자습서: Stream 분석을 사용하여 Event Hubs 이벤트에 대한 Apache Kafka 처리
이 문서에서는 데이터를 Event Hubs로 스트리밍하고 Azure Stream Analytics를 사용하여 처리하는 방법을 보여줍니다. 다음 단계를 안내합니다.
- Event Hubs 네임스페이스를 만듭니다.
- 이벤트 허브로 메시지를 전송하는 Kafka 클라이언트를 만듭니다.
- 이벤트 허브에서 Azure Blob Storage로 데이터를 복사하는 Stream Analytics 작업을 만듭니다.
이벤트 허브에서 노출한 Kafka 엔드포인트를 사용하는 경우 프로토콜 클라이언트를 변경하거나 사용자 고유의 클러스터를 실행할 필요가 없습니다. Azure Event Hubs는 Apache Kafka 버전 1.0 이상을 지원합니다.
필수 조건
이 빠른 시작을 완료하려면 다음 필수 구성 요소가 있어야 합니다.
- Azure 구독 구독이 없으면 시작하기 전에 체험 계정을 만듭니다.
- Java Development Kit(JDK) 1.7+.
- Maven 이진 아카이브를 다운로드하여 설치합니다.
- Git
- Azure Storage 계정. 계정이 없는 경우 계속 진행하기 전에 만듭니다. 이 연습에서 Stream Analytics 작업은 Azure Blob Storage에 출력 데이터를 저장합니다.
Event Hubs 네임스페이스 만들기
Event Hubs 네임스페이스를 만들면 네임스페이스에 대한 Kafka 엔드포인트가 자동으로 활성화됩니다. Kafka 프로토콜을 사용하는 애플리케이션에서 이벤트 허브로 이벤트를 스트리밍할 수 있습니다. Azure Portal을 사용하여 이벤트 허브 만들기의 단계별 지침에 따라 Event Hubs 네임스페이스를 만듭니다. 전용 클러스터를 사용하는 경우 전용 클러스터에서 네임스페이스 및 이벤트 허브 만들기를 참조하세요.
참고 항목
Kafka용 Event Hubs는 기본 계층에서 지원되지 않습니다.
Event Hubs에서 Kafka로 메시지 보내기
Kafka용 Azure Event Hubs 리포지토리를 머신에 복제합니다.
azure-event-hubs-for-kafka/quickstart/java/producer폴더로 이동합니다.src/main/resources/producer.config에서 생산자에 대한 구성 세부 정보를 업데이트합니다. 이벤트 허브 네임스페이스에 대한 이름 및 연결 문자열을 지정합니다.bootstrap.servers={EVENT HUB NAMESPACE}.servicebus.windows.net:9093 security.protocol=SASL_SSL sasl.mechanism=PLAIN sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="$ConnectionString" password="{CONNECTION STRING for EVENT HUB NAMESPACE}";azure-event-hubs-for-kafka/quickstart/java/producer/src/main/java/으로 이동하고 선택한 편집기에서 TestDataReporter.java 파일을 엽니다.다음 코드 줄을 주석으로 처리합니다.
//final ProducerRecord<Long, String> record = new ProducerRecord<Long, String>(TOPIC, time, "Test Data " + i);주석 처리된 코드 대신 다음 코드 줄을 추가합니다.
final ProducerRecord<Long, String> record = new ProducerRecord<Long, String>(TOPIC, time, "{ \"eventData\": \"Test Data " + i + "\" }");이 코드는 JSON 형식으로 이벤트 데이터를 보냅니다. Stream Analytics 작업에 대한 입력을 구성할 때 입력 데이터 형식으로 JSON을 지정합니다.
생산자를 실행하고 Event Hubs로 스트리밍합니다. Windows 머신에서 Node.js 명령 프롬프트를 사용할 때 이러한 명령을 실행하기 전에
azure-event-hubs-for-kafka/quickstart/java/producer폴더로 전환합니다.mvn clean package mvn exec:java -Dexec.mainClass="TestProducer"
이벤트 허브에서 데이터를 수신하는지 확인
엔터티에서 Event Hubs를 선택합니다. 테스트라는 이벤트 허브가 표시되는지 확인합니다.
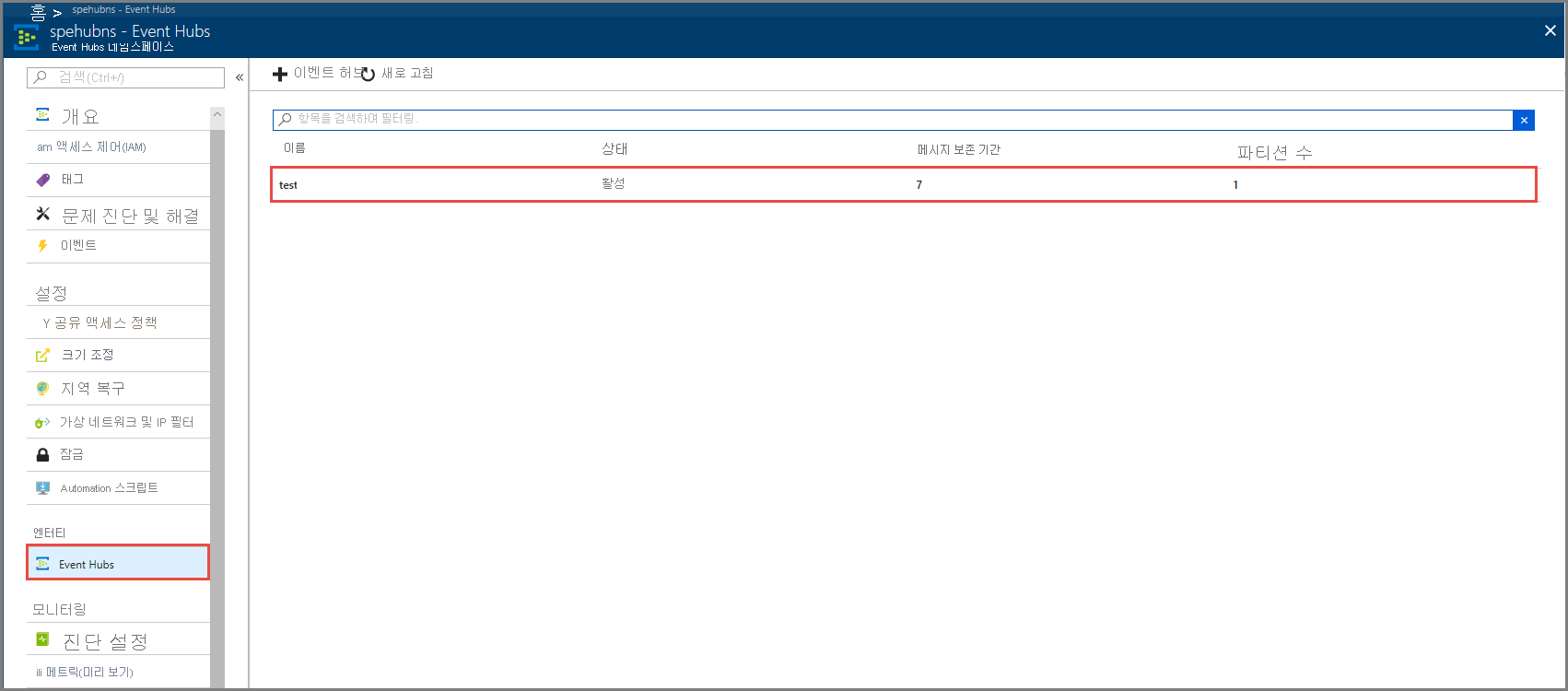
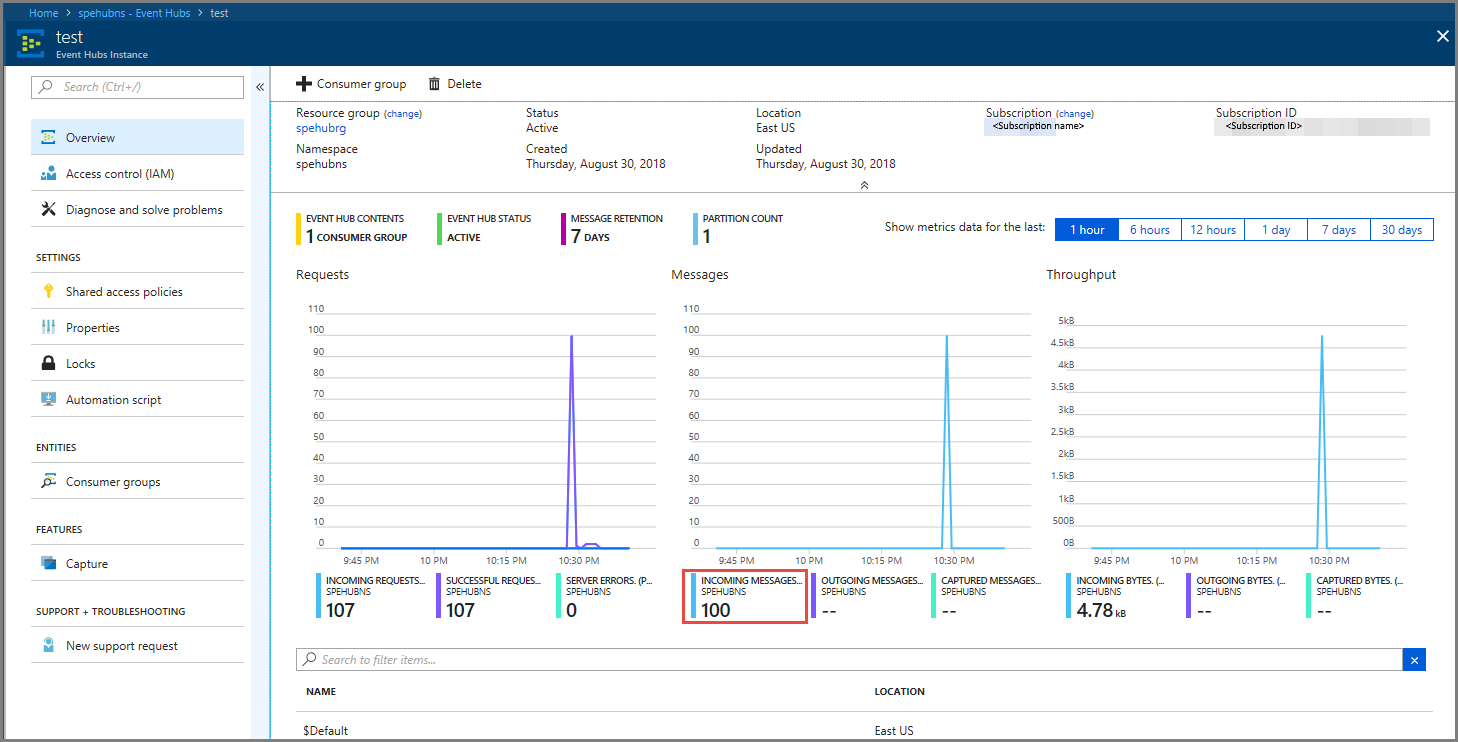
이벤트 허브로 들어오는 메시지가 표시되는지 확인합니다.
Stream Analytics 작업을 사용하여 이벤트 데이터 처리
이 섹션에서는 Azure Stream Analytics 작업을 만듭니다. Kafka 클라이언트가 이벤트 허브로 이벤트를 보냅니다. 입력으로 이벤트 데이터를 사용하고 Azure Blob Storage에 출력하는 Stream Analytics 작업을 만듭니다. Azure Storage 계정이 없는 경우 만듭니다.
Stream Analytics 작업에서 쿼리는 분석을 수행하지 않고 데이터를 통해 전달됩니다. 다른 형식으로 또는 얻은 정보를 사용하여 출력 데이터를 생성하기 위해 입력 데이터를 변환하는 쿼리를 만들 수 있습니다.
Stream Analytics 작업 만들기
- Azure Portal에서 + 리소스 만들기를 선택합니다.
- Azure Marketplace 메뉴에서 Analytics를 선택하고 Stream Analytics 작업을 선택합니다.
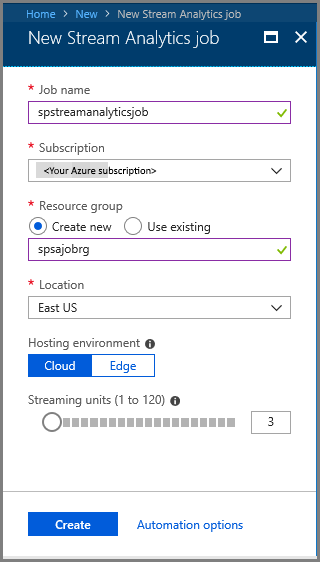
- 새 Stream Analytics 페이지에서 다음 작업을 수행합니다.
작업의 이름을 입력합니다.
구독을 선택합니다.
리소스 그룹에 대해 새로 만들기를 선택하고 이름을 입력합니다. 기존 리소스 그룹을 사용할 수도 있습니다.
작업의 위치를 선택합니다.
만들기를 선택하여 작업을 만듭니다.
작업 입력 구성
알림 메시지에서 리소스로 이동을 선택하여 Stream Analytics 작업 페이지를 봅니다.
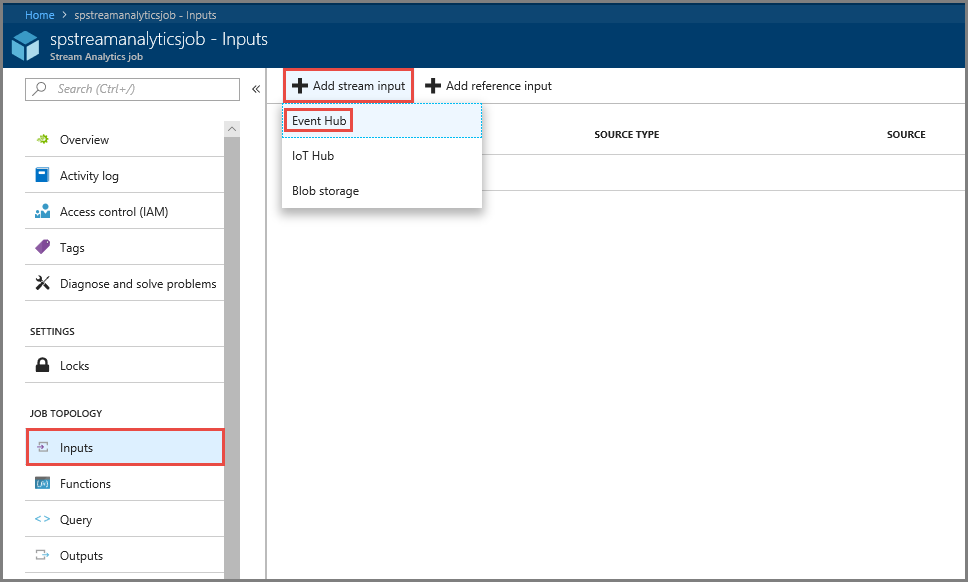
왼쪽 메뉴의 작업 토폴로지 섹션에서 입력을 선택합니다.
스트림 입력 추가를 선택한 다음, 이벤트 허브를 선택합니다.
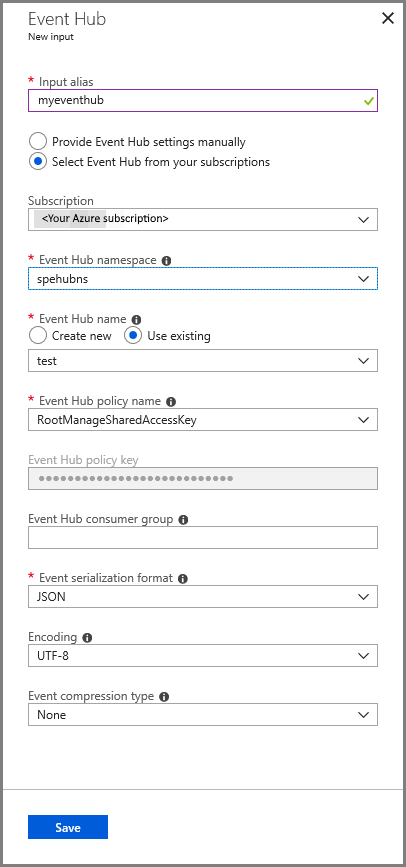
이벤트 허브 입력 구성 페이지에서 다음 작업을 수행합니다.
입력의 별칭을 지정합니다.
Azure 구독을 선택합니다.
이전에 만든 이벤트 허브 네임스페이스를 선택합니다.
이벤트 허브에 대해 테스트를 선택합니다.
저장을 선택합니다.
작업 출력 구성
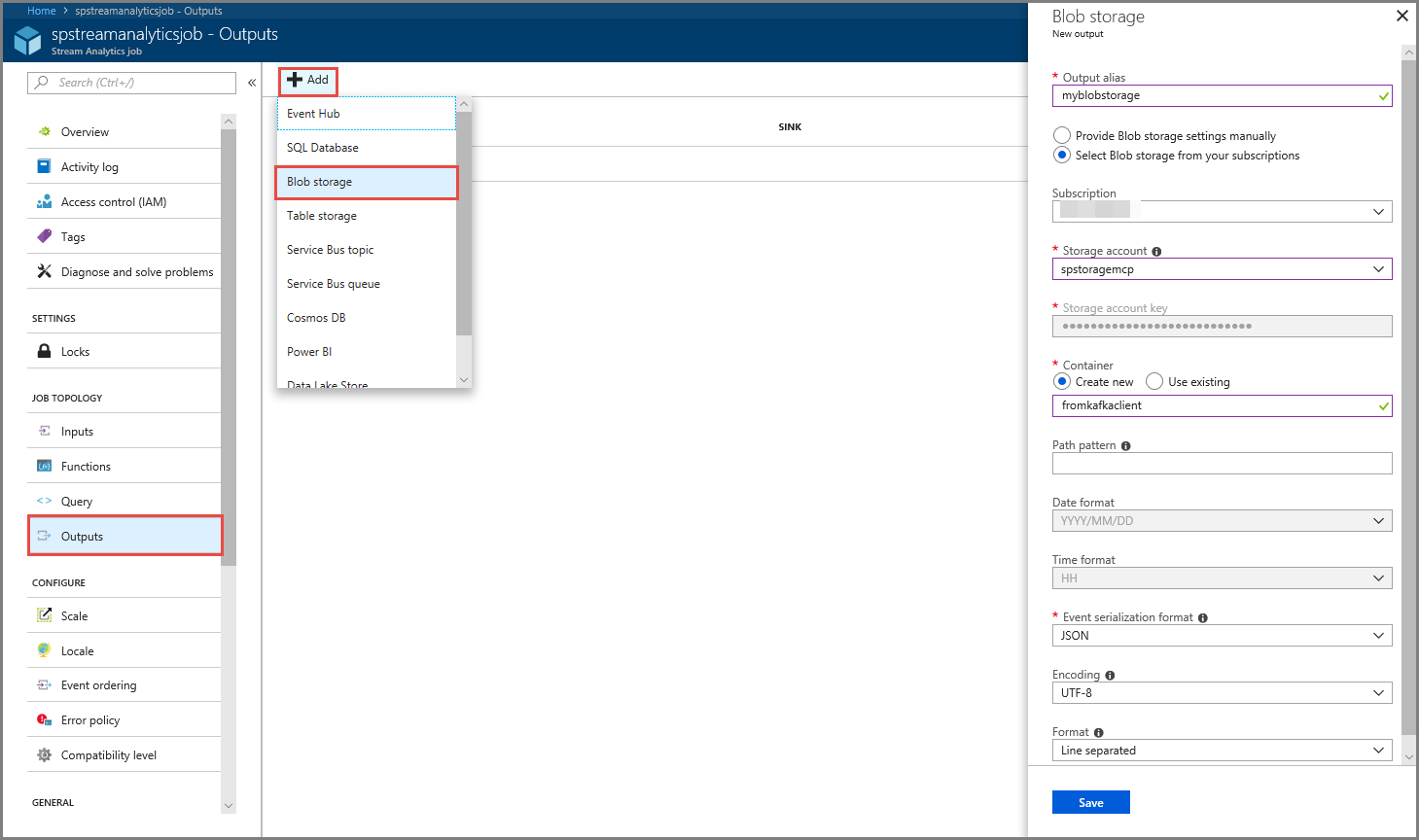
- 메뉴의 작업 토폴로지 섹션에서 출력을 선택합니다.
- 도구 모음에서 + 추가를 선택하고, Blob Storage를 선택합니다.
- Blob Storage 출력 설정 페이지에서 다음 작업을 수행합니다.
출력의 별칭을 지정합니다.
Azure 구독을 선택합니다.
Azure Storage 계정을 선택합니다.
Stream Analytics 쿼리에서 출력 데이터를 저장하는 컨테이너에 대한 이름을 입력합니다.
저장을 선택합니다.
쿼리 정의
들어오는 데이터 스트림을 읽을 Stream Analytics 작업을 설정한 후에 할 일은 데이터를 실시간으로 분석하는 변환을 만드는 것입니다. Stream Analytics 쿼리 언어를 사용하여 변환 쿼리를 정의합니다. 이 연습에서는 변환을 수행하지 않고 데이터를 통해 전달되는 쿼리를 정의합니다.
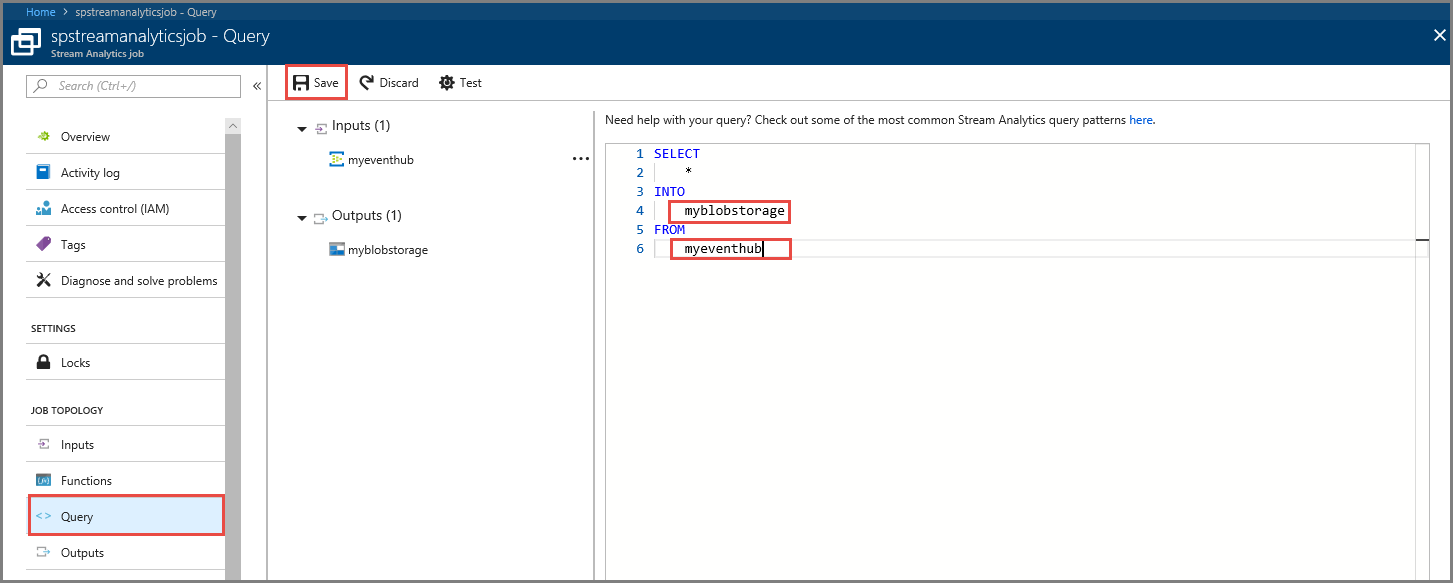
쿼리를 선택합니다.
쿼리 창에서
[YourOutputAlias]를 앞에서 만든 출력 별칭으로 바꿉니다.[YourInputAlias]를 앞에서 만든 입력 별칭으로 바꿉니다.도구 모음에서 저장을 선택합니다.
Stream Analytics 작업 실행
왼쪽 메뉴에서 개요를 선택합니다.
시작을 선택합니다.
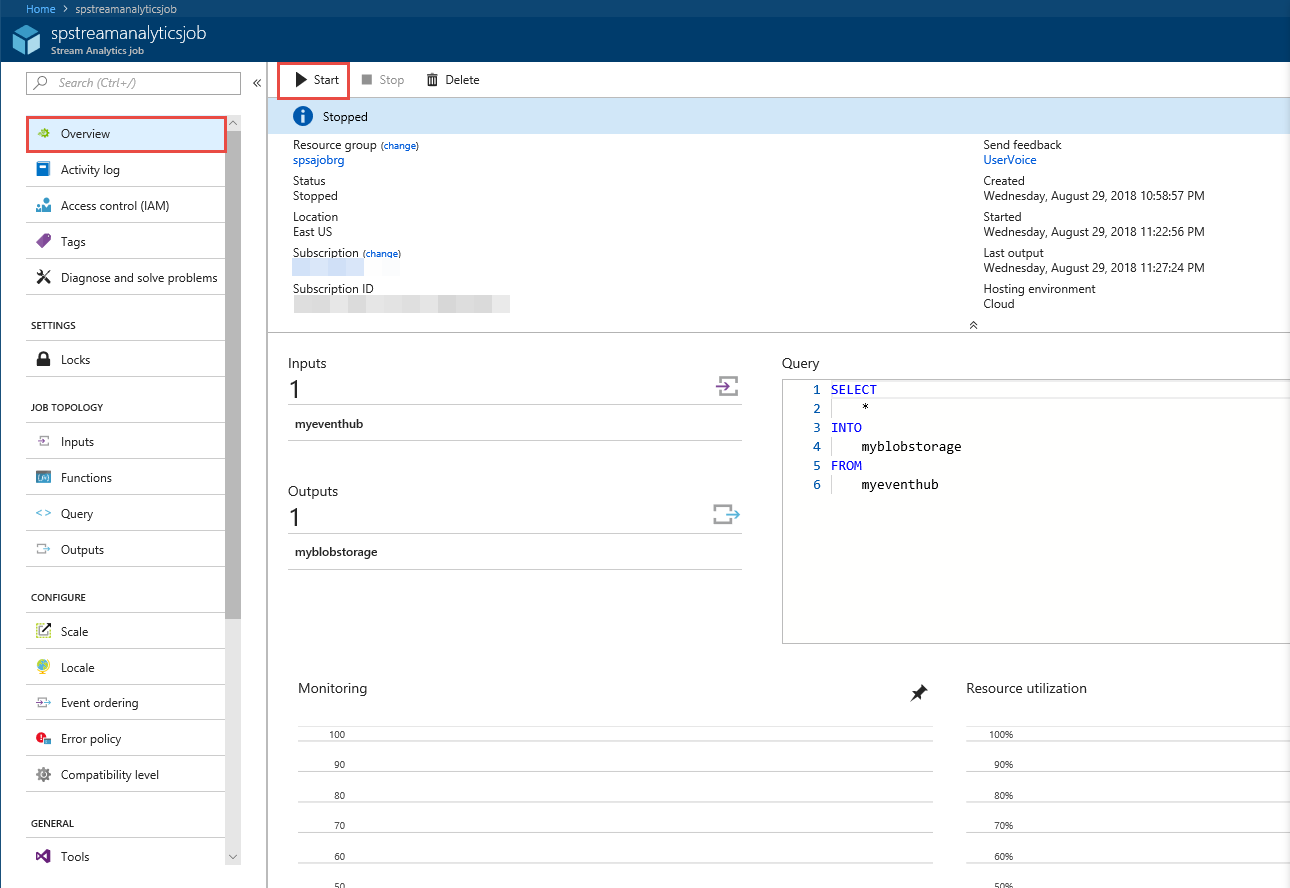
작업 시작 페이지에서 시작을 선택합니다.
작업의 상태가 시작에서 실행 중으로 변경될 때까지 기다립니다.

시나리오 테스트
Kafka 생산자를 다시 실행하여 이벤트 허브로 이벤트를 보냅니다.
mvn exec:java -Dexec.mainClass="TestProducer"Azure Blob Storage에 출력 데이터가 생성되었는지 확인합니다. 다음 샘플 행처럼 보이는 100개 행이 있는 컨테이너에 JSON 파일이 표시됩니다.
{"eventData":"Test Data 0","EventProcessedUtcTime":"2018-08-30T03:27:23.1592910Z","PartitionId":0,"EventEnqueuedUtcTime":"2018-08-30T03:27:22.9220000Z"} {"eventData":"Test Data 1","EventProcessedUtcTime":"2018-08-30T03:27:23.3936511Z","PartitionId":0,"EventEnqueuedUtcTime":"2018-08-30T03:27:22.9220000Z"} {"eventData":"Test Data 2","EventProcessedUtcTime":"2018-08-30T03:27:23.3936511Z","PartitionId":0,"EventEnqueuedUtcTime":"2018-08-30T03:27:22.9220000Z"}Azure Stream Analytics 작업은 이벤트 허브에서 입력 데이터를 받고 이 시나리오에서 Azure Blob Storage에 저장했습니다.
다음 단계
이 문서에서는 프로토콜 클라이언트를 변경하거나 사용자 고유의 클러스터를 실행하지 않고 Event Hubs로 스트리밍하는 방법을 배웠습니다. Apache Kafka용 Event Hubs에 대한 자세한 내용은 Azure Event Hubs용 Apache Kafka 개발자 가이드를 참조하세요.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기