캐싱은 동일한 데이터를 여러 번 다시 계산하거나 가져올 필요가 없도록 하여 데이터 웨어하우스 시스템의 성능을 향상시키는 데 필수적인 기술입니다. Databricks SQL에서 캐싱은 쿼리 실행 속도를 크게 높이고 웨어하우스 사용을 최소화하여 비용을 절감하고 리소스 사용률을 높일 수 있습니다. 각 캐싱 계층은 쿼리 성능을 향상시키고, 클러스터 사용을 최소화하며, 원활한 데이터 웨어하우스 환경을 위해 리소스 사용률을 최적화합니다.
캐싱은 다음을 포함하여 데이터 웨어하우스에서 다양한 이점을 제공합니다.
- 속도: 쿼리 결과 또는 자주 액세스하는 데이터를 메모리 또는 기타 빠른 스토리지 매체에 저장하면 캐싱을 통해 쿼리 실행 시간을 크게 줄일 수 있습니다. 이 스토리지는 시스템에서 다시 계산하는 대신 캐시된 결과를 신속하게 검색할 수 있으므로 반복 쿼리에 특히 유용합니다.
- 클러스터 사용 감소: 캐싱은 이전에 계산된 결과를 다시 사용하여 추가 컴퓨팅 리소스의 필요성을 최소화합니다. 이렇게 하면 전체 웨어하우스 가동 시간 및 추가 컴퓨팅 클러스터에 대한 수요가 감소하여 비용을 절감하고 리소스 할당을 개선합니다.
Databricks SQL의 쿼리 캐시 유형
Databricks SQL은 여러 유형의 쿼리 캐싱을 수행합니다.
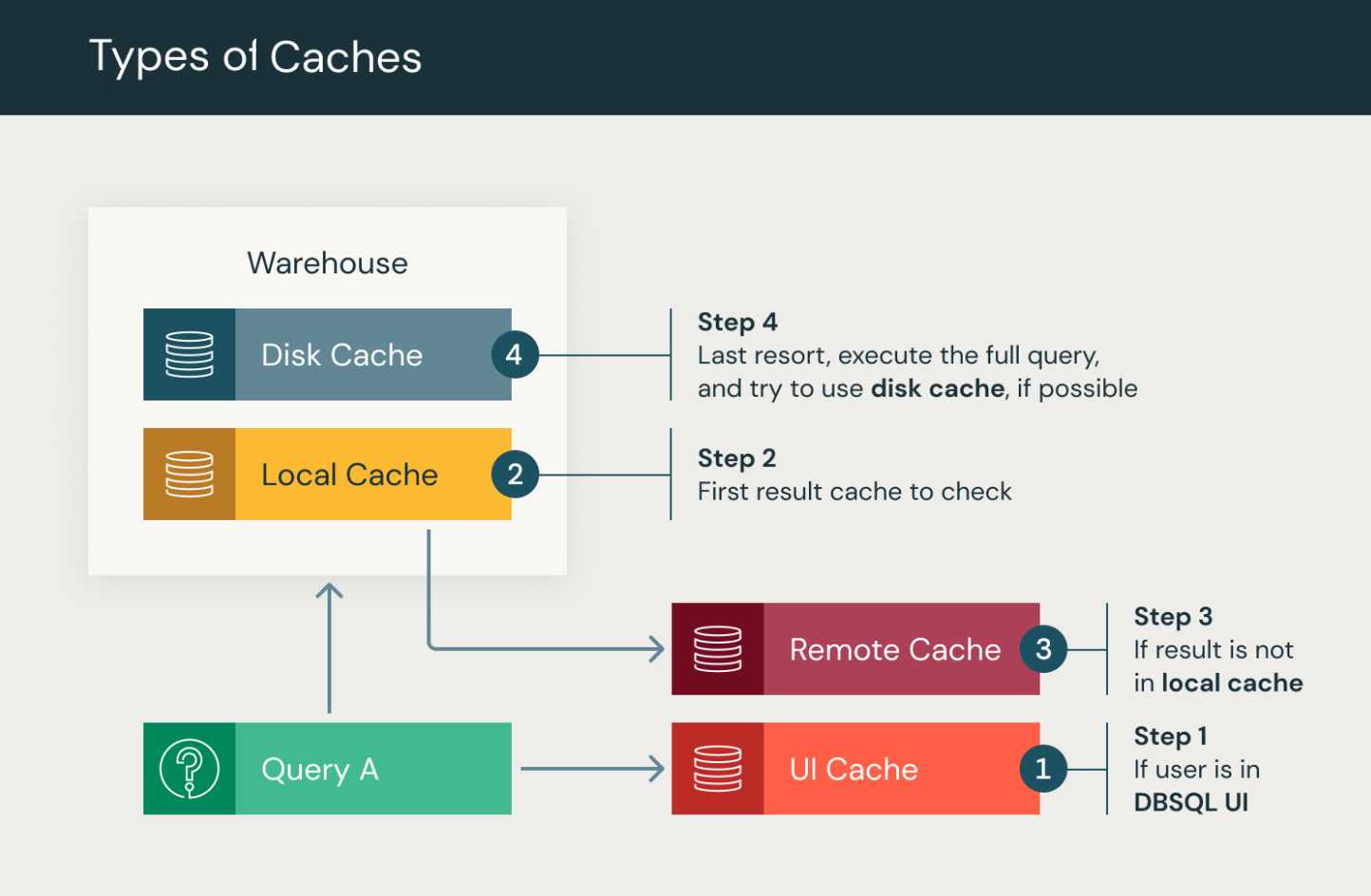
Databricks SQL UI 캐시: 모든 쿼리 및 대시보드의 사용자별 캐싱으로 인해 Databricks SQL UI가 생성됩니다. 사용자가 대시보드 또는 SQL 쿼리를 처음 열면 Databricks SQL UI 캐시는 예약된 실행의 결과를 포함하여 가장 최근의 쿼리 결과를 표시합니다.
Databricks SQL UI 캐시에는 최대 7일의 수명 주기가 있습니다. 캐시는 계정의 Azure Databricks 파일 시스템 내에 있습니다. 더 이상 저장하지 않으려는 쿼리를 다시 실행하여 쿼리 결과를 삭제할 수 있습니다. 다시 실행되면 이전 쿼리 결과가 캐시에서 제거됩니다. 또한 기본 테이블이 업데이트되면 캐시가 무효화됩니다.
결과 캐시: SQL 웨어하우스를 통한 모든 쿼리에 대한 쿼리 결과의 클러스터별 캐싱. 결과 캐싱에는 메모리 또는 원격 스토리지 매체에 쿼리 결과를 저장하여 쿼리 성능을 향상시키기 위해 함께 작동하는 로컬 및 원격 결과 캐시가 모두 포함됩니다.
- 로컬 캐시: 로컬 캐시는 클러스터의 수명 또는 캐시가 꽉 찼을 때까지 먼저 오는 쿼리 결과를 저장하는 메모리 내 캐시입니다. 이 캐시는 반복 쿼리 속도를 향상하여 동일한 결과를 다시 계산할 필요가 없도록 하는 데 유용합니다. 그러나 클러스터가 중지되거나 다시 시작되면 캐시가 정리되고 모든 쿼리 결과가 제거됩니다.
- 원격 결과 캐시: 원격 결과 캐시는 작업 영역 시스템 데이터로 유지하여 쿼리 결과를 유지하는 서버리스 전용 캐시 시스템입니다. 따라서 SQL 웨어하우스를 중지하거나 다시 시작하여 이 캐시가 무효화되지 않습니다. 원격 결과 캐시는 컴퓨팅 리소스가 실행되는 동안에만 사용 가능한 상태로 유지되는 메모리 내 쿼리 결과 캐싱의 일반적인 문제 지점을 해결합니다. 원격 캐시는 Databricks 작업 영역의 모든 웨어하우스에서 영구 공유 캐시입니다.
원격 결과 캐시에 액세스하려면 실행 중인 웨어하우스가 필요합니다. 쿼리를 처리할 때 클러스터는 먼저 로컬 캐시를 찾은 다음 필요한 경우 원격 결과 캐시를 찾습니다. 쿼리 결과가 캐시되지 않은 경우에만 쿼리가 실행됩니다. 로컬 캐시와 원격 캐시의 수명 주기는 모두 24시간이며 캐시 항목에서 시작됩니다. 원격 결과 캐시는 SQL 웨어하우스의 중지 또는 다시 시작을 통해 유지됩니다. 기본 테이블이 업데이트되면 두 캐시가 모두 무효화됩니다.
원격 결과 캐시는 ODBC/JDBC 클라이언트 및 SQL 문 API를 사용하는 쿼리에 사용할 수 있습니다.
쿼리 결과 캐싱을 사용하지 않도록 설정하려면 SQL 편집기에서
SET use_cached_result = false를 실행합니다.중요
이 옵션은 테스트 또는 벤치마킹에만 사용해야 합니다.
디스크 캐시: SQL 웨어하우스를 통한 쿼리를 위해 데이터 스토리지에서 읽은 데이터에 대한 로컬 SSD 캐싱입니다. 디스크 캐시는 디스크에 데이터를 저장하여 쿼리 성능을 향상시켜 가속 데이터 읽기를 허용하도록 설계되었습니다. 빠른 중간 형식을 사용하여 파일을 가져올 때 데이터가 자동으로 캐시됩니다. 디스크 캐시는 컴퓨팅 노드에 연결된 로컬 스토리지에 파일 복사본을 저장하여 데이터가 작업자와 더 가깝게 배치되어 쿼리 성능이 향상됩니다. 캐싱을 사용하여 Azure Databricks에서 성능을 최적화하는 방법에 대해 참조하세요.
디스크 캐시는 기본 함수 외에도 기본 데이터 파일의 변경 내용을 자동으로 검색합니다. 변경 내용을 감지하면 캐시가 무효화됩니다. 디스크 캐시는 로컬 결과 캐시와 동일한 수명 주기 특성을 공유합니다. 즉, 클러스터가 중지되거나 다시 시작되면 캐시가 정리되고 다시 채워져야 합니다.
쿼리 결과 캐싱 및 디스크 캐시는 Databricks SQL UI 및 BI 및 기타 외부 클라이언트의 쿼리에 영향을 줍니다.