Databricks 레이크하우스의 데이터 개체
Databricks Lakehouse는 데이터베이스, 테이블 및 뷰와 같은 친숙한 관계로 클라우드 개체 스토리지에 Delta Lake와 함께 저장된 데이터를 구성합니다. 이 모델은 엔터프라이즈 데이터 웨어하우스의 많은 이점과 데이터 레이크의 확장성 및 유연성을 결합합니다. 조직의 Databricks Lakehouse를 디자인하고 구현할 때 모범 사례를 적용할 수 있도록 이 모델의 작동 방식과 개체 데이터와 메타데이터 간의 관계에 대해 자세히 알아봅니다.
Databricks 레이크하우스에 있는 데이터 개체는 무엇인가요?
Databricks Lakehouse 아키텍처는 클라우드 개체 스토리지의 Delta Lake 프로토콜과 저장된 데이터를 메타스토어에 등록된 메타데이터와 결합합니다. Databricks 레이크하우스에는 다음과 같은 다섯 가지 기본 개체가 있습니다.
- 카탈로그: 데이터베이스 그룹입니다.
- 데이터베이스 또는 스키마: 카탈로그의 개체 그룹입니다. 데이터베이스에는 테이블, 뷰 및 함수가 포함됩니다.
- 테이블: 개체 스토리지에 데이터 파일로 저장된 행과 열의 컬렉션입니다.
- 뷰: 일반적으로 하나 이상의 테이블 또는 데이터 원본에 대해 저장된 쿼리입니다.
- 함수: 스칼라 값 또는 행 집합을 반환하는 저장된 논리입니다.
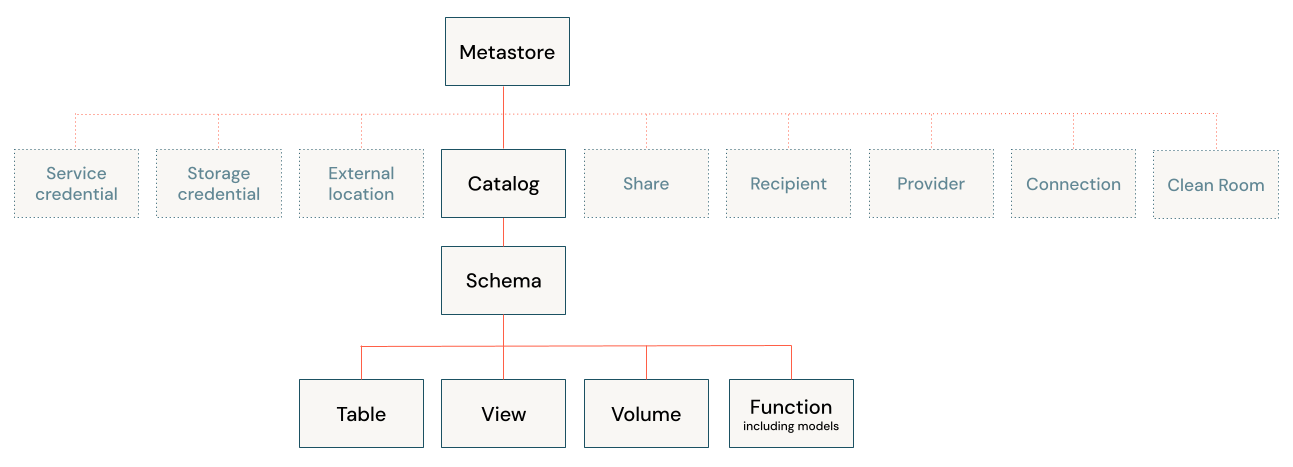
Unity 카탈로그로 개체를 보호하는 방법에 대한 자세한 내용은 보안 개체 모델을 참조하세요.
메타스토어란 무엇인가요?
메타스토어에는 Lakehouse의 데이터 개체를 정의하는 모든 메타데이터가 포함됩니다. Azure Databricks는 다음과 같은 메타스토어 옵션을 제공합니다.
Unity 카탈로그 메타스토어: Unity 카탈로그는 중앙 집중식 액세스 제어, 감사, 계보 및 데이터 검색 기능을 제공합니다. Azure Databricks 계정 수준에서 Unity 카탈로그 메타스토어를 만들고 여러 작업 영역에서 단일 메타스토어를 사용할 수 있습니다.
각 Unity 카탈로그 메타스토어는 Azure 계정의 Azure Data Lake Storage Gen2 컨테이너에 있는 루트 스토리지 위치로 구성됩니다. 이 스토리지 위치는 관리되는 테이블의 데이터를 저장하는 데 기본적으로 사용됩니다.
Unity 카탈로그에서 데이터는 기본적으로 안전합니다. 처음에는 사용자가 메타스토어의 데이터에 액세스할 수 없습니다. 메타스토어 관리자 또는 개체 소유자가 액세스 권한을 부여할 수 있습니다. Unity 카탈로그의 보안 개체는 계층적이며 권한은 아래로 상속됩니다. Unity 카탈로그는 데이터 액세스 정책을 관리할 수 있는 단일 위치를 제공합니다. 사용자는 메타스토어가 연결된 모든 작업 영역에서 Unity 카탈로그의 데이터에 액세스할 수 있습니다. 자세한 내용은 Unity 카탈로그의 권한 관리를 참조 하세요.
기본 제공 Hive 메타스토어(레거시): 각 Azure Databricks 작업 영역에는 관리 서비스로 기본 제공 Hive 메타스토어가 포함됩니다. 메타스토어의 인스턴스는 각 클러스터에 배포되고 각 고객 작업 영역의 중앙 리포지토리에서 메타데이터에 안전하게 액세스합니다.
Hive 메타스토어는 Unity 카탈로그보다 덜 중앙 집중화된 데이터 거버넌스 모델을 제공합니다. 기본적으로 클러스터를 사용하면 해당 클러스터에 대해 테이블 액세스 제어를 사용하도록 설정하지 않는 한 모든 사용자가 작업 영역의 기본 제공 Hive 메타스토어에서 관리하는 모든 데이터에 액세스할 수 있습니다. 자세한 내용은 Hive metastore 테이블 액세스 제어(레거시)를 참조하세요.
테이블 액세스 제어는 계정 수준에 저장되지 않으므로 각 작업 영역에 대해 별도로 구성해야 합니다. Unity 카탈로그에서 제공하는 중앙 집중식 및 간소화된 데이터 거버넌스 모델을 활용하기 위해 Databricks는 작업 영역의 Hive 메타스토어에서 관리하는 테이블을 Unity 카탈로그 메타스토어로 업그레이드하는 것이 좋습니다.
외부 Hive 메타스토어(레거시): Azure Databricks에 사용자 고유의 메타스토어를 가져올 수도 있습니다. Azure Databricks 클러스터는 기존 외부 Apache Hive 메타스토어에 연결할 수 있습니다. 테이블 액세스 제어를 사용하여 외부 메타스토어에서 권한을 관리할 수 있습니다. 테이블 액세스 제어는 외부 메타스토어에 저장되지 않으므로 각 작업 영역에 대해 별도로 구성해야 합니다. Databricks는 단순성과 계정 중심의 거버넌스 모델인 Unity 카탈로그를 대신 사용할 것을 권장합니다.
사용하는 메타스토어에 관계없이 Azure Databricks는 모든 테이블 데이터를 클라우드 계정의 개체 스토리지에 저장합니다.
카탈로그란 무엇인가요?
카탈로그는 Databricks Lakehouse 관계형 모델에서 가장 높은 추상화(또는 거친 곡물)입니다. 모든 데이터베이스는 카탈로그와 연결됩니다. 카탈로그는 메타스토어 내에서 개체로 존재합니다.
Unity 카탈로그를 도입하기 전에 Azure Databricks는 2계층 네임스페이스를 사용했습니다. 카탈로그는 Unity 카탈로그 네임스페이스 모델의 세 번째 계층입니다.
catalog_name.database_name.table_name
기본 제공 Hive 메타스토어는 단일 카탈로그 hive_metastore만 지원합니다.
데이터베이스란?
데이터베이스는 테이블이나 뷰("관계"라고도 함)와 같은 데이터 개체 및 함수의 컬렉션입니다. Azure Databricks에서 "스키마"와 "데이터베이스"라는 용어는 같은 의미로 사용됩니다(많은 관계형 시스템에서 데이터베이스는 스키마 컬렉션임).
데이터베이스는 항상 클라우드 개체 스토리지의 위치와 연결됩니다. 다음 사항을 염두에 두고 데이터베이스를 등록할 때 선택적으로 LOCATION을 지정할 수 있습니다.
- 데이터베이스와 연결된
LOCATION은 항상 관리 위치로 간주됩니다. - 데이터베이스를 만들어도 대상 위치에 파일이 만들어지지 않습니다.
- 데이터베이스의
LOCATION은 해당 데이터베이스에 등록된 모든 테이블의 데이터에 대한 기본 위치를 결정합니다. - 데이터베이스를 성공적으로 삭제하면 관리 위치에 저장된 모든 데이터와 파일이 반복적으로 삭제됩니다.
데이터베이스에서 관리하는 위치와 데이터 파일 간의 이러한 상호 작용은 매우 중요합니다. 실수로 데이터를 삭제하지 않으려면:
- 여러 데이터베이스 정의에서 데이터베이스 위치를 공유하지 마세요.
- 이미 데이터가 포함된 위치에 데이터베이스를 등록하지 마세요.
- 데이터베이스와 독립적으로 데이터 수명 주기를 관리하려면 데이터베이스 위치 아래에 중첩되지 않은 위치에 데이터를 저장합니다.
테이블이란?
Azure Databricks ‘테이블’은 table 정형 데이터 컬렉션입니다. Delta 테이블은 데이터를 클라우드 개체 스토리지에 파일 디렉터리로 저장하고 테이블 메타데이터를 카탈로그 및 스키마 내의 메타스토어에 등록합니다. Delta Lake는 Azure Databricks에서 만든 테이블의 기본 형식이므로 Databricks에서 만든 모든 테이블은 기본적으로 델타 테이블입니다. Delta 테이블은 데이터를 클라우드 개체 스토리지에 저장하고 메타스토어를 통해 데이터에 대한 참조를 제공하기 때문에 조직 전체의 사용자는 선호하는 API를 사용하여 데이터에 액세스할 수 있습니다. Databricks에서 여기에는 SQL, Python, PySpark, Scala 및 R이 포함됩니다.
Delta 테이블이 아닌 Databricks에서 테이블을 만들 수 있습니다. 이러한 테이블은 Delta Lake에서 지원하지 않으며 ACID 트랜잭션 및 Delta 테이블의 최적화된 성능을 제공하지 않습니다. 이 범주에 속하는 테이블에는 외부 시스템의 데이터에 대해 등록된 테이블과 데이터 레이크의 다른 파일 형식에 대해 등록된 테이블이 포함됩니다. 데이터 원본에 대한 커넥트 참조하세요.
Databricks에는 관리되는 테이블과 관리되지 않는(또는 외부) 테이블의 두 가지 종류가 있습니다.
참고 항목
라이브 테이블과 스트리밍 라이브 테이블 간의 Delta Live Tables 구분은 테이블 관점에서 적용되지 않습니다.
관리되는 테이블이란 무엇인가요?
Azure Databricks는 관리되는 테이블의 메타데이터와 데이터를 모두 관리합니다. 테이블을 삭제하면 기본 데이터도 삭제됩니다. 주로 SQL에서 작업하는 데이터 분석이 및 기타 사용자는 이 동작을 기본 설정할 수 있습니다. 테이블을 만들 때 기본값은 관리되는 테이블입니다. 관리되는 테이블의 데이터는 등록된 데이터베이스의 LOCATION에 있습니다. 데이터 위치와 데이터베이스 간의 관리되는 관계는 관리되는 테이블을 새 데이터베이스로 이동하기 위해 모든 데이터를 새 위치에 다시 작성해야 함을 의미합니다.
다음을 포함하여 관리되는 테이블을 만드는 방법에는 여러 가지가 있습니다.
CREATE TABLE table_name AS SELECT * FROM another_table
CREATE TABLE table_name (field_name1 INT, field_name2 STRING)
df.write.saveAsTable("table_name")
관리되지 않는 테이블이란 무엇인가요?
Azure Databricks는 관리되지 않는(외부) 테이블에 대한 메타데이터만 관리합니다. 테이블을 삭제할 때 기본 데이터에 영향을 주지 않습니다. 관리되지 않는 테이블은 테이블을 만드는 중에 항상 LOCATION을 지정합니다. 데이터 파일의 기존 디렉터리를 테이블로 등록하거나 테이블이 처음 정의될 때 경로를 제공할 수 있습니다. 데이터와 메타데이터는 독립적으로 관리되기 때문에 데이터를 이동할 필요 없이 테이블의 이름을 바꾸거나 새 데이터베이스에 등록할 수 있습니다. 데이터 엔지니어는 관리되지 않는 테이블과 프로덕션 데이터에 제공하는 유연성을 기본 설정하는 경우가 많습니다.
다음을 포함하여 관리되지 않는 테이블을 만드는 방법에는 여러 가지가 있습니다.
CREATE TABLE table_name
USING DELTA
LOCATION '/path/to/existing/data'
CREATE TABLE table_name
(field_name1 INT, field_name2 STRING)
LOCATION '/path/to/empty/directory'
df.write.option("path", "/path/to/empty/directory").saveAsTable("table_name")
뷰란?
뷰는 일반적으로 메타스토어에 있는 하나 이상의 데이터 원본 또는 테이블에 대한 쿼리 텍스트를 저장합니다. Databricks에서 뷰는 데이터베이스의 개체로 유지되는 Spark DataFrame과 동일합니다. DataFrames와 달리 권한이 있는 경우 Databricks 제품의 모든 부분에서 뷰를 쿼리할 수 있습니다. 뷰를 만들면 데이터가 처리되거나 작성되지 않습니다. 쿼리 텍스트만 연결된 데이터베이스의 메타스토어에 등록됩니다.
임시 뷰란 무엇인가요?
임시 뷰는 제한된 범위와 지속성을 가지며 스키마나 카탈로그에 등록되지 않습니다. 임시 뷰의 수명은 사용 중인 환경에 따라 다릅니다.
- Notebooks 및 작업에서 임시 뷰의 범위는 Notebooks 또는 스크립트 수준입니다. 선언된 Notebook 외부에서 참조할 수 없으며 Notebook이 클러스터에서 분리되면 더 이상 존재하지 않습니다.
- Databricks SQL에서 임시 뷰의 범위는 쿼리 수준입니다. 동일한 쿼리 내의 여러 문이 임시 뷰를 사용할 수 있지만 동일한 대시보드 내에서도 다른 쿼리에서 참조할 수 없습니다.
- 전역 임시 뷰는 클러스터 수준으로 범위가 지정되며 컴퓨팅 리소스를 공유하는 Notebooks 또는 작업 간에 공유할 수 있습니다. Databricks는 전역 임시 뷰 대신 적절한 테이블 ACL이 있는 뷰를 사용할 것을 권장합니다.
함수란 무엇인가요?
함수를 사용하면 사용자 정의 논리를 데이터베이스와 연결할 수 있습니다. 함수는 스칼라 값 또는 행 집합을 반환할 수 있습니다. 함수는 데이터를 집계하는 데 사용됩니다. Azure Databricks를 사용하면 SQL이 광범위하게 지원되므로 실행 컨텍스트에 따라 다양한 언어로 함수를 저장할 수 있습니다. 함수를 사용하여 Databricks 제품의 다양한 컨텍스트에서 사용자 지정 논리에 대한 관리 액세스를 제공할 수 있습니다.
관계형 개체는 Delta Live Tables에서 어떻게 작동하나요?
Delta Live Tables는 선언적 구문을 사용하여 DDL, DML 및 인프라 배포를 정의하고 관리합니다. Delta Live Tables는 논리 계획 및 실행 중에 "가상 스키마" 개념을 사용합니다. Delta Live Tables는 Databricks 환경의 다른 데이터베이스와 상호 작용할 수 있으며 Delta Live Tables는 파이프라인 구성 설정에서 대상 데이터베이스를 지정하여 다른 곳에서 쿼리하기 위해 테이블을 게시하고 유지할 수 있습니다.
델타 라이브 테이블에서 만든 모든 테이블은 델타 테이블입니다. 델타 라이브 테이블에서 Unity 카탈로그를 사용하는 경우 모든 테이블은 Unity 카탈로그 관리 테이블입니다. Unity 카탈로그가 활성화되지 않은 경우 테이블을 관리 테이블 또는 관리되지 않는 테이블로 선언할 수 있습니다.
뷰는 Delta Live Tables에서 선언할 수 있지만 파이프라인으로 범위가 지정된 임시 뷰로 간주해야 합니다. Delta Live Tables의 임시 테이블은 고유한 개념입니다. 이러한 테이블은 데이터를 스토리지에 유지하지만 대상 데이터베이스에 데이터를 게시하지는 않습니다.
APPLY CHANGES INTO와 같은 일부 작업은 테이블과 뷰를 모두 데이터베이스에 등록합니다. 테이블 이름은 밑줄(_)로 시작하고 뷰에는 APPLY CHANGES INTO 작업의 대상으로 선언된 테이블 이름이 있습니다. 뷰는 결과를 구체화하기 위해 해당하는 숨겨진 테이블을 쿼리합니다.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기