중요합니다
이 페이지에서는 MLflow 2에서 에이전트 평가 버전을 0.22 사용하는 것을 설명합니다. Databricks는 에이전트 평가 >1.0와 통합된 MLflow 3을 사용하는 것이 좋습니다. MLflow 3에서 에이전트 평가 API는 이제 패키지의 mlflow 일부입니다.
이 항목에 대한 자세한 내용은 앱 검토를 참조하세요.
이 문서에서는 검토 앱을 사용하여 중소기업(주체 전문가)로부터 피드백을 수집하는 방법을 설명합니다. 검토 앱을 사용하여 다음을 수행할 수 있습니다.
- 이해 관계자에게 사전 프로덕션 생성 AI 앱과 채팅하고 피드백을 제공할 수 있는 기능을 제공합니다.
- Unity 카탈로그의 델타 테이블에 의해 지원되는 평가 데이터 세트를 만듭니다.
- SME를 활용하여 해당 평가 데이터 세트를 확장하고 반복합니다.
- SME를 활용하여 프로덕션 추적에 레이블을 지정하여 Gen AI 앱의 품질을 이해합니다.
사람 평가는 어떻게 되나요?
Databricks 검토 앱은 이해 관계자가 상호 작용할 수 있는 환경을 단계별로 설명합니다. 즉, 대화를 나누고, 질문을 하고, 피드백을 제공하는 등의 작업을 수행할 수 있습니다.
검토 앱을 사용하는 두 가지 주요 방법이 있습니다.
- 봇채팅: 유추 테이블에서 질문, 답변 및 피드백을 수집하여 GEN AI 앱의 성능을 추가로 분석할 수 있습니다. 이러한 방식으로 검토 앱은 애플리케이션이 제공하는 답변의 품질과 안전을 보장하는 데 도움이 됩니다.
- 세션 레이블 응답: MLFLow 실행 아래에 저장된 레이블 지정 세션의 중소기업에서 피드백 및 기대치를 수집합니다. 필요에 따라 이러한 레이블을 평가 데이터 세트에 동기화할 수 있습니다.
요구 사항
- 개발자는
databricks-agentsSDK를 설치하여 권한을 설정하고 검토 앱을 구성해야 합니다.
%pip install databricks-agents
dbutils.library.restartPython()
- 봇과의 채팅의 경우:
- 유추 테이블 에이전트를 제공하는 엔드포인트에서 사용하도록 설정해야 합니다.
- 각 사용자 검토자는 검토 앱 작업 영역에 대한 액세스 권한이 있거나 SCIM을 사용하여 Azure Databricks 계정에 동기화되어야 합니다. 검토 앱사용하도록 권한을 설정하기
다음 섹션을 참조하세요.
- 레이블링 세션의 경우:
- 각 사용자 검토자는 검토 앱 작업 영역에 액세스할 수 있어야 합니다.
검토 앱을 사용할 수 있는 권한 설정
메모
- 봇과 채팅하기 위해 사용자 검토자 작업 영역에 액세스할 필요가 없습니다.
- 레이블링 세션에서는 인간 검토자가 작업 공간에 액세스할 필요가 있습니다.
"봇과 채팅"에 대한 설정 권한
- 작업 영역에 액세스할 수 없는 사용자의 경우 계정 관리자는 계정 수준 SCIM 프로비저닝을 사용하여 ID 공급자에서 Azure Databricks 계정으로 사용자 및 그룹을 자동으로 동기화합니다. Databricks에서 ID를 설정할 때 이러한 사용자 및 그룹을 수동으로 등록하여 액세스 권한을 부여할 수도 있습니다. Microsoft Entra ID에서 SCIM 을 사용하여 사용자 및 그룹을 동기화하는 방법에 대한 정보를에서 참조하십시오.
- 검토 앱이 포함된 작업 영역에 대한 액세스 권한이 이미 있는 사용자의 경우 추가 구성이 필요하지 않습니다.
다음 코드 예제에서는 사용자에게 agents.deploy통해 배포된 모델에 대한 권한을 부여하는 방법을 보여 줍니다.
users 매개 변수는 전자 메일 주소 목록을 사용합니다.
from databricks import agents
# Note that <user_list> can specify individual users or groups.
agents.set_permissions(model_name=<model_name>, users=[<user_list>], permission_level=agents.PermissionLevel.CAN_QUERY)
메모
작업 영역의 모든 사용자에 대한 사용 권한을 부여하려면 .를 설정합니다 users=["users"].
세션 레이블 지정에 대한 설정 권한
레이블 지정 세션을 만들고 assigned_users 인수를 제공할 때 사용자에게 적절한 권한(실험에 대한 쓰기 액세스 및 데이터 세트에 대한 읽기 액세스)이 자동으로 부여됩니다.
자세한 내용은 아래의 레이블 지정 세션 만들기 및 검토 요청을 참조하세요.
검토 앱 만들기
자동으로 agents.deploy() 사용
agents.deploy()사용하여 gen AI 앱을 배포하면 검토 앱이 자동으로 사용하도록 설정되고 배포됩니다. 명령의 출력에서 리뷰 앱의 URL 표시됩니다. Gen AI 앱("에이전트"라고도 함)을 배포하는 방법에 대한 자세한 내용은 생성 AI 애플리케이션에 대한 에이전트 배포를 참조하세요.
메모
에이전트는 엔드포인트가 완전히 배포될 때까지 검토 앱 UI에 표시되지 않습니다.
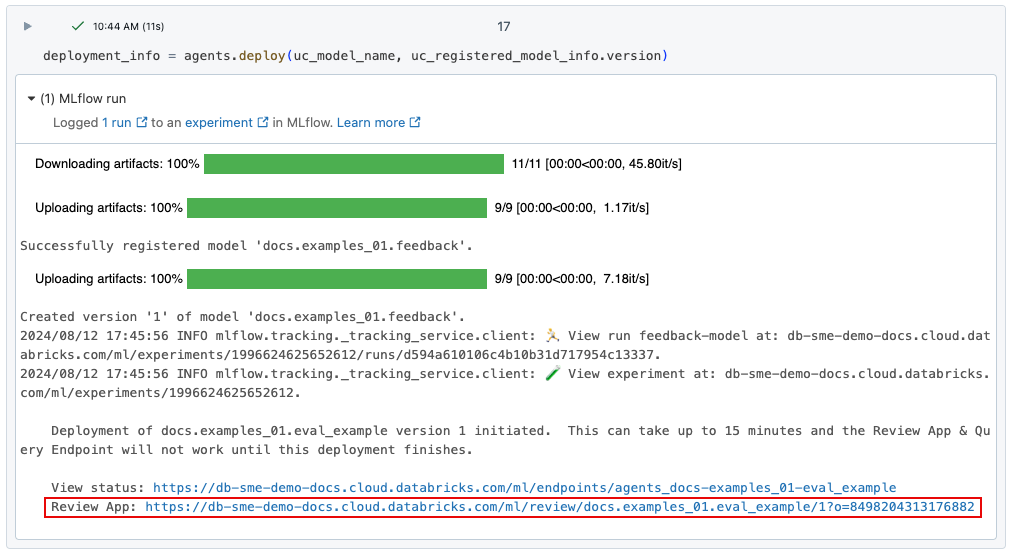
검토 앱 UI에 대한 링크가 손실되면 get_review_app()사용하여 찾을 수 있습니다.
import mlflow
from databricks.agents import review_app
# The review app is tied to the current MLFlow experiment.
mlflow.set_experiment("same_exp_used_to_deploy_the_agent")
my_app = review_app.get_review_app()
print(my_app.url)
print(my_app.url + "/chat") # For "Chat with the bot".
수동으로 Python API 사용
아래 코드 조각은 검토 앱을 만들고 봇과의 채팅을 위해 엔드포인트를 제공하는 모델과 연결하는 방법을 보여 줍니다. 레이블 지정 세션을 만들려면 를 참조하세요.
- 레이블링 세션을 만들고 평가 데이터 세트에 레이블을 지정하기 위한 검토를 위해 보냅니다.
- 레이블 지정을 위한 추적에 대한 피드백을 수집합니다. 유의하세요, 실시간 담당자는 필요하지 않습니다.
from databricks.agents import review_app
# The review app is tied to the current MLFlow experiment.
my_app = review_app.get_review_app()
# TODO: Replace with your own serving endpoint.
my_app.add_agent(
agent_name="llama-70b",
model_serving_endpoint="databricks-meta-llama-3-3-70b-instruct",
)
print(my_app.url + "/chat") # For "Chat with the bot".
개념
데이터셋
데이터 세트 세대 AI 애플리케이션을 평가하는 데 사용되는 예제의 컬렉션입니다. 데이터 세트 레코드에는 gen AI 애플리케이션에 대한 입력이 포함되며, 필요에 따라 기대치(mlflow.evaluate()입력으로 직접 사용할 수 있습니다. 데이터 세트는 Unity 카탈로그의 델타 테이블로 지원되며, 이 델타 테이블에서 정의된 사용 권한을 상속합니다. 데이터 세트를 만들려면 데이터 세트만들기를 참조하세요.
입력 및 예상 열만 표시하는 평가 데이터 세트 예제:

평가 데이터 세트에는 다음 스키마가 있습니다.
| 기둥 (if context refers to architectural column) | 데이터 형식 | 설명 |
|---|---|---|
| 데이터셋 기록 번호 | 문자열 | 레코드의 고유 식별자입니다. |
| 입력 | 문자열 | json serialize dict<str, Any>로 평가하기 위한 입력입니다. |
| 기대 | 문자열 | 예상 값은 JSON 형식으로 직렬화된 dict<str, Any>입니다.
expectations 에는 LLM 심사위원(예: guidelines, expected_facts및 expected_response)에 사용되는 예약 키가 있습니다. |
| 생성_시간 | 타임 스탬프 | 기록이 생성된 시간입니다. |
| 작성자 | 문자열 | 레코드를 만든 사용자입니다. |
| 마지막 업데이트 시간 | 타임 스탬프 | 레코드가 마지막으로 업데이트된 시간입니다. |
| 마지막으로 업데이트한 사람 | 문자열 | 레코드를 마지막으로 업데이트한 사용자입니다. |
| 근원 | 구조체 | 데이터 세트 레코드의 원본입니다. |
| 인간 출처 | 구조체 | 원본이 사람에서 온 경우 정의됩니다. |
| source.human.user_name | 문자열 | 레코드와 연결된 사용자의 이름입니다. |
| 소스 문서 | 문자열 | 문서로부터 레코드가 합성되었을 때 정의됩니다. |
| source.document.doc_uri | 문자열 | 문서의 URI입니다. |
| 소스 문서 내용 | 문자열 | 문서의 내용입니다. |
| 소스 추적 | 문자열 | 레코드가 추적으로부터 생성된 시점을 정의합니다. |
| source.trace.trace_id | 문자열 | 추적의 고유 식별자입니다. |
| 태그 | 지도 | 데이터셋 레코드의 키-값 태그입니다. |
세션 레이블 지정
SME가 검토 앱 UI에서 레이블을 지정하기 위한 유한한 추적 또는 데이터 세트 레코드의 집합인 LabelingSession입니다. 추적은 프로덕션의 애플리케이션에 대한 유추 테이블 또는 MLFlow 실험의 오프라인 추적에서 비롯할 수 있습니다. 결과는 MLFlow 실행으로 저장됩니다. 레이블은 Assessment단위로 MLFlow 추적에 저장됩니다. "예상"이 있는 레이블을 평가 데이터 세트로 다시 동기화할 수 있습니다.
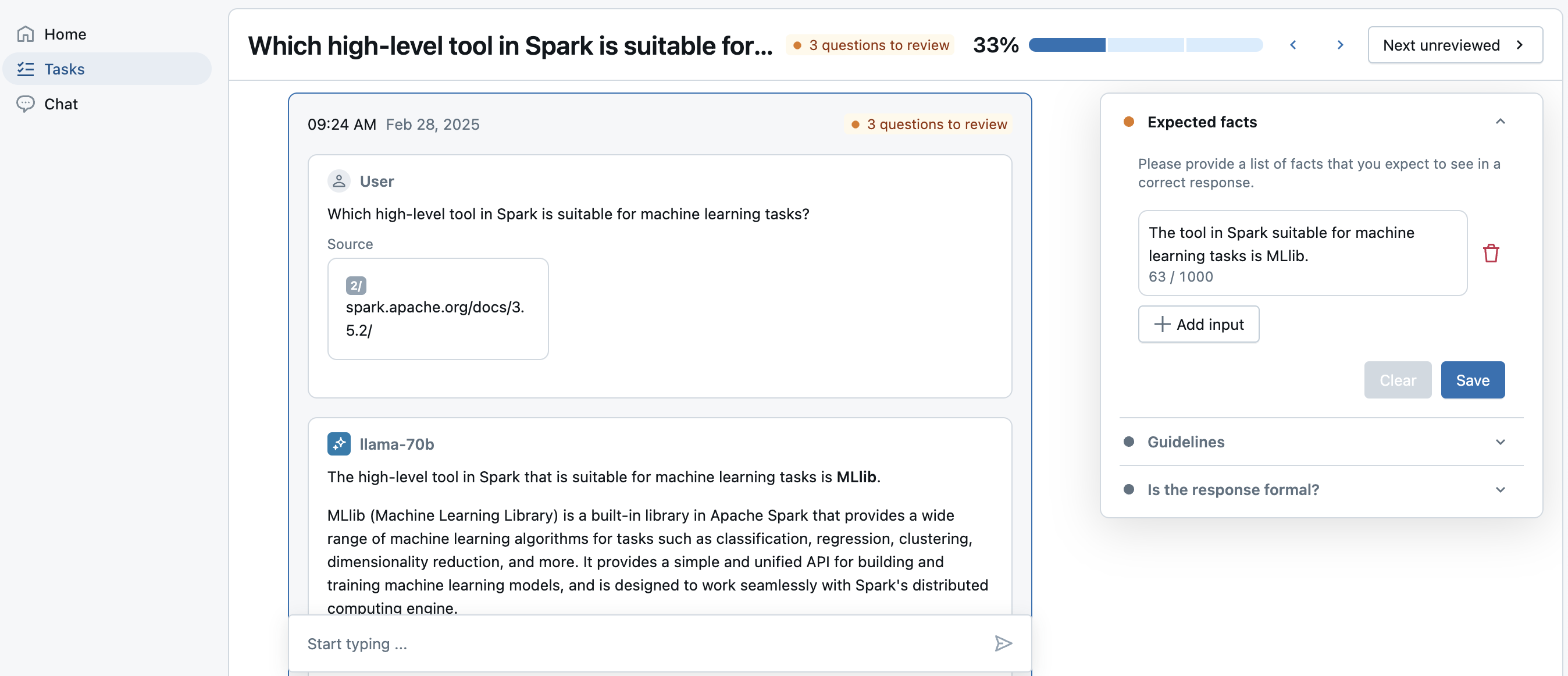
평가 및 레이블
SME가 추적에 레이블을 지정하면, 필드 아래에 있는 추적에 Trace.info.assessments이 기록됩니다.
Assessment두 가지 형식을 가질 수 있습니다.
-
expectation: 올바른 추적이 가져야 할 것을 나타내는 레이블. 예를 들어expected_facts이상적인 응답에 있어야 하는 사실을 나타내는expectation레이블로 사용할 수 있습니다. 이러한expectation레이블을 평가 데이터 세트로 다시 동기화하여mlflow.evaluate()과 함께 사용할 수 있습니다. -
feedback: "좋아요" 및 "싫어요" 또는 자유로운 형식의 댓글과 같은 추적에 대한 간단한 피드백을 나타내는 레이블입니다.Assessment유형의feedback은 특정 MLFlow 추적의 인간 평가이기 때문에 평가 데이터 세트와 함께 사용되지 않습니다. 이러한 평가는mlflow.search_traces()사용하여 읽을 수 있습니다.
데이터셋
이 섹션에서는 다음을 수행하는 방법을 설명합니다.
- 데이터 세트를 만들고 SME 없이 평가에 사용합니다.
- 더 나은 평가 데이터 세트를 큐레이팅하기 위해 SME에서 레이블 지정 세션을 요청합니다.
데이터 세트 만들기
다음 예제에서는 데이터 세트 만들고 평가를 삽입합니다. 데이터 세트를 합성 평가로 시드하려면, 평가 집합 합성을 참조하세요.
from databricks.agents import datasets
import mlflow
# The following call creates an empty dataset. To delete a dataset, use datasets.delete_dataset(uc_table_name).
dataset = datasets.create_dataset("cat.schema.my_managed_dataset")
# Optionally, insert evaluations.
# The `guidelines` specified here are saved to the `expectations` field in the dataset.
eval_set = [{
"request": {"messages": [{"role": "user", "content": "What is the capital of France?"}]},
"guidelines": ["The response must be in English", "The response must be clear, coherent, and concise"],
}]
dataset.insert(eval_set)
이 데이터 세트의 데이터는 Unity 카탈로그의 델타 테이블에 의해 지원되며 카탈로그 탐색기에 표시됩니다.
메모
명명된 지침(사전 사용)은 현재 레이블 지정 세션에서 지원되지 않습니다.
평가에 데이터 세트 사용
다음 예제에서는 평가 데이터 세트를 사용하여 간단한 시스템 프롬프트 에이전트를 평가하여 Unity 카탈로그에서 데이터 세트를 읽습니다.
import mlflow
from mlflow.deployments import get_deploy_client
# Define a very simple system-prompt agent to test against our evaluation set.
@mlflow.trace(span_type="AGENT")
def llama3_agent(request):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={
"messages": [
{"role": "system", "content": SYSTEM_PROMPT},
*request["messages"]
]
}
)
evals = spark.read.table("cat.schema.my_managed_dataset")
mlflow.evaluate(
data=evals,
model=llama3_agent,
model_type="databricks-agent"
)
레이블 지정 세션 만들기 및 검토를 위해 보내기
다음 예제에서는 ReviewApp.create_labeling_session사용하여 위의 데이터 세트에서 LabelingSession 만들고, guidelines 필드를 사용하여 중소기업에서 expected_facts 수집 및 수집하도록 세션을 구성합니다.
ReviewApp.create_label_schema 사용하여 사용자 지정 레이블 스키마를 만들 수도 있습니다.
메모
- 레이블 지정 세션을 만들 때 할당된 사용자는 다음과 같습니다.
- MLFlow 실험에 대한 WRITE 권한이 부여되었습니다.
- 검토 앱과 연결된 엔드포인트를 제공하는 모델에 대한 QUERY 권한이 부여되었습니다.
- 레이블 지정 세션에 데이터 세트를 추가할 때 할당된 사용자에게 레이블 지정 세션을 시드하는 데 사용되는 데이터 세트의 델타 테이블에 대한 SELECT 권한이 부여됩니다.
작업 영역의 모든 사용자에 대한 사용 권한을 부여하려면 .를 설정합니다 assigned_users=["users"].
from databricks.agents import review_app
import mlflow
# The review app is tied to the current MLFlow experiment.
my_app = review_app.get_review_app()
# You can use the following code to remove any existing agents.
# for agent in list(my_app.agents):
# my_app.remove_agent(agent.agent_name)
# Add the llama3 70b model serving endpoint for labeling. You should replace this with your own model serving endpoint for your
# own agent.
# NOTE: An agent is required when labeling an evaluation dataset.
my_app.add_agent(
agent_name="llama-70b",
model_serving_endpoint="databricks-meta-llama-3-3-70b-instruct",
)
# Create a labeling session and collect guidelines and/or expected-facts from SMEs.
# Note: Each assigned user is given QUERY access to the serving endpoint above and write access.
# to the MLFlow experiment.
my_session = my_app.create_labeling_session(
name="my_session",
agent="llama-70b",
assigned_users = ["email1@company.com", "email2@company.com"],
label_schemas = [review_app.label_schemas.GUIDELINES, review_app.label_schemas.EXPECTED_FACTS]
)
# Add the records from the dataset to the labeling session.
# Note: Each assigned user above is given SELECT access to the UC delta table.
my_session.add_dataset("cat.schema.my_managed_dataset")
# Share the following URL with your SMEs for them to bookmark. For the given review app linked to an experiment, this URL never changes.
print(my_app.url)
# You can also link them directly to the labeling session URL, however if you
# request new labeling sessions from SMEs there will be new URLs. Use the review app
# URL above to keep a permanent URL.
print(my_session.url)
이 시점에서 위의 URL을 중소기업에 보낼 수 있습니다.
SME가 레이블을 지정하는 동안 다음 코드를 사용하여 레이블 지정 상태를 볼 수 있습니다.
mlflow.search_traces(run_id=my_session.mlflow_run_id)
레이블 지정 세션 기대치를 데이터 세트로 다시 동기화
SME가 레이블 지정을 완료한 후 expectation사용하여 레이블을 데이터 세트에 다시 동기화할 수 있습니다.
expectation 유형의 레이블 예로는 GUIDELINES, EXPECTED_FACTS가 있으며, 또는 expectation유형의 사용자 지정 레이블 스키마가 포함될 수 있습니다.
my_session.sync_expectations(to_dataset="cat.schema.my_managed_dataset")
display(spark.read.table("cat.schema.my_managed_dataset"))
이제 다음 평가 데이터 세트를 사용할 수 있습니다.
eval_results = mlflow.evaluate(
model=llama3_agent,
data=dataset.to_df(),
model_type="databricks-agent"
)
추적에 대한 피드백 수집
이 섹션에서는 다음 중 하나에서 가져올 수 있는 MLFlow 추적 개체에서 레이블을 수집하는 방법을 설명합니다.
- MLFlow 실험 또는 실행
- 유추 테이블입니다.
- 모든 MLFlow Python 추적 객체입니다.
MLFlow 실험에서 피드백 수집 또는 실행
이 예제에서는 SME에서 레이블을 지정할 추적 집합을 만듭니다.
import mlflow
from mlflow.deployments import get_deploy_client
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Create a trace to be labeled.
with mlflow.start_run(run_name="llama3") as run:
run_id = run.info.run_id
llama3_agent([{"content": "What is databricks?", "role": "user"}])
llama3_agent([{"content": "How do I set up a SQL Warehouse?", "role": "user"}])
추적에 대한 레이블을 가져와 이를 바탕으로 레이블링 세션을 시작할 수 있습니다. 다음은 에이전트 응답에 대한 "형식성" 피드백을 수집하도록 레이블 지정 세션을 단일 레이블 스키마로 설정하는 예제입니다. SME의 레이블은 MLFlow 추적 기록에 평가로 저장됩니다.
더 많은 유형의 스키마 입력은 databricks-agents SDK참조하세요.
# The review app is tied to the current MLFlow experiment.
my_app = review_app.get_review_app()
# Use the run_id from above.
traces = mlflow.search_traces(run_id=run_id)
formality_label_schema = my_app.create_label_schema(
name="formal",
# Type can be "expectation" or "feedback".
type="feedback",
title="Is the response formal?",
input=review_app.label_schemas.InputCategorical(options=["Yes", "No"]),
instruction="Please provide a rationale below.",
enable_comment=True
)
my_session = my_app.create_labeling_session(
name="my_session",
# NOTE: An `agent` is not required. If you do provide an Agent, your SME can ask follow up questions in a converstion and create new questions in the labeling session.
assigned_users=["email1@company.com", "email2@company.com"],
# More than one label schema can be provided and the SME will be able to provide information for each one.
# We use only the "formal" schema defined above for simplicity.
label_schemas=["formal"]
)
# NOTE: This copies the traces into this labeling session so that labels do not modify the original traces.
my_session.add_traces(traces)
# Share the following URL with your SMEs for them to bookmark. For the given review app, linked to an experiment, this URL will never change.
print(my_app.url)
# You can also link them directly to the labeling session URL, however if you
# request new labeling sessions from SMEs there will be new URLs. Use the review app
# URL above to keep a permanent URL.
print(my_session.url)
SME가 레이블 지정을 완료하면 결과 추적 및 평가가 레이블 지정 세션과 연결된 실행의 일부가 됩니다.
mlflow.search_traces(run_id=my_session.mlflow_run_id)
이제 이러한 평가를 사용하여 모델을 개선하거나 평가 데이터 세트를 업데이트할 수 있습니다.
유추 테이블에서 피드백 수집
이 예제에서는 유추 테이블(요청 페이로드 로그)에서 직접 추적을 레이블 지정 세션에 추가하는 방법을 보여 줍니다.
# CHANGE TO YOUR PAYLOAD REQUEST LOGS TABLE
PAYLOAD_REQUEST_LOGS_TABLE = "catalog.schema.my_agent_payload_request_logs"
traces = spark.table(PAYLOAD_REQUEST_LOGS_TABLE).select("trace").limit(3).toPandas()
my_session = my_app.create_labeling_session(
name="my_session",
assigned_users = ["email1@company.com", "email2@company.com"],
label_schemas=[review_app.label_schemas.EXPECTED_FACTS]
)
# NOTE: This copies the traces into this labeling session so that labels do not modify the original traces.
my_session.add_traces(traces)
print(my_session.url)
예제 노트
다음 Notebook에서는 Mosaic AI 에이전트 평가에서 데이터 세트 및 레이블 지정 세션을 사용하는 다양한 방법을 보여 줍니다.
앱 예제 노트북 검토
노트북 가져오기
에이전트 평가 사용자 지정 메트릭, 지침 및 도메인 전문가 레이블 노트북
노트북 가져오기