Unity 카탈로그 모델 예제
이 예제에서는 Unity 카탈로그의 모델을 사용하여 풍력 발전소의 일일 전력 출력을 예측하는 기계 학습 애플리케이션을 빌드하는 방법을 보여 줍니다. 이 예제에서는 방법을 보여줍니다:
- MLflow로 모델을 추적하고 기록하세요.
- Unity 카탈로그에 모델 등록
- 별칭을 사용하여 모델을 설명하고 유추를 위해 배포하기
- 등록된 모델을 프로덕션 애플리케이션과 통합
- Unity 카탈로그에서 모델 검색 및 찾기
- 모델 삭제
이 문서에서는 Unity 카탈로그 UI 및 API의 MLflow 트래킹 및 모델을 사용하여 이러한 단계를 수행하는 방법을 설명합니다.
요구 사항
요구 사항의 모든 요구 사항을 충족하는지 확인하세요. 또한 이 문서의 코드 예제에서는 다음과 같은 권한이 있다고 가정합니다.
USE CATALOGmain카탈로그에 대한 권한.CREATE MODEL스키마에 대한USE SCHEMA및main.default권한.
Notebook
이 문서의 모든 코드는 다음 Notebook에 제공됩니다.
Unity 카탈로그 모델 예제 Notebook
MLflow Python 클라이언트 설치하기
해당 예제에는 MLflow Python 클라이언트 버전 2.5.0 이상과 TensorFlow가 필요합니다. 이러한 종속성을 설치하려면 notebook 상단에 다음 명령을 추가하세요.
%pip install --upgrade "mlflow-skinny[databricks]>=2.5.0" tensorflow
dbutils.library.restartPython()
데이터 세트 로드, 모델 훈련, Unity 카탈로그 등록
이 섹션에서는 풍력 발전소 데이터 세트를 로드하고, 모델을 학습시키고, 모델을 Unity 카탈로그에 등록하는 방법을 보여 줍니다. 모델 학습 실행 및 메트릭은 실험 실행에서 추적됩니다.
데이터 세트 로드
다음 코드는 미국의 한 풍력 발전 단지의 날씨 데이터 및 전력 출력 정보를 포함하는 데이터 세트를 로드합니다. 이 데이터 세트에는 6시간마다(00:00에 한 번, 08:00에 한 번, 16:00에 한 번) 샘플링된 wind direction, wind speed 및 air temperature 특징과 일일 집계 전력 출력(power)의 몇 년 치 데이터를 포함합니다.
import pandas as pd
wind_farm_data = pd.read_csv("https://github.com/dbczumar/model-registry-demo-notebook/raw/master/dataset/windfarm_data.csv", index_col=0)
def get_training_data():
training_data = pd.DataFrame(wind_farm_data["2014-01-01":"2018-01-01"])
X = training_data.drop(columns="power")
y = training_data["power"]
return X, y
def get_validation_data():
validation_data = pd.DataFrame(wind_farm_data["2018-01-01":"2019-01-01"])
X = validation_data.drop(columns="power")
y = validation_data["power"]
return X, y
def get_weather_and_forecast():
format_date = lambda pd_date : pd_date.date().strftime("%Y-%m-%d")
today = pd.Timestamp('today').normalize()
week_ago = today - pd.Timedelta(days=5)
week_later = today + pd.Timedelta(days=5)
past_power_output = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(today)]
weather_and_forecast = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(week_later)]
if len(weather_and_forecast) < 10:
past_power_output = pd.DataFrame(wind_farm_data).iloc[-10:-5]
weather_and_forecast = pd.DataFrame(wind_farm_data).iloc[-10:]
return weather_and_forecast.drop(columns="power"), past_power_output["power"]
Unity 카탈로그의 모델에 액세스하도록 MLflow 클라이언트 구성하기
기본적으로 MLflow Python 클라이언트는 Azure Databricks의 작업 영역 모델 레지스트리에 모델을 생성합니다. Unity 카탈로그의 모델로 업그레이드하려면 Unity 카탈로그의 모델에 액세스할 수 있도록 클라이언트를 구성합니다.
import mlflow
mlflow.set_registry_uri("databricks-uc")
모델을 학습시키고 등록합니다
다음 코드는 데이터 세트의 날씨 특징을 기반으로 전력 출력을 예측하기 위해 TensorFlow Keras를 사용하여 인공신경망을 학습시키고, MLflow API를 사용하여 적합 모델을 Unity 카탈로그에 등록합니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
MODEL_NAME = "main.default.wind_forecasting"
def train_and_register_keras_model(X, y):
with mlflow.start_run():
model = Sequential()
model.add(Dense(100, input_shape=(X.shape[-1],), activation="relu", name="hidden_layer"))
model.add(Dense(1))
model.compile(loss="mse", optimizer="adam")
model.fit(X, y, epochs=100, batch_size=64, validation_split=.2)
example_input = X[:10].to_numpy()
mlflow.tensorflow.log_model(
model,
artifact_path="model",
input_example=example_input,
registered_model_name=MODEL_NAME
)
return model
X_train, y_train = get_training_data()
model = train_and_register_keras_model(X_train, y_train)
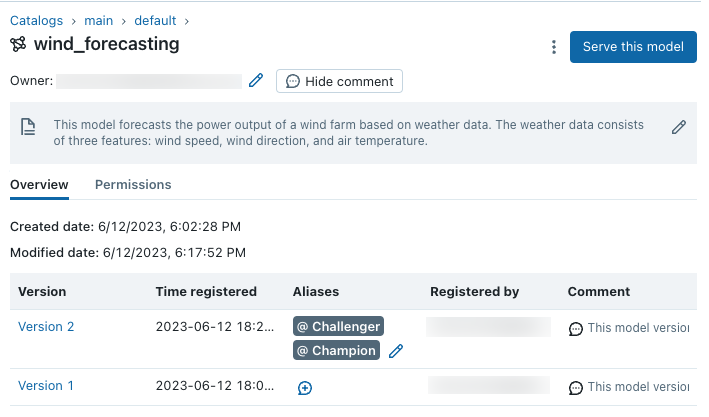
UI에서 모델 확인
카탈로그 탐색기를 사용하여 Unity 카탈로그에서 등록된 모델과 모델 버전을 확인하고 관리할 수 있습니다. main 카탈로그 및 default 스키마에서 방금 생성한 모델을 찾습니다.

유추를 위한 모델 버전 배포
Unity 카탈로그의 모델은 모델 배포를 위한 별칭을 지원 합니다. 별칭은 특정 버전의 등록된 모델에 대해 "챔피언" 또는 "챌린저"와 같은 변경 가능한 이름 참조를 제공합니다. 이 별칭을 사용하여 다운스트림 유추 워크플로에서 모델 버전을 참조하고 대상으로 지정할 수 있습니다.
카달로그 탐색기에서 등록된 모델로 이동한 후, 별칭 열 아래를 클릭하여 최신 모델 버전에 "챔피언" 별칭을 할당하고, "계속"을 눌러 변경 사항을 저장하십시오.

API를 사용하여 모델 버전 불러오기
MLflow 모델 구성 요소는 여러 기계 학습 프레임워크에서 모델을 로드하기 위한 함수를 정의합니다. 예를 들어, mlflow.tensorflow.load_model()은 MLflow 형식으로 저장된 TensorFlow 모델을 로드하는 데 사용되고, mlflow.sklearn.load_model()은 MLflow 형식으로 저장된 scikit-learn 모델을 로드하는 데 사용됩니다.
이러한 함수는 Unity 카탈로그의 모델에서 모델을 로드할 수 있습니다.
import mlflow.pyfunc
model_version_uri = "models:/{model_name}/1".format(model_name=MODEL_NAME)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_version_uri))
model_version_1 = mlflow.pyfunc.load_model(model_version_uri)
model_champion_uri = "models:/{model_name}@Champion".format(model_name=MODEL_NAME)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_champion_uri))
champion_model = mlflow.pyfunc.load_model(model_champion_uri)
챔피언 모델을 사용한 전력 출력 예측
이 섹션에서는 챔피언 모델을 사용하여 풍력 발전 단지의 일기 예보 데이터를 평가합니다. forecast_power() 애플리케이션이 지정된 스테이지에서 최신 버전의 예측 모델을 로드하고 이를 사용하여 향후 5일의 전력 발전을 예측합니다.
from mlflow.tracking import MlflowClient
def plot(model_name, model_alias, model_version, power_predictions, past_power_output):
import matplotlib.dates as mdates
from matplotlib import pyplot as plt
index = power_predictions.index
fig = plt.figure(figsize=(11, 7))
ax = fig.add_subplot(111)
ax.set_xlabel("Date", size=20, labelpad=20)
ax.set_ylabel("Power\noutput\n(MW)", size=20, labelpad=60, rotation=0)
ax.tick_params(axis='both', which='major', labelsize=17)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
ax.plot(index[:len(past_power_output)], past_power_output, label="True", color="red", alpha=0.5, linewidth=4)
ax.plot(index, power_predictions.squeeze(), "--", label="Predicted by '%s'\nwith alias '%s' (Version %d)" % (model_name, model_alias, model_version), color="blue", linewidth=3)
ax.set_ylim(ymin=0, ymax=max(3500, int(max(power_predictions.values) * 1.3)))
ax.legend(fontsize=14)
plt.title("Wind farm power output and projections", size=24, pad=20)
plt.tight_layout()
display(plt.show())
def forecast_power(model_name, model_alias):
import pandas as pd
client = MlflowClient()
model_version = client.get_model_version_by_alias(model_name, model_alias).version
model_uri = "models:/{model_name}@{model_alias}".format(model_name=MODEL_NAME, model_alias=model_alias)
model = mlflow.pyfunc.load_model(model_uri)
weather_data, past_power_output = get_weather_and_forecast()
power_predictions = pd.DataFrame(model.predict(weather_data))
power_predictions.index = pd.to_datetime(weather_data.index)
print(power_predictions)
plot(model_name, model_alias, int(model_version), power_predictions, past_power_output)
forecast_power(MODEL_NAME, "Champion")
API를 사용하여 모델 및 모델 버전 설명 추가하기
이 섹션의 코드는 MLflow API로 모델 및 모델 버전 설명을 추가하는 방법을 보여 줍니다.
client = MlflowClient()
client.update_registered_model(
name=MODEL_NAME,
description="This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature."
)
client.update_model_version(
name=MODEL_NAME,
version=1,
description="This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer."
)
새 모델 버전 만들기
전력 예측에는 고전적인 기계 학습 기법도 효과적입니다. 다음은 scikit-learn을 통해 임의의 포리스트 모델을 학습하고 이 mlflow.sklearn.log_model() 함수로 Unity 카탈로그에 등록하는 코드입니다.
import mlflow.sklearn
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
with mlflow.start_run():
n_estimators = 300
mlflow.log_param("n_estimators", n_estimators)
rand_forest = RandomForestRegressor(n_estimators=n_estimators)
rand_forest.fit(X_train, y_train)
val_x, val_y = get_validation_data()
mse = mean_squared_error(rand_forest.predict(val_x), val_y)
print("Validation MSE: %d" % mse)
mlflow.log_metric("mse", mse)
example_input = val_x.iloc[[0]]
# Specify the `registered_model_name` parameter of the `mlflow.sklearn.log_model()`
# function to register the model to <UC>. This automatically
# creates a new model version
mlflow.sklearn.log_model(
sk_model=rand_forest,
artifact_path="sklearn-model",
input_example=example_input,
registered_model_name=MODEL_NAME
)
새 모델 버전 번호 가져오기
다음 코드는 모델명에 대한 최신 모델 버전 번호를 검색하는 방법을 보여줍니다.
client = MlflowClient()
model_version_infos = client.search_model_versions("name = '%s'" % MODEL_NAME)
new_model_version = max([model_version_info.version for model_version_info in model_version_infos])
새 모델 버전에 설명 추가하기
client.update_model_version(
name=MODEL_NAME,
version=new_model_version,
description="This model version is a random forest containing 100 decision trees that was trained in scikit-learn."
)
새 모델 버전을 챌린저로 표시하고 모델 테스트하기
프로덕션 트래픽을 처리하기 위해 모델을 배포하기 전에 프로덕션 데이터 샘플에서 테스트하는 것이 가장 좋습니다. 이전에는 대부분의 프로덕션 워크로드를 지원하는 모델 버전을 나타내기 위해 “챔피언” 별칭을 사용했습니다. 다음 코드는 새로운 모델 버전에 "챌린저" 별칭을 할당하고, 그 성능을 평가합니다.
client.set_registered_model_alias(
name=MODEL_NAME,
alias="Challenger",
version=new_model_version
)
forecast_power(MODEL_NAME, "Challenger")
새 모델 버전을 챔피언 모델 버전으로 배포합니다
새 모델 버전이 테스트에서 잘 작동하는지 확인한 후 다음 코드는 새 모델 버전에 “챔피언” 별칭을 할당하고 챔피언 모델 섹션의 예측 전력 출력과 정확히 동일한 애플리케이션 코드를 사용하여 전력 예측을 생성합니다.
client.set_registered_model_alias(
name=MODEL_NAME,
alias="Champion",
version=new_model_version
)
forecast_power(MODEL_NAME, "Champion")
이제 예측 모델에는 Keras 모델에서 학습된 모델 버전과 Scikit-Learn에서 학습된 버전, 두 가지 모델 버전이 있습니다. "챌린저" 별칭이 새로운 scikit-learn 모델 버전에 계속 할당되어 있으므로, "챌린저" 모델 버전을 대상으로 하는 다운 스트림 워크로드는 계속 성공적으로 실행됩니다.
모델 삭제
모델 버전을 더 이상 사용하지 않는 경우 삭제할 수 있습니다. 등록된 모델 전체를 삭제할 수도 있습니다. 이렇게 하면 관련된 모든 모델 버전이 제거됩니다. 모델 버전을 삭제하면 모델 버전에 할당된 별칭이 지워지게 됩니다.
MLflow API를 사용하여 Version 1 삭제하기
client.delete_model_version(
name=MODEL_NAME,
version=1,
)
MLflow API를 사용하여 모델 삭제하기
client = MlflowClient()
client.delete_registered_model(name=MODEL_NAME)