데이터 레이크하우스란?
데이터 레이크 하우스는 데이터 레이크와 데이터 웨어하우스의 이점을 결합한 데이터 관리 시스템입니다. 이 문서에서는 레이크하우스 아키텍처 패턴과 Azure Databricks에서 수행할 수 있는 작업을 설명합니다.
데이터 레이크하우스의 용도는 무엇인가요?
데이터 레이크하우스는 ML(기계 학습) 및 BI(비즈니스 인텔리전스)와 같은 다양한 워크로드를 처리하기 위해 격리된 시스템을 방지하려는 최신 조직에 확장 가능한 스토리지 및 처리 기능을 제공합니다. 데이터 레이크하우스는 단일 진실 소스를 설정하고 중복 비용을 제거하며 데이터 새로 고침을 보장하는 데 도움이 될 수 있습니다.
데이터 레이크하우스는 스테이징 및 변환 계층을 통해 이동할 때 데이터를 증분 방식으로 개선, 보강 및 구체화하는 데이터 디자인 패턴을 사용하는 경우가 많습니다. 레이크하우스의 각 레이어에는 하나 이상의 레이어가 포함될 수 있습니다. 이 패턴을 medallion 아키텍처라고도 합니다. 자세한 내용은 medallion Lakehouse 아키텍처란?
Databricks 레이크하우스는 어떻게 작동하나요?
Databricks는 Apache Spark를 기반으로 합니다. Apache Spark를 사용하면 스토리지에서 분리된 컴퓨팅 리소스에서 실행되는 확장성이 뛰어난 대규모 엔진을 사용할 수 있습니다. 자세한 내용은 Azure Databricks의 Apache Spark를 참조 하세요.
Databricks 레이크하우스는 다음 두 가지 핵심 기술을 추가로 사용합니다.
- Delta Lake: ACID 트랜잭션 및 스키마 적용을 지원하는 최적화된 스토리지 계층입니다.
- Unity 카탈로그: 데이터 및 AI를 위한 통합되고 세분화된 거버넌스 솔루션입니다.
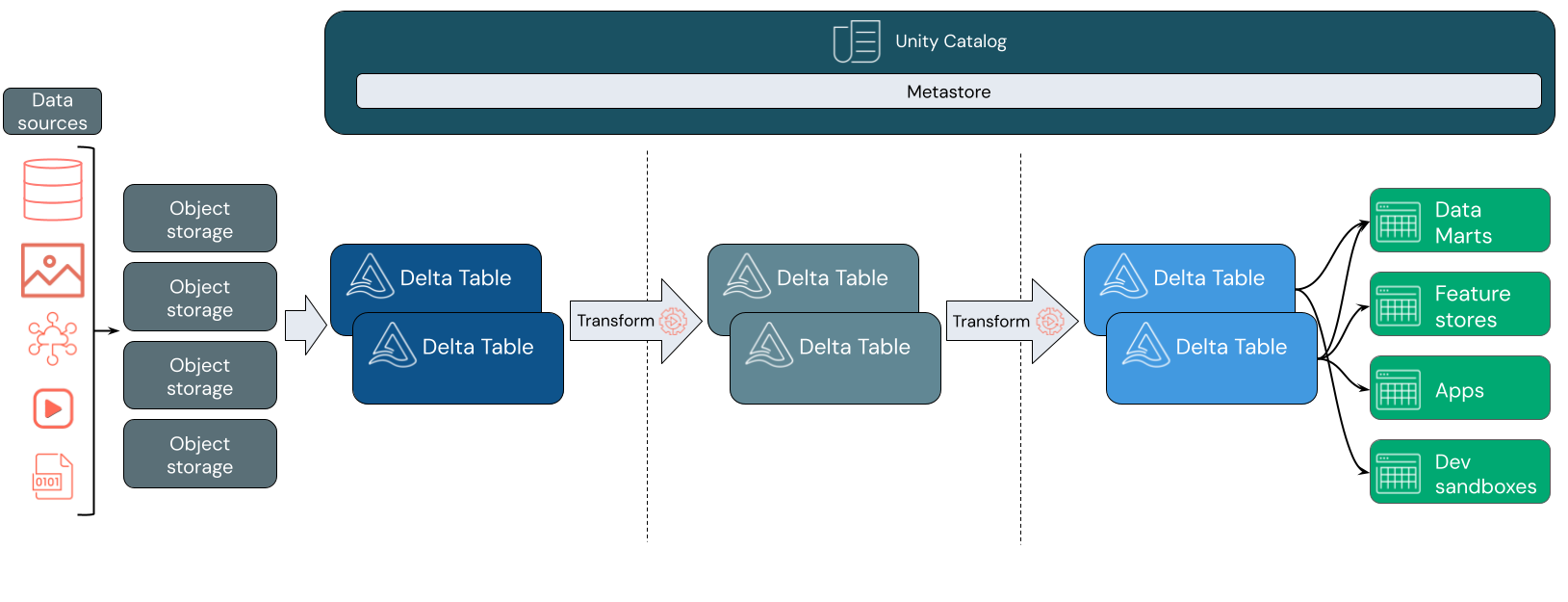
데이터 수집
수집 계층에서 일괄 처리 또는 스트리밍 데이터는 다양한 원본과 다양한 형식으로 도착합니다. 이 첫 번째 논리 계층은 해당 데이터가 원시 형식으로 배치되는 위치를 제공합니다. 이러한 파일을 델타 테이블로 변환할 때 Delta Lake의 스키마 적용 기능을 사용하여 누락되거나 예기치 않은 데이터를 검사 수 있습니다. Unity 카탈로그를 사용하여 데이터 거버넌스 모델 및 필요한 데이터 격리 경계에 따라 테이블을 등록할 수 있습니다. Unity 카탈로그를 사용하면 데이터의 계보를 변환 및 구체화할 때 추적할 수 있을 뿐만 아니라 통합 거버넌스 모델을 적용하여 중요한 데이터를 비공개로 안전하게 유지할 수 있습니다.
데이터 처리, 큐레이션 및 통합
확인되면 데이터 큐레이팅 및 구체화를 시작할 수 있습니다. 데이터 과학자와 기계 학습 실무자는 이 단계에서 데이터를 자주 사용하여 새로운 기능을 결합하거나 만들고 데이터 클린 작업을 완료하기 시작합니다. 데이터가 완전히 클린 되면 특정 비즈니스 요구 사항을 충족하도록 설계된 테이블로 통합하고 재구성할 수 있습니다.
델타 스키마 진화 기능과 결합된 쓰기 기반 스키마 접근 방식은 최종 사용자에게 데이터를 제공하는 다운스트림 논리를 반드시 다시 작성하지 않고도 이 계층을 변경할 수 있음을 의미합니다.
데이터 서비스
최종 계층은 최종 사용자에게 클린 보강된 데이터를 제공합니다. 최종 테이블은 모든 사용 사례에 대한 데이터를 제공하도록 설계되어야 합니다. 통합 거버넌스 모델은 데이터 계보를 단일 진리 원본으로 다시 추적할 수 있습니다. 다양한 작업에 최적화된 데이터 레이아웃을 사용하면 최종 사용자가 기계 학습 애플리케이션, 데이터 엔지니어링 및 비즈니스 인텔리전스 및 보고를 위한 데이터에 액세스할 수 있습니다.
Delta Lake에 대한 자세한 내용은 Delta Lake 란? Unity 카탈로그에 대한 자세한 내용은 Unity 카탈로그 란?
Databricks 레이크하우스의 기능
Databricks를 기반으로 하는 레이크하우스는 최신 데이터 회사의 데이터 레이크 및 데이터 웨어하우스에 대한 현재 종속성을 대체합니다. 수행할 수 있는 몇 가지 주요 작업은 다음과 같습니다.
- 실시간 데이터 처리: 즉각적인 분석 및 작업을 위해 실시간으로 스트리밍 데이터를 처리합니다.
- 데이터 통합: 단일 시스템에서 데이터를 통합하여 공동 작업을 가능하게 하고 조직에 대한 단일 진실 소스를 설정합니다.
- 스키마 진화: 기존 데이터 파이프라인을 방해하지 않고 변화하는 비즈니스 요구에 맞게 시간에 따라 데이터 스키마를 수정합니다.
- 데이터 변환: Apache Spark 및 Delta Lake를 사용하면 데이터에 속도, 확장성 및 안정성이 제공됩니다.
- 데이터 분석 및 보고: 데이터 웨어하우징 워크로드에 최적화된 엔진을 사용하여 복잡한 분석 쿼리를 실행합니다.
- 기계 학습 및 AI: 모든 데이터에 고급 분석 기술을 적용합니다. ML을 사용하여 데이터를 보강하고 다른 워크로드를 지원합니다.
- 데이터 버전 관리 및 계보: 데이터 세트의 버전 기록을 유지하고 계보를 추적하여 데이터 출처 및 추적 가능성을 보장합니다.
- 데이터 거버넌스: 단일 통합 시스템을 사용하여 데이터에 대한 액세스를 제어하고 감사를 수행합니다.
- 데이터 공유: 팀 전체에서 큐레이팅된 데이터 세트, 보고서 및 인사이트를 공유할 수 있도록 하여 공동 작업을 용이하게 합니다.
- 운영 분석: 레이크하우스 모니터링 데이터에 기계 학습을 적용하여 데이터 품질 메트릭, 모델 품질 메트릭 및 드리프트를 모니터링합니다.
Lakehouse vs Data Lake vs Data Warehouse
데이터 웨어하우스는 데이터 흐름을 제어하는 시스템에 대한 일련의 디자인 지침으로 발전하여 약 30년 동안 BI(비즈니스 인텔리전스) 결정을 내렸습니다. 엔터프라이즈 데이터 웨어하우스는 BI 보고서에 대한 쿼리를 최적화하지만 결과를 생성하는 데 몇 분 또는 몇 시간이 걸릴 수 있습니다. 자주 변경되지 않는 데이터를 위해 설계된 데이터 웨어하우스는 동시에 실행되는 쿼리 간의 충돌을 방지하려고 합니다. 많은 데이터 웨어하우스에서 독점적인 형식을 사용하며, 이에 따라 기계 학습에 대한 지원을 제한하는 경우가 많습니다. Azure Databricks의 데이터 웨어하우징은 Databricks Lakehouse 및 Databricks SQL의 기능을 활용합니다. 자세한 내용은 Azure Databricks의 데이터 웨어하우징이란?을 참조하세요.
데이터 레이크는 데이터 스토리지의 기술 발전과 데이터의 형식 및 볼륨의 기하급수적인 증가로 인해 지난 10년 동안 광범위하게 사용되었습니다. 데이터 레이크는 데이터를 저렴하고 효율적인 방식으로 저장하고 처리합니다. 데이터 레이크는 데이터 웨어하우스와 반대로 정의되는 경우가 많습니다. 데이터 웨어하우스는 BI 분석을 위해 순수한 정형 데이터를 제공하는 반면, 데이터 레이크는 모든 형식의 데이터를 영구적이고 저렴하게 저장합니다. 많은 조직에서 데이터 레이크를 데이터 과학 및 기계 학습에 사용하지만, 유효성이 검사되지 않은 특성으로 인해 BI 보고에는 사용하지 않습니다.
데이터 레이크 하우스는 데이터 레이크와 데이터 웨어하우스의 이점을 결합하고 다음을 제공합니다.
- 표준 데이터 형식으로 저장된 데이터에 대한 개방형 직접 액세스
- 기계 학습 및 데이터 과학에 최적화된 인덱싱 프로토콜
- BI 및 고급 분석을 위한 짧은 쿼리 대기 시간 및 높은 안정성
최적화된 메타데이터 계층을 클라우드 개체 스토리지에 표준 형식으로 저장된 유효성 검사된 데이터와 결합하여 데이터 과학자와 ML 엔지니어가 동일한 데이터 기반 BI 보고서에서 모델을 빌드할 수 있도록 합니다.
다음 단계
Databricks를 사용하여 레이크하우스를 구현하고 운영하기 위한 원칙과 모범 사례에 대해 자세히 알아보려면 잘 설계된 데이터 레이크하우스 소개를 참조 하세요.