Lakeflow Jobs, dbutils.notebook.run(), 작업 영역 파일 및 %run를 사용하여 Databricks 노트북을 오케스트레이션하고 코드를 모듈화할 수 있습니다. 예약, 매개 변수 전달 및 버전 제어의 필요성에 따라 메서드를 선택합니다.
오케스트레이션 및 코드 모듈화 메서드
다음 표에서는 Notebook을 오케스트레이션하고 Notebook에서 코드를 모듈화하는 데 사용할 수 있는 방법을 비교합니다.
| 메서드 | 사용 사례 | 메모 |
|---|---|---|
| Lakeflow 직업 | 노트북 오케스트레이션(권장) | 노트북을 오케스트레이션하는 데 권장되는 방법입니다. 작업 종속성, 일정 및 트리거를 사용하여 복잡한 워크플로를 지원합니다. 프로덕션 워크로드에 대해 강력하고 확장 가능한 접근 방식을 제공하지만 설정 및 구성이 필요합니다. |
| dbutils.notebook.run() |
Notebook 오케스트레이션 |
dbutils.notebook.run()을 사용하세요. 예를 들어 메타데이터 파일(메타데이터 기반 ETL)에 따라 노트북을 동적으로 실행하는 경우처럼 Jobs가 사용 사례를 지원할 수 없는 경우에 사용합니다.각 호출에 대해 새 임시 작업을 시작하여 오버헤드를 증가시키고 고급 일정 기능이 부족할 수 있습니다. |
| 작업 영역 파일 | 코드 모듈화(권장) | 코드를 모듈화하는 데 권장되는 방법입니다. 코드를 작업 영역에 저장된 재사용 가능한 코드 파일로 모듈화합니다. 디버깅 및 단위 테스트를 향상하기 위해 리포지토리와 IDE와의 통합을 통해 버전 제어를 지원합니다. 파일 경로 및 종속성을 관리하려면 추가 설정이 필요합니다. |
| %run | 코드 모듈화 | 작업 영역 파일에 액세스할 수 없는 경우 사용합니다 %run .함수 또는 변수를 인라인으로 실행하여 다른 Notebook에서 가져옵니다. 프로토타입 생성에 유용하지만 유지 관리가 더 어려운 긴밀하게 결합된 코드로 이어질 수 있습니다. 매개 변수 전달 또는 버전 제어를 지원하지 않습니다. |
%run 대 dbutils.notebook.run()
%run명령을 사용하면 Notebook 내에 다른 Notebook을 포함할 수 있습니다.
%run 사용하여 지원 함수를 별도의 Notebook에 배치하여 코드를 모듈화할 수 있습니다. 이를 통해 분석의 단계를 구현하는 Notebook을 연결할 수도 있습니다.
%run을 사용하면 호출된 Notebook이 즉시 실행되고 그 안에 정의된 함수와 변수를 호출 Notebook에서 사용할 수 있게 됩니다.
dbutils.notebook API는 notebook에 매개 변수를 전달하고 값을 반환할 수 있으므로 %run 보완합니다. 이렇게 하면 종속성이 있는 복잡한 워크플로 및 파이프라인을 빌드할 수 있습니다. 예를 들어 디렉터리의 파일 목록을 가져와서 이름을 다른 Notebook에 전달할 수 있습니다. 이 경우 %run사용할 수 없습니다. 반환 값에 따라 if-then-else 워크플로를 만들 수도 있습니다.
%run과 달리 dbutils.notebook.run() 메서드는 Notebook을 실행하는 새 작업을 시작합니다.
모든 dbutils API와 마찬가지로 이러한 메서드는 Python 및 Scala에서만 사용할 수 있습니다. 그러나 dbutils.notebook.run()을 사용하여 R Notebook을 호출할 수 있습니다.
%run을 사용하여 Notebook 가져오기
아래 예제에서 첫 번째 Notebook은 reverse 매직을 사용하여 %run을 실행한 후 두 번째 Notebook에서 사용할 수 있는 함수 shared-code-notebook을 정의합니다.

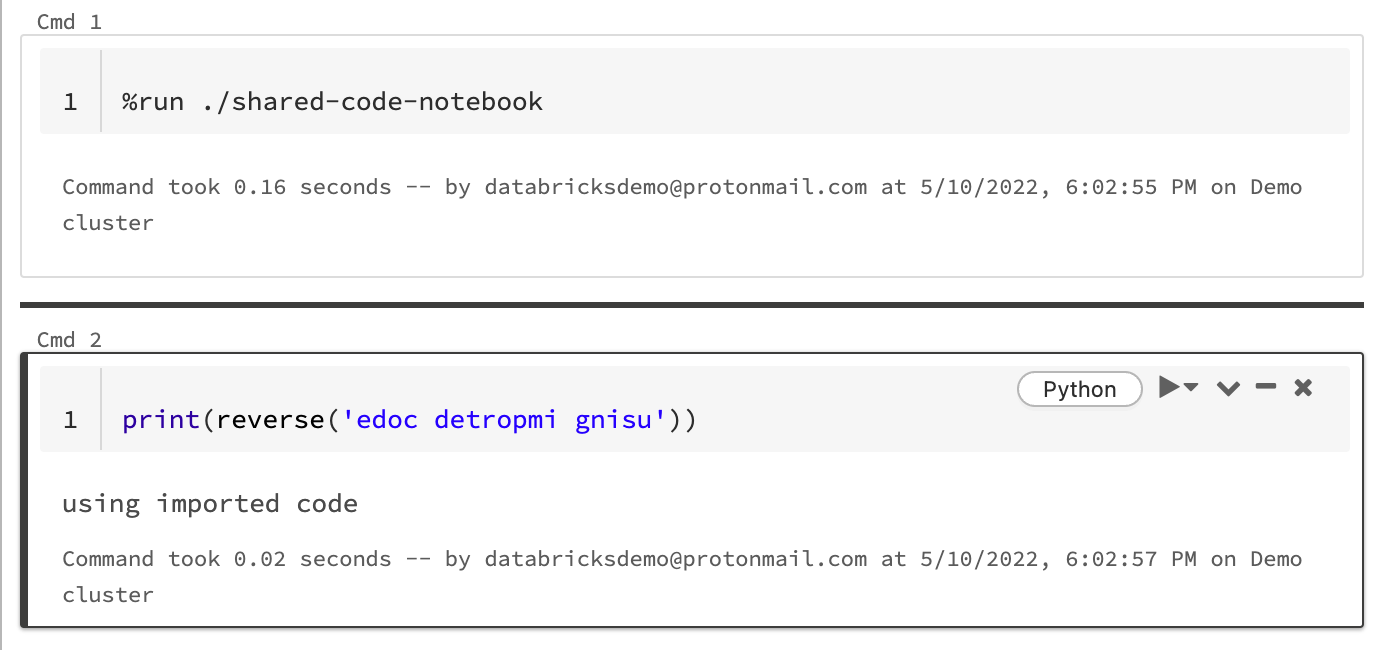
두 노트북이 작업 영역의 동일한 디렉터리에 있으므로, 현재 실행 중인 노트북을 기준으로 경로를 확인하려면 ./ 접두사를 ./shared-code-notebook에서 사용해야 함을 나타냅니다. Notebook을 디렉터리(예: %run ./dir/notebook)로 구성하거나 절대 경로(예: %run /Users/username@organization.com/directory/notebook)를 사용할 수 있습니다.
참고
-
%run은 Notebook 전체를 인라인으로 실행하기 때문에 셀에 단독으로 있어야 합니다. -
Python 파일을 실행하고 해당 파일에 정의된 엔터티를 노트북에
%run가져오는 데import사용할 수 없습니다. Python 파일에서 가져오려면 파일을 사용하여 코드 수정 참조하세요. 또는 파일을 Python 라이브러리로 패키지하고, 해당 Python 라이브러리로 Azure Databricks 라이브러리를 생성한 후, 노트북을 실행하는 클러스터에 라이브러리를 설치합니다. - 위젯이 포함된 Notebook을 실행하는 데 사용하는
%run경우 기본적으로 지정된 Notebook은 위젯의 기본값으로 실행됩니다. Databricks 위젯 사용에 관한 자세한 내용은 에서 %run,를 참조하세요; 위젯에 값을 전달할 수도 있습니다.
dbutils.notebook.run 사용하여 새 작업 시작
노트북을 실행하고 종료 값을 반환합니다. 메서드는 즉시 실행되는 임시 작업을 시작합니다.
dbutils.notebook API에서 사용 가능한 메서드는 run 와 exit입니다. 매개 변수와 반환 값은 모두 문자열이어야 합니다.
run(path: String, timeout_seconds: int, arguments: Map): String
timeout_seconds 매개 변수는 실행의 시간 제한을 제어합니다(0은 시간 제한을 의미하지 않음). 지정된 시간 내에 완료되지 않으면 run 호출이 예외를 발생시킵니다. Azure Databricks 10분 이상 중단되면 timeout_seconds 관계없이 Notebook 실행이 실패합니다.
arguments 매개 변수는 대상 Notebook의 위젯 값을 설정합니다. 특히, 실행 중인 노트북에 A라는 위젯이 있고 ("A": "B") 호출에 대한 인수 매개 변수의 일부로 키-값 쌍 run()을(를) 전달하는 경우, 위젯 A의 값을 조회하면 "B"가 반환됩니다.
Databricks 위젯 페이지에서 위젯을 만들고 사용하는 방법에 대한 지침을 찾을 수 있습니다.
참고
-
arguments매개 변수는 라틴 문자만 허용합니다(ASCII 문자 집합). ASCII가 아닌 문자를 사용하면 오류가 반환됩니다. -
dbutils.notebookAPI를사용하여 만든 작업은 30일 이내에 완료되어야 합니다.
run 사용
Python
dbutils.notebook.run("notebook-name", 60, {"argument": "data", "argument2": "data2", ...})
스칼라
dbutils.notebook.run("notebook-name", 60, Map("argument" -> "data", "argument2" -> "data2", ...))
노트북 간에 구조화된 데이터 전달
이 섹션에서는 Notebook 간에 구조화된 데이터를 전달하는 방법을 보여 줍니다.
Python
# Example 1 - returning data through temporary views.
# You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
# return a name referencing data stored in a temporary view.
## In callee notebook
spark.range(5).toDF("value").createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
# Example 2 - returning data through DBFS.
# For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
## In callee notebook
dbutils.fs.rm("/tmp/results/my_data", recurse=True)
spark.range(5).toDF("value").write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(spark.read.format("parquet").load(returned_table))
# Example 3 - returning JSON data.
# To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
## In callee notebook
import json
dbutils.notebook.exit(json.dumps({
"status": "OK",
"table": "my_data"
}))
## In caller notebook
import json
result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
print(json.loads(result))
스칼라
서버리스 호환성 Databricks는 Databricks 서버리스 컴퓨팅 아키텍처와 호환되지 않으므로 RDD API에서 벗어나는 것이 좋습니다. 대신 DataFrame API를 사용합니다.
// Example 1 - returning data through temporary views.
// You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
// return a name referencing data stored in a temporary view.
/** In callee notebook */
sc.parallelize(1 to 5).toDF().createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
val global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
// Example 2 - returning data through DBFS.
// For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
/** In callee notebook */
dbutils.fs.rm("/tmp/results/my_data", recurse=true)
sc.parallelize(1 to 5).toDF().write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(sqlContext.read.format("parquet").load(returned_table))
// Example 3 - returning JSON data.
// To return multiple values, use standard JSON libraries to serialize and deserialize results.
/** In callee notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
// Exit with json
dbutils.notebook.exit(jsonMapper.writeValueAsString(Map("status" -> "OK", "table" -> "my_data")))
/** In caller notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
val result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
println(jsonMapper.readValue[Map[String, String]](result))
오류 처리
이 섹션에서는 오류를 처리하는 방법을 보여 줍니다.
Python
# Errors throw a WorkflowException.
def run_with_retry(notebook, timeout, args = {}, max_retries = 3):
num_retries = 0
while True:
try:
return dbutils.notebook.run(notebook, timeout, args)
except Exception as e:
if num_retries > max_retries:
raise e
else:
print("Retrying error", e)
num_retries += 1
run_with_retry("LOCATION_OF_CALLEE_NOTEBOOK", 60, max_retries = 5)
스칼라
// Errors throw a WorkflowException.
import com.databricks.WorkflowException
// Since dbutils.notebook.run() is just a function call, you can retry failures using standard Scala try-catch
// control flow. Here, we show an example of retrying a notebook a number of times.
def runRetry(notebook: String, timeout: Int, args: Map[String, String] = Map.empty, maxTries: Int = 3): String = {
var numTries = 0
while (true) {
try {
return dbutils.notebook.run(notebook, timeout, args)
} catch {
case e: WorkflowException if numTries < maxTries =>
println("Error, retrying: " + e)
}
numTries += 1
}
"" // not reached
}
runRetry("LOCATION_OF_CALLEE_NOTEBOOK", timeout = 60, maxTries = 5)
여러 Notebook을 동시에 실행
표준 Scala 및 Python 구문을 사용하여 쓰레드(Scala, Python)와 Future(Scala, Python)를 통해 여러 notebook을 동시에 실행할 수 있습니다. 예제 Notebook에서는 이러한 구문을 사용하는 방법을 보여 줍니다.
- 다음의 네 개 전자 필기장을 다운로드하세요. Notebook은 Scala로 작성됩니다.
- Notebook을 작업 영역의 단일 폴더로 가져옵니다.
- 동시 실행 노트북을 실행합니다.