Azure Databricks 작업에서의 dbt 변환 사용
Azure Databricks 작업에서 dbt Core 프로젝트를 작업으로 실행할 수 있습니다. dbt Core 프로젝트를 작업 작업으로 실행하면 다음 Azure Databricks 작업 기능을 활용할 수 있습니다.
- dbt 작업을 자동화하고 dbt 작업이 포함된 워크플로를 예약합니다.
- dbt 변환을 모니터링하고 변환 상태에 대한 알림을 보냅니다.
- 다른 작업과 함께 워크플로에 dbt 프로젝트를 포함합니다. 예를 들어 워크플로는 자동 로더로 데이터를 수집하고, dbt로 데이터를 변환하고, Notebook 작업으로 데이터를 분석할 수 있습니다.
- 로그, 결과, 매니페스트 및 구성을 포함하여 작업 실행의 아티팩트를 자동으로 보관합니다.
dbt Core에 대한 자세한 내용은 dbt 설명서를 참조하세요.
개발 및 프로덕션 워크플로
Databricks는 Databricks SQL 웨어하우스에 대해 dbt 프로젝트를 개발할 것을 권장합니다. Databricks SQL 웨어하우스를 사용하여 dbt에서 생성된 SQL을 테스트하고 SQL 웨어하우스 쿼리 기록을 사용하여 dbt에서 생성된 쿼리를 디버그할 수 있습니다.
프로덕션에서 dbt 변환을 실행하기 위해 Databricks는 Databricks 작업에서 dbt 작업을 사용할 것을 권장합니다. 기본적으로 dbt 작업은 Azure Databricks 컴퓨팅을 사용하여 dbt Python 프로세스를 실행하고 선택한 SQL 웨어하우스에 대해 dbt에서 생성된 SQL을 실행합니다.
서버리스 SQL 웨어하우스 또는 pro SQL Warehouse, Azure Databricks 컴퓨팅 또는 기타 dbt 지원 웨어하우스에서 dbt 변환을 실행할 수 있습니다. 이 문서에서는 예와 함께 처음 두 가지 옵션에 대해 설명합니다.
작업 영역이 Unity 카탈로그 사용이고 서버리스 워크플로 가 사용하도록 설정된 경우 기본적으로 작업은 서버리스 컴퓨팅에서 실행됩니다.
참고 항목
SQL 웨어하우스에 대해 dbt 모델을 개발하고 Azure Databricks 컴퓨팅에서 프로덕션 환경에서 실행하면 성능 및 SQL 언어 지원의 미묘한 차이가 발생할 수 있습니다. Databricks는 컴퓨팅 및 SQL 웨어하우스에 동일한 Databricks 런타임 버전을 사용하는 것이 좋습니다.
요구 사항
dbt Core 및
dbt-databricks패키지를 사용하여 개발 환경에서 dbt 프로젝트를 만들고 실행하는 방법을 알아보려면 dbt Core에 연결을 참조하세요.Databricks는 dbt-spark 패키지가 아닌 dbt-databricks 패키지를 사용할 것을 권장합니다. dbt-databricks 패키지는 Databricks에 최적화된 dbt-spark 포크입니다.
Azure Databricks 작업에서 dbt 프로젝트를 사용하려면 Databricks Git 폴더와 Git 통합을 설정 해야 합니다. DBFS에서 dbt 프로젝트를 실행할 수 없습니다.
서버리스 또는 Pro SQL 웨어하우스가 사용하도록 설정되어 있어야 합니다.
Databricks SQL 자격이 있어야 합니다.
첫 번째 dbt 작업 만들기 및 실행
다음 예에서는 핵심 dbt 개념을 보여 주는 프로젝트 예인 jaffle_shop 프로젝트를 사용합니다. jaffle shop 프로젝트를 실행하는 작업을 만들려면 다음 단계를 수행합니다.
Azure Databricks 방문 페이지로 이동하여 다음 중 하나를 수행합니다.
- 사이드바에서 워크플로를 클릭하고 을 클릭합니다
 .
.
- 사이드바에서 새로 만들기를 클릭하고
 작업을 선택합니다.
작업을 선택합니다.
- 사이드바에서 워크플로를 클릭하고 을 클릭합니다
작업 탭의 작업 텍스트 상자에서 작업 이름 추가...
작업 이름에 작업 이름을 입력합니다.
형식에서 dbt 작업 종류를 선택합니다.
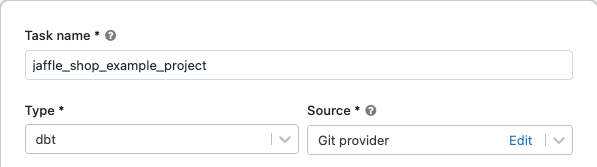
원본 드롭다운 메뉴에서 작업 영역을 선택하여 원격 Git 리포지토리에 있는 프로젝트에 대해 Azure Databricks 작업 영역 폴더 또는 Git 공급자에 있는 dbt 프로젝트를 사용할 수 있습니다. 이 예제에서는 Git 리포지토리에 있는 jaffle shop 프로젝트를 사용하므로 Git 공급자를 선택하고 편집을 클릭한 다음 jaffle shop GitHub 리포지토리에 대한 세부 정보를 입력합니다.
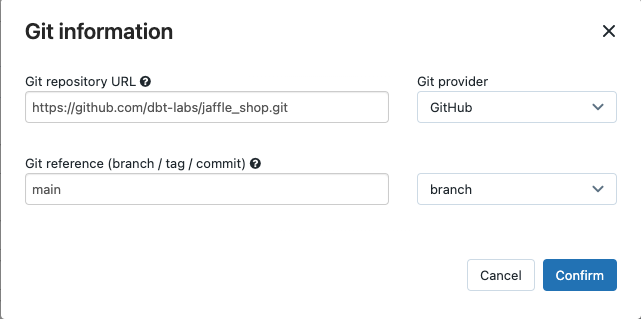
- Git 리포지토리 URL에 jaffle shop 프로젝트의 URL을 입력합니다.
- Git 참조(분기/태그/커밋)에서
main을 입력합니다. 태그 또는 SHA를 사용할 수도 있습니다.
확인을 클릭합니다.
dbt 명령 텍스트 상자에서 실행할 dbt 명령(deps, seed 및 run)을 지정합니다. 모든 명령에는
dbt접두어를 붙여야 합니다. 명령은 지정된 순서로 실행됩니다.
SQL 웨어하우스에서 dbt에 의해 생성된 SQL을 실행할 SQL 웨어하우스를 선택합니다. SQL 웨어하우스 드롭다운 메뉴에는 서버리스 및 Pro SQL 웨어하우스만 표시됩니다.
(선택 사항) 작업 출력에 대한 스키마를 지정할 수 있습니다. 기본적으로
default스키마가 사용됩니다.(선택 사항) dbt Core를 실행하는 컴퓨팅 구성을 변경하려면 dbt CLI 컴퓨팅을 클릭합니다.
(선택 사항) 작업에 대한 dbt-databricks 버전을 지정할 수 있습니다. 예를 들어 dbt 작업을 개발 및 프로덕션용 특정 버전에 고정하려면 다음을 수행합니다.
- 종속 라이브러리에서 현재 dbt-databricks 버전 옆을 클릭합니다
 .
. - 추가를 클릭합니다.
- 종속 라이브러리 추가 대화 상자에서 PyPI를 선택하고 패키지 텍스트 상자에 dbt-package 버전을 입력합니다(예:
dbt-databricks==1.6.0). - 추가를 클릭합니다.

참고 항목
Databricks는 dbt 작업을 dbt-databricks 패키지의 특정 버전에 고정하여 개발 및 프로덕션 실행에 동일한 버전을 사용할 것을 권장합니다. Databricks는 1.6.0 이상의 dbt-databricks 패키지를 권장합니다.
- 종속 라이브러리에서 현재 dbt-databricks 버전 옆을 클릭합니다
만들기를 클릭합니다.
지금 작업을 실행하려면 을 클릭합니다
 .
.
dbt 작업 작업의 결과 보기
작업이 완료되면 Notebook에서 SQL 쿼리를 실행하거나 Databricks 웨어하우스에서 쿼리를 실행하여 결과를 테스트할 수 있습니다. 예를 들어 다음 샘플 쿼리를 참조하세요.
SHOW tables IN <schema>;
SELECT * from <schema>.customers LIMIT 10;
<schema>를 작업 구성에 구성된 스키마 이름으로 바꿉니다.
API 예제
작업 API를 사용하여 dbt 작업을 포함하는 작업을 만들고 관리할 수도 있습니다. 다음 예에서는 단일 dbt 작업으로 작업을 만듭니다.
{
"name": "jaffle_shop dbt job",
"max_concurrent_runs": 1,
"git_source": {
"git_url": "https://github.com/dbt-labs/jaffle_shop",
"git_provider": "gitHub",
"git_branch": "main"
},
"job_clusters": [
{
"job_cluster_key": "dbt_CLI",
"new_cluster": {
"spark_version": "10.4.x-photon-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 0,
"spark_conf": {
"spark.master": "local[*, 4]",
"spark.databricks.cluster.profile": "singleNode"
},
"custom_tags": {
"ResourceClass": "SingleNode"
}
}
}
],
"tasks": [
{
"task_key": "transform",
"job_cluster_key": "dbt_CLI",
"dbt_task": {
"commands": [
"dbt deps",
"dbt seed",
"dbt run"
],
"warehouse_id": "1a234b567c8de912"
},
"libraries": [
{
"pypi": {
"package": "dbt-databricks>=1.0.0,<2.0.0"
}
}
]
}
]
}
(고급) 사용자 지정 프로필로 dbt 실행
SQL 웨어하우스(권장) 또는 다목적 컴퓨팅을 사용하여 dbt 작업을 실행하려면 연결할 웨어하우스 또는 Azure Databricks 컴퓨팅을 정의하는 사용자 지정 profiles.yml 을 사용합니다. 웨어하우스 또는 다목적 컴퓨팅을 사용하여 jaffle shop 프로젝트를 실행하는 작업을 만들려면 다음 단계를 수행합니다.
참고 항목
SQL 웨어하우스 또는 다목적 컴퓨팅만 dbt 작업의 대상으로 사용할 수 있습니다. dbt의 대상으로 작업 컴퓨팅을 사용할 수 없습니다.
jaffle_shop 리포지토리의 포크를 만듭니다.
포크된 리포지토리를 데스크톱에 복제합니다. 예를 들어 다음과 같은 명령을 실행할 수 있습니다.
git clone https://github.com/<username>/jaffle_shop.git<username>을 GitHub 핸들로 바꿉니다.다음 콘텐츠로
jaffle_shop디렉터리에profiles.yml이라는 새 파일을 만듭니다.jaffle_shop: target: databricks_job outputs: databricks_job: type: databricks method: http schema: "<schema>" host: "<http-host>" http_path: "<http-path>" token: "{{ env_var('DBT_ACCESS_TOKEN') }}"<schema>를 프로젝트 테이블의 스키마 이름으로 바꿉니다.- SQL 웨어하우스에서 dbt 작업을 실행하려면
<http-host>를 SQL 웨어하우스의 연결 세부 정보에 있는 서버 호스트 이름 값으로 바꿉니다. 다목적 컴퓨팅으로 dbt 작업을 실행하려면 Azure Databricks 컴퓨팅에 대한 고급 옵션, JDBC/ODBC 탭의 서버 호스트 이름 값으로 바꿉<http-host>니다. - SQL 웨어하우스에서 dbt 작업을 실행하려면
<http-path>를 SQL 웨어하우스의 연결 세부 정보에 있는 HTTP 경로 값으로 바꿉니다. 다목적 컴퓨팅으로 dbt 작업을 실행하려면 Azure Databricks 컴퓨팅에 대한 고급 옵션, JDBC/ODBC 탭의 HTTP 경로 값으로 바꿉<http-path>니다.
이 파일을 소스 제어로 확인하므로 파일에 액세스 토큰과 같은 비밀을 지정하지 않습니다. 대신 이 파일은 dbt 템플릿 기능을 사용하여 런타임에 자격 증명을 동적으로 삽입합니다.
참고 항목
생성된 자격 증명은 실행 기간(최대 30일)에 유효하며 완료 후 자동으로 해지됩니다.
이 파일을 Git에 체크인하고 포크된 리포지토리에 푸시합니다. 예를 들어 다음과 같은 명령을 실행할 수 있습니다.
git add profiles.yml git commit -m "adding profiles.yml for my Databricks job" git pushDatabricks UI의 사이드바에서 워크플로를 클릭합니다
. dbt 작업을 선택하고 작업 탭을 클릭합니다.
원본에서 편집을 클릭하고 포크된 jaffle shop GitHub 리포지토리 세부 정보를 입력합니다.
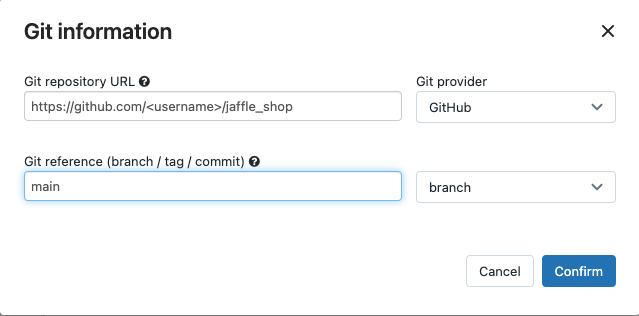
SQL 웨어하우스에서 없음(수동)을 선택합니다.
프로필 디렉터리에
profiles.yml파일이 포함된 디렉터리의 상대 경로를 입력합니다. 리포지토리 루트의 기본값을 사용하려면 경로 값을 비워 둡니다.
(고급) 워크플로에서 dbt Python 모델 사용
참고 항목
Python 모델에 대한 dbt 지원은 베타 버전으로 dbt 1.3 이상이 필요합니다.
현재 dbt는 Databricks를 비롯한 특정 데이터 웨어하우스에서 Python 모델을 지원합니다. dbt Python 모델을 통해 Python 에코시스템의 도구를 사용하여 SQL로는 어려운 변환을 구현할 수 있습니다. Azure Databricks 작업을 만들어 dbt Python 모델을 사용하여 단일 작업을 실행하거나 여러 작업을 포함하는 워크플로의 일부분으로 dbt 작업을 포함할 수 있습니다.
SQL 웨어하우스를 사용하여 dbt 작업에서 Python 모델을 실행할 수 없습니다. Azure Databricks에서 dbt Python 모델을 사용하는 방법에 대한 자세한 내용은 dbt 설명서의 특정 데이터 웨어하우스를 참조하세요.
오류 및 문제 해결
프로필 파일이 존재하지 않음 오류
오류 메시지:
dbt looked for a profiles.yml file in /tmp/.../profiles.yml but did not find one.
가능한 원인:
지정된 $PATH에서 profiles.yml 파일을 찾을 수 없습니다. dbt 프로젝트의 루트에 profiles.yml 파일이 포함되어 있는지 확인합니다.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기