Tableau에 연결 및 Azure Databricks
이 문서에서는 파트너 연결을 사용하여 Azure Databricks에서 Tableau Desktop으로, Tableau Desktop 또는 Tableau Cloud에서 Azure Databricks로 연결하는 방법을 보여 줍니다. 이 문서에는 Linux의 Tableau Server에 대한 정보도 포함되어 있습니다.
참고 항목
Tableau Server에서 Azure Databricks 로그온을 구성하려면 Tableau Server에서 Azure Databricks 로그온 구성을 참조 하세요.
Tableau에서 Azure Databricks를 데이터 원본으로 사용하는 경우 대규모 데이터 집합으로 확장해 강력한 대화형 분석을 제공하여 데이터 과학자 및 데이터 엔지니어의 기여를 비즈니스 분석가에게 제공할 수 있습니다.
Azure Databricks에서 Tableau Cloud의 탐색
Tableau Cloud에서 Azure Databricks를 데이터 원본으로 사용하는 경우 Databricks UI에서 직접 테이블 또는 스키마에서 Tableau 데이터 원본을 만들 수 있습니다.
요구 사항
- 데이터는 Unity 카탈로그에 있어야 하며 컴퓨팅(클러스터)은 Unity 카탈로그를 사용하도록 설정해야 합니다. Hive 메타스토어는 현재 지원되지 않습니다.
Tableau Cloud에 Azure Databricks 테이블 게시
- Databricks 작업 영역에 로그인하고 사이드바에서
 카탈로그 클릭하여 카탈로그 탐색기를 엽니다.
카탈로그 클릭하여 카탈로그 탐색기를 엽니다. - 오른쪽 위에 있는 드롭다운 목록에서 컴퓨팅 리소스를 선택합니다.
- 카탈로그를 열고 게시할 스키마 또는 테이블을 선택합니다. Hive 메타스토어나 샘플 카탈로그에서 선택하지 마세요.
- 오른쪽 위에서 BI 도구와 함께 사용 또는 대시보드에서 테이블을 열기를 클릭합니다.
- Tableau Cloud에서 탐색을 선택합니다.
- Compute 확인하고 데이터 게시 원하는지 확인한 다음 Tableau Cloud 탐색을 클릭합니다.
- 10~20초 후에 새 탭에서 Tableau Cloud 계정에 로그인하라는 메시지가 표시됩니다.
- 로그인한 후 Tableau 페이지로 이동하여 Azure Databricks에 다시 로그인하라는 메시지를 표시합니다.
- Azure Databricks에 로그인한 후 통합 문서 편집기 페이지에서 대시보드 빌드를 시작할 수 있습니다.
- Tableau Cloud에서 열기 단추를 클릭하여 Tableau Cloud에서 통합 문서를 열 수도 있습니다.
역할 및 메모
- 테이블 또는 스키마를 게시할 수 있습니다. 스키마를 게시할 때 Tableau 데이터 원본 패널에서 테이블을 선택해야 합니다.
- Databricks는 Tableau Cloud에 게시할 때 OAuth 인증 모드로 적용합니다.
- 게시된 데이터 원본은 초안 모드에 있으며 어디에도 저장되지 않습니다. 다른 사용자가 액세스할 수 있도록 Tableau Cloud에서 저장해야 합니다.
- Tableau에서 반환된 리디렉션 링크는 약 5분 후에 만료됩니다.
Tableau 및 Azure Databricks를 연결하기 위한 요구 사항
컴퓨팅 리소스 또는 SQL 웨어하우스, 특히 Server 호스트 이름 및 HTTP 경로 값에 대한 연결 세부 정보입니다.
- Azure Databricks 컴퓨팅 리소스대한 연결 세부 정보를 가져옵니다.
Tableau Desktop 2019.3 이상.
Databricks ODBC Driver 2.6.15 이상.
Microsoft Entra ID(이전의 Azure Active Directory) 토큰(권장), Azure Databricks 개인용 액세스 토큰, 또는 Microsoft Entra ID 계정 자격 증명.
참고 항목
보안 모범 사례로, 자동화된 도구, 시스템, 스크립트, 앱을 사용하여 인증할 때 Databricks는 작업 영역 사용자 대신 서비스 주체에 속한 개인용 액세스 토큰을 사용하는 것을 권장합니다. 서비스 주체에 대한 토큰을 만들려면 서비스 주체에 대한 토큰 관리를 참조하세요.
다음 Microsoft Entra ID 역할 중 하나를 할당받아야 합니다.
관리자 동의 워크플로가 구성된 경우 관리자가 아닌 사용자가 로그인할 때 Tableau에 대한 액세스를 요청할 수 있습니다.
파트너 연결을 사용하여 Tableau Desktop에 Azure Databricks 연결
파트너 연결을 사용하여 몇 번의 클릭만으로 Tableau Desktop과 컴퓨팅 리소스 또는 SQL 웨어하우스를 연결할 수 있습니다.
- Azure Databricks 계정, 작업 영역 및 로그인한 사용자가 모두 Partner Connect에 대한 요구 사항을 충족하는지 확인합니다.
- 사이드바에서
 Marketplace.
Marketplace. - 파트너 연결 통합에서, 모두 보기를 클릭합니다.
- Tableau 타일을 클릭합니다.
- 파트너에 연결 대화 상자에서 컴퓨팅의 경우 연결하려는 Azure Databricks 컴퓨팅 리소스의 이름을 선택합니다.
- 연결 파일 다운로드를 선택합니다.
- Tableau Desktop을 시작하는 다운로드한 연결 파일을 엽니다.
- Tableau Desktop에서 인증 자격 증명을 입력한 다음 로그인클릭합니다.
- Microsoft Entra ID 토큰을 사용하려면 사용자 이름에 대한 토큰과 암호에 대한 Microsoft Entra ID 토큰을 입력합니다.
- Azure Databricks 개인용 액세스 토큰을 사용하려면 사용자 이름에 대한 토큰과 암호에 대한 개인 액세스 토큰을 입력합니다.
- Microsoft Entra ID 자격 증명을 사용하려면 연결편집을 클릭하고 데이터 탭에서 데이터베이스를 두 번 클릭한 다음 인증 목록에서 Microsoft Entra ID 선택합니다.
Tableau Desktop 2021.1 이상의 경우:
-
Microsoft Entra ID(이전의 Azure Active Directory) B2B 게스트 계정 또는 Azure Government의 Azure Databricks를 사용하지 않는 경우 OAuth 엔드포인트
https://login.microsoftonline.com/common입력 하기만 하면 됩니다.
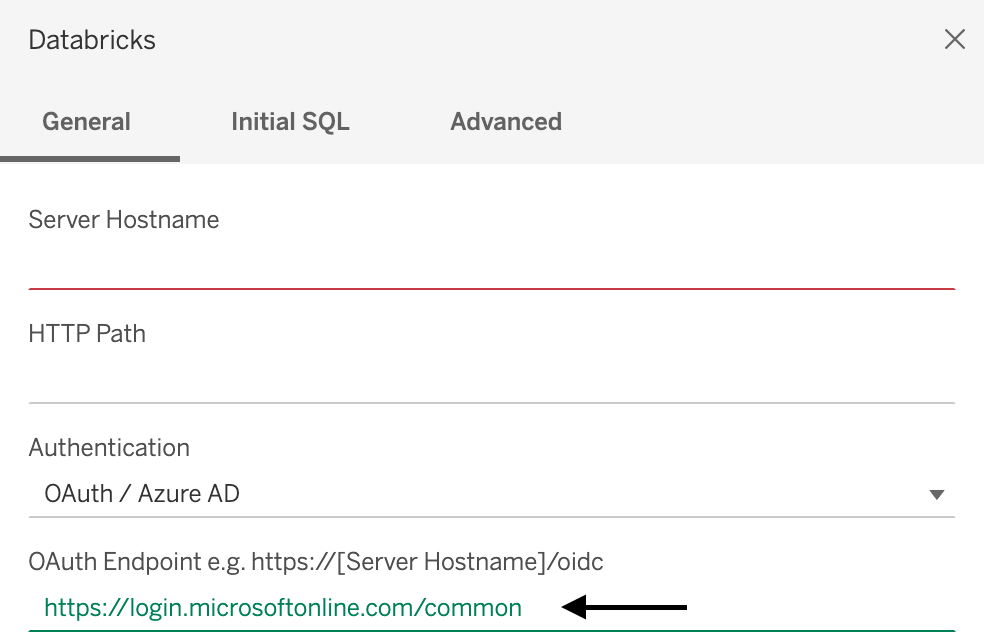
- Microsoft Entra ID B2B 게스트 계정이나 Azure Government의 Azure Databricks를 사용할 경우, 전용 Microsoft Entra ID 서비스 주체를 받으려면 관리자에게 문의하세요.
참고 항목
관리자가 아닌 경우 관리자 승인 필요 오류가 표시됩니다. 클라우드 애플리케이션 관리자 또는 애플리케이션 관리자에게 Tableau에 연결할 수 있는 권한을 부여하도록 요청한 다음 다시 로그인합니다.
Microsoft Entra ID 계정에 관리자 동의 워크플로가 사용하도록 설정된 경우 Tableau Desktop에서 Tableau에 대한 액세스를 요청하라는 메시지를 표시합니다. 클라우드 애플리케이션 관리자 또는 애플리케이션 관리자가 요청을 승인한 후 다시 로그인합니다.
-
Microsoft Entra ID(이전의 Azure Active Directory) B2B 게스트 계정 또는 Azure Government의 Azure Databricks를 사용하지 않는 경우 OAuth 엔드포인트
Azure Databricks에 Tableau Desktop 연결
다음 지침에 따라 Tableau Desktop에서 컴퓨팅 리소스 또는 SQL 웨어하우스로 연결합니다.
참고 항목
Tableau Desktop을 사용하여 더 빠르게 연결하려면 Partner Connect를 사용합니다.
Tableau Desktop을 시작합니다.
파일 > 새로 만들기를 클릭합니다.
데이터 탭에서 데이터에 연결을 클릭합니다.
커넥터 목록에서 Databricks클릭합니다.
서버 호스트 이름 및 HTTP 경로를 입력합니다.
인증방법을 선택하고 인증 자격 증명을 입력한 다음 로그인을 클릭합니다.
Microsoft Entra ID 토큰을 사용하려면 개인용 액세스 토큰 선택하고 암호Microsoft Entra ID 토큰을 입력합니다.
Azure Databricks 개인용 액세스 토큰을 사용하려면 개인 액세스 토큰 선택하고 암호대한 개인 액세스 토큰을 입력합니다.
Microsoft Entra ID 자격 증명을 사용하려면 Microsoft Entra ID을 선택합니다.
Tableau Desktop 2021.1 이상의 경우:
Microsoft Entra ID(이전의 Azure Active Directory) B2B 게스트 계정 또는 Azure Government의 Azure Databricks를 사용하지 않는 경우 OAuth 엔드포인트
https://login.microsoftonline.com/common입력 하기만 하면 됩니다.
- Azure Government에서 Microsoft Entra ID B2B 게스트 계정 또는 Azure Databricks를 사용하는 경우 관리자에게 문의하여 전용 Microsoft Entra ID 웨어하우스를 가져옵니다.
참고 항목
관리자가 아닌 경우 관리자 승인 필요 오류가 표시됩니다. 클라우드 애플리케이션 관리자 또는 애플리케이션 관리자에게 Tableau에 연결할 수 있는 권한을 부여하도록 요청한 다음, 다시 로그인해 봅니다.
Microsoft Entra ID 계정에 관리자 동의 워크플로가 사용하도록 설정된 경우 Tableau Desktop에서 Tableau에 대한 액세스를 요청하라는 메시지를 표시합니다. 클라우드 애플리케이션 관리자 또는 애플리케이션 관리자가 요청을 승인한 후 다시 로그인합니다.
작업 영역에 Unity 카탈로그를 사용하도록 설정한 경우 기본 카탈로그를 추가로 설정합니다. 고급 탭에서 연결 속성에 대해
Catalog=<catalog-name>을 추가합니다. 기본 카탈로그를 변경하려면 초기 SQL 탭에서USE CATALOG <catalog-name>입력합니다.
Azure Databricks에 Tableau Cloud 연결
다음 지침에 따라 Tableau Cloud에서 컴퓨팅 리소스 또는 SQL 웨어하우스에 연결합니다.
- 새 통합 문서 시작
- 메뉴 모음에서 데이터
- 데이터에 연결 페이지에서 커넥터 Databricks>를 클릭합니다.
- Azure Databricks 페이지에서 서버 호스트 이름과 HTTP 경로 값을 입력합니다.
- 인증 방법을 선택하고 요청된 정보를 입력합니다(있는 경우).
- 로그인을 클릭합니다.
Tableau Server on Linux
다음을 포함하도록 /etc/odbcinst.ini을 편집합니다.
[Simba Spark ODBC Driver 64-bit]
Description=Simba Spark ODBC Driver (64-bit)
Driver=/opt/simba/spark/lib/64/libsparkodbc_sb64.so
참고 항목
Tableau Server on Linux는 64비트 처리 아키텍처를 권장합니다.
Tableau Desktop에서 Tableau Cloud에 통합 문서 게시 및 새로 고침
이 문서에서는 Tableau Desktop에서 Tableau Cloud로 통합 문서를 게시하고 데이터 원본이 변경되면 계속 업데이트하는 방법을 보여줍니다. Tableau Desktop의 통합 문서와 Tableau Cloud 계정이 필요합니다.
- Tableau Desktop에서 통합 문서의 데이터를 추출합니다. Tableau Desktop에서 게시할 통합 문서가 표시된 상태에서 데이터>
<data-source-name>> 추출을 클릭합니다. - 데이터 추출 대화 상자에서 추출을 클릭합니다.
- 추출된 데이터를 저장할 로컬 컴퓨터의 위치로 이동한 다음 저장을 클릭합니다.
- 통합 문서의 데이터 원본을 Tableau Cloud에 게시합니다. Tableau Desktop에서 서버 > 데이터 원본 >
<data-source-name> - Tableau Server 로그인 대화 상자가 표시되면 Tableau Cloud 링크를 클릭하고 화면의 지시에 따라 Tableau Cloud에 로그인합니다.
- Tableau Cloud에 데이터 원본 게시
대화 상자의 새로 고침 사용 안 함 옆에 있는편집 링크를 클릭합니다. - 표시되는 플라이아웃 상자에서 인증에 대한 새로 고침 사용 안 함 을(를) 새로 고침 액세스 허용으로 변경합니다.
- 이 플라이아웃 외부의 아무 곳이나 클릭하여 숨깁니다.
- 업데이트 통합 문서를 선택하여 게시된 데이터 원본사용합니다.
- 게시를 클릭합니다. 데이터 원본이 Tableau Cloud에 표시됩니다.
- Tableau Cloud의 게시 완료 대화 상자에서 일정을 클릭하고 화면의 지시를 따릅니다.
- Tableau Cloud에 통합 문서 게시: Tableau Desktop에서 게시할 통합 문서가 표시된 상태에서 서버 > 게시 통합 문서를 클릭합니다.
- Tableau Cloud에 통합 문서 게시 대화 상자에서 게시를 클릭합니다. 통합 문서는 Tableau Cloud에 표시됩니다.
Tableau Cloud는 설정한 일정에 따라 데이터 원본의 변경 내용을 확인하고 변경 내용이 검색되면 게시된 통합 문서를 업데이트합니다.
자세한 정보는 Tableau 웹 사이트에서 다음을 참조하세요.
모범 사례 및 문제 해결
Tableau 쿼리를 최적화하기 위한 두 가지 기본 작업은 다음과 같습니다.
- 단일 차트 또는 대시보드에서 쿼리 및 시각화되는 레코드 수를 줄입니다.
- 단일 차트 또는 대시보드에서 Tableau에서 보내는 쿼리 수를 줄입니다.
먼저 시도할 것을 결정하는 것은 대시보드에 따라 달라집니다. 동일한 대시보드에 있는 개별 사용자에 대한 여러 차트가 있는 경우 Tableau가 Azure Databricks에 너무 많은 쿼리를 보낼 가능성이 높습니다. 차트가 몇 개뿐이지만 로드하는 데 시간이 오래 걸리는 경우 Azure Databricks에서 반환되는 레코드가 너무 많아 효과적으로 로드할 수 없을 수도 있습니다.
Tableau Desktop과 Tableau Server 모두에서 사용할 수 있는 Tableau 성능 기록은 특정 워크플로 또는 대시보드를 실행할 때 대기 시간을 유발하는 프로세스를 식별하여 성능 병목 상태를 식별하는 데 도움이 될 수 있습니다.
성능 기록을 사용하여 Tableau 이슈 디버그
예를 들어 쿼리 실행이 문제인 경우 쿼리하는 데이터 엔진 프로세스 또는 데이터 원본과 관련이 있다는 것을 알 수 있습니다. 시각적 레이아웃이 느리게 수행되는 경우 VizQL임을 알 수 있습니다.
성능 기록에 대기 시간이 실행 중인 쿼리에 있다고 표시되면 Azure Databricks에서 결과를 반환하거나 ODBC/커넥터 오버레이가 VizQL용 SQL로 데이터를 처리하는 데 너무 많은 시간이 소요된 것 같습니다. 이 경우 모든 항목을 하나의 대시보드로 밀어 넣고 빠른 필터에 의존하는 대신 반환되는 항목을 분석하고 그룹, 세그먼트 또는 아티클당 대시보드를 갖도록 분석 패턴을 변경해야 합니다.
정렬 또는 시각적 레이아웃으로 인해 성능이 저하되는 경우 대시보드에서 반환하려는 표시 수가 문제일 수 있습니다. Azure Databricks는 100만 개의 레코드를 신속하게 반환할 수 있지만 Tableau는 레이아웃을 계산하고 결과를 정렬하지 못할 수 있습니다. 이런 문제가 있는 경우 쿼리를 집계하고 하위 수준으로 드릴합니다. Tableau는 실행 중인 컴퓨터의 물리적 리소스에 의해서만 제한되므로 더 큰 컴퓨터를 사용해 볼 수도 있습니다.
성능 레코더에 대한 자세한 자습서는 성능 기록 만들기를 참조하세요.
Tableau Server 대비 Tableau Desktop의 성능
일반적으로 Tableau Desktop에서 실행되는 워크플로는 Tableau Server에서 더 빠르지 않습니다. Tableau Desktop에서 실행되지 않는 대시보드는 Tableau Server에서 실행되지 않습니다.
Tableau Server는 문제를 해결할 때 고려해야 할 프로세스가 더 많기 때문에 Desktop을 사용하는 것이 훨씬 더 나은 문제 해결 기술입니다. Tableau Desktop에서 작동하지만 Tableau Server에서는 작동하지 않는 경우 Tableau Desktop에 없는 Tableau Server의 프로세스로 문제를 안전하게 좁힐 수 있습니다.
구성
기본적으로 연결 URL의 매개 변수는 Simba ODBC DSN의 매개 변수보다 우선합니다. Tableau에서 ODBC 구성을 사용자 지정할 수 있는 두 가지 방법이 있습니다.
단일 데이터 원본에 대한
.tds파일:-
데이터 원본 저장의 지침에 따라 데이터 원본에 대한
.tds파일을 내보냅니다. -
odbc-connect-string-extras=''파일에서 속성 줄.tds찾아 매개 변수를 설정합니다. 예를 들어AutoReconnect및UseNativeQuery을 사용하려면 줄을odbc-connect-string-extras='AutoReconnect=1,UseNativeQuery=1'로 변경할 수 있습니다. - 연결을 다시 연결하여
.tds파일을 다시 로드합니다.
컴퓨팅 리소스는 큰 결과를 수집하기 위해 더 적은 힙 메모리를 사용하도록 최적화되어 Simba ODBC의 기본값보다 페치 블록당 더 많은 행을 제공할 수 있습니다.
RowsFetchedPerBlock=100000'속성 값에odbc-connect-string-extras을 추가합니다.-
데이터 원본 저장의 지침에 따라 데이터 원본에 대한
모든 데이터 원본에 대한
.tdc파일:-
.tdc파일을 만든 적이 없는 경우 TableauTdcExample.tdc를 폴더Document/My Tableau Repository/Datasources에 추가할 수 있습니다. - 대시보드를 공유할 때 작동하도록 모든 개발자의 Tableau Desktop 설치에 파일을 추가합니다.
-
차트 최적화(워크시트)
Tableau 워크시트의 성능을 개선하는 데 도움이 되는 다양한 전략적인 차트 최적화가 있습니다.
자주 변경되지 않고 상호 작용할 수 없는 필터의 경우 컨텍스트 필터를 사용하여 실행 시간을 단축합니다.
또 다른 좋은 규칙은 쿼리의 if/else 문 대신 case/when 문을 사용하는 것입니다.
Tableau는 필터를 데이터 원본으로 푸시다운하여 쿼리 속도를 향상시킬 수 있습니다. 데이터 원본 푸시다운 필터에 대한 자세한 내용은 매개 변수를 사용하여 여러 데이터 원본에서 필터링하기 및 여러 데이터 원본에서 데이터를 필터링하기를 참조하세요.
전체 데이터 세트를 검사할 때 테이블 계산을 피합니다. 테이블 계산에 대한 자세한 내용은 테이블 계산사용하여 값 변환
대시보드 최적화
다음은 Tableau 대시보드 성능을 개선하기 위해 적용할 수 있는 몇 가지 팁과 문제 해결 연습입니다.
Azure Databricks에 연결된 Tableau 대시보드를 사용하면 다양한 사용자, 함수 또는 세그먼트를 제공하는 개별 대시보드에 대한 빠른 필터가 일반적인 문제의 원인일 수 있습니다. 대시보드의 모든 차트에 빠른 필터를 연결할 수 있습니다. 5개의 차트가 있는 대시보드에서 하나의 빠른 필터를 사용하면 최소 10개의 쿼리가 Azure Databricks로 전송됩니다. 이렇게 하면 더 많은 필터가 추가될 때 더 많은 수로 증가할 수 있으며, Spark가 동일한 순간에 시작하는 많은 동시 쿼리를 처리하도록 빌드되지 않았기 때문에 성능 문제가 발생할 수 있습니다. 이 문제는 사용 중인 Azure Databricks 클러스터 또는 SQL 웨어하우스가 대용량 쿼리를 처리할 만큼 충분히 크지 않을 때 더 문제가 됩니다.
첫 번째 단계로 Tableau 성능 기록을 사용하여 이슈의 원인이 될 수 있는 문제를 해결하는 것이 좋습니다.
성능 저하가 정렬 또는 시각적 레이아웃에 의해 발생하는 경우, 문제는 대시보드에서 반환하려는 표시 수일 수 있습니다. Azure Databricks는 100만 개의 레코드를 신속하게 반환할 수 있지만 Tableau는 레이아웃을 계산하고 결과를 정렬하지 못할 수 있습니다. 이런 문제가 있는 경우 쿼리를 집계하고 하위 수준으로 드릴합니다. Tableau는 실행 중인 컴퓨터의 물리적 리소스에 의해서만 제한되므로 더 큰 컴퓨터를 사용해 볼 수도 있습니다.
Tableau에서 드릴다운하는 방법에 대한 자세한 내용은 세부 정보 드릴다운을 참조하세요.
세분화된 표시가 많은 경우 인사이트를 제공하지 않으므로 분석 패턴이 좋지 않은 경우가 많습니다. 높은 수준의 집계에서 세부 항목으로 내려가는 것이 더 합리적이며, 처리 및 시각화해야 할 레코드 수를 줄입니다.
액션을 사용하여 대시보드를 최적화
Tableau _actions을 사용하여 마크(예: 지도상의 주)를 클릭하면 클릭한 주에 따라 필터링되는 다른 대시보드로 전송됩니다. _actions 사용하면 한 대시보드에서 여러 필터의 필요성과 생성해야 하는 레코드 수가 줄어듭니다. (필터링할 조건자를 얻을 때까지 으로 작업을 설정하고이 아닌 레코드를 생성합니다.
자세한 정보는 작업 및 대시보드 성능을 더 향상시키는 6가지 팁을 참조하세요.
캐싱
데이터 캐싱은 워크시트 또는 대시보드의 성능을 향상시키는 좋은 방법입니다.
Tableau의 캐싱
Tableau에는 데이터가 라이브 연결 또는 추출에 있는지 여부에 관계없이 데이터로 돌아가기 전에 다음 과 같은 4개의 캐싱 계층이 있습니다.
- 타일: 다른 사용자가 동일한 대시보드를 로드하고 변경 내용이 없는 경우 Tableau는 차트에 동일한 타일을 다시 사용하려고 합니다. 이는 Google Maps 타일과 유사합니다.
- 모델: 타일 캐시를 사용할 수 없는 경우 수학 계산의 모델 캐시를 사용하여 시각화를 생성합니다. Tableau Server는 동일한 모델을 사용하려고 합니다.
- 추상: 쿼리의 집계 결과도 저장됩니다. 이것은 세 번째 "방어" 수준입니다. 쿼리가 이전 쿼리에서 Sum(Sales), Count(orders), Sum(Cost)을 반환하고 이후 쿼리에서 Sum(Sales)만 원하는 경우 Tableau는 해당 결과를 가져와 사용합니다.
- 네이티브 캐시: 쿼리가 다른 쿼리와 동일한 경우 Tableau는 동일한 결과를 사용합니다. 이것은 캐싱의 마지막 수준입니다. 이 작업이 실패하면 Tableau가 데이터로 이동합니다.
Tableau의 캐싱 빈도
Tableau에는 더 많거나 적게 캐싱하기 위한 관리 설정이 있습니다. 서버가 덜 자주 새로 고침로 설정되면 Tableau는 최대 12시간 동안 캐시에 데이터를 유지합니다. 서버가 더 자주 새로 고침으로 설정되면, Tableau는 모든 페이지가 새로 고침될 때마다 데이터로 돌아갑니다.
같은 대시보드를 반복적으로 사용하는 고객(예: "월요일 아침 파이프라인 보고서"
Tableau의 캐시 온난화
Tableau에서는 대시보드를 보기 전에 보낼 대시보드에 대한 구독을 설정하여 캐시를 웜할 수 있습니다. (구독 이메일 이미지를 생성하려면 대시보드를 렌더링해야 합니다.) 구독을 사용하여 Tableau Server 캐시를 예열하는 방법에 대한 내용은 을 참조하세요..
Tableau Desktop: 오류 The drivers... are not properly installed
문제: Tableau Desktop을 Databricks에 연결하려고 하면 드라이버 다운로드 페이지에 대한 링크가 있는 연결 대화 상자에 오류 메시지가 표시됩니다. 여기서 드라이버 링크 및 설치 지침을 찾을 수 있습니다.
원인: Tableau Desktop 설치 시 지원되는 드라이버가 실행되고 있지 않습니다.
해결 방법: Databricks ODBC 드라이버 버전 2.6.15 이상을 다운로드합니다.
참고 항목: 오류 "드라이버가... Tableau 웹 사이트에 제대로 설치되지 않았습니다."
기본/외래 키 제약 조건
기본 키(PK) 및 FK(외래 키) 제약 조건을 Azure Databricks에서 Tableau로 전파하려면 제약 조건과 관련된 두 플랫폼의 기능 및 제한 사항을 이해해야 합니다.
Azure Databricks 제약 조건 이해
Azure Databricks는 Databricks Runtime 15.2부터 기본 및 외래 키 제약 조건을 지원합니다. 이러한 제약 조건은 정보 제공이며 기본적으로 적용되지 않으므로 데이터 무결성 위반을 방지하지는 않지만 쿼리를 최적화하고 데이터 관계에 대한 메타데이터를 제공하는 데 사용할 수 있습니다. 기본 키 및 외래 키 관계 선언을 참조하세요.
Tableau에서 제약 조건을 사용하여 테이블 관계를 이해하기
Tableau는 기본 및 외래 키 제약 조건을 직접 적용하지 않습니다. 대신 Tableau는 관계를 사용하여 데이터 연결을 모델링합니다. Tableau의 제약 조건을 사용하려면 Tableau의 데이터 모델이 논리 계층과 물리적 계층이라는 두 가지 수준의 모델링을 제공한다는 것을 이해해야 합니다. Tableau 데이터 모델을 참조하세요. Tableau에서 관계로 인식되는 Azure Databricks 제약 조건에 대한 이 2단계 데이터 모델의 의미는 아래에 설명되어 있습니다.
Tableau에 Azure Databricks 연결
Azure Databricks를 Tableau에 연결하면 Tableau는 기존 키 제약 조건과 일치하는 필드를 기반으로 테이블 간의 실제 계층에서 관계를 만들려고 합니다. Tableau는 Azure Databricks에 정의된 기본 및 외래 키 제약 조건에 따라 물리적 계층에서 관계를 자동으로 검색하고 만들려고 시도합니다. 키 제약 조건이 정의되지 않은 경우 Tableau는 일치하는 열 이름을 사용하여 조인을 자동으로 생성합니다. 논리 계층에서는 관계를 결정하는 데 단일 열 이름 일치만 사용됩니다. 물리적 계층에서 이 열 이름 일치는 단순(단일 열) 및 복합(다중 열) 키 관계를 모두 검색합니다.
Tableau에서 일치하는 필드를 확인할 수 없는 경우 열, 조건 및 제약 조건 유형을 제공하여 실제 계층에서 두 테이블 간의 조인 관계를 수동으로 지정해야 합니다. UI의 논리 계층에서 실제 계층으로 이동하려면 논리 계층에서 테이블을 두 번 클릭합니다.