2020년 7월
이러한 기능 및 Azure Databricks 플랫폼 개선 사항은 2020년 7월에 릴리스되었습니다.
참고 항목
릴리스가 준비되었습니다. Azure Databricks 계정은 최초 릴리스 날짜 이후 최대 일주일까지 업데이트되지 않을 수 있습니다.
웹 터미널(공개 미리 보기)
2020년 7월 29일~8월 4일: 버전 3.25
웹 터미널은 클러스터에 대해 CAN ATTACH TO 권한을 가진 사용자가 Vim 또는 Emacs와 같은 편집기를 포함하여 셸 명령을 실행할 수 있는 편리하고 대화형 방법을 제공합니다. 웹 터미널의 사용 예에는 리소스 사용량 모니터링 및 Linux 패키지 설치가 포함됩니다.
자세한 내용은 Azure Databricks 웹 터미널에서 셸 명령 실행을 참조 하세요.
새롭고 더 안전한 글로벌 init 스크립트 프레임워크(공개 미리 보기)
2020년 7월 29일 - 8월 4일: 버전 3.25
새로운 전역 초기화 스크립트 프레임워크는 레거시 전역 초기화 스크립트에 비해 크게 개선되었습니다.
- 초기화 스크립트는 만들기, 보기 및 삭제에 관리자 권한이 필요하므로 더 안전합니다.
- 스크립트 관련 실행 실패가 기록됩니다.
- 여러 초기화 스크립트의 실행 순서를 설정할 수 있습니다.
- 초기화 스크립트는 클러스터 관련 환경 변수를 참조할 수 있습니다.
- Init 스크립트는 관리자 설정 페이지 또는 새 Global Init 스크립트 REST API를 사용하여 만들고 관리할 수 있습니다.
Databricks는 이러한 개선 사항을 활용하기 위해 기존 레거시 전역 초기화 스크립트를 새 프레임워크로 마이그레이션할 것을 권장합니다.
자세한 내용은 전역 init 스크립트 사용을 참조 하세요.
이제 IP 액세스 목록 GA
2020년 7월 29일 - 8월 4일: 버전 3.25
이제 IP 액세스 목록 API가 일반 공급됩니다.
GA 버전에는 list_type 값의 이름을 바꾸는 한 가지 변경 내용이 포함되어 있습니다.
WHITELIST-ALLOWBLACKLIST-BLOCK
IP 액세스 목록 API를 사용하여 사용자가 보안 경계가 있는 기존 회사 네트워크를 통해서만 서비스에 연결하도록 Azure Databricks 작업 영역을 구성합니다. Azure Databricks 관리자는 IP 액세스 목록 API를 사용하여 허용 및 차단 목록을 포함하여 승인된 IP 주소 집합을 정의할 수 있습니다. 웹 애플리케이션 및 REST API에 대한 모든 수신 액세스는 사용자가 승인된 IP 주소에서 연결해야 하므로 사용자가 VPN을 사용하지 않는 한 커피숍이나 공항과 같은 공용 네트워크에서 작업 영역에 액세스할 수 없습니다.
이 기능을 사용하려면 Premium 플랜이 필요합니다.
자세한 내용은 작업 영역에 대한 IP 액세스 목록 구성을 참조 하세요.
새 파일 업로드 대화 상자
2020년 7월 29일 - 8월 4일: 버전 3.25
이제 작은 테이블 형식 데이터 파일(예: CSV)을 업로드하고 Notebook 파일 메뉴에서 데이터 추가를 선택하여 Notebook에서 액세스할 수 있습니다. 생성된 코드는 데이터를 Pandas 또는 DataFrames에 로드하는 방법을 보여 줍니다. 관리자는 관리 콘솔 고급 탭에서 이 기능을 사용하지 않도록 설정할 수 있습니다.
자세한 내용은 DBFS에서 파일 찾아보기를 참조하세요.
SCIM API 필터 및 정렬 개선 사항
2020년 7월 29일 - 8월 4일: 버전 3.25
SCIM API에는 이제 다음과 같은 필터링 및 정렬 개선 사항이 포함됩니다.
- 관리 사용자가 특성에 대해 사용자를 필터링할
active수 있습니다. - 모든 사용자는
sortBy및sortOrder쿼리 매개 변수를 사용하여 결과를 정렬할 수 있습니다. 기본값은 ID별로 정렬하는 것입니다.
추가된 Azure Government 지역
2020년 7월 25일
Azure Databricks는 최근 미국 정부 기관 및 파트너를 위해 US Gov Arizona 및 US Gov Virginia 지역에서 사용할 수 있게 되었습니다.
Databricks Runtime 7.1 GA
2020년 7월 21일
Databricks Runtime 7.1은 다음을 포함하여 Databricks Runtime 7.0에 비해 많은 추가 기능과 개선 사항을 제공합니다.
- Google BigQuery 커넥터
- Notebook 세션에 설치된 Python 라이브러리를 관리하는
%pip명령 - 설치된 코알라
- 다음을 비롯한 많은 Delta Lake 개선 사항:
- 사용자 정의 커밋 메타데이터 설정
- 현재
SparkSession이 작성한 마지막 커밋 버전 가져오기 _spark_metadata트랜잭션 로그를 사용하여 구조적 스트리밍에서 만들어진 Parquet 테이블 변환MERGE INTO성능 향상
자세한 내용은 전체 Databricks Runtime 7.1(지원되지 않는) 릴리스 정보를 참조하세요.
Databricks Runtime 7.1 ML GA
2020년 7월 21일
Machine Learning용 Databricks Runtime 7.1은 Databricks Runtime 7.1을 기반으로 빌드되었으며 다음과 같은 새로운 기능과 라이브러리 변경 내용을 제공합니다.
- 기본적으로 사용하도록 설정된 pip 및 conda 매직 명령
- spark-tensorflow-distributor: 0.1.0
- pillow 7.0.0 -> 7.1.0
- pytorch 1.5.0 -> 1.5.1
- torchvision 0.6.0 -> 0.6.1
- horovod 0.19.1 -> 0.19.5
- mlflow 1.8.0 -> 1.9.1
자세한 내용은 ML용 전체 Databricks Runtime 7.1(지원되지 않는) 릴리스 정보를 참조하세요.
Databricks Runtime 7.1 Genomics GA
2020년 7월 21일
Genomics용 Databricks Runtime 7.1은 Databricks Runtime 7.1을 기반으로 빌드되었으며 다음과 같은 새로운 기능을 제공합니다.
- LOCO 변환
- GLOWGR 출력 변형 함수
- RNASeq는 짝을 이루지 않은 정렬을 출력합니다.
Databricks 커넥트 7.1(공개 미리 보기)
2020년 7월 17일
Databricks Connect 7.1이 이제 공개 미리 보기로 제공됩니다.
IP 액세스 목록 API 업데이트
2020년 7월 15~21일: 버전 3.24
다음 IP Access List API 속성이 변경되었습니다.
updator_user_id-updated_bycreator_user_id-created_by
이제 Python Notebook은 셀당 여러 출력을 지원합니다.
2020년 7월 15~21일: 버전 3.24
이제 Python Notebooks는 셀당 여러 출력을 지원합니다. 이는 셀에 display, displayHTML 또는 print 문을 원하는 수만큼 가질 수 있음을 의미합니다. 동일한 셀에서 원시 데이터와 플롯을 보거나 오류가 발생하기 전에 성공한 모든 출력을 볼 수 있는 기능을 활용합니다.
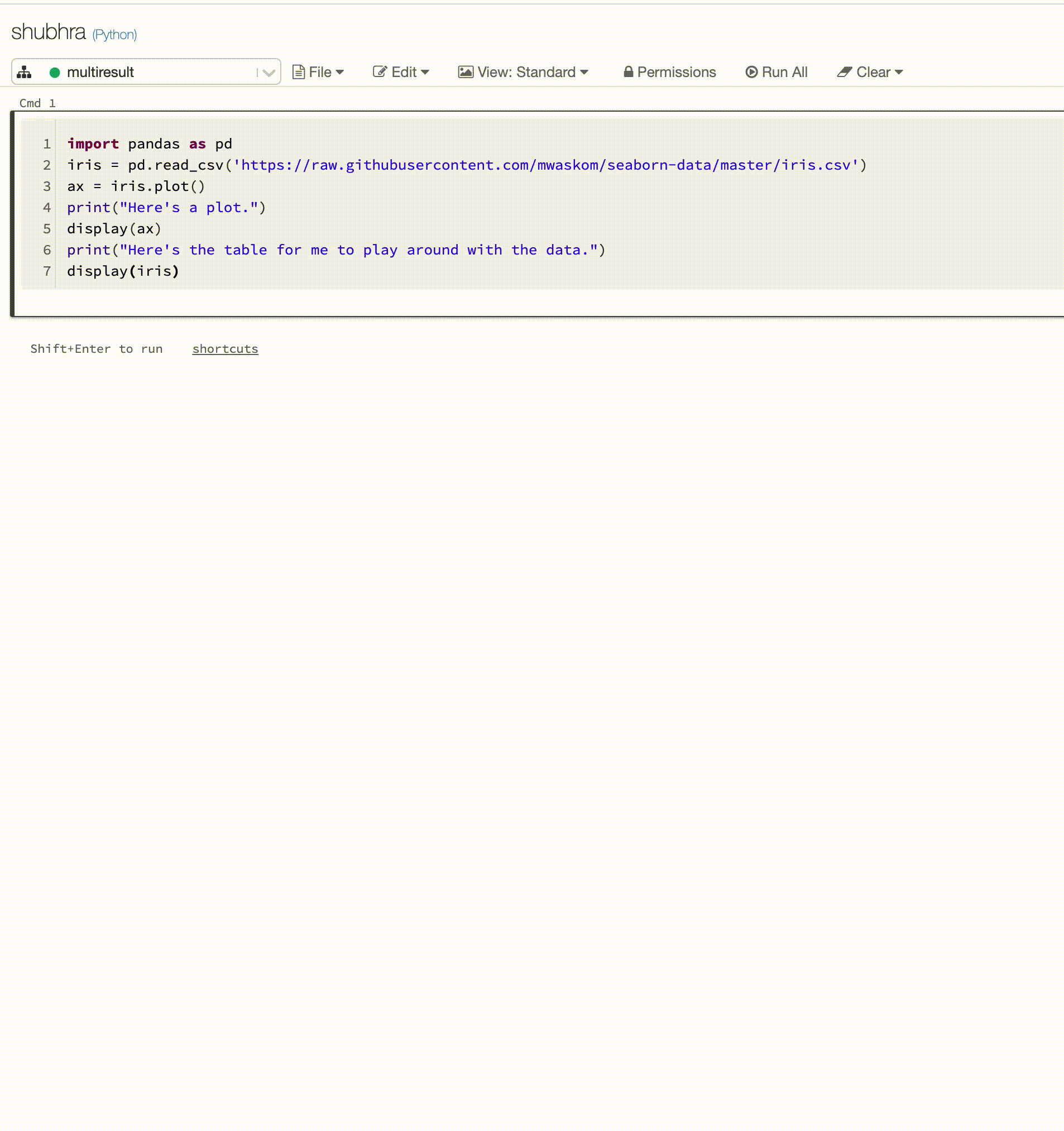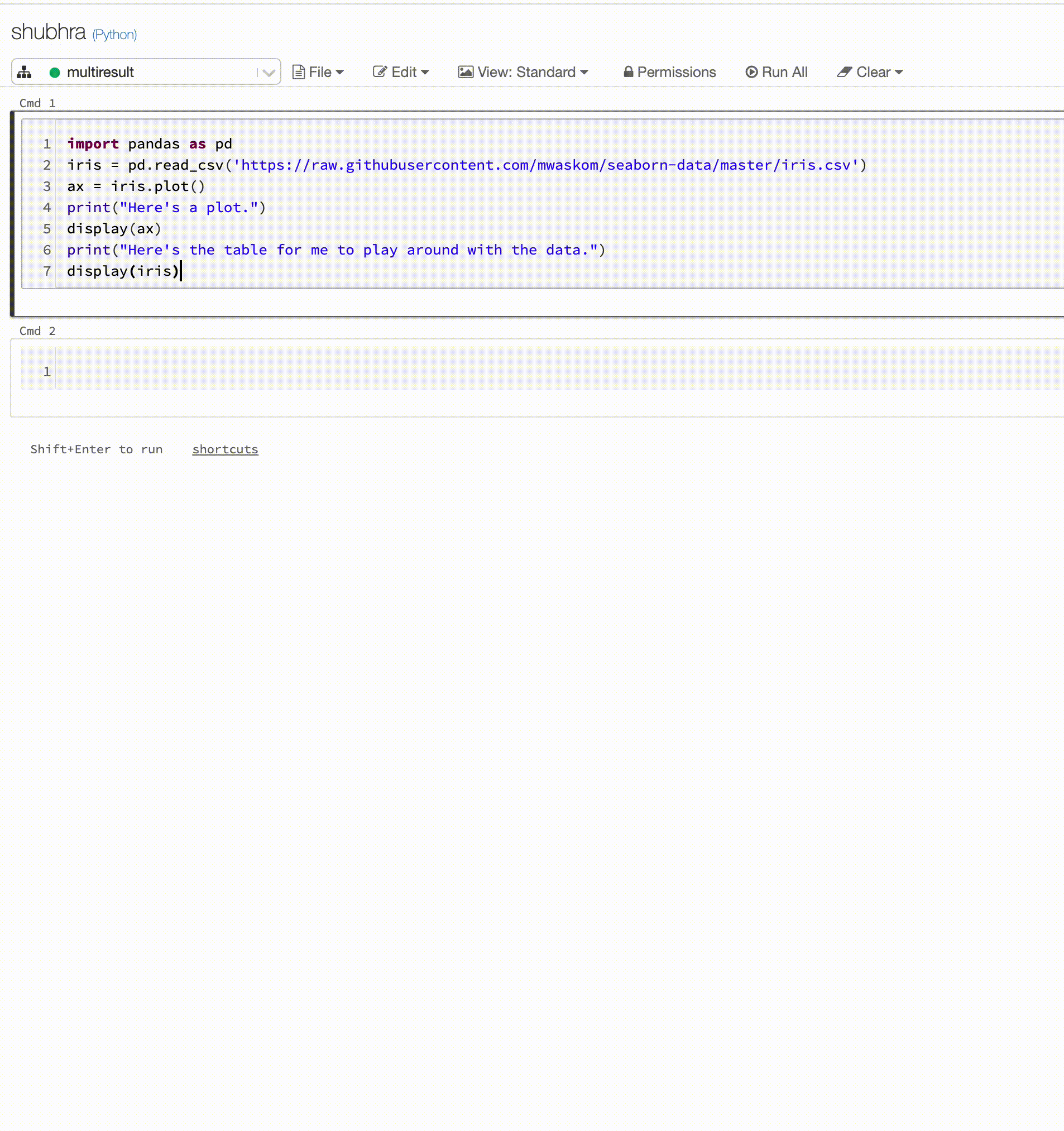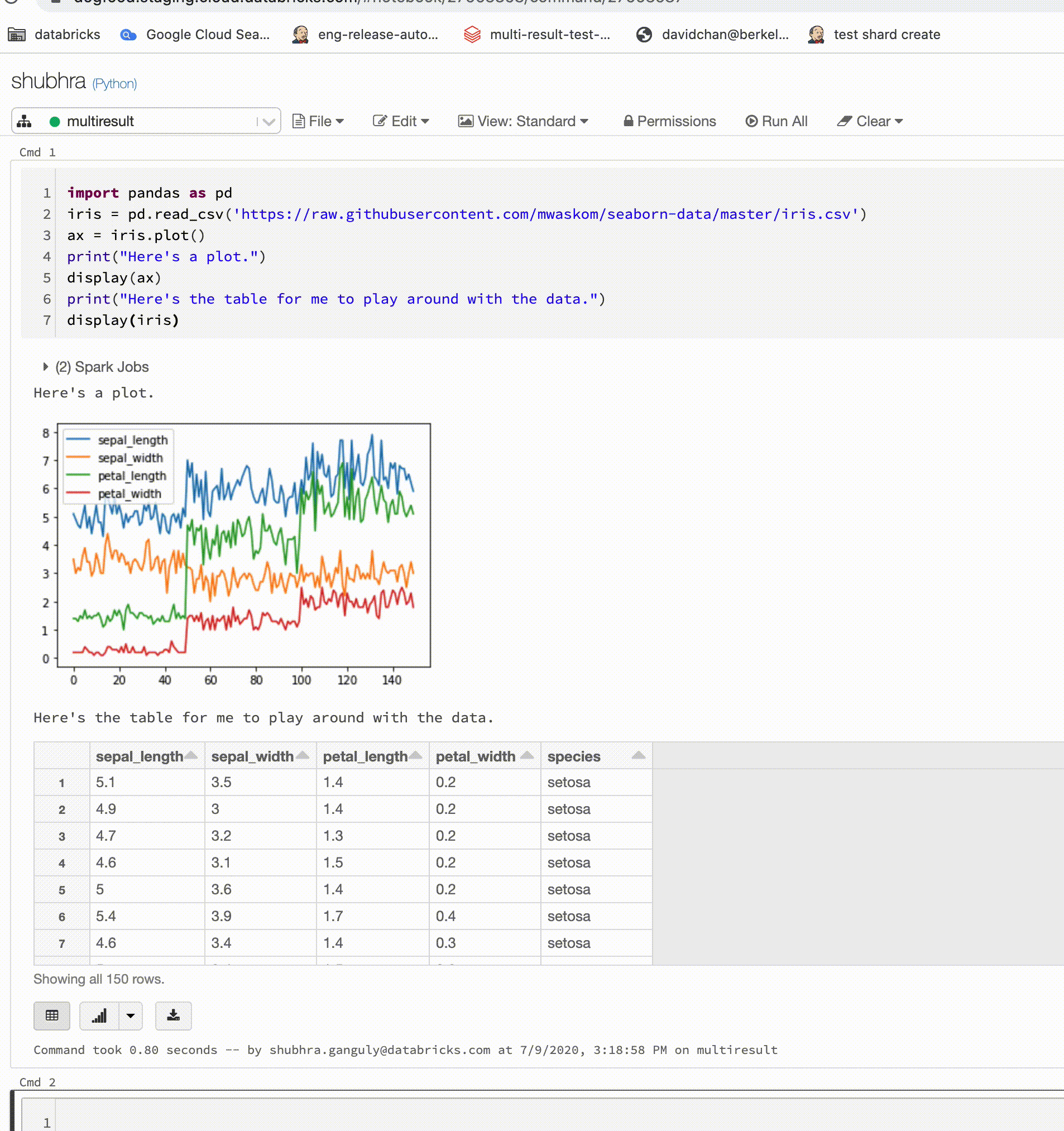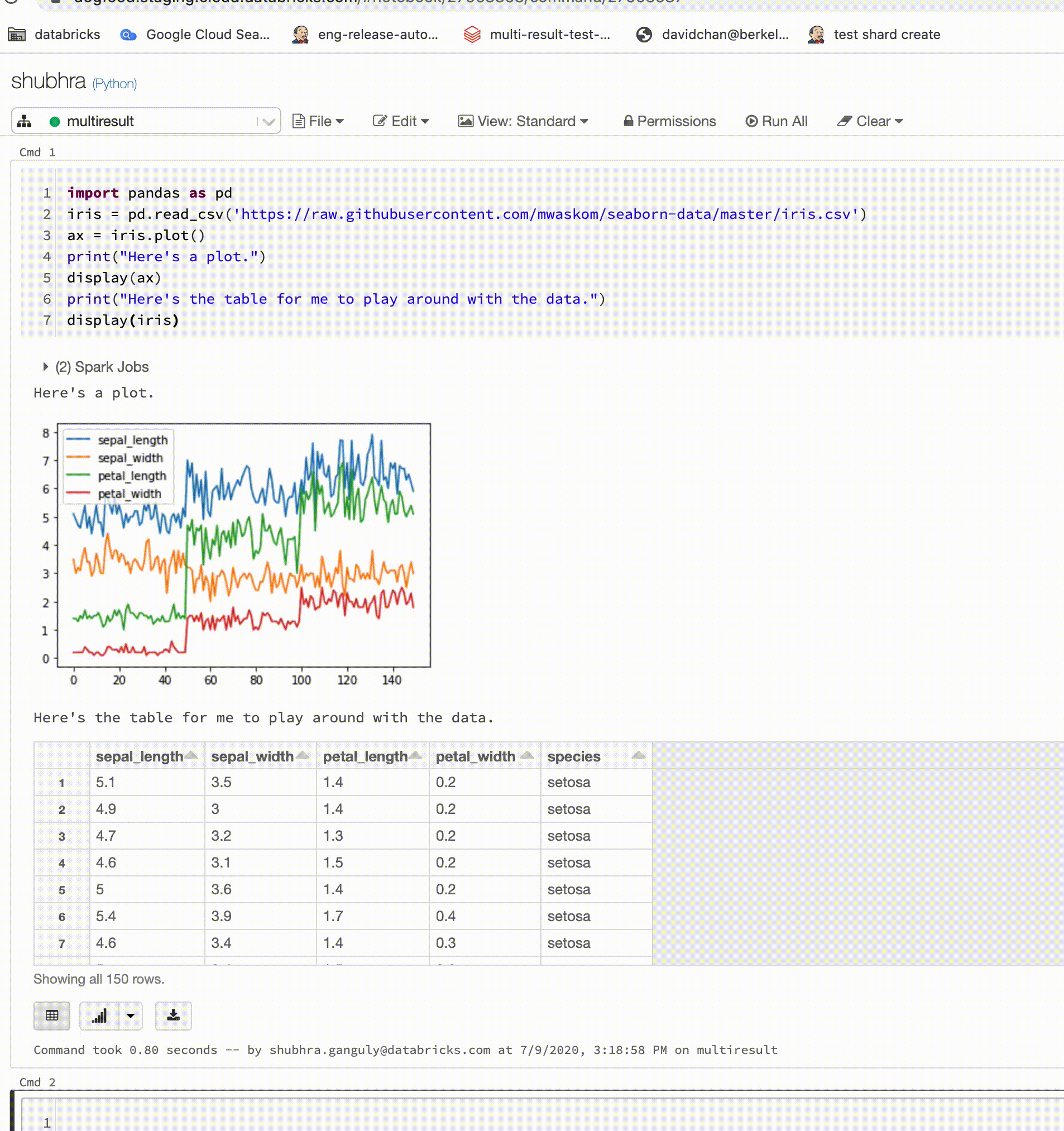
이 기능을 사용하려면 Databricks Runtime 7.1 이상이 필요하며 Databricks Runtime 7.1에서는 기본적으로 사용하지 않도록 설정되어 있습니다. spark.databricks.workspace.multipleResults.enabled true를 설정하여 사용하도록 설정합니다.
Notebook 코드와 결과 셀을 나란히 보기
2020년 7월 15~21일: 버전 3.24
새로운 나란히 Notebook 표시 옵션을 사용하면 코드와 결과를 나란히 볼 수 있습니다. 이 표시 옵션은 "표준" 옵션(이전의 "코드")과 "결과만" 옵션을 결합합니다.
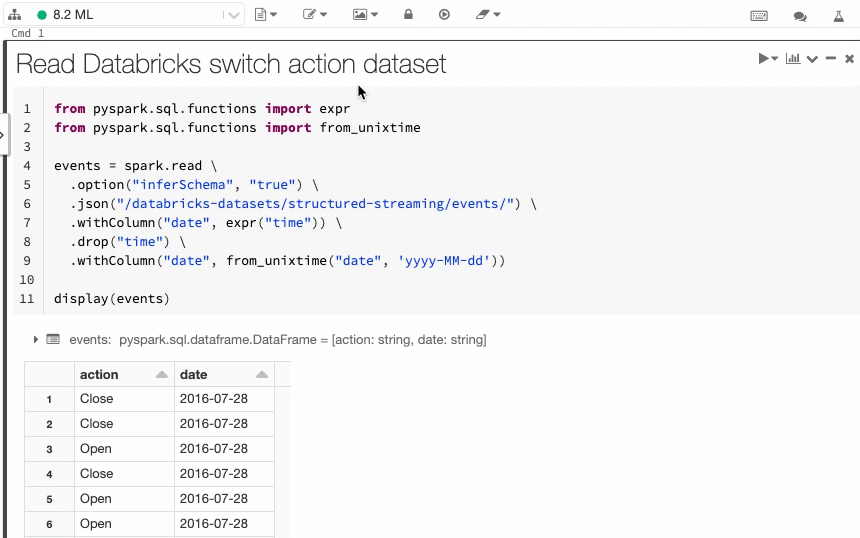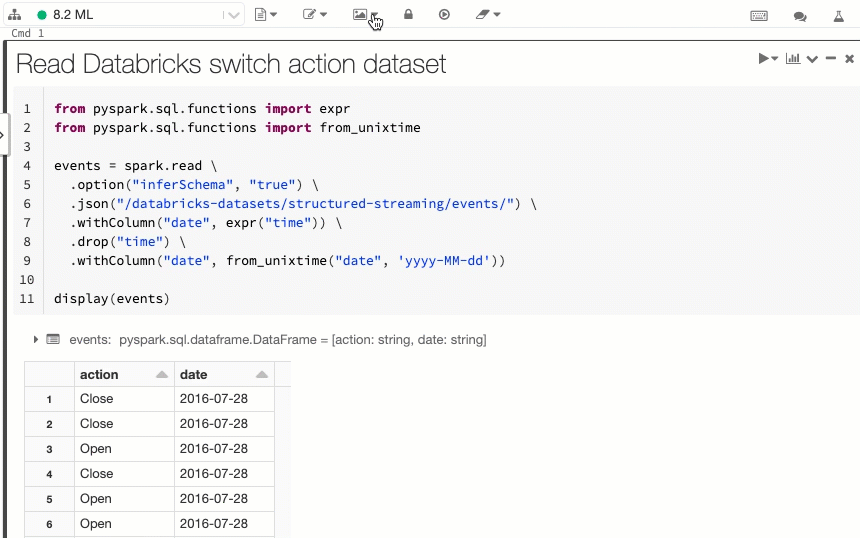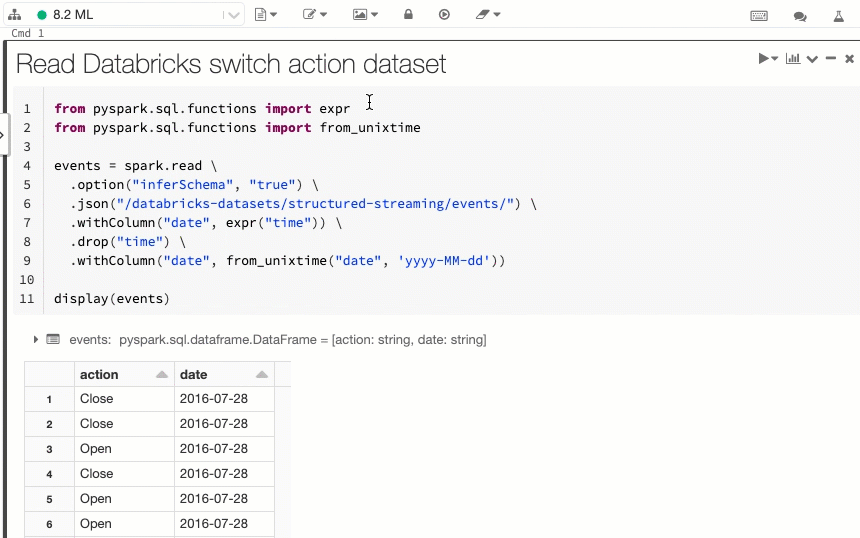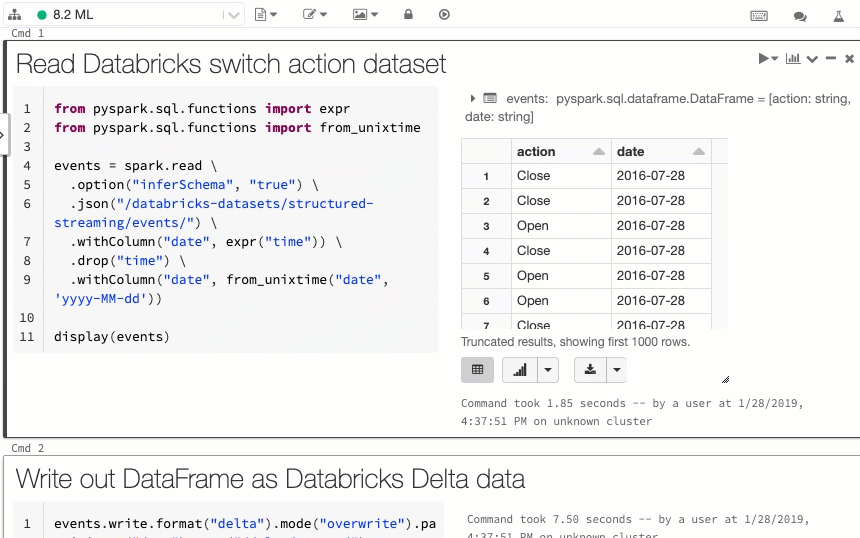
작업 일정 일시 중지
2020년 7월 15~21일: 버전 3.24
이제 작업 일정에 일시 중지 및 일시 중지 해제 단추가 있어 작업을 쉽게 일시 중지 및 다시 시작할 수 있습니다. 이제 변경하는 동안 추가 작업 실행을 시작하지 않고 작업 일정을 변경할 수 있습니다. 현재 실행 또는 지금 실행에 의해 트리거된 실행은 영향을 받지 않습니다. 자세한 내용은 작업 일정 일시 중지 및 다시 시작를 참조하세요.
작업 API 엔드포인트가 실행 ID의 유효성을 검사합니다.
2020년 7월 15~21일: 버전 3.24
jobs/runs/cancel 및 jobs/runs/output API 엔드포인트는 이제 run_id 매개 변수가 유효한지 유효성 검사합니다. 잘못된 매개 변수의 경우 이러한 API 엔드포인트는 이제 코드 500 대신 HTTP 상태 코드 400을 반환합니다.
Databricks REST API GA에 권한을 부여하는 Microsoft Entra ID 토큰
2020년 7월 15~21일: 버전 3.24
이제 Microsoft Entra ID 토큰을 사용하여 작업 영역 API에 인증할 수 있습니다. Microsoft Entra ID 토큰을 사용하면 새 작업 영역의 생성 및 설정을 자동화할 수 있습니다. 서비스 주체는 Microsoft Entra ID의 애플리케이션 개체입니다. Azure Databricks 작업 영역 내에서 서비스 주체를 사용하여 워크플로를 자동화할 수도 있습니다. 자세한 내용은 Microsoft Entra ID(이전의 Azure Active Directory) 토큰을 참조하세요.
Notebooks의 SQL 형식을 자동으로 지정
2020년 7월 15~21일: 버전 3.24
이제 바로 가기 키, 명령 바로 가기 메뉴 및 Notebook 편집 메뉴에서 SQL Notebook 셀의 서식을 지정할 수 있습니다(편집 > SQL 셀 서식 지정 선택). SQL 형식을 사용하면 적은 활동으로 코드를 쉽게 읽고 유지 관리할 수 있습니다. SQL Notebooks 및 %sql 셀에서 작동합니다.

Maven 및 CRAN 라이브러리에 대한 재현 가능한 설치 순서
2020년 7월 1일~9일: 버전 3.23
Azure Databricks는 이제 클러스터에 설치된 순서대로 Maven 및 CRAN 라이브러리를 처리합니다.
토큰 관리 API(공개 미리 보기)를 사용하여 사용자의 개인용 액세스 토큰 제어
2020년 7월 1일~9일: 버전 3.23
이제 Azure Databricks 관리자는 Token Management API를 사용하여 사용자의 Azure Databricks 개인용 액세스 토큰을 관리할 수 있습니다.
- 사용자의 개인용 액세스 토큰을 모니터링하고 해지합니다.
- 작업 영역에서 이후 토큰의 수명을 제어합니다.
- 토큰을 만들고 사용할 수 있는 사용자를 제어합니다.
개인용 액세스 토큰 모니터링 및 관리를 참조 하세요.
잘라내기 전자 필기장 셀 복원
2020년 7월 1일~9일: 버전 3.23
이제(Z) 바로 가기 키를 사용하거나 편집 > 셀 잘라내기 실행 취소를 선택하여 잘라낸 Notebook 셀을 복원할 수 있습니다. 이 함수는 삭제된 셀을 실행 취소하는 함수와 유사합니다.
관리자가 아닌 사용자에게 작업 CAN MANAGE 권한 할당
2020년 7월 1일~9일: 버전 3.23
이제 관리자가 아닌 사용자 및 그룹을 작업에 대한 CAN MANAGE 권한에 할당할 수 있습니다. 이 권한 수준을 통해 사용자는 권한 할당, 소유자 변경, 클러스터 구성 변경(예: 라이브러리 추가 및 클러스터 사양 수정)을 포함하여 작업의 모든 설정을 관리할 수 있습니다. 작업에 대한 액세스 제어를 참조 하세요.
관리자가 아닌 Azure Databricks 사용자는 SCIM API를 사용하여 사용자 이름으로 보고 필터링할 수 있습니다.
2020년 7월 1일~9일: 버전 3.23
관리자가 아닌 사용자는 이제 SCIM /Users 엔드포인트를 사용하여 사용자 이름을 보고 사용자 이름별로 사용자를 필터링할 수 있습니다.
작업 실행 세부 정보를 볼 때 클러스터 사양을 보는 링크
2020년 7월 1일~9일: 버전 3.23
이제 작업 실행에 대한 세부 정보를 볼 때 클러스터 구성 페이지에 대한 링크를 클릭하여 클러스터 사양을 볼 수 있습니다. 이전에는 URL에서 작업 ID를 복사하고 클러스터 목록으로 이동하여 검색해야 했습니다.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기