성 옵션은 여전히 마이크로 일괄 처리 크기를 제어하는 데 적용할 수 있지만 처리 특성으로 인해 대략적인 방식으로만 적용됩니다.
아래 그래픽은 이 프로세스를 보여줍니다.
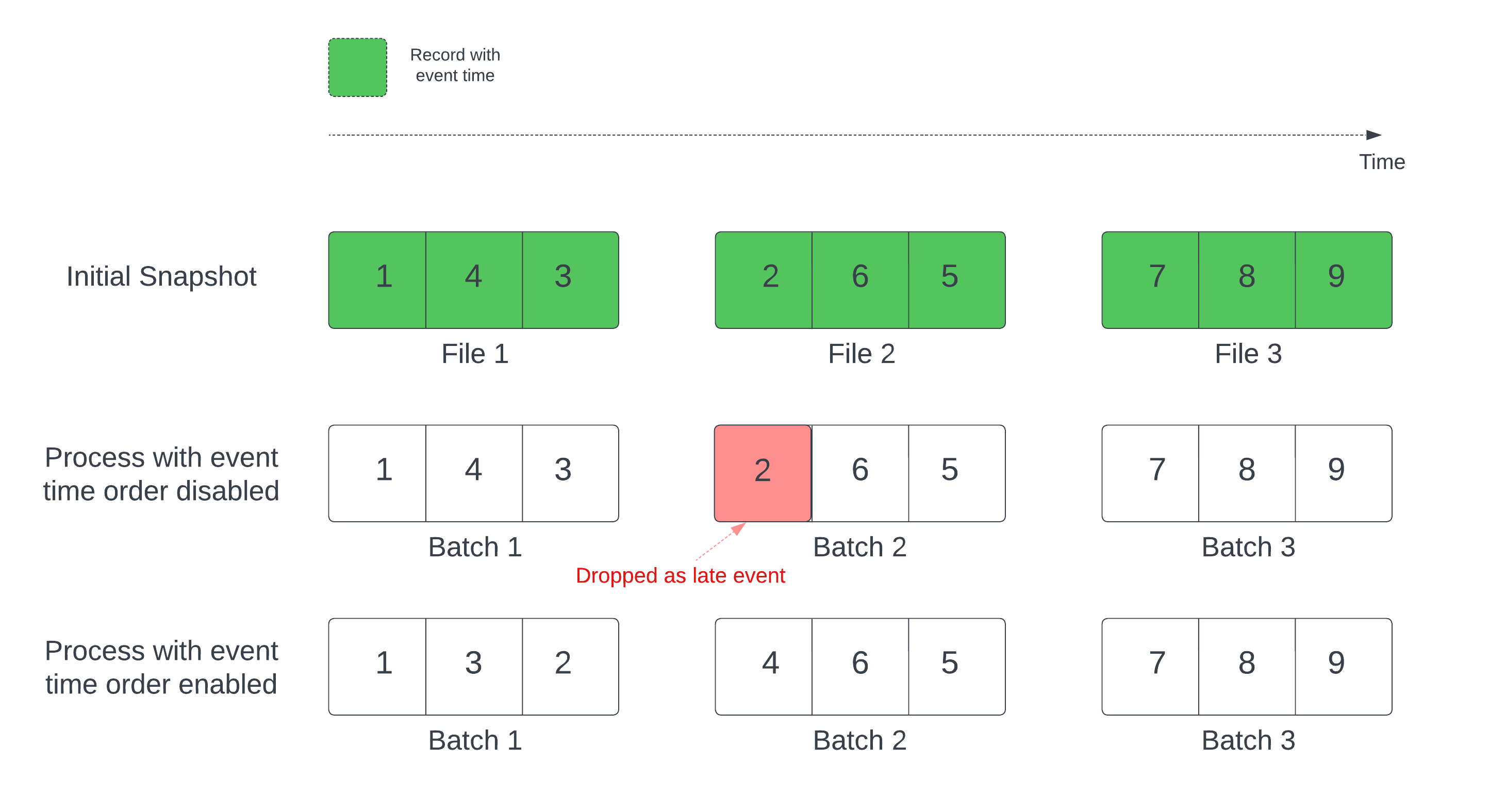
이 기능의 중요 정보는 다음과 같습니다.
- 데이터 삭제 문제는 상태 저장 스트리밍 쿼리의 초기 델타 스냅샷이 기본 순서로 처리될 때만 발생합니다.
- 초기 스냅샷이 처리되는 동안 스트림 쿼리가 시작된 후에는
withEventTimeOrder를 변경할 수 없습니다.withEventTimeOrder를 변경한 상태로 다시 시작하려면 체크포인트를 삭제해야 합니다. - withEventTimeOrder를 사용하여 스트림 쿼리를 실행하는 경우 초기 스냅샷 처리가 완료될 때까지 이 기능을 지원하지 않는 DBR 버전으로 다운그레이드할 수 없습니다. 다운그레이드해야 하는 경우 초기 스냅샷이 완료될 때까지 기다리거나 체크포인트를 삭제하고 쿼리를 다시 시작할 수 있습니다.
- 이 기능은 다음과 같은 일반적이지 않은 시나리오에서는 지원되지 않습니다.
- 이벤트 시간 열은 생성된 열이고 델타 원본 및 워터마크 사이에 비프로젝션 변환이 있습니다.
- 스트림 쿼리에 델타 원본이 2개 이상 있는 워터마크가 있습니다.
- 이벤트 시간 순서를 사용하도록 설정하면 델타 초기 스냅샷 처리의 성능이 느려질 수 있습니다.
- 각 마이크로 일괄 처리에서는 초기 스냅샷을 스캔하여 해당 이벤트 시간 범위 내에서 데이터를 필터링합니다. 더 빠른 필터 작업을 위해 데이터 건너뛰기를 적용할 수 있도록 델타 원본 열을 이벤트 시간으로 사용하는 것이 좋습니다(해당되는 경우 Delta Lake에 대한 데이터 건너뛰기 검사). 또한 이벤트 시간 열을 따라 테이블을 분할하여 처리 속도를 더 높일 수 있습니다. Spark UI에서 특정 마이크로 일괄 처리에 대해 델타 파일이 얼마나 많이 스캔되었는지 확인할 수 있습니다.
예시
event_time 열의 user_events 테이블이 있다고 가정해 보세요. 스트리밍 쿼리는 집계 쿼리입니다. 초기 스냅샷 처리 중 데이터가 삭제되지 않도록 하려면 다음을 사용할 수 있습니다.
spark.readStream.format("delta")
.option("withEventTimeOrder", "true")
.load("/tmp/delta/user_events")
.withWatermark("event_time", "10 seconds")
참고 항목
또한 클러스터의 Spark 구성을 사용하여 이 설정을 사용하도록 설정할 수도 있습니다. 이 설정은 모든 스트리밍 쿼리에 적용됩니다. spark.databricks.delta.withEventTimeOrder.enabled true
Delta 테이블을 싱크로
구조적 스트리밍을 사용하여 Delta 테이블에 데이터를 쓸 수도 있습니다. 트랜잭션 로그를 사용하면 Delta Lake가 테이블에 대해 동시에 실행 중인 다른 스트림이나 일괄 처리 쿼리가 있는 경우에도 정확히 한 번 처리를 보장할 수 있습니다.
참고 항목
Delta Lake VACUUM 함수는 Delta Lake에서 관리하지 않는 모든 파일을 제거하되, _로 시작되는 디렉터리는 건너뜁니다. <table-name>/_checkpoints 같은 디렉터리 구조를 사용하여 Delta 테이블에 대한 다른 데이터 및 메타데이터와 함께 검사점을 안전하게 저장할 수 있습니다.
메트릭
numBytesOutstanding 및 numFilesOutstanding 메트릭으로 스트리밍 쿼리 프로세스에서 아직 처리되지 않은 바이트 수와 파일 수를 확인할 수 있습니다. 추가 메트릭은 다음과 같습니다.
numNewListedFiles: 이 일괄 처리에 대한 백로그를 계산하기 위해 나열된 Delta Lake 파일의 수입니다.backlogEndOffset: 백로그를 계산하는 데 사용되는 테이블 버전입니다.
Notebook에서 스트림을 실행하는 경우 스트리밍 쿼리 진행률 대시보드의 원시 데이터 탭 아래에서 이러한 메트릭을 볼 수 있습니다.
{
"sources" : [
{
"description" : "DeltaSource[file:/path/to/source]",
"metrics" : {
"numBytesOutstanding" : "3456",
"numFilesOutstanding" : "8"
},
}
]
}
추가 모드
기본적으로 스트림은 새 레코드를 테이블에 추가하는 추가 모드로 실행됩니다.
경로 메서드를 사용할 수 있습니다.
Python
(events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/_checkpoints/")
.start("/delta/events")
)
Scala
events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.start("/tmp/delta/events")
또는 메서드는 toTable 다음과 같습니다.
Python
(events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
전체 모드
또한 구조적 스트리밍을 사용하여 전체 테이블을 모든 일괄 처리로 바꿀 수 있습니다. 한 가지 사용 사례는 집계를 사용하여 요약을 계산하는 것입니다.
Python
(spark.readStream
.format("delta")
.load("/tmp/delta/events")
.groupBy("customerId")
.count()
.writeStream
.format("delta")
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.start("/tmp/delta/eventsByCustomer")
)
Scala
spark.readStream
.format("delta")
.load("/tmp/delta/events")
.groupBy("customerId")
.count()
.writeStream
.format("delta")
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.start("/tmp/delta/eventsByCustomer")
앞의 예에서는 고객별 집계 이벤트 수가 포함된 테이블을 지속적으로 업데이트합니다.
대기 시간 요구 사항이 더 관대한 애플리케이션의 경우 일회성 트리거로 컴퓨팅 리소스를 절약할 수 있습니다. 이를 사용하여 주어진 일정에 따라 요약 집계 테이블을 업데이트하고 마지막 업데이트 이후에 도착한 새 데이터만 처리합니다.
foreachBatch를 사용하여 스트리밍 쿼리에서 upsert
스트리밍 쿼리에서 mergeforeachBatch 델타 테이블로 복잡한 upsert를 조합하여 작성할 수 있습니다. foreachBatch를 사용하여 임의의 데이터 싱크에 쓰기를 참조하세요.
이 패턴에는 다음을 포함하여 많은 애플리케이션이 있습니다.
- 업데이트 모드에서 스트리밍 집계 쓰기: 이것은 완전 모드보다 훨씬 효율적입니다.
- 데이터베이스 변경 사항 스트림을 Delta 테이블에 쓰기:
foreachBatch에서 변경 데이터 쓰기를 위한 병합 쿼리를 사용하여 Delta 테이블에 변경 사항 스트림을 연속 적용할 수 있습니다. - 중복 제거를 사용하여 델타 테이블에 데이터 스트림 작성: 중복 제거를 위한 삽입 전용 병합 쿼리를 사용하여
foreachBatch자동 중복 제거를 사용하여 델타 테이블에 데이터를 연속적으로 쓸 수 있습니다.
참고 항목
- 스트리밍 쿼리가 다시 시작되면 작업이 동일한 데이터 일괄 처리에 여러 차례 적용될 수 있으므로
foreachBatch내부의merge문이 idempotent해야 합니다. merge가foreachBatch에서 사용되는 경우, (StreamingQueryProgress를 통해 보고되고 Notebook 속도 그래프에 표시되는) 스트리밍 쿼리의 입력 데이터 속도는 원본에서 데이터가 생성되는 실제 속도의 배수로 보고될 수 있습니다. 이는merge가 입력 데이터를 여러 번 읽어서 입력 메트릭이 곱해지기 때문입니다. 이것이 병목 상태가 된다면merge앞에서 일괄 처리 DataFrame을 캐시하고merge뒤에서 캐시 해제하면 됩니다.
다음 예제에서는 SQL을 foreachBatch 사용하여 이 작업을 수행하는 방법을 보여 줍니다.
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
다음 예제와 같이 Delta Lake API를 사용하여 스트리밍 upsert를 수행하도록 선택할 수도 있습니다.
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forPath(spark, "/data/aggregates")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, "/data/aggregates")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
foreachBatch에서 멱등원 테이블 쓰기
참고 항목
Databricks는 업데이트하려는 각 싱크에 대해 별도의 스트리밍 쓰기를 구성하는 것이 좋습니다. 여러 테이블에 쓰는 데 사용하면 foreachBatch 쓰기가 직렬화되어 병렬 처리가 줄어들고 전체 대기 시간이 증가합니다.
델타 테이블은 idempotent 내 foreachBatch 의 여러 테이블에 쓰기를 위해 다음 DataFrameWriter 옵션을 지원합니다.
txnAppId: 각 DataFrame 쓰기에 전달할 수 있는 고유 문자열입니다. 예를 들어 StreamingQuery ID를txnAppId로 사용할 수 있습니다.txnVersion: 트랜잭션 버전 역할을 하는 단조 증가하는 숫자입니다.
Delta Lake는 txnAppId 및 txnVersion 조합을 사용하여 중복 쓰기를 식별하고 무시합니다.
일괄 처리 쓰기가 실패로 중단된 경우 일괄 처리를 다시 실행하면 동일한 애플리케이션 및 일괄 처리 ID를 사용하여 런타임이 중복 쓰기를 올바르게 식별하고 무시하도록 도와줍니다. 애플리케이션 ID(txnAppId)는 사용자 생성 고유 문자열일 수 있으며 스트림 ID와 관련될 필요는 없습니다. foreachBatch를 사용하여 임의의 데이터 싱크에 쓰기를 참조하세요.
Warning
스트리밍 검사포인트를 삭제하고 새 검사포인트를 사용하여 쿼리를 다시 시작하는 경우 다른 txnAppId항목을 제공해야 합니다. 새 검사포인트는 일괄 처리 ID로 시작합니다0. Delta Lake는 일괄 처리 ID와 txnAppId 고유 키로 사용하고 이미 표시된 값이 있는 일괄 처리를 건너뜁니다.
다음 코드 예제에서는 이 패턴을 보여 줍니다.
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기