이 문서에서는 수집, 변환 및 실시간 처리를 포함하여 데이터 엔지니어링 워크로드에 사용되는 두 가지 데이터 처리 의미 체계인 일괄 처리와 스트리밍의 주요 차이점을 설명합니다.
스트리밍은 일반적으로 Apache Kafka와 같은 메시지 버스에서 대기 시간이 짧고 지속적인 처리와 연결됩니다.
그러나 Azure Databricks에는 보다 광범위한 정의가 있습니다. Lakeflow Spark 선언적 파이프라인(Apache Spark 및 구조적 스트리밍)의 기본 엔진에는 일괄 처리 및 스트리밍 처리를 위한 통합 아키텍처가 있습니다.
- 엔진은 효율적인 증분 처리를 위해 클라우드 개체 스토리지 및 Delta Lake 와 같은 원본을 스트리밍 원본으로 처리할 수 있습니다.
- 스트리밍 처리는 트리거된 방식과 지속적인 방식으로 실행할 수 있으므로 스트리밍 워크로드에 대한 비용 및 성능 절충을 유연하게 제어할 수 있습니다.
다음은 일괄 처리 및 스트리밍을 구분하는 기본 의미 체계 차이점이며, 여기에는 장점과 단점, 워크로드에 대한 선택 고려 사항이 포함됩니다.
배치 의미론
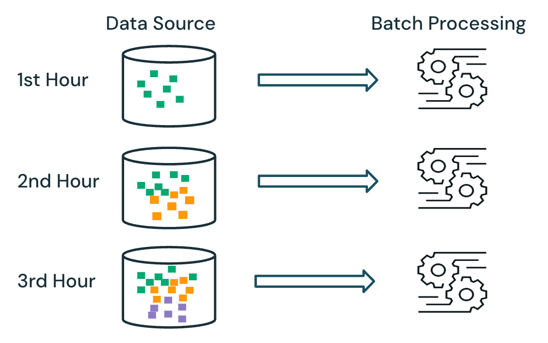
일괄 처리에서는 엔진이 원본에서 이미 처리 중인 데이터를 추적하지 않습니다. 현재 원본에서 사용할 수 있는 모든 데이터는 처리 시 처리됩니다. 실제로 일괄 처리 데이터 원본은 일반적으로 데이터 재처리를 제한하기 위해 일 또는 지역별로 논리적으로 분할됩니다.
예를 들어 전자상거래 회사에서 실행하는 판매 이벤트에 대해 시간 단위로 집계된 평균 항목 판매 가격을 계산하면 매시간 평균 판매 가격을 계산하기 위해 일괄 처리로 예약할 수 있습니다. 일괄 처리를 사용하면 이전 시간의 데이터가 매시간 다시 처리되고, 이전에 계산된 결과는 최신 결과를 반영하도록 덮어씁니다.
스트리밍 의미 체계
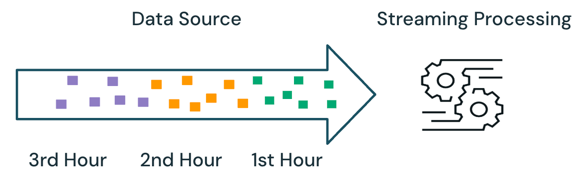
스트리밍 처리를 통해 엔진은 처리 중인 데이터를 추적하고 후속 실행에서 새 데이터만 처리합니다. 위의 예제에서는 일괄 처리 대신 스트리밍 처리를 예약하여 매시간 평균 판매 가격을 계산할 수 있습니다. 스트리밍을 사용하면 마지막 실행 이후 새 데이터만 원본에 추가됩니다. 전체 결과를 확인하려면 이전에 계산된 결과에 새로 계산된 결과를 추가해야 합니다.
일괄 처리 및 스트리밍
위의 예제에서 스트리밍은 이전 실행에서 처리된 동일한 데이터를 처리하지 않으므로 일괄 처리보다 낫습니다. 그러나 원본의 잘못된 순서 및 지연 도착 데이터와 같은 시나리오에서는 스트리밍 처리가 더 복잡해집니다.
지연 도착 데이터의 예는 첫 번째 시간의 일부 판매 데이터가 두 번째 시간까지 원본에 도착하지 않는 경우입니다.
- 일괄 처리에서 첫 번째 시간의 지연 도착 데이터는 두 번째 시간의 데이터와 첫 번째 시간의 기존 데이터로 처리됩니다. 첫 번째 시간의 이전 결과를 덮어쓰고 지연 도착 데이터로 수정합니다.
- 스트리밍 처리에서 첫 번째 시간에 늦게 도착하는 데이터는 먼저 처리된 첫 번째 시간의 다른 데이터와는 별도로 처리됩니다. 처리 논리는 이전 결과를 올바르게 업데이트하려면 첫 번째 시간의 평균 계산에서 합계 및 개수 정보를 저장해야 합니다.
일반적으로 이러한 스트리밍 복잡성은 조인, 집계 및 중복 제거와 같이 처리가 상태 저장일 때 발생합니다.
상태 없는 스트리밍 처리의 경우, 원본에서 데이터를 추가할 때 잘못된 순서의 데이터와 지연 도착 데이터를 처리하는 것이 덜 복잡합니다. 이는 지연 도착 데이터를 이전 결과에 추가할 수 있기 때문입니다.
아래 표에서는 일괄 처리 및 스트리밍 처리의 장단점과 Databricks Lakeflow에서 이러한 두 처리 의미 체계를 지원하는 다양한 제품 기능을 간략하게 설명합니다.
| 의미 처리 | 장점 | 단점 | 데이터 엔지니어링 제품 |
|---|---|---|---|
| 묶음 |
|
|
|
| 스트리밍 |
|
|
|
권장 사항
아래 표에서는 medallion 아키텍처의 각 계층에서 데이터 처리 워크로드의 특성에 따라 권장되는 처리 의미 체계를 간략하게 설명합니다.
| 메달리언 계층 | 워크로드 특성 | 추천 |
|---|---|---|
| 청동 |
|
|
| 은 |
|
|
| 금 |
|
|