중요합니다
Microsoft SQL Server 커넥터는 공개 미리 보기로 제공됩니다.
이 페이지에서는 Lakeflow Connect를 사용하여 SQL Server에서 데이터를 수집하고 Azure Databricks에 로드하는 방법을 설명합니다. SQL Server 커넥터는 Azure SQL 및 Amazon RDS SQL 데이터베이스를 지원합니다. 여기에는 Azure VM(가상 머신) 및 Amazon EC2에서 실행되는 SQL Server가 포함됩니다. 또한 커넥터는 Azure ExpressRoute 및 AWS Direct Connect 네트워킹을 사용하여 SQL Server 온-프레미스를 지원합니다.
시작하기 전 주의 사항:
수집 파이프라인을 만들려면 다음 요구 사항을 충족해야 합니다.
작업 영역이 Unity 카탈로그를 사용할 수 있도록 설정되었습니다.
서버리스 컴퓨팅은 작업 영역에 대해 사용하도록 설정됩니다. 서버리스 컴퓨팅 사용을 참조하세요.
연결을 만들려는 경우: 메타스토어에 대한
CREATE CONNECTION권한이 있습니다.커넥터가 UI 기반 파이프라인 작성을 지원하는 경우 이 페이지의 단계를 완료하여 연결 및 파이프라인을 동시에 만들 수 있습니다. 그러나 API 기반 파이프라인 작성을 사용하는 경우 이 페이지의 단계를 완료하기 전에 카탈로그 탐색기에서 연결을 만들어야 합니다. 관리된 수집 소스에 연결하기를 참조하세요.
기존 연결을 사용하려는 경우:
USE CONNECTION권한이 있거나ALL PRIVILEGES연결에 있습니다.대상 카탈로그에 대한
USE CATALOG권한이 있습니다.USE SCHEMA,CREATE TABLE,CREATE VOLUME에 대한 기존 스키마에 대한 권한이 있거나 대상 카탈로그에 대한CREATE SCHEMA권한이 있습니다.
기본 SQL Server 인스턴스에 액세스할 수 있습니다. 변경 내용 추적 및 변경 데이터 캡처 기능은 읽기 복제본 또는 보조 인스턴스에서 지원되지 않습니다.
클러스터를 만들 수 있는 무제한 권한 또는 사용자 지정 정책입니다. 사용자 지정 정책은 다음 요구 사항을 충족해야 합니다.
가족: 작업 연산
정책 그룹 우선 변경:
{ "cluster_type": { "type": "fixed", "value": "dlt" }, "num_workers": { "type": "unlimited", "defaultValue": 1, "isOptional": true }, "runtime_engine": { "type": "fixed", "value": "STANDARD", "hidden": true } }Databricks는 게이트웨이 성능에 영향을 주지 않으므로 수집 게이트웨이에 대해 가능한 가장 작은 작업자 노드를 지정하는 것이 좋습니다.
"driver_node_type_id": { "type": "unlimited", "defaultValue": "r5.xlarge", "isOptional": true }, "node_type_id": { "type": "unlimited", "defaultValue": "m4.large", "isOptional": true }
클러스터 정책에 대한 자세한 내용은 클러스터 정책 선택을 참조하세요.
SQL Server에서 수집하려면 원본 설정도 완료해야 합니다.
옵션 1: Azure Databricks UI
관리자 사용자는 UI에서 동시에 연결 및 파이프라인을 만들 수 있습니다. 관리되는 수집 파이프라인을 만드는 가장 간단한 방법입니다.
Azure Databricks 작업 영역의 사이드바에서 데이터 수집을 클릭합니다.
데이터 추가 페이지의 Databricks 커넥터 아래에서 SQL Server를 클릭합니다.
데이터 수집 마법사가 열립니다.
마법사의 수집 게이트웨이 페이지에서 게이트웨이의 고유한 이름을 입력합니다.
스테이징 수집 데이터에 대한 카탈로그 및 스키마를 선택한 다음 다음을 클릭합니다.
수집 파이프라인 페이지에서 파이프라인의 고유한 이름을 입력합니다.
대상 카탈로그의 경우 수집된 데이터를 저장할 카탈로그를 선택합니다.
원본 데이터에 액세스하는 데 필요한 자격 증명을 저장하는 Unity 카탈로그 연결을 선택합니다.
원본에 대한 기존 연결이 없는 경우 연결 만들기 를 클릭하고 원본 설정에서 얻은 인증 세부 정보를 입력합니다. metastore에 대한
CREATE CONNECTION권한이 있어야 합니다.파이프라인 만들기를 클릭하고 계속합니다.
원본 페이지에서 수집할 테이블을 선택합니다.
필요에 따라 기본 기록 추적 설정을 변경합니다. 자세한 내용은 기록 추적을 참조하세요.
다음을 클릭합니다.
대상 페이지에서 Unity Catalog의 카탈로그와 스키마를 선택하여 작성합니다.
기존 스키마를 사용하지 않으려면 스키마 만들기클릭합니다. 부모 카탈로그에 대한
USE CATALOG및CREATE SCHEMA권한이 있어야 합니다.저장을 클릭하고 계속합니다.
(선택 사항) 설정 페이지에서 일정 생성을 클릭합니다. 대상 테이블을 새로 고치는 빈도를 설정합니다.
(선택 사항) 파이프라인 작업의 성공 또는 실패에 대한 이메일 알림을 설정합니다.
저장을 클릭하고 파이프라인을 실행합니다.
옵션 2: 기타 인터페이스
Databricks 자산 번들, Databricks API, Databricks SDK 또는 Databricks CLI를 사용하여 수집하기 전에 기존 Unity 카탈로그 연결에 액세스할 수 있어야 합니다. 자세한 내용은 관리되는 수집 원본에 대한 연결을 참조하세요.
스테이징 카탈로그 및 스키마 만들기
스테이징 카탈로그 및 스키마는 대상 카탈로그 및 스키마와 같을 수 있습니다. 스테이징 카탈로그는 외국 카탈로그일 수 없습니다.
명령 줄 인터페이스 (CLI)
export CONNECTION_NAME="my_connection"
export TARGET_CATALOG="main"
export TARGET_SCHEMA="lakeflow_sqlserver_connector_cdc"
export STAGING_CATALOG=$TARGET_CATALOG
export STAGING_SCHEMA=$TARGET_SCHEMA
export DB_HOST="cdc-connector.database.windows.net"
export DB_USER="..."
export DB_PASSWORD="..."
output=$(databricks connections create --json '{
"name": "'"$CONNECTION_NAME"'",
"connection_type": "SQLSERVER",
"options": {
"host": "'"$DB_HOST"'",
"port": "1433",
"trustServerCertificate": "false",
"user": "'"$DB_USER"'",
"password": "'"$DB_PASSWORD"'"
}
}')
export CONNECTION_ID=$(echo $output | jq -r '.connection_id')
게이트웨이 및 데이터 수집 파이프라인 만들기
수집 게이트웨이는 원본 데이터베이스에서 스냅샷 및 변경 데이터를 추출하고 Unity 카탈로그 준비 볼륨에 저장합니다. 게이트웨이를 연속 파이프라인으로 실행해야 합니다. 이렇게 하면 원본 데이터베이스에 있는 변경 로그 보존 정책을 수용할 수 있습니다.
수집 파이프라인은 스냅샷을 적용하고 준비 볼륨에서 대상 스트리밍 테이블로 데이터를 변경합니다.
비고
각 수집 파이프라인은 정확히 하나의 수집 게이트웨이와 연결되어야 합니다.
수집 파이프라인은 둘 이상의 대상 카탈로그 및 스키마를 지원하지 않습니다. 여러 대상 카탈로그 또는 스키마에 작성해야 하는 경우 여러 게이트웨이-파이프라인 쌍을 만듭니다.
Databricks 자산 번들
이 탭에서는 Databricks 자산 번들을 사용하여 수집 파이프라인을 배포하는 방법을 설명합니다. 번들은 작업 및 태스크의 YAML 정의를 포함할 수 있고, Databricks CLI를 사용하여 관리되며, 다른 대상 작업 영역(예: 개발, 스테이징 및 프로덕션)에서 공유 및 실행할 수 있습니다. 자세한 내용은 Databricks 자산 번들을 참조하세요.
Databricks CLI를 사용하여 새 묶음을 만듭니다.
databricks bundle init번들에 두 개의 새 리소스 파일을 추가합니다.
- 파이프라인 정의 파일(
resources/sqlserver_pipeline.yml)입니다. - 데이터 수집
resources/sqlserver.yml()의 빈도를 제어하는 워크플로 파일입니다.
다음은 예시
resources/sqlserver_pipeline.yml파일입니다.variables: # Common variables used multiple places in the DAB definition. gateway_name: default: sqlserver-gateway dest_catalog: default: main dest_schema: default: ingest-destination-schema resources: pipelines: gateway: name: ${var.gateway_name} gateway_definition: connection_name: <sqlserver-connection> gateway_storage_catalog: main gateway_storage_schema: ${var.dest_schema} gateway_storage_name: ${var.gateway_name} target: ${var.dest_schema} catalog: ${var.dest_catalog} channel: PREVIEW pipeline_sqlserver: name: sqlserver-ingestion-pipeline ingestion_definition: ingestion_gateway_id: ${resources.pipelines.gateway.id} objects: # Modify this with your tables! - table: # Ingest the table test.ingestion_demo_lineitem to dest_catalog.dest_schema.ingestion_demo_line_item. source_catalog: test source_schema: ingestion_demo source_table: lineitem destination_catalog: ${var.dest_catalog} destination_schema: ${var.dest_schema} - schema: # Ingest all tables in the test.ingestion_whole_schema schema to dest_catalog.dest_schema. The destination # table name will be the same as it is on the source. source_catalog: test source_schema: ingestion_whole_schema destination_catalog: ${var.dest_catalog} destination_schema: ${var.dest_schema} target: ${var.dest_schema} catalog: ${var.dest_catalog} channel: PREVIEW다음은 예시
resources/sqlserver_job.yml파일입니다.resources: jobs: sqlserver_dab_job: name: sqlserver_dab_job trigger: # Run this job every day, exactly one day from the last run # See https://docs.databricks.com/api/workspace/jobs/create#trigger periodic: interval: 1 unit: DAYS email_notifications: on_failure: - <email-address> tasks: - task_key: refresh_pipeline pipeline_task: pipeline_id: ${resources.pipelines.pipeline_sqlserver.id}- 파이프라인 정의 파일(
Databricks CLI를 사용하여 파이프라인을 배포합니다.
databricks bundle deploy
노트북
원본 연결, 대상 카탈로그, 대상 스키마 및 테이블을 사용하여 다음 Notebook의 Configuration 셀을 업데이트하여 원본에서 데이터를 적용합니다.
게이트웨이 및 수집 파이프라인 만들기
명령 줄 인터페이스 (CLI)
게이트웨이를 만드는 방법:
output=$(databricks pipelines create --json '{
"name": "'"$GATEWAY_PIPELINE_NAME"'",
"gateway_definition": {
"connection_id": "'"$CONNECTION_ID"'",
"gateway_storage_catalog": "'"$STAGING_CATALOG"'",
"gateway_storage_schema": "'"$STAGING_SCHEMA"'",
"gateway_storage_name": "'"$GATEWAY_PIPELINE_NAME"'"
}
}')
export GATEWAY_PIPELINE_ID=$(echo $output | jq -r '.pipeline_id')
데이터 수집 파이프라인을 만들려면 다음을 수행합니다.
databricks pipelines create --json '{
"name": "'"$INGESTION_PIPELINE_NAME"'",
"ingestion_definition": {
"ingestion_gateway_id": "'"$GATEWAY_PIPELINE_ID"'",
"objects": [
{"table": {
"source_catalog": "tpc",
"source_schema": "tpch",
"source_table": "lineitem",
"destination_catalog": "'"$TARGET_CATALOG"'",
"destination_schema": "'"$TARGET_SCHEMA"'",
"destination_table": "<YOUR_DATABRICKS_TABLE>",
}},
{"schema": {
"source_catalog": "tpc",
"source_schema": "tpcdi",
"destination_catalog": "'"$TARGET_CATALOG"'",
"destination_schema": "'"$TARGET_SCHEMA"'"
}}
]
}
}'
파이프라인에서 시작하고, 예약하고, 알림을 설정하세요.
파이프라인 세부 정보 페이지에서 파이프라인에 대한 일정을 만들 수 있습니다.
파이프라인을 만든 후 Azure Databricks 작업 영역을 다시 방문한 다음 파이프라인을 클릭합니다.
새 파이프라인이 파이프라인 목록에 나타납니다.
파이프라인 세부 정보를 보려면 파이프라인 이름을 클릭합니다.
파이프라인 세부 정보 페이지에서 일정을 클릭하여 파이프라인을 예약할 수 있습니다.
파이프라인에서 알림을 설정하려면 설정을 클릭한 다음 알림을 추가합니다.
파이프라인에 추가된 각 일정에 대해 Lakeflow Connect는 자동으로 작업을 생성합니다. 수집 파이프라인은 작업 내의 과제입니다. 필요에 따라 작업에 더 많은 작업을 추가할 수 있습니다.
성공적인 데이터 수집 확인
파이프라인 세부 정보 페이지의 목록 보기에는 데이터가 수집될 때 처리되는 레코드 수가 표시됩니다. 이러한 숫자는 자동으로 새로 고쳐집니다.
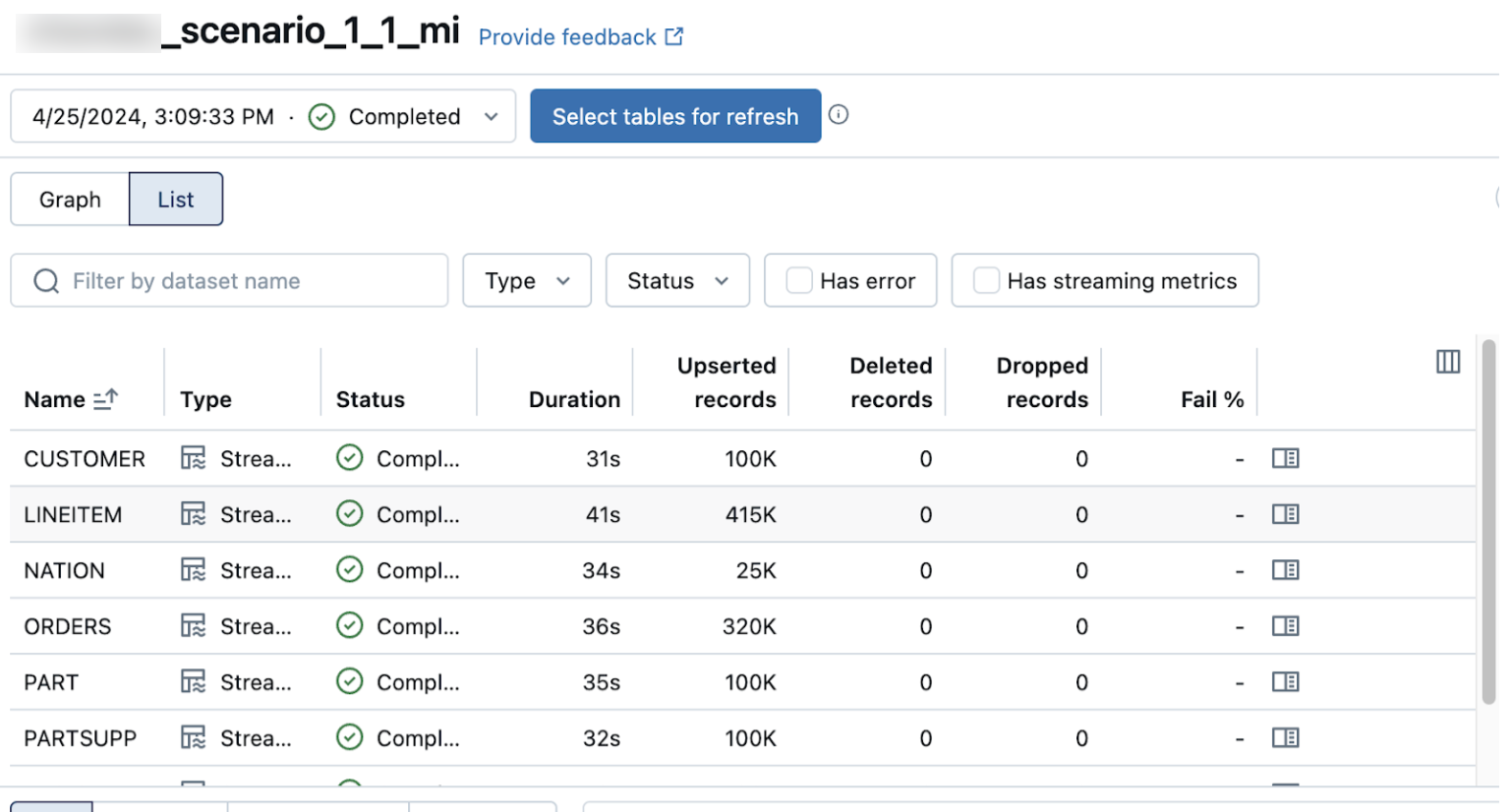
Upserted records 및 Deleted records 열은 기본적으로 표시되지 않습니다. 열 구성 ![]() 단추를 클릭하고 선택하여 사용하도록 설정할 수 있습니다.
단추를 클릭하고 선택하여 사용하도록 설정할 수 있습니다.