중요
영어가 아닌 번역은 편의를 위해서만 제공됩니다.
이 문서의 EN-US 버전을 최종적으로 확인하세요.
이 문서에서는 OCR(광학 문자 인식) 서비스가 고객이 제공한 데이터를 처리하는 방법에 대한 몇 가지 개략적인 정보를 제공합니다. 중요한 알림으로, 귀하는 이 기술을 구현하고 이 서비스에 데이터를 보내는 데 필요한 모든 라이선스 또는 권한이 있는지 확인해야 합니다. 관할 구역의 모든 관련 법률 및 규정을 준수하는 것은 사용자의 책임입니다.
데이터 수집 및 처리
OCR 서비스는 다음과 같은 유형의 데이터를 처리합니다.
- 이미지(PNG, JPG 및 BMP) 및 문서(PDF 및 TIFF)를 포함하는 OCR 입력 데이터 입니다.
- 고객 문서 및 이미지에서 추출된 텍스트와 텍스트 줄 및 단어의 형식, 해당 위치와 신뢰도 점수가 포함된 OCR 결과 입니다.
OCR 서비스는 데이터를 어떻게 처리하나요?
다음 다이어그램에서는 데이터가 처리되는 방법을 보여 줍니다.
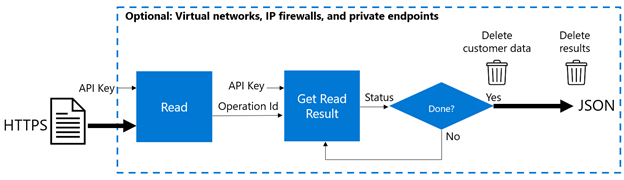
인증(구독 또는 API 키 사용): Vision API 및 해당 읽기 OCR에 대한 액세스를 인증하는 가장 일반적인 방법은 고객의 Vision API 키를 사용하는 것입니다. 서비스 URL에 대한 각 요청에는 인증 헤더가 포함되어야 합니다. 이 헤더는 서비스 또는 서비스 그룹에 대한 구독의 유효성을 검사하는 데 사용되는 API 키(또는 해당하는 경우 토큰)를 전달합니다. 자세히 알아보세요.
전송 중인 데이터 보안(검색용): Vision Read API URL을 비롯한 모든 Foundry 도구 엔드포인트는 전송 중 데이터를 암호화하기 위해 HTTPS URL을 사용합니다. 클라이언트 운영 체제는 엔드포인트를 호출하기 위해 TLS(전송 계층 보안) 1.2를 지원해야 합니다. 자세히 알아보세요.
처리를 위한 입력 데이터 암호화: 들어오는 데이터는 Vision 리소스가 만들어진 동일한 지역에서 처리됩니다. 문서를 읽기 작업에 제출하면 문서를 분석하여 모든 텍스트를 추출하는 프로세스가 시작됩니다. 이 시간 동안 데이터와 결과는 일시적으로 암호화되어 Microsoft 내부 Azure Storage 리소스에 저장됩니다.
추출된 텍스트 결과 검색: 읽기 결과 가져오기 작업을 호출하여 작업 완료 상태를 확인하고 필요에 따라 작업이 성공하면 추출된 텍스트 결과가 발생합니다. 상태의 다른 값은 작업이 시작되지 않았는지, 실행 중인지 또는 실패했는지를 나타냅니다.
OCR에 의해 저장된 데이터
고객이 검색할 결과를 일시적으로 저장합니다. 읽기 및 읽기 결과 가져오기는 비동기 호출입니다. 즉, 고객이 추출된 텍스트 결과를 가져오기 위해 읽기 결과 가져오기 작업을 호출할 시기를 서비스에서 알 수 없습니다. 완료 상태를 확인하고 완료 시 추출된 결과를 고객에게 쉽게 반환하기 위해 추출된 텍스트는 Azure Storage 일시적으로 저장됩니다. 이 동작을 통해 고객은 작업 완료 상태에 대한 비동기 읽기 결과 가져오기 작업을 폴링하고 완료 시 결과를 가져올 수 있습니다.
데이터 삭제: 입력 데이터 및 결과는 24시간 이내에 삭제되며 다른 용도로는 사용되지 않습니다.
Microsoft 개인 정보 보호 및 보안 약정에 대한 자세한 내용은 Microsoft 보안 센터 참조하세요.