중요합니다
이 기능은 공개 미리보기 단계에 있습니다.
이 페이지에서는 Databricks Assistant에서 에이전트 모드를 선택하여 사용할 수 있는 AI 데이터 에이전트인 데이터 과학 에이전트를 소개합니다. Databricks Notebook 및 SQL 편집기를 위해 특별히 설계된 이 도구는 단일 프롬프트에서 데이터를 탐색하고, 코드를 생성 및 실행하고, 오류를 수정합니다.
데이터 과학 에이전트란?
데이터 과학 에이전트는 Databricks Assistant의 에이전트 모드에서 강력한 기능으로, 도우미를 Databricks Notebook 및 SQL 편집기에서 전체 다단계 데이터 과학 워크플로를 자동화할 수 있는 지능형 도우미로 변환합니다.
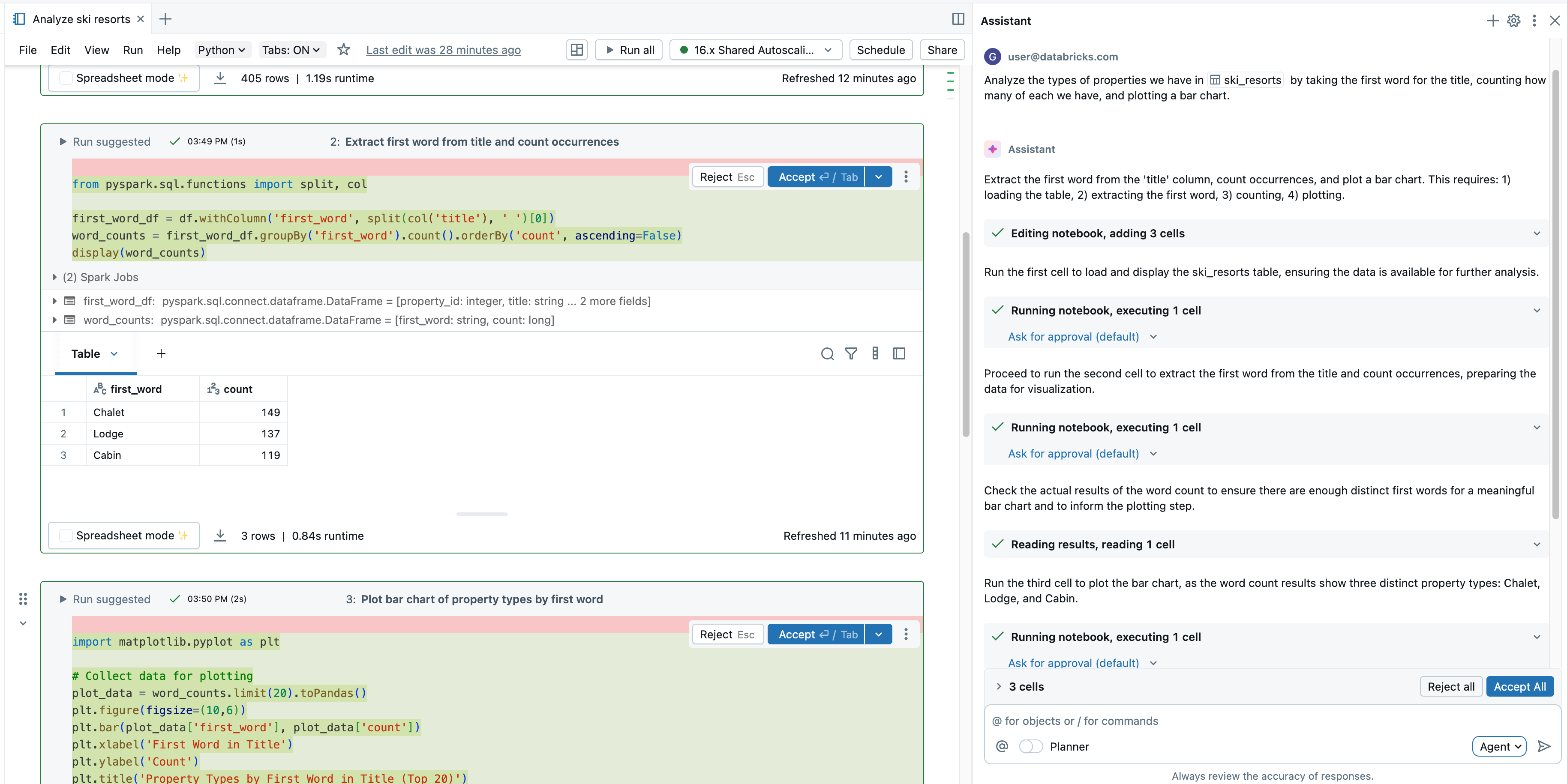
도우미 채팅 모드에 비해 에이전트 모드는 솔루션 계획, 관련 자산 검색, 코드 실행, 셀 출력을 사용하여 결과 개선, 오류 자동 수정 등 기능을 확장했습니다.
데이터 과학 에이전트는 SQL 편집기에서 실행할 Notebook 또는 쿼리에서 실행할 코드를 계획하고 생성할 수 있습니다. 에이전트는 계속하기 전에 사용자와 협력하여 계획을 승인하고 다음 단계를 확인합니다. 승인을 통해 데이터 과학 에이전트는 도구를 사용하여 테이블 검색, 전자 필기장 편집, 셀 실행 및 셀 출력 읽기와 같은 작업을 수행할 수 있습니다.
데이터 과학 에이전트의 액세스 및 작업은 사용자의 권한에 의해 제어됩니다. 액세스 권한이 있는 데이터에만 액세스하고 권한이 있는 작업을 수행할 수 있습니다.
요구 사항
데이터 과학 에이전트를 사용하려면 작업 영역에 다음이 필요합니다.
- 계정 및 작업 영역 모두에 대해 사용하도록 설정된 파트너 기반 AI 기능입니다. 파트너 기반 AI 기능을 참조하세요.
- Databricks 도우미 에이전트 모드 미리 보기가 사용하도록 설정되었습니다. Azure Databricks 미리 보기 관리를 참조하세요.
데이터 과학 에이전트 사용
데이터 과학 에이전트를 사용하려면 다음을 수행합니다.
Databricks Notebook 또는 SQL 편집기에서 길잡이 쪽 패널을 엽니다.
오른쪽 아래 모서리에서 에이전트를 선택합니다. 이렇게 하면 도우미의 에이전트 모드에서 전환되어 데이터 과학 에이전트와 상호 작용할 수 있습니다.
에이전트에 대한 프롬프트를 입력합니다. 예를 들어 "samples.bakehouse에서 분석
@sales_transactions하여 상위 판매 제품을 식별합니다."팁 (조언)
를 사용하여
@table_name특정 테이블을 참조합니다. 에이전트는 해당 테이블 및 연결된 메타데이터를 사용하여 응답을 큐레이팅합니다. 에이전트는 사용자의 Unity 카탈로그 권한을 준수하므로 액세스 권한이 있는 데이터에만 액세스할 수 있습니다.에이전트가 응답을 생성할 때 입력을 가져오기 위해 일시 중지되는 경우가 많습니다.
더 복잡한 작업의 경우 에이전트는 단계별 계획을 만들고 명확한 질문을 할 수 있습니다. 에이전트의 명확한 질문에 답변하여 계획을 연마하는 데 도움을 주세요.
에이전트가 코드를 실행해야 하는 경우 계속하기 전에 승인을 요청합니다. 요청을 허용하거나 거부합니다. 이 스레드에서 허용(도우미 대화 스레드 참조)을 선택하거나 항상 허용을 선택할 수도 있습니다.
중요합니다
데이터 과학 에이전트는 Notebook에서 코드를 생성하고 실행할 수 있습니다. 위험한 행동을 방지하기 위한 가드레일이 있지만 여전히 위험이 있습니다. 신뢰할 수 있는 코드 및 데이터에서만 사용해야 합니다.
에이전트가 작업을 계속하면 계속 또는 거부를 선택하라는 메시지가 표시될 수 있습니다 . 에이전트의 기존 작업을 검토한 다음 계속을 선택하여 에이전트가 다음 단계를 계속 진행하도록 허용하거나 거부 를 선택하여 다른 작업을 시도하도록 지시합니다.
에이전트가 작동하는 동안 중지하려면 빨간색
 을 클릭합니다.
을 클릭합니다.
에이전트는 새 Notebook 셀(또는 쿼리)을 만들고, 텍스트와 코드를 생성하고, Notebook 셀을 실행하고, 셀 출력에 액세스하여 결과를 해석할 수 있습니다.
비고
데이터 과학 에이전트가 작업을 계속하고 다음 단계를 수행하려면 에이전트가 작업 중인 현재 탭을 유지해야 합니다.
사용 사례
에이전트 모드에서 도우미는 데이터 찾기, 출력 해석 및 셀 작업 수행과 같은 기능을 확장했습니다.
데이터 과학 에이전트는 예비 데이터 분석, 예측 및 기계 학습을 비롯한 복잡한 데이터 과학 작업을 도울 수 있습니다. 데이터 과학 에이전트를 사용하여 새 데이터 분석 Notebook을 처음부터 만들 수도 있습니다. 더 나은 결과를 위해 테이블 및 파이프라인을 참조하여 에이전트에 컨텍스트를 @<resource_name>제공합니다.
다음 프롬프트를 시도하여 시작합니다.
-
데이터 검색:
- "bakehouse 트랜잭션 데이터가 포함된 테이블은 무엇인가요?"
- "나는 로스 앤젤레스, 캘리포니아의 도시에서 날짜 2025-01-01에 대한 날씨 데이터를보고 싶다."
- "뉴욕시 택시 데이터가 포함된 테이블을 찾아서 처음 10개 행을 표시합니다."
-
예비 데이터 분석:
- "A열에서 JSON 문자열을 구문 분석하는 데 도움을 주세요."
- "이 테이블에서 데이터의 시각화를 만듭니다."
- "이 가로 막대형 차트를 해석합니다."
- "데이터 세트를 설명
@sales_transactions합니다. 열 통계를 이해하고 값의 분포를 시각화하는 데 도움이 되는 몇 가지 EDA를 수행합니다. 데이터 과학자처럼 생각하십시오." - "지난 주 수익별로 Databricks SQL 워크로드의 상위 5개 고객을 찾기 위해 분석
@workload_insights합니다. 그런 다음 지난 6주 동안 해당 고객이 주당 Databricks SQL에 대해 얼마나 많은 사용자를 가지고 있었는지를 그립니다."
-
예측:
- "데이터 세트를 사용하여
@incidents다음 2주 동안의 일일 인시던트 수 예측을 작성합니다. 완료되면 결과를 표시할 수 있는 데이터 테이블과 대화형 차트를 제공하세요." - "데이터 세트를 사용하여
@website_traffic다음 달의 일일 방문자 수를 예측합니다. 계절 패턴을 강조 표시합니다." - "신뢰 구간을 포함하여 데이터 세트에서 향후 6개월 동안
@inventory제품 수요 예측을 생성합니다."
- "데이터 세트를 사용하여
-
기계 학습:
- "일부 데이터 준비 및 기능 엔지니어링을 수행하여 모델 학습을 위해 이 데이터 세트를 준비합니다."
- "데이터 세트에서 분류 모델을
@customer_data학습하여 변동을 예측합니다. 정확도 및 AUC 메트릭을 사용하여 모델을 평가합니다." - "데이터 세트를 사용하여
@housing_prices회귀 모델에서 하이퍼 매개 변수 튜닝을 수행하여 예측 오류를 개선합니다." - "데이터 세트에
@sales_leads클러스터링 모델을 빌드하여 고객 세그먼트를 식별하고 각 클러스터의 특성에 대한 요약을 제공합니다."
-
Notebook 조직:
- "이 Notebook의 결과를 요약하는 새 셀을 만듭니다."
- "이 전자 필기장에게 관련 이름을 지정합니다."
예비 데이터 분석
데이터 과학 에이전트를 사용하여 데이터 세트에 대한 예비 데이터 분석을 수행합니다. 예를 들어 에이전트를 사용하여 데이터 세트를 분석 samples.bakehouse.sales_transactions 하는 새 Notebook을 만들 수 있습니다.
빈 전자 필기장 탭에서 길잡이 패널을 열고 에이전트 모드를 선택하고 다음 프롬프트를 입력합니다. "samples.bakehouse에서 데이터 세트를 @sales_transactions 설명합니다. 열 통계를 이해하고 값의 분포를 시각화할 수 있도록 몇 가지 EDA를 수행하려고 합니다. 데이터 과학자처럼 생각하십시오."
에이전트는 프롬프트에 응답하는 계획을 만들고 명확한 질문을 할 수 있습니다. 승인을 통해 프로세스 및 결과를 설명하는 데이터 및 텍스트를 탐색하는 코드가 포함된 새 Notebook 셀을 생성합니다.