Databricks 기능 제공 기능을 사용하면 Databricks 플랫폼의 데이터를 Azure Databricks 외부에서 배포된 모델 또는 애플리케이션에서 사용할 수 있습니다. 기능 서비스 엔드포인트는 자동으로 크기가 조정되어 실시간 트래픽에 맞게 조정되고 기능을 제공하기 위한 고가용성 대기 시간이 짧은 서비스를 제공합니다. 이 페이지에서는 기능 제공을 설정하고 사용하는 방법을 설명합니다. 단계별 자습서는 예제: 엔드포인트를 제공하는 기능 배포 및 쿼리를 참조하세요.
Mosaic AI Model Serving를 사용하여 Databricks의 기능을 사용하여 빌드된 모델을 제공하는 경우 모델은 자동으로 유추 요청에 대한 기능을 조회하고 변환합니다. Databricks 기능 제공을 사용하면 RAG(검색 보강 세대) 애플리케이션뿐만 아니라 Databricks 외부에서 제공되는 모델 또는 Unity 카탈로그의 데이터를 기반으로 하는 기능이 필요한 다른 애플리케이션과 같은 다른 애플리케이션에 필요한 기능을 위해 구조화된 데이터를 제공할 수 있습니다.
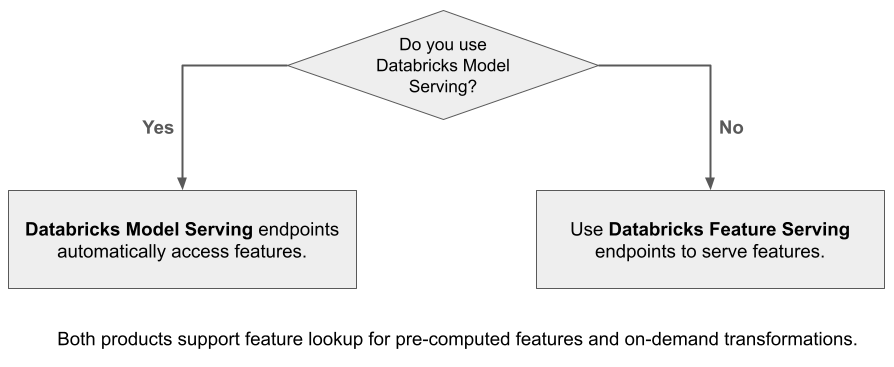
기능 제공을 사용하는 이유는 무엇인가요?
Databricks 기능 제공은 미리 구체화된 주문형 기능을 제공하는 단일 인터페이스를 제공합니다. 또한 다음과 같은 혜택이 포함됩니다.
- 단순성입니다. Databricks는 인프라를 처리합니다. 단일 API 호출을 통해 Databricks는 프로덕션 준비 서비스 환경을 만듭니다.
- 고가용성 및 확장성. 기능 서비스 엔드포인트는 자동으로 확장 및 축소되어 서비스 요청 볼륨에 맞게 조정됩니다.
- 보안. 엔드포인트는 보안 네트워크 경계에 배포되며 엔드포인트가 삭제되거나 0으로 확장될 때 종료되는 전용 컴퓨팅을 사용합니다.
요구 사항
- Databricks Runtime 14.2 ML 이상
- Python API를 사용하려면 기능 제공에는 Databricks Runtime 14.2 ML에 기본 제공되는
databricks-feature-engineering버전 0.1.2 이상이 필요합니다. 이전 Databricks Runtime ML 버전의 경우%pip install databricks-feature-engineering>=0.1.2을 사용하여 수동으로 필수 버전을 설치해야 합니다. Databricks Notebook을 사용하는 경우 새 셀인dbutils.library.restartPython()명령을 실행하여 Python 커널을 다시 시작해야 합니다. - Databricks SDK를 사용하려면 기능 제공에
databricks-sdk버전 0.18.0 이상이 필요합니다. 필요한 버전을 수동으로 설치하려면%pip install databricks-sdk>=0.18.0를 사용합니다. Databricks Notebook을 사용하는 경우 새 셀인dbutils.library.restartPython()명령을 실행하여 Python 커널을 다시 시작해야 합니다.
Databricks 기능 제공은 엔드포인트 만들기, 업데이트, 쿼리 및 삭제를 위한 UI 및 여러 프로그래밍 옵션을 제공합니다. 이 문서에는 다음 각 옵션에 대한 지침이 포함되어 있습니다.
- Databricks 사용자 인터페이스
- REST API (REST 애플리케이션 프로그래밍 인터페이스)
- Python API
- Databricks SDK
REST API 또는 MLflow 배포 SDK를 사용하려면 Databricks API 토큰이 있어야 합니다.
중요합니다
프로덕션 시나리오에 대한 보안 모범 사례로 Databricks는 프로덕션 중에 인증 을 위해 머신-머신 OAuth 토큰을 사용하는 것이 좋습니다.
테스트 및 개발을 위해 Databricks는 작업 영역 사용자 대신 서비스 주체 에 속하는 개인용 액세스 토큰을 사용하는 것이 좋습니다. 서비스 주체에 대한 토큰을 만들려면 서비스 주체에 대한 토큰 관리를 참조하세요.
기능 제공에 대한 인증
인증에 대한 자세한 내용은 Azure Databricks 리소스에 대한 액세스 권한 부여 참조하세요.
생성 FeatureSpec
FeatureSpec는 사용자 정의 기능 및 함수 집합입니다.
FeatureSpec에서 기능과 함수를 결합할 수 있습니다.
FeatureSpecs는 Unity 카탈로그에 저장되고 관리되며 카탈로그 탐색기에 표시됩니다.
에 FeatureSpec 지정된 테이블은 온라인 기능 저장소 또는 타사 온라인 스토어에 게시해야 합니다.
Databricks Online 기능 저장소를 참조하세요.
databricks-feature-engineering 패키지를 사용하여 FeatureSpec를 만들어야 합니다.
먼저 함수를 정의합니다.
from unitycatalog.ai.core.databricks import DatabricksFunctionClient
client = DatabricksFunctionClient()
CATALOG = "main"
SCHEMA = "default"
def difference(num_1: float, num_2: float) -> float:
"""
A function that accepts two floating point numbers, subtracts the second one
from the first, and returns the result as a float.
Args:
num_1 (float): The first number.
num_2 (float): The second number.
Returns:
float: The resulting difference of the two input numbers.
"""
return num_1 - num_2
client.create_python_function(
func=difference,
catalog=CATALOG,
schema=SCHEMA,
replace=True
)
그런 다음 FeatureSpec에서 이 함수를 사용할 수 있습니다.
from databricks.feature_engineering import (
FeatureFunction,
FeatureLookup,
FeatureEngineeringClient,
)
fe = FeatureEngineeringClient()
features = [
# Lookup column `average_yearly_spend` and `country` from a table in UC by the input `user_id`.
FeatureLookup(
table_name="main.default.customer_profile",
lookup_key="user_id",
feature_names=["average_yearly_spend", "country"]
),
# Calculate a new feature called `spending_gap` - the difference between `ytd_spend` and `average_yearly_spend`.
FeatureFunction(
udf_name="main.default.difference",
output_name="spending_gap",
# Bind the function parameter with input from other features or from request.
# The function calculates num_1 - num_2.
input_bindings={"num_1": "ytd_spend", "num_2": "average_yearly_spend"},
),
]
# Create a `FeatureSpec` with the features defined above.
# The `FeatureSpec` can be accessed in Unity Catalog as a function.
fe.create_feature_spec(
name="main.default.customer_features",
features=features,
)
기본값 지정
기능에 대한 기본값을 지정하려면 . default_values 에서 매개 변수를 FeatureLookup사용합니다. 다음 예제를 참조하세요.
feature_lookups = [
FeatureLookup(
table_name="ml.recommender_system.customer_features",
feature_names=[
"membership_tier",
"age",
"page_views_count_30days",
],
lookup_key="customer_id",
default_values={
"age": 18,
"membership_tier": "bronze"
},
),
]
매개 변수 rename_outputs 를 사용하여 기능 열의 default_values 이름을 바꾸는 경우 이름이 바뀐 기능 이름을 사용해야 합니다.
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id',
rename_outputs={"materialized_feature_value": "feature_value"},
default_values={
"feature_value": 0
}
)
엔드포인트 만들기
FeatureSpec은 엔드포인트를 정의합니다. 자세한 내용은 엔드포인트를 제공하는 사용자 지정 모델 만들기Python API 설명서 또는 Databricks SDK 설명서를 참조하세요.
참고 사항
대기 시간이 중요하거나 초당 높은 쿼리가 필요한 워크로드의 경우 Model Serving는 엔드포인트를 제공하는 사용자 지정 모델에 대한 경로 최적화를 제공합니다. 엔드포인트 제공에 대한 경로 최적화를 참조하세요.
Databricks SDK - Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
workspace = WorkspaceClient()
# Create endpoint
workspace.serving_endpoints.create(
name="my-serving-endpoint",
config = EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
)
Python API
from databricks.feature_engineering.entities.feature_serving_endpoint import (
ServedEntity,
EndpointCoreConfig,
)
fe.create_feature_serving_endpoint(
name="customer-features",
config=EndpointCoreConfig(
served_entities=ServedEntity(
feature_spec_name="main.default.customer_features",
workload_size="Small",
scale_to_zero_enabled=True,
instance_profile_arn=None,
)
)
)
REST API (REST 애플리케이션 프로그래밍 인터페이스)
curl -X POST -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints \
-H 'Content-Type: application/json' \
-d '"name": "customer-features",
"config": {
"served_entities": [
{
"entity_name": "main.default.customer_features",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
]
}'
엔드포인트를 보려면 Databricks UI의 왼쪽 사이드바에서 서비스(Serving )를 클릭합니다. 상태가 준비 상태이면 엔드포인트가 쿼리에 응답할 준비가 된 것입니다. 모자이크 AI 모델 제공에 대한 자세한 내용은 모자이크 AI 모델 서비스를 참조하세요.
유추 테이블에 보강된 DataFrame 저장
2025년 2월부터 만든 엔드포인트의 경우 조회된 기능 값과 함수 반환 값이 포함된 보강된 DataFrame을 기록하도록 엔드포인트를 제공하는 모델을 구성할 수 있습니다. DataFrame은 제공된 모델의 유추 테이블에 저장됩니다.
이 구성 설정에 대한 지침은 테이블 유추에 대한 로그 기능 조회 데이터 프레임을 참조하세요.
유추 테이블에 대한 자세한 내용은 모델 모니터링 및 디버깅에 대한 유추 테이블을 참조하세요.
엔드포인트 가져오기
Databricks SDK 또는 Python API를 사용하여 엔드포인트의 메타데이터 및 상태를 가져올 수 있습니다.
Databricks SDK - Python
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
endpoint = workspace.serving_endpoints.get(name="customer-features")
# print(endpoint)
Python API
endpoint = fe.get_feature_serving_endpoint(name="customer-features")
# print(endpoint)
엔드포인트의 스키마 가져오기
Databricks SDK 또는 REST API를 사용하여 엔드포인트의 스키마를 가져올 수 있습니다. 엔드포인트 스키마에 대한 자세한 내용은 엔드포인트 스키마를 제공하는 모델 가져오기를 참조하세요.
Databricks SDK - Python
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
# Create endpoint
endpoint = workspace.serving_endpoints.get_open_api(name="customer-features")
REST API (REST 애플리케이션 프로그래밍 인터페이스)
ACCESS_TOKEN=<token>
ENDPOINT_NAME=<endpoint name>
curl "https://example.databricks.com/api/2.0/serving-endpoints/$ENDPOINT_NAME/openapi" -H "Authorization: Bearer $ACCESS_TOKEN" -H "Content-Type: application/json"
엔드포인트 쿼리
REST API, MLflow 배포 SDK 또는 서비스 UI를 사용하여 엔드포인트를 쿼리할 수 있습니다.
다음 코드에서는 MLflow 배포 SDK를 사용할 때 자격 증명을 설정하고 클라이언트를 만드는 방법을 보여줍니다.
# Set up credentials
export DATABRICKS_HOST=...
export DATABRICKS_TOKEN=...
# Set up the client
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
참고 사항
보안 모범 사례로, 자동화된 도구, 시스템, 스크립트 및 앱을 사용하여 인증하는 경우 Databricks는 작업 영역 사용자 대신 서비스 주체 에 속한 개인용 액세스 토큰을 사용하는 것이 좋습니다. 서비스 주체에 대한 토큰을 만들려면 서비스 주체에 대한 토큰 관리를 참조하세요.
API를 사용하여 엔드포인트 쿼리
이 섹션에는 REST API 또는 MLflow 배포 SDK를 사용하여 엔드포인트를 쿼리하는 예제가 포함되어 있습니다.
MLflow 배포 기능 SDK
중요합니다
다음 예제에서는 predict()의 API를 사용합니다. 이 API는 실험적이며 API 정의가 변경될 수 있습니다.
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
response = client.predict(
endpoint="test-feature-endpoint",
inputs={
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280},
]
},
)
REST API (REST 애플리케이션 프로그래밍 인터페이스)
curl -X POST -u token:$DATABRICKS_API_TOKEN $ENDPOINT_INVOCATION_URL \
-H 'Content-Type: application/json' \
-d '{"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]}'
UI를 사용하여 엔드포인트 쿼리
서비스 UI에서 직접 서비스 엔드포인트를 쿼리할 수 있습니다. UI에는 엔드포인트를 쿼리하는 데 사용할 수 있는 생성된 코드 예제가 포함되어 있습니다.
Azure Databricks 작업 영역의 왼쪽 사이드바에서 Serving 클릭합니다.
쿼리할 엔드포인트를 클릭합니다.
화면의 오른쪽 위에서 쿼리 엔드포인트를 클릭합니다.
요청 상자에 요청 본문을 JSON 형식으로 입력합니다.
요청 보내기를 클릭합니다.
// Example of a request body.
{
"dataframe_records": [
{ "user_id": 1, "ytd_spend": 598 },
{ "user_id": 2, "ytd_spend": 280 }
]
}
쿼리 엔드포인트 대화 상자에는 curl, Python 및 SQL에서 생성된 예제 코드가 포함됩니다. 탭을 클릭하여 예제 코드를 보고 복사합니다.
코드를 복사하려면 텍스트 상자의 오른쪽 상단에 있는 복사 아이콘을 클릭하세요.
엔드포인트 업데이트
중요합니다
기능 서비스 엔드포인트의 구성(예: 워크로드 크기 변경 FeatureSpec )을 수정하려면 항상 이 섹션에 설명된 업데이트 API를 사용합니다. 변경 내용을 적용하려면 엔드포인트를 삭제하고 다시 만들지 마세요. 라이브 엔드포인트를 삭제하면 즉시 가동 중지가 발생하고 쿼리하는 모든 애플리케이션이 중단됩니다.
REST API, Databricks SDK 또는 서비스 UI를 사용하여 엔드포인트를 업데이트할 수 있습니다.
API를 사용하여 엔드포인트 업데이트
Databricks SDK - Python
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
workspace.serving_endpoints.update_config(
name="my-serving-endpoint",
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
REST API (REST 애플리케이션 프로그래밍 인터페이스)
curl -X PUT -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>/config \
-H 'Content-Type: application/json' \
-d '"served_entities": [
{
"name": "customer-features",
"entity_name": "main.default.customer_features_new",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
]'
UI를 사용하여 엔드포인트 업데이트
서비스 제공 UI를 사용하려면 다음 단계를 따르세요.
- Azure Databricks 작업 영역의 왼쪽 사이드바에서 Serving 클릭합니다.
- 테이블에서 업데이트하려는 엔드포인트의 이름을 클릭합니다. 엔드포인트 화면이 나타납니다.
- 화면의 오른쪽 위에서 엔드포인트 편집을 클릭합니다.
- 서비스 엔드포인트 편집 대화 상자에서 필요에 따라 엔드포인트 설정을 편집합니다.
- 업데이트를 클릭하여 변경 내용을 저장합니다.

엔드포인트 삭제
경고
이 작업은 되돌릴 수 없습니다. 기능 서비스 엔드포인트를 삭제하면 쿼리하는 모든 애플리케이션에 즉시 가동 중지 시간이 발생합니다. 엔드포인트의 구성을 변경하려면 엔드포인트를 삭제하고 다시 만드는 대신 엔드포인트 업데이트를 사용합니다.
REST API, Databricks SDK, Python API 또는 서비스 UI를 사용하여 엔드포인트를 삭제할 수 있습니다.
API를 사용하여 엔드포인트 삭제
Databricks SDK - Python
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
workspace.serving_endpoints.delete(name="customer-features")
Python API
fe.delete_feature_serving_endpoint(name="customer-features")
REST API (REST 애플리케이션 프로그래밍 인터페이스)
curl -X DELETE -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>
UI를 사용하여 엔드포인트 삭제
다음 단계에 따라 서비스 UI를 사용하여 엔드포인트를 삭제합니다.
- Azure Databricks 작업 영역의 왼쪽 사이드바에서 Serving 클릭합니다.
- 테이블에서 삭제할 엔드포인트의 이름을 클릭합니다. 엔드포인트 화면이 나타납니다.
- 화면 오른쪽 위에서 케밥 메뉴
 을 클릭하고 삭제를 선택합니다.
을 클릭하고 삭제를 선택합니다.

엔드포인트의 상태 모니터링
기능 제공 엔드포인트에 사용할 수 있는 로그 및 메트릭에 대한 자세한 내용은 모델 품질 및 엔드포인트 상태 모니터링을 참조하세요.
접근 제어
기능 서비스 엔드포인트에 대한 사용 권한에 대한 자세한 내용은 엔드포인트를 제공하는 모델에 대한 권한 관리를 참조하세요.
예제 노트북
이 Notebook에서는 Databricks SDK를 사용하여 Databricks Online 기능 저장소를 사용하여 기능 제공 엔드포인트를 만드는 방법을 보여 줍니다.