CDC(변경 데이터 캡처)는 삽입, 업데이트 및 삭제와 같은 원본 시스템의 데이터에 대한 변경 내용을 캡처하는 데이터 통합 패턴입니다. 목록으로 표시되는 이러한 변경 내용을 일반적으로 CDC 피드라고 합니다. 전체 원본 데이터 세트를 읽는 대신 CDC 피드에서 작동하는 경우 데이터를 훨씬 더 빠르게 처리할 수 있습니다. SQL Server, MySQL 및 Oracle과 같은 트랜잭션 데이터베이스는 CDC 피드를 생성합니다. 델타 테이블은 CDF(변경 데이터 피드)라고 하는 자체 CDC 피드를 생성합니다.
다음 다이어그램은 직원 데이터가 포함된 원본 테이블의 행이 업데이트되면 변경 내용 만 포함된 CDC 피드에 새 행 집합을 생성한다는 것을 보여 줍니다. CDC 피드의 각 행에는 일반적으로 각각의 행에 대한 작업, 예를 들어 UPDATE 같은 추가 메타데이터가 포함되며, 이는 순서가 뒤바뀐 업데이트를 관리할 수 있도록 CDC 피드의 각 행을 체계적으로 정렬하는 데 사용할 수 있는 열이 함께 제공됩니다. 예를 들어 sequenceNum 다음 다이어그램의 열은 CDC 피드의 행 순서를 결정합니다.
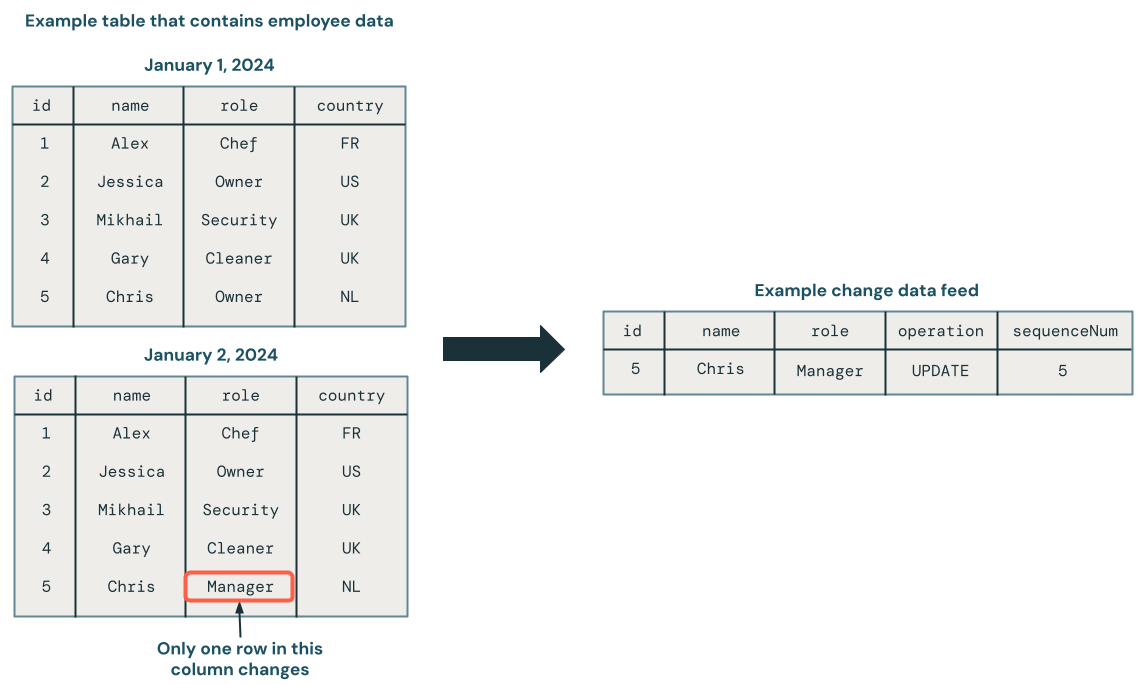
변경 데이터 피드 처리: 최신 데이터만 유지 및 기록 버전의 데이터 유지
변경된 데이터 피드의 처리를 느리게 변하는 차원(SCD)이라고 합니다. CDC 피드를 처리할 때 다음을 선택할 수 있습니다.
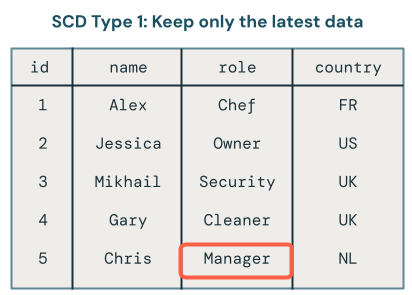
- 최신 데이터만 유지합니까(즉, 기존 데이터 덮어쓰기)? 이를 SCD 형식 1이라고합니다.
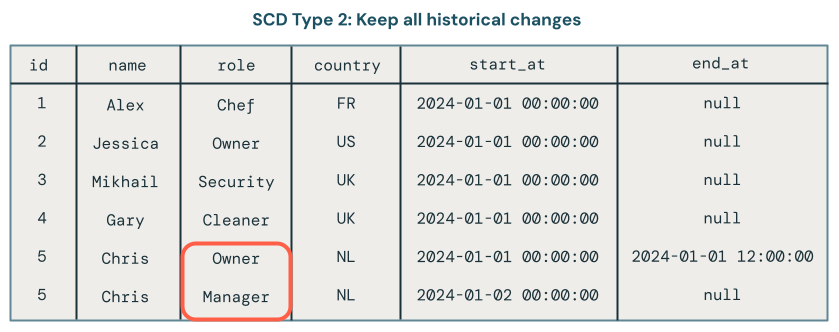
- 또는 데이터 변경 기록을 보관합니까? 이를 SCD 유형 2라고합니다.
SCD 형식 1 처리에는 변경이 발생할 때마다 이전 데이터를 새 데이터로 덮어쓰는 작업이 포함됩니다. 즉, 변경 내용의 기록이 유지되지 않습니다. 최신 버전의 데이터만 사용할 수 있습니다. 이는 간단한 접근 방식이며 오류 수정 또는 고객 전자 메일 주소와 같은 중요하지 않은 필드 업데이트와 같이 변경 기록이 중요하지 않은 경우에 자주 사용됩니다.
SCD 형식 2 처리는 시간이 지남에 따라 다른 버전의 데이터를 캡처하는 추가 레코드를 만들어 데이터 변경의 기록 레코드를 유지 관리합니다. 데이터의 각 버전은 타임스탬프가 지정되거나 사용자가 변경이 발생한 시기를 추적할 수 있는 메타데이터로 태그가 지정됩니다. 이는 분석 목적으로 시간 경과에 따른 고객 주소 변경 내용 추적과 같이 데이터의 진화를 추적하는 것이 중요한 경우에 유용합니다.
Lakeflow Spark 선언적 파이프라인을 사용한 SCD Type 1 및 Type 2 처리의 예
이 섹션의 예제에서는 SCD 형식 1 및 형식 2를 사용하는 방법을 보여 줍니다.
1단계: 샘플 데이터 준비
이 예제에서는 샘플 CDC 피드를 생성합니다. 먼저 Notebook을 만들고 다음 코드를 붙여넣습니다. 코드 블록의 시작 부분에 있는 변수를 테이블 및 뷰를 만들 수 있는 권한이 있는 카탈로그 및 스키마로 업데이트합니다.
이 코드는 여러 변경 레코드가 포함된 새 Delta 테이블을 만듭니다. 스키마는 다음과 같습니다.
-
id- 정수, 이 직원의 고유 식별자 -
name- 문자열, 직원의 이름 -
role- 문자열, 직원의 역할 -
country- 문자열, 국가 코드, 직원이 근무하는 위치 -
operation- 형식 변경(예:INSERT,UPDATE또는DELETE) -
sequenceNum- 정수는 원본 데이터에서 CDC 이벤트의 논리적 순서를 식별합니다. Lakeflow Spark 선언적 파이프라인은 이 시퀀싱을 사용하여 순서가 잘못 도착하는 변경 이벤트를 처리합니다.
# update these to the catalog and schema where you have permissions
# to create tables and views.
catalog = "mycatalog"
schema = "myschema"
employees_cdf_table = "employees_cdf"
def write_employees_cdf_to_delta():
data = [
(1, "Alex", "chef", "FR", "INSERT", 1),
(2, "Jessica", "owner", "US", "INSERT", 2),
(3, "Mikhail", "security", "UK", "INSERT", 3),
(4, "Gary", "cleaner", "UK", "INSERT", 4),
(5, "Chris", "owner", "NL", "INSERT", 6),
# out of order update, this should be dropped from SCD Type 1
(5, "Chris", "manager", "NL", "UPDATE", 5),
(6, "Pat", "mechanic", "NL", "DELETE", 8),
(6, "Pat", "mechanic", "NL", "INSERT", 7)
]
columns = ["id", "name", "role", "country", "operation", "sequenceNum"]
df = spark.createDataFrame(data, columns)
df.write.format("delta").mode("overwrite").saveAsTable(f"{catalog}.{schema}.{employees_cdf_table}")
write_employees_cdf_to_delta()
다음 SQL 명령을 사용하여 이 데이터를 미리 볼 수 있습니다.
SELECT *
FROM mycatalog.myschema.employees_cdf
2단계: SCD 유형 1을 사용하여 최신 데이터만 유지
Lakeflow Spark 선언적 파이프라인에서 API를 사용하여 AUTO CDC 변경 데이터 피드를 SCD 형식 1 테이블로 처리하는 것이 좋습니다.
- 새 Notebook을 만듭니다.
- 다음 코드를 붙여넣습니다.
- 파이프라인을 만들고 연결합니다.
이 함수는 employees_cdf 변경 데이터 캡처 처리에 사용할 API가 변경 스트림을 입력으로 예상하기 때문에 create_auto_cdc_flow 위에서 방금 만든 테이블을 스트림으로 읽습니다. 테이블로 구체화하지 않기 위해 이 스트림을 데코레이터 @dp.temporary_view로 감쌉니다.
그런 다음, 이 변경 데이터 피드를 처리한 결과를 포함하는 스트리밍 테이블을 만드는 데 사용합니다 dp.create_target_table .
마지막으로 변경 데이터 피드를 처리하는 데 사용합니다 dp.create_auto_cdc_flow . 각 인수를 살펴보겠습니다.
-
target- 이전에 정의한 대상 스트리밍 테이블입니다. -
source- 이전에 정의한 변경 레코드 스트림에 대한 뷰입니다. -
keys- 변경 피드의 고유 행을 식별합니다.id를 고유 식별자로 사용하고 있으므로,id을(를) 유일한 식별 열로 제공하면 됩니다. -
sequence_by- 원본 데이터에서 CDC 이벤트의 논리적 순서를 지정하는 열 이름입니다. 순서가 맞지 않게 도착하는 변경 이벤트를 처리하려면 이 시퀀싱이 필요합니다.sequenceNum을(를) 시퀀싱 열로 제공합니다. -
apply_as_deletes예제 데이터에 삭제 작업이 포함되어 있으면,apply_as_deletes를 사용하여 CDC 이벤트가 upsert가 아닌DELETE으로 처리되어야 하는 시기를 나타냅니다. -
except_column_list- 대상 테이블에 포함하지 않으려는 열 목록을 포함합니다. 이 예제에서는 이 인수를 사용하여sequenceNum와operation를 제외합니다. -
stored_as_scd_type- 사용할 SCD 형식을 나타냅니다.
from pyspark import pipelines as dp
from pyspark.sql.functions import col, expr, lit, when
from pyspark.sql.types import StringType, ArrayType
catalog = "mycatalog"
schema = "myschema"
employees_cdf_table = "employees_cdf"
employees_table_current = "employees_current"
employees_table_historical = "employees_historical"
@dp.temporary_view
def employees_cdf():
return spark.readStream.format("delta").table(f"{catalog}.{schema}.{employees_cdf_table}")
dp.create_target_table(f"{catalog}.{schema}.{employees_table_current}")
dp.create_auto_cdc_flow(
target=f"{catalog}.{schema}.{employees_table_current}",
source=employees_cdf_table,
keys=["id"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
except_column_list = ["operation", "sequenceNum"],
stored_as_scd_type = 1
)
시작을 클릭하여 이 파이프라인을 실행 합니다.
그런 다음 SQL 편집기에서 다음 쿼리를 실행하여 변경 레코드가 올바르게 처리되었는지 확인합니다.
SELECT *
FROM mycatalog.myschema.employees_current
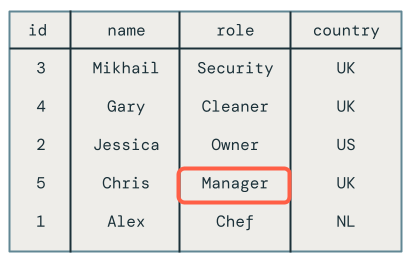
비고
직원 Chris의 순서에서 벗어난 업데이트는 그들의 역할이 여전히 관리자가 아닌 소유자로 설정되어 있어 올바르게 삭제되었습니다.
3단계: SCD 형식 2를 사용하여 기록 데이터 유지
이 예제에서는 직원 레코드에 대한 변경 내용의 전체 기록을 포함하는 두 번째 대상 테이블을 employees_historical만듭니다.
파이프라인에 이 코드를 추가합니다. 여기서 유일한 차이점은 1이 아닌 2로 설정된다는 stored_as_scd_type 것입니다.
dp.create_target_table(f"{catalog}.{schema}.{employees_table_historical}")
dp.create_auto_cdc_flow(
target=f"{catalog}.{schema}.{employees_table_historical}",
source=employees_cdf_table,
keys=["id"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
except_column_list = ["operation", "sequenceNum"],
stored_as_scd_type = 2
)
시작을 클릭하여 이 파이프라인을 실행 합니다.
그런 다음 SQL 편집기에서 다음 쿼리를 실행하여 변경 레코드가 올바르게 처리되었는지 확인합니다.
SELECT *
FROM mycatalog.myschema.employees_historical
삭제된 직원(예: Pat)을 포함하여 직원의 모든 변경 내용이 표시됩니다.
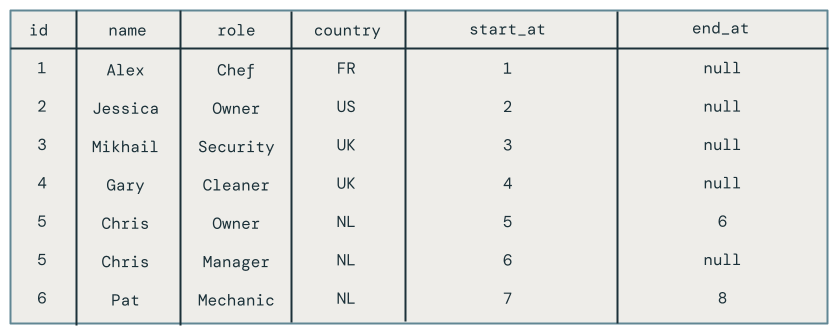
4단계: 리소스 정리
완료되면 다음 단계에 따라 리소스를 정리합니다.
파이프라인을 삭제합니다.
비고
파이프라인을 삭제하면
employees및employees_historical테이블이 자동으로 삭제됩니다.- 작업 및 파이프라인을 클릭한 다음 삭제할 파이프라인의 이름을 찾습니다.
-
 을 클릭합니다. 같은 행에서 파이프라인 이름을 지정한 다음 삭제를 클릭합니다.
을 클릭합니다. 같은 행에서 파이프라인 이름을 지정한 다음 삭제를 클릭합니다.
전자 필기장을 삭제합니다.
변경 데이터 피드가 포함된 테이블을 삭제합니다.
- 새 > 쿼리를 클릭합니다.
- 카탈로그 및 스키마를 적절하게 조정하여 다음 SQL 코드를 붙여넣고 실행합니다.
DROP TABLE mycatalog.myschema.employees_cdf
변경 데이터 캡처 사용 MERGE INTO 및 foreachBatch 사용의 단점
Databricks는 MERGE INTO SQL 명령을 제공하며 이는 API와 함께 사용하여 델타 테이블에 행을 업서트할 수 있습니다foreachBatch. 이 섹션에서는 이 기술을 간단한 사용 사례에 사용할 수 있는 방법을 살펴보지만 실제 시나리오에 적용할 때 이 메서드는 점점 더 복잡하고 취약해집니다.
이 예제에서는 이전 예제에서 사용한 것과 동일한 샘플 변경 데이터 피드를 사용합니다.
Naive 구현 및 MERGE INTOforeachBatch
Notebook을 만들고 다음 코드를 복사합니다.
catalog변수 schema및 employees_table 변수를 적절하게 변경합니다.
catalog 및 schema 변수는 테이블을 만들 수 있는 Unity 카탈로그의 위치로 각각 설정해야 합니다.
Notebook을 실행하면 다음을 수행합니다.
-
create_table에 대상 테이블을 만듭니다. 이 단계를 자동으로 처리하는 것과 달리create_auto_cdc_flow스키마를 지정해야 합니다. - 변경 데이터 피드를 스트림으로 읽습니다. 각 마이크로배치는
upsertToDelta메서드를 사용하여 처리되며, 이는MERGE INTO명령을 실행합니다.
catalog = "jobs"
schema = "myschema"
employees_cdf_table = "employees_cdf"
employees_table = "employees_merge"
def upsertToDelta(microBatchDF, batchId):
microBatchDF.createOrReplaceTempView("updates")
microBatchDF.sparkSession.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
def create_table():
spark.sql(f"DROP TABLE IF EXISTS {catalog}.{schema}.{employees_table}")
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {catalog}.{schema}.{employees_table}
(id INT, name STRING, age INT, country STRING)
""")
create_table()
cdcData = spark.readStream.table(f"{catalog}.{schema}.{employees_cdf_table}")
cdcData.writeStream \
.foreachBatch(upsertToDelta) \
.outputMode("append") \
.start()
결과를 보려면 다음 SQL 쿼리를 실행합니다.
SELECT *
FROM mycatalog.myschema.employees_merge
아쉽게도 다음과 같이 결과가 잘못되었습니다.
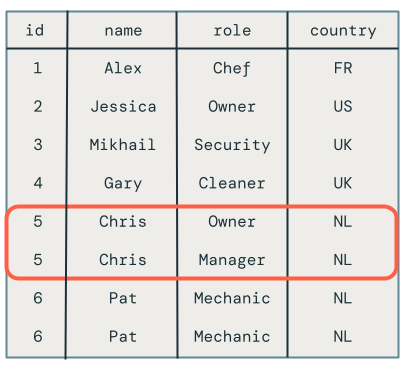
동일한 마이크로배치에서 동일한 키에 대한 여러 업데이트
첫 번째 문제는 코드가 동일한 마이크로배치에서 동일한 키에 대한 여러 업데이트를 처리하지 않는다는 것입니다. 예를 들어 직원 Chris를 삽입한 다음 해당 역할을 소유자에서 관리자로 업데이트하는 데 사용합니다 INSERT . 이렇게 하면 한 행이 생성되지만 대신 두 개의 행이 있습니다.
마이크로배치에서 동일한 키에 대한 업데이트가 여러 개 있는 경우 어떤 변경이 승리합니까?
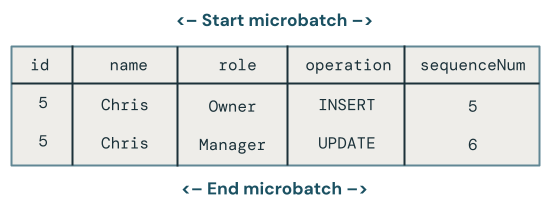
논리는 더 복잡해집니다. 다음 코드 예제에서는 최신 행을 검색하고 sequenceNum 다음과 같이 해당 데이터만 대상 테이블에 병합합니다.
- 기본 키로 그룹화합니다
id. - 해당 키에 대한 일괄 처리의 최대
sequenceNum값을 포함하는 행의 모든 열을 가져옵니다. - 행을 다시 확장합니다.
다음과 같이 메서드를 upsertToDelta 업데이트한 다음 코드를 실행합니다.
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
대상 테이블을 쿼리할 때 Chris라는 직원이 올바른 역할을 가지고 있음을 알 수 있지만 대상 테이블에 표시되는 레코드를 삭제했기 때문에 해결해야 할 다른 문제가 여전히 있습니다.
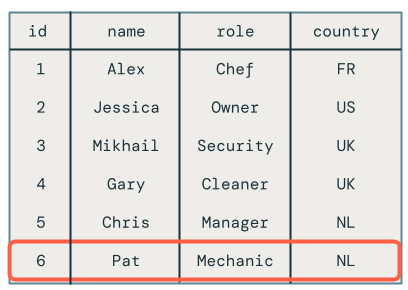
마이크로배치 간의 순서를 벗어난 업데이트
이 섹션에서는 마이크로배치 전체에서 순서가 다른 업데이트의 문제를 살펴봅니다. 다음 다이어그램은 다음과 같은 문제를 설명합니다: Chris의 행에 첫 번째 마이크로배치에서 UPDATE 연산이 발생하고, 후속 마이크로배치에서 INSERT 연산이 이어진다면 어떻게 될까요? 코드가 이를 올바르게 처리하지 않습니다.
여러 마이크로배치에서 동일한 키에 대한 업데이트가 순서에 맞지 않게 이뤄질 때, 어떤 변화가 이깁니까?
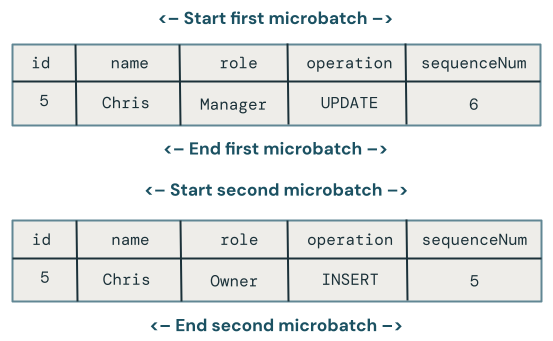
이 문제를 해결하려면 코드를 확장하여 다음과 같이 각 행에 버전을 저장합니다.
- 행이 마지막으로 업데이트된 시점을
sequenceNum에 저장합니다. - 각 새 행에 대해 타임스탬프가 저장된 행보다 큰지 확인한 다음, 다음 논리를 적용합니다.
- 더 큰 경우 대상의 새 데이터를 사용합니다.
- 그렇지 않으면 원본에 데이터를 유지합니다.
먼저 createTable을 저장하도록 메서드를 업데이트합니다. 각 행의 버전을 지정하는 데 이 값을 사용할 것입니다.
def create_table():
spark.sql(f"DROP TABLE IF EXISTS {catalog}.{schema}.{employees_table}")
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {catalog}.{schema}.{employees_table}
(id INT, name STRING, age INT, country STRING, sequenceNum INT)
""")
upsertToDelta을 다음으로 업데이트하여 행 버전을 처리합니다.
UPDATE SET 조건은 MERGE INTO의 모든 열을 개별적으로 처리해야 합니다.
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED THEN UPDATE SET
name=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.name ELSE t.name END,
age=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.age ELSE t.age END,
country=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.country ELSE t.country END
WHEN NOT MATCHED THEN INSERT *
""")
삭제 처리
아쉽게도 코드에는 여전히 문제가 있습니다.
DELETE 작업을 처리하지 않는다는 것은 직원 Pat이 여전히 대상 테이블에 남아 있다는 사실에서 볼 수 있습니다.
삭제가 동일한 마이크로배치에 도착한다고 가정해 보겠습니다. 이를 처리하려면 다음과 같이 변경 데이터 레코드가 삭제를 나타내는 경우 행을 삭제하도록 메서드를 다시 업데이트 upsertToDelta 합니다.
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED AND s.operation = 'DELETE' THEN DELETE
WHEN MATCHED THEN UPDATE SET
name=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.name ELSE t.name END,
age=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.age ELSE t.age END,
country=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.country ELSE t.country END
WHEN NOT MATCHED THEN INSERT *
""")
삭제 후 잘못된 순서로 도착하는 업데이트 처리
아쉽게도 위의 코드는 마이크로배치 간에 DELETE 다음에 순서가 잘못된 UPDATE이 오는 경우를 처리하지 않기 때문에 여전히 완벽하지 않습니다.
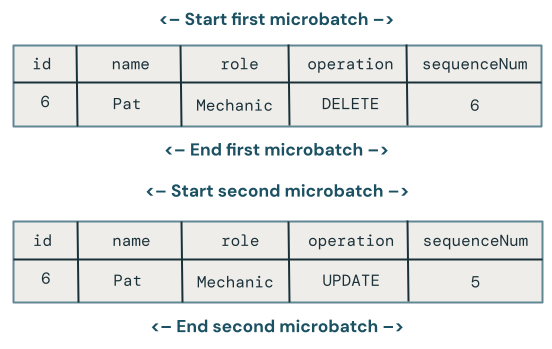
이 경우를 처리하는 알고리즘은 비순차적 업데이트를 처리할 수 있도록 삭제 내역을 기억해야 합니다. 이렇게 하려면 다음을 수행합니다.
- 행을 즉시 삭제하는 대신 타임스탬프 또는
sequenceNum로 일시 삭제합니다. 일시 삭제된 행은 삭제됩니다. - 모든 사용자를 삭제된 항목을 필터링하는 보기로 리디렉션합니다.
- 시간이 지남에 따라 툼스톤을 제거하는 정리 작업을 설계합니다.
다음 코드를 사용합니다.
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED AND s.operation = 'DELETE' THEN UPDATE SET DELETED_AT=now()
WHEN MATCHED THEN UPDATE SET
name=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.name ELSE t.name END,
age=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.age ELSE t.age END,
country=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.country ELSE t.country END
WHEN NOT MATCHED THEN INSERT *
""")
사용자는 대상 테이블을 직접 사용할 수 없으므로 쿼리할 수 있는 보기를 만듭니다.
CREATE VIEW employees_v AS
SELECT * FROM employees_merge
WHERE DELETED_AT = NULL
마지막으로, 툼스톤 처리된 행을 주기적으로 제거하는 정리 작업을 설정합니다.
DELETE FROM employees_merge
WHERE DELETED_AT < now() - INTERVAL 1 DAY