HDInsight on AKS 클러스터 자동 스케일링
참고 항목
2025년 1월 31일에 Azure HDInsight on AKS가 사용 중지됩니다. 2025년 1월 31일 이전에 워크로드가 갑자기 종료되지 않도록 워크로드를 Microsoft Fabric 또는 동등한 Azure 제품으로 마이그레이션해야 합니다. 구독의 나머지 클러스터는 호스트에서 중지되고 제거됩니다.
사용 중지 날짜까지 기본 지원만 사용할 수 있습니다.
Important
이 기능은 현지 미리 보기로 제공됩니다. Microsoft Azure 미리 보기에 대한 보충 사용 약관에는 베타 또는 미리 보기로 제공되거나 아직 일반 공급으로 릴리스되지 않은 Azure 기능에 적용되는 더 많은 약관이 포함되어 있습니다. 이 특정 미리 보기에 대한 자세한 내용은 Azure HDInsight on AKS 미리 보기 정보를 참조하세요. 질문이나 기능 제안이 있는 경우 세부 정보와 함께 AskHDInsight에 요청을 제출하고 Azure HDInsight 커뮤니티에서 추가 업데이트를 보려면 팔로우하세요.
작업 성과를 충족하고 비용을 미리 관리하기 위한 클러스터 스케일링은 항상 까다롭고 결정하기 어렵습니다. 클라우드를 통해 데이터 레이크 하우스를 빌드할 때 얻을 수 있는 매력적인 혜택 중 하나는 탄력성, 즉 자동 스케일링 기능을 사용하여 현재 사용 중인 리소스의 활용도를 극대화할 수 있다는 것입니다. Kubernetes를 사용한 자동 스케일링은 비용 최적화 에코시스템을 설정하는 한 가지 핵심입니다. 모든 엔터프라이즈에서 다양한 사용 패턴으로 인해 시간이 지남에 따라 클러스터 로드가 변형되어 클러스터가 과소 프로비전(성능 저하) 또는 과잉 프로비전(유휴 리소스로 인한 불필요한 비용)으로 이어질 수 있습니다.
HDInsight on AKS에서 제공되는 자동 스케일링 기능은 클러스터의 작업자 노드 수를 자동으로 늘리거나 줄일 수 있습니다. 자동 스케일링은 고객이 사용하는 클러스터 메트릭 및 스케일링 정책을 사용합니다.
이 기능은 중요 업무용 워크로드에 적합하며,
- 가변 또는 예측할 수 없는 트래픽 패턴 및 고성능 및 규모에 대한 SLA 필요 또는
- 클러스터에서 작업을 성공적으로 실행하는 데 필요한 작업자 노드를 사용할 수 있도록 미리 결정된 일정입니다.
AKS 클러스터의 HDInsight를 사용한 자동 스케일링을 통해 Azure에서 클러스터를 비용 효율적이고 탄력적으로 확장할 수 있습니다.
자동 스케일링을 사용하면 고객은 워크로드에 영향을 주지 않고 클러스터를 스케일 다운할 수 있습니다. 단계적인 서비스 해제 및 냉각 기간과 같은 고급 기능으로 사용하도록 설정됩니다. 이러한 기능을 통해 사용자는 클러스터의 현재 로드에 따라 노드 추가 및 제거에 대해 정보에 입각한 선택을 할 수 있습니다.
작동 방식
자동 스케일링 기능은 스케일 업 및 스케일 다운 작업의 성능 메트릭이나 정의된 일정에 따라 미리 설정된 제한 내에서 노드 수를 조정하여 작동합니다. 자동 스케일링 기능은 다음 두 가지 조건 유형을 사용하여 스케일링 이벤트를 트리거합니다. 하나는 다양한 클러스터 성능 메트릭에 대한 임계값(로드 기반 스케일링이라고 함)이고, 다른 하나는 시간 기반 트리거(일정 기반 스케일링이라고 함)입니다.
최적의 CPU 사용량을 보장하고 실행 비용을 최소화하기 위해, 부하 기반 크기 조정에서는 설정하는 범위 내에서 클러스터의 노드 수를 변경합니다.
일정 기반 크기 조정은 확대 및 축소 작업의 일정에 따라 클러스터의 노드 수를 변경합니다.
참고 항목
자동 스케일링은 기존 클러스터의 SKU 유형 변경을 지원하지 않습니다.
클러스터 호환성
다음 테이블에서는 자동 스케일링 기능과 호환되는 클러스터 유형과 사용 가능하거나 계획된 항목에 대해 설명합니다.
| 작업 부하 | 로드 기반 | 일정 기반 |
|---|---|---|
| Flink | 예정 | 예 |
| Trino | 네** | 네** |
| Spark | 네** | 네** |
**단계적인 서비스 해제를 구성할 수 있습니다.
스케일링 방법
일정 기반 스케일링:
작업이 고정 일정과 예측 가능한 기간 동안 실행될 것으로 예상되는 경우 또는 하루 중 특정 시간 동안 사용량이 낮을 것으로 예상되는 경우(예: 근무 후 시간, 하루 작업 종료 후의 테스트 및 개발 환경)

로드 기반 스케일링:
예를 들어 하루 중 로드 패턴이 예측할 수 없을 정도로 크게 변동하는 경우 다양한 요인에 따라 로드 패턴이 무작위로 변동하는 데이터 처리를 주문합니다.

새 스케일링 규칙 구성 옵션을 사용하여 이제 스케일링 규칙을 사용자 지정할 수 있습니다.

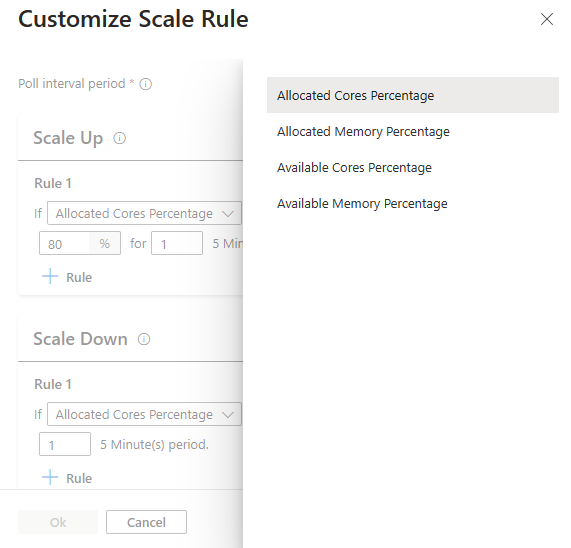
팁
- 스케일 업 규칙은 하나 이상의 규칙이 트리거될 때 우선적으로 적용됩니다. 스케일 업 규칙 중 하나만 클러스터가 과소 프로비전되는 것을 제안하더라도 클러스터는 스케일 업을 시도합니다. 스케일 다운이 발생하려면 스케일 업 규칙을 트리거하지 않아야 합니다.


부하 기반 크기 조정 조건
다음 조건이 감지되면 자동 스케일링에서 스케일링 요청을 실행합니다.
| 강화 | 스케일 다운 |
|---|---|
| 할당된 코어는 5분 폴링 간격(1분 확인 기간)에 대해 80%를 초과합니다. | 할당된 코어는 5분 폴링 간격(1분 확인 기간)에 대해 20% 이하입니다. |
스케일 업의 경우 자동 스케일링에서 필요한 노드 수를 추가하기 위한 스케일 업 요청을 발행합니다. 확대는 현재 CPU 및 메모리 요구 사항을 충족하는 데 필요한 새 작업자 노드 수를 기반으로 합니다. 이 값은 설정된 작업자 노드의 최대 수로 제한됩니다.
스케일 다운의 경우 자동 스케일링은 일부 노드를 제거하라는 요청을 발급합니다. 스케일 다운 고려 사항에는 노드당 Pod 수, 현재 CPU 및 메모리 요구 사항, 작업자 노드가 포함되며, 현재 작업 실행에 따라 제거할 후보입니다. 스케일 다운 작업은 먼저 노드를 해제한 다음, 클러스터에서 제거합니다.
Important
자동 스케일링 규칙 엔진은 시스템 메모리를 최적화하기 위해 30분마다 이전 이벤트를 사전에 플러시합니다. 따라서 스케일링 규칙 간격에 상한 제한인 30분이 있습니다. 스케일링 작업의 일관되고 안정적인 트리거를 보장하려면 스케일링 규칙 간격을 한도보다 작은 값으로 설정해야 합니다. 이 지침을 준수하면 시스템 리소스를 효과적으로 관리하면서 원활하고 효율적인 스케일링 프로세스를 보장할 수 있습니다.
클러스터 메트릭
자동 스케일링은 클러스터를 지속적으로 모니터링하고 로드 기반 자동 스케일링에 대한 다음 메트릭을 수집합니다.
스케일링을 위해 사용할 수 있는 클러스터 메트릭
| 메트릭 | 설명 |
|---|---|
| 사용 가능한 코어 비율 | 클러스터의 총 코어 수와 비교하여 클러스터에서 사용할 수 있는 총 코어 수입니다. |
| 사용 가능한 메모리 비율 | 클러스터의 총 메모리 양과 비교하여 클러스터에서 사용할 수 있는 총 메모리(MB)입니다. |
| 할당된 코어 비율 | 클러스터의 총 코어 수와 비교하여 클러스터에 할당된 총 코어 수입니다. |
| 할당된 메모리 비율 | 클러스터의 총 메모리 양과 비교하여 클러스터에 할당된 메모리 양입니다. |
기본적으로 위의 메트릭은 300초마다 확인되며 자동 스케일링 옵션을 사용자 지정하여 폴링 간격을 사용자 지정할 때도 구성할 수 있습니다. 자동 스케일링은 이러한 메트릭을 기반으로 스케일 업 및 스케일 다운 의사 결정을 내립니다.
참고 항목
기본적으로 자동 스케일링은 Apache Spark용 YARN에 대한 기본 리소스 계산기를 사용합니다. 로드 기반 스케일링은 Apache Spark 클러스터에 사용할 수 있습니다.
단계적인 서비스 해제
기업은 자동 스케일링을 사용하여 페타바이트 규모를 달성하고 더 이상 필요하지 않을 때 리소스를 단계적으로 해제할 수 있는 방법이 필요합니다. 이러한 시나리오에서는 단계적인 서비스 해제 기능이 유용합니다.
단계적인 서비스 해제를 사용하면 자동 스케일링이 작업자 노드의 서비스 해제를 트리거한 후에도 작업을 완료할 수 있습니다. 이 기능을 사용하면 작업이 완료될 때까지 노드를 계속 프로비전할 수 있습니다.
Trino: 작업자는 기본적으로 단계적인 서비스 해제를 사용하도록 설정되어 있습니다. 코디네이터를 사용하면 종료 작업자가 클러스터에서 작업자를 제거하기 전에 구성된 시간 동안 해당 작업을 완료할 수 있습니다. 네이티브 Trino 매개 변수
shutdown.grace-period를 사용하거나 Azure Portal 서비스 구성 페이지에서 시간 제한을 구성할 수 있습니다.Apache Spark: 스케일 다운하면 클러스터에서 실행 중인 모든 작업에 영향을 미치거나 이를 중지할 수 있습니다. Azure Portal에서 단계적인 서비스 해제 설정을 사용하도록 설정하면 YARN 노드의 단계적인 서비스 해제를 통합하고 AKS 클러스터의 HDInsight에서 노드가 제거되기 전에 작업자 노드에서 진행 중인 모든 작업이 완료되도록 합니다.
휴지 기간
지속적인 스케일 업 작업을 방지하기 위해 자동 스케일링 엔진은 다른 스케일 업 작업 집합을 시작하기 전에 구성 가능한 간격을 기다립니다. 기본값은 180초로 설정됩니다.
참고 항목
- 사용자 지정 스케일링 규칙에서 규칙 트리거의 트리거 간격은 30분보다 길 수 없습니다. 자동 스케일링 이벤트가 발생한 후 다른 스케일링 정책을 적용하기 전에 대기하는 시간입니다.
- 냉각 기간은 정책 간격보다 커야 클러스터 메트릭을 다시 설정할 수 있습니다.
시작하기
자동 스케일링이 작동하려면 왼쪽 창의 IAM을 사용하여 클러스터 수준에서 MSI(클러스터를 만드는 동안 사용됨)에 소유자 또는 기여자 권한을 할당해야 합니다.
역할 할당을 추가하는 방법에 대해서는 다음 그림과 단계를 참조하세요.

역할 할당 추가를 선택합니다.
- 할당 유형: 권한 있는 관리자 역할
- 역할: 소유자 또는 기여자
- 멤버: 관리 ID를 선택하고 클러스터 생성 단계에서 제공된 사용자가 할당한 관리 ID를 선택합니다.
- 역할을 할당합니다.

일정 기반 자동 스케일링을 사용하여 클러스터 만들기
클러스터 풀이 만들어지면 클러스터 유형에서 원하는 워크로드를 사용하여 새 클러스터를 만들고 일반 클러스터 만들기 프로세스의 일부로 다른 단계를 완료합니다.
구성 탭에서 자동 스케일링 토글을 사용하도록 설정합니다.
일정 기반 자동 스케일링
시간대를 선택하고 + 규칙 추가를 클릭합니다.
새 조건이 적용되는 주의 날짜를 선택합니다.
조건이 적용되는 시간 및 클러스터의 크기를 조정해야 하는 노드 수를 편집합니다.

참고 항목
- 자동 스케일링이 작동하려면 클러스터 MSI에서 사용자에게 “소유자” 또는 “기여자” 역할이 있어야 합니다.
- 기본값은 클러스터를 만들 때 클러스터의 초기 크기를 정의합니다.
- 두 일정 사이의 차이는 기본적으로 30분으로 설정됩니다.
- 시간 값은 24시간 형식을 따릅니다.
- 며칠에 걸쳐 24시간을 초과하는 연속 기간의 경우 며칠에 걸쳐 자동 크기 조정 일정을 설정해야 하며, 자동 크기 조정은 23:59를 00:00(노드 수 동일)로 간주하고 이틀에 걸친 22:00~23:59 및 00:00~02:00을 22:00~02:00로 간주합니다.
- 일정은 기본적으로 UTC(협정 세계시)로 설정됩니다. 언제든지 사용 가능한 드롭다운에서 현지 표준 시간대에 해당하는 표준 시간대로 업데이트할 수 있습니다. 일광 절약 시간을 관찰하는 표준 시간대에 있는 경우 일정이 자동으로 조정되지 않으므로 그에 따라 일정 업데이트를 관리해야 합니다.

로드 기반 자동 스케일링을 사용하여 클러스터 만들기
클러스터 풀이 만들어지면 클러스터 유형에서 원하는 워크로드를 사용하여 새 클러스터를 만들고 일반 클러스터 만들기 프로세스의 일부로 다른 단계를 완료합니다.
구성 탭에서 자동 스케일링 토글을 사용하도록 설정합니다.
로드 기반 자동 스케일링 선택
워크로드 유형에 따라 단계적인 서비스 해제 시간, 냉각 기간을 추가하는 옵션이 있습니다.
최소 및 최대 노드를 선택하고 필요한 경우 필요에 따라 자동 스케일링을 사용자 지정하도록 스케일링 규칙을 구성합니다.

팁
- 구독에는 각 Azure 지역에 대한 용량 할당량이 있습니다. 헤드 노드의 코어와 최대 작업자 노드의 총 수는 용량 할당량을 초과하면 안됩니다. 그러나 이 할당량은 소프트 제한이며, 언제든지 지원 티켓을 만들어서 간편하게 할당량을 늘릴 수 있습니다.
- 총 코어 할당량 한도를 초과하면
The maximum node count you can select is {maxCount} due to the remaining quota in the selected subscription ({remaining} cores)와 같은 오류 메시지가 표시됩니다. - 스케일 업 규칙은 하나 이상의 규칙이 트리거될 때 우선적으로 적용됩니다. 스케일 업 규칙 중 하나만 클러스터가 과소 프로비전되는 것을 제안하더라도 클러스터는 스케일 업을 시도합니다. 스케일 다운이 발생하려면 스케일 업 규칙을 트리거하지 않아야 합니다.
- 공개 미리 보기에서 HDInsight on AKS는 클러스터에서 최대 500개의 노드를 지원합니다.

Resource Manager 템플릿을 사용하여 클러스터 만들기
일정 기반 자동 스케일링
Azure 리소스 관리자 템플릿을 사용하여 일정 기반 자동 스케일링 기능이 있는 HDInsight on AKS 클러스터를 만들려면 clusterProfile -> autoscaleProfile 섹션에 자동 스케일링을 추가하면 됩니다.
자동 스케일링 노드에는 변경이 발생하는 시기를 설명하는 표준 시간대 및 일정이 있는 되풀이가 포함됩니다. 전체 Resource Manager 템플릿은 샘플 JSON을 참조하세요.
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "ScheduleBased",
"gracefulDecommissionTimeout": 60,
"scheduleBasedConfig": {
"schedules": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday"
],
"startTime": "09:00",
"endTime": "10:00",
"count": 2
},
{
"days": [
"Sunday",
"Saturday"
],
"startTime": "12:00",
"endTime": "22:00",
"count": 5
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "22:00",
"endTime": "23:59",
"count": 6
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "00:00",
"endTime": "05:00",
"count": 6
}
],
"timeZone": "UTC",
"defaultCount": 110
}
}
}
팁
- 스케일링 작업 오류를 방지하려면 ARM 배포를 사용하여 충돌하지 않는 일정을 설정해야 합니다.
로드 기반 자동 스케일링
Azure 리소스 관리자 템플릿을 사용하여 로드 기반 자동 스케일링 기능이 있는 HDInsight on AKS 클러스터를 만들려면 clusterProfile -> autoscaleProfile 섹션에 자동 스케일링을 추가하면 됩니다.
자동 스케일링 노드에 포함
- 폴링 간격, 냉각 기간,
- 단계적인 서비스 해제,
- 최소 및 최대 노드,
- 표준 임계값 규칙,
- 변경이 발생하는 시기를 설명하는 메트릭 스케일링.
전체 Resource Manager 템플릿은 다음과 같이 샘플 JSON을 참조하세요.
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "LoadBased",
"gracefulDecommissionTimeout": 60,
"loadBasedConfig": {
"minNodes": 2,
"maxNodes": 157,
"pollInterval": 300,
"cooldownPeriod": 180,
"scalingRules": [
{
"actionType": "scaleup",
"comparisonRule": {
"threshold": 80,
"operator": " greaterThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
},
{
"actionType": "scaledown",
"comparisonRule": {
"threshold": 20,
"operator": " lessThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
}
]
}
}
}
REST API 사용
REST API를 사용하여 실행 중인 클러스터에서 자동 스케일링을 사용하거나 사용하지 않도록 설정하려면 자동 스케일링 엔드포인트에 PATCH 요청을 보냅니다. https://management.azure.com/subscriptions/{{USER_SUB}}/resourceGroups/{{USER_RG}}/providers/Microsoft.HDInsight/clusterpools/{{CLUSTER_POOL_NAME}}/clusters/{{CLUSTER_NAME}}?api-version={{HILO_API_VERSION}}
- 요청 페이로드에서 적절한 매개 변수를 사용합니다. json 페이로드를 사용하여 자동 스케일링을 사용하도록 설정할 수 있습니다.
- 페이로드(autoscaleProfile: null)를 사용하거나 플래그(사용, false)를 사용하여 자동 스케일링을 사용하지 않도록 설정합니다.
- 참조하려면 위의 단계에서 언급한 JSON 샘플을 참조하세요.
실행 중인 클러스터에 대한 자동 스케일링 일시 중지
자동 스케일링에 일시 중지 기능이 도입되었습니다. 이제 Azure Portal을 사용하여 실행 중인 클러스터에서 자동 스케일링을 일시 중지할 수 있습니다. 아래 다이어그램에서는 일시 중지를 선택하고 자동 스케일링을 다시 시작하는 방법을 보여 줍니다.

자동 스케일링 작업을 다시 시작하려는 경우 다시 시작할 수 있습니다.

팁
여러 일정을 구성하고 자동 스케일링을 일시 중지하는 경우 다음 일정이 트리거되지 않습니다. 노드 수가 서비스 해제된 상태인 경우에도 노드 수는 동일하게 유지됩니다.
자동 스케일링 구성 복사
이제 Azure Portal을 사용하여 클러스터 풀 전체에서 동일한 클러스터 셰이프에 대해 동일한 자동 스케일링 구성을 복사할 수 있습니다. 이 기능을 사용하여 동일한 구성을 내보내거나 가져올 수 있습니다.

자동 스케일링 작업 모니터링
클러스터 상태
Azure Portal에 나열된 클러스터 상태를 통해 자동 스케일링 작업을 모니터링할 수 있습니다. 표시될 수 있는 모든 클러스터 상태 메시지는 아래 목록에 설명되어 있습니다.
| 클러스터 상태 | 설명 |
|---|---|
| 성공함 | 클러스터가 정상적으로 작동하고 있습니다. 모든 이전 자동 스케일링 작업이 성공적으로 완료되었습니다. |
| Accepted | 클러스터 작업(예: 스케일 업)이 수락되어 작업이 완료될 때까지 기다립니다. |
| 실패함 | 이는 어떤 이유로 인해 현재 작업이 실패했으며 클러스터가 작동하지 않을 수 있음을 의미합니다. |
| Canceled | 현재 작업이 취소되었습니다. |

클러스터의 현재 노드 수를 보려면 클러스터의 개요 페이지에서 클러스터 크기 차트로 이동합니다.

작업 기록
클러스터 메트릭의 일부로 클러스터 확대 및 축소 기록을 볼 수 있습니다. 어제, 지난주 또는 기타 기간의 스케일링 작업도 모두 나열할 수 있습니다.

추가 리소스